









数位DP:
用来统计区间内符合条件的数的个数,通常区间范围很大,并且条件通常与数的组成有关。
解题关键:对前缀的抽象分类。须符合两个条件。
- 对于一个数anan-1……a2a1a0, 可以将前缀anan-1…ak+1归类于状态(sta,k), 使得具有相同状态的前缀的解一致。
- 可以求解,在状态(sta,k)下,dkdk-1…d1d0中符合条件的数字的个数。
实现方法是记忆化搜索。dp[k][sta]存储状态为sta,剩余k+1位时的解。
实现小技巧:
上界限制:limit -> 对当前位的取值有上界限制,如213,若前两位取21,则对个位取值上界产生影响
前导0: lead -> 如果前面的位数都是0,会对后面的计数产生影响
注意点:这类问题的检错相对方便许多,因为可以直接输入数字查看其计算结果。所以可以直接对范围两个边界进行输出检查,如左侧直接输出检查[-1, 19]。右侧则还要考虑会不会溢出。最后再检查一下中间特殊点(如果有的话)。如果都没问题,那么出错概率就小很多了。
附上例题:
比较典型的例题就是hdu2089-不要62
题意:
给定整数对n, m(0 < n ≤ m ≤ 1000000),求区间[n,m]中不含4和62的数。
思路:
这题就是典型的数位dp了,显然对于尾数不为6的任意前缀,给定剩余位数,其解是相同的。例如,23xxx和32xxx中符合条件的数是相同的。同理,尾数为6的前缀的解也是相同的。
代码:
// 数位DP
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cstring>
#include <string>
#include <vector>
#include <queue>
#include <map>
#include <set>
using namespace std;
const int MAX_POS = 7;
const int INF_ = 0x3f3f3f3f;
int dp[MAX_POS+1][2]; // dp[i][1] 当第i+1位为6时前i符合条件的个数。
int num[MAX_POS+1]; // 将数字按位放置到数组中
void init()
{
memset(dp, -1, sizeof(dp));
}
// 当前面位已知,求0到pos位符合条件数的个数
// 三种情况:
// 1. 0位到pos位都可以取任意数 存于dp[pos][0]
// 2. 前一位pre是6, pos位选值有影响 存于dp[pos][1]
// 3. 前面几位都是取到最高位(limit=true), 因此0位到pos位的取值受影响 -> 影响当前pos位取值, 并将影响递归下去;
int dfs(int pos, int pre, bool limit)
{
if (pos == -1) return 1;
// 记忆化
if (!limit && dp[pos][pre == 6] != -1) return dp[pos][pre == 6];
int up = limit ? num[pos] : 9;
int tmp = 0;
for (int i = 0; i <= up; i++)
{
if (i == 4) continue;
if (pre == 6 && i == 2) continue;
tmp += dfs(pos-1, i, limit && i == up);
}
if (!limit) dp[pos][pre == 6] = tmp;
return tmp;
}
int solve(int n)
{
int pos = 0;
while (n > 0)
{
num[pos++] = n % 10;
n /= 10;
}
return dfs(pos-1, -1, 1);
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
int n, m;
init();
while (cin >> n >> m)
{
if (n == 0 && m == 0) break;
cout << solve(m) - solve(n-1) << endl;
}
}
稍微难一点的题目codeforces55(D)-Beautiful numbers
题意:
求区间[li,ri]中可以整除自身所有非0数字的数的数目。(1 ≤ li ≤ ri ≤ 9*10^18)
分析:
还是一样的思路,对前缀进行抽象分类。即给定怎样的前缀,他们的解是一样的。
首先可以对整除自身所有非0数字进行分析,这句话的意思就是说要求整除这些非0数的最小公倍数。而其实1到9可以组成的公倍数的数量只有48个。其中最大的最小公倍数是2520(2^3*3^2*5*7)。
所谓整除就是取mod为0,而取mod有个常用的性质,就是分配率。即anan-1…a2a1 mod p = (an...ak+1 * 10^k mod p + ak-1...a1 mod p) mod p。于是我们就可以将前缀与后缀分开,从而对前缀进行分类了。具有相同最小公倍数,并且对所有最小公倍数求mod的值相同的前缀可以归于一类。这时状态数量=19 * 48 * 48 * 2520。而对所有最小公倍数求模值相同等价于对他们的公倍数求模相同( (A mod p1p2) mod p1 = A mod p1)。而2520就是所有最小公倍数的公倍数,所以我们可以只记录其前缀对2520取模的值。这时状态数量就变成19 * 48 * 2520了。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <cmath>
#include <cstring>
#include <string>
#include <vector>
#include <queue>
#include <map>
#include <set>
using namespace std;
/*
即求可以整除其自身所有位数的最小公倍数的数字数目。
位数的最小公倍数的数量为 (4*3*2*2), 最大的最小公倍数为(2^3*3^2*5*7)
所以可以根据前缀最小公倍数分为48个状态
