






因由
接收到项目现场报某个组件模块cpu占用过高,飙升达4000+(64线程服务器);
现场状况
现场有40多台的服务器,报警服务器所在组件模块是一个java组件模块,并且部署在了容器中;现场有几千的并发,且都是一些较大的数据对象;使用jdk1.8
解决
初步怀疑是内存溢出导致频繁full gc从而导致cpu飙高;
查看gc日志并未发现频繁full gc,且也未出现内存溢出时的堆快照文件(设置了-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath);
此时通过top命令,然后按c,找到占用cpu最高的pid(本次案例中占用4000+cpu的pid=7);
然后通过查看该pid对应的java进程下线程资源的占用情况;
#top -Hp $pid
top -Hp 7
发现有几十个线程的cpu占用非常高,大概都维持在99+以上,这几十个线程应该就是导致cpu飙高的罪魁祸首;

盘它!进入jdk的bin目录,请出神器jstack;因本次问题线程较多,为了方便查看分析,将其导出到文件中;如果线程不多,可以直接用命令查看分析;
# 将一个问题线程的id转为16进制(java线程栈中线程id为16进制),例如将上图的第一个线程pid=339转为16进制为153
printf '%x\n' 339
# 使用jstack $pid | grep 16进制tid的形式来查看问题线程的堆栈;
jstack 7 | grep "nid=0x153 " -A20
# jstack命令来导出问题pid的所有线程栈到文件
jstack 7 > stack.log
然后进入导出的线程栈文件中,根据问题线程id转16进制后,找到对应的线程栈位置;从内容发现这批问题线程来自一个线程池,且一直处于RUNNABLE状态,而且都是卡在了TreeMap的put方法上,找到对应的业务代码位置,发现,该处为开启了对应服务器台数的线程池,然后每次请求时,会并发该数目(40多个)的线程对每个服务器发起请求获取数据,然后每个线程拿到数据后会放到共享的一个TreeMap里供后续的业务处理;
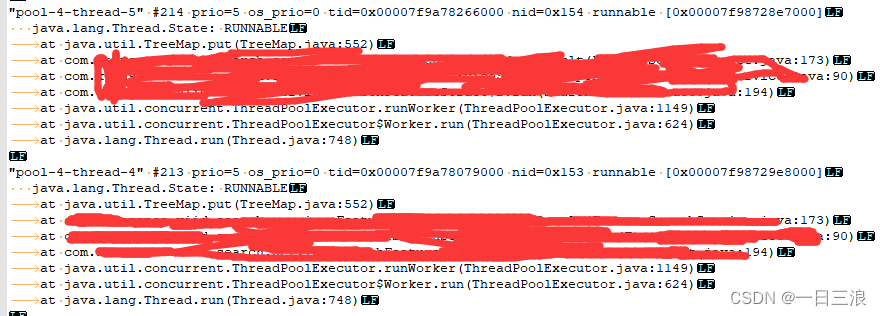
此时,问题真相大白,该问题时一个多线程Map使用不当的例子;非线程安全的Map,在并发处理时,可能会造成死循环从而导致cpu飙升;
引申阅读:多线程下Map的死循环原因
引申阅读:不止 JDK7 的 HashMap ,JDK8 的 ConcurrentHashMap 也会造成 CPU 100%?原因与解决~
此时,将TreeMap包装成线程安全对象,Collections.synchronizedMap(new TreeMap()), 或者使用线程安全的ConcurrentSkipListMap来代替TreeMap;问题得到解决;
引申阅读:TreeMap 和 ConcurrentSkipListMap
引申阅读:跳表的实现原理















 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