若我们已知给定前缀,mod48个状态所得各个取值的数字个数,则给定前缀,我们可以快速求出答案。
需48*48*2520个状态
(A mod p1p2) mod p1 = A mod p1
只需记录(mod 2520)即可知道其mod其他最小公倍数的值, 只需48*2520个状态
剩余pos+1个bit, (mod (2520) == sta)的前缀的解
dp[pos][sta_id][2520]
*/
const long long MAX_POS = 19; // 最多占用19个bit
const long long MAX_STA = 48; // 最小公倍数数量
const long long MAX_VAL = 2520; // 最大的最小公倍数
long long dp[MAX_POS][MAX_STA][MAX_VAL];
long long num[MAX_POS];
long long sta_vals[MAX_STA];
long long pow_10[MAX_POS];
long long myPow(long long base, long long e)
{
long long ans = 1;
for (int i = 0; i < e; i++) ans *= base;
return ans;
}
void init()
{
memset(dp, -1, sizeof(dp));
long long cnt = 0;
for (long long i = 0; i <= 3; i++)
for (long long j = 0; j <= 2; j++)
for (long long p = 0; p <= 1; p++)
for (long long q = 0; q <= 1; q++)
{
sta_vals[cnt++] = myPow(2, i) * myPow(3, j) * myPow(5, p) * myPow(7, q);
}
for (long long i = 0; i < MAX_POS; i++)
{
pow_10[i] = myPow(10, i);
// pow_10[i] = pow(ten, i);
// cout << "10^"<<i<<" "<< pow_10[i] << endl;
// pow返回值是浮点数,会有精度损失
}
}
long long getStaId(long long sta)
{
for (long long i = 0; i < MAX_STA; i++)
if (sta == sta_vals[i]) return i;
}
long long getLCM(long long a, long long digit)
{
if (digit == 0) return a;
long long tmp = a;
long long prime_num[] = {2, 3, 5, 7};
for (long long i = 0; i < 4; i++)
{
while (tmp % prime_num[i] == 0 && digit % prime_num[i] == 0)
{
tmp /= prime_num[i];
digit /= prime_num[i];
}
}
return a*digit;
}
// 当前位数, 状态(前缀数字的最小公倍数), mod_val(mod 2520的值)
long long dfs(long long pos, long long sta, long long mod_val, bool limit)
{
if (pos == -1)
{
if (mod_val % sta == 0) return 1;
else return 0;
}
long long sta_id = getStaId(sta);
if (!limit && dp[pos][sta_id][mod_val] != -1) return dp[pos][sta_id][mod_val];
long long up = limit ? num[pos] : 9;
long long tmp = 0;
for (long long i = 0; i <= up; i++)
{
long long new_mod_val = ((i * pow_10[pos]) % MAX_VAL + mod_val) % MAX_VAL;
long long new_sta = getLCM(sta, i);
tmp += dfs(pos - 1, new_sta, new_mod_val, limit && (i == up));
}
if (!limit) dp[pos][sta_id][mod_val] = tmp;
return tmp;
}
long long solve(long long n)
{
long long pos = 0;
while (n > 0)
{
num[pos++] = n % 10;
n /= 10;
}
return dfs(pos-1, 1, 0, true);
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
init();
long long t;
cin >> t;
while (t-->0)
{
long long le, ri;
cin >> le >> ri;
cout << solve(ri)-solve(le-1) << endl;
}
}
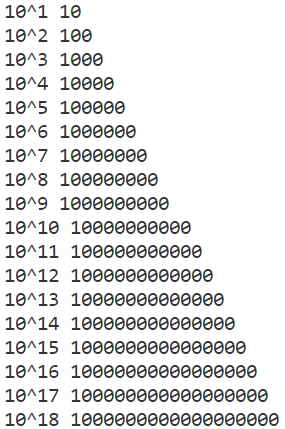
在这题我遇到了一个坑。我在本机的输出和在codeforces上的输出不一致。多亏codeforces有测试样例输出,我才发现了在codeforces上整形pow函数会有精度损失。左图是本机计算pow(10,i)的结果,右图是codeforces上的结果。原因是pow函数的返回值都是浮点类型,所以取整的时候可能会出现精度损失。因此,以后对于整形的求指,还是自己实现吧!
















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









