







本笔记为DataWhale 9月GitModel课程的学习内容,链接为:
https://github.com/Git-Model/Modeling-Universe/Data Analysis and Statistical Modeling/
目录
引言
回归与分类
- 回归和分类是数据分析的两大重要任务,它们最大的区别在于因变量的类别:回归分析的因变量是连续变量;分类分析的因变量是分类属性变量。
- 与回归分析一样,在进行分类分析之前,必须要弄清楚建模的目的是推断还是预测,任务的不同将很大程度决定我们建模所采用的方法论的不同。
- 如果是以推断/分析为主,在建模时所采用的模型最好是易于解释的白盒模型,如一众线性模型;
- 如果是以预测为主,建模的依据主要是预测的精度,模型的可解释性相对而言不那么重要。
关于分类
- 对于分类任务而言,当前预测精度高的模型基本上都是深度学习/机器学习模型(如:支持向量机、随机森林、Xgboost等),而这些模型的可解释性一般都很差,难以在这些模型中寻找变量之间的依存信息。
- 如果追求分类模型的可解释性,探究各自变量对分类决策的影响,那么使用线性模型框架下的分类模型就比较合适了(如:Logistic回归、Probit回归等)。
- 分类问题按照被分类对象的类别划分,总共可以分为三类:二分类问题、无序多分类问题、有序多分类问题。
- 二分类问题是最简单也是最常见的分类问题,如我们要研究客户流失跟哪些因素有关,从而对客户流失做出预警,此时因变量就是客户“是”与“否”会流失;又例如根据短信正文的内容判断邮件是垃圾邮件还是正常邮件,这些都属于二分类问题。二分类问题可用二分类Logistic回归模型与Probit模型
- 无序多分类问题是二分类问题的延伸,如我们要根据新闻内容对新闻主题进行分类,分类主题有体育、政治、娱乐、生活等。这种因变量类别多于两个,且类别间没有大小顺序的分类问题,被称为无序多分类问题,可用多类别logistic回归模型建模。
- 有序多分类问题也称为定序问题,在问卷调查中常常出现,如我们要求消费者对产品进行满意度评价,评价结果包括不满意、一般、满意三个选项,我们可以将之赋值为1/2/3。这三个取值是存在先后大小之分的,这是与无序多分类问题最大的不同。对于这类问题,我们可用有序Logistic回归模型。
- 分类问题与对应模型:
·1. 二分类问题——二分类Logistic回归、Probit回归。
·2. 无序多分类问题——多分类Logistic回归。
·3. 有序多分类问题——有序Logistic回归。
一、二分类问题
1. 二分类Logistic回归、Probit回归
-
若映射函数为Logistic函数:
G ( y ) = 1 1 + e − y G(y)=\frac{1}{1+e^{-y}} G(y)=1+e−y1
则整个预测模型被称为Logistic线性回归模型 -
若映射函数为Probit函数:
Φ ( y ) = P ( Y ≤ y ) = ∫ − ∞ y 1 2 π exp ( − 1 2 x 2 ) d x \Phi(y)=P(Y \leq y)=\int_{-\infty}^{y} \frac{1}{\sqrt{2 \pi}} \exp \left(-\frac{1}{2} x^{2}\right) d x Φ(y)=P(Y≤y)=∫−∞y2π1exp(−21x2)dx
则整个预测模型被称为Probit线性回归模型。注意到,Probit函数实际上就是标准正态分布的累积函数。 -
两个函数都是具有单调递增性质的可逆函数,且值域位于(0,1)之间,是理想的概率映射函数。
-
Logistic回归模型与一般多元回归模型的一大区别在于,前者的因变量是一个有关概率 p ( y = 1 ∣ x ) p\left( y=1|x \right) p(y=1∣x)的函数,而后者的因变量只是其本身。如果把 y = 1 y=1 y=1 看作“成功”, y = 0 y=0 y=0 看作失败,则 p ( x ) [ 1 − p ( x ) ] \frac{p(x)} {[1-p(x)]} [1−p(x)]p(x) 就是成功与失败的概率比,被称为胜率(odd)。
2. 模型推断
Logistic、Probit回归 与 OLS估计 的不同点:
- a. 两类模型用的是极大似然估计法对模型参数进行估计。
- b. Logistic回归与Probit回归参数检验统计量:
- 单参数检验下,渐进服从标准正态分布:
H 0 : β j = β j 0 ↔ H 1 : β j ≠ β j 0 H_{0}: \beta_{j}=\beta_{j 0} \leftrightarrow H_{1}: \beta_{j} \neq \beta_{j 0} H0:βj=βj0↔H1:βj=βj0
β ^ j − β j s d ( β ^ j ) ⇒ N ( 0 , 1 ) \frac{\hat{\beta}_{j}-\beta_{j}}{s d\left(\hat{\beta}_{j}\right)} \Rightarrow N(0,1) sd(β^j)β^j−βj⇒N(0,1) - 多参数检验下,引入离差作统计量计算:
D e v i a n c e = − 2 ⋅ l o g ( l i k e l i h o o d ( m o d e l ) ) \,\,\mathrm{Deviance} =-2\cdot log\left( likelihood(model) \right) Deviance=−2⋅log(likelihood(model))
公式含义是 − 2 -2 −2 倍的模型对数似然比,而模型的对数似然比在summary播报中正是指标Log-Likelihood。- 当两个模型的离差足够大时: D r − D u r > C D_{r}-D_{u r}>C Dr−Dur>C,便可以拒绝原假设( H 0 : β 1 = β 2 = ⋯ = β 7 = 0 H_{0}: \beta_{1}=\beta_{2}=\cdots=\beta_{7}=0 H0:β1=β2=⋯=β7=0),认为参数是联合显著的;
- 在这个检验中,似然比检验统计量定义为:
L R = 2 ( l u r − l r ) = D r − D u r ∼ H 0 χ q 2 L R=2\left(l_{u r}-l_{r}\right)=D_{r}-D_{u r} \sim^{H_{0}} \chi_{q}^{2} LR=2(lur−lr)=Dr−Dur∼H0χq2
服从自由度为 q q q 约束个数的卡方分布。
- 单参数检验下,渐进服从标准正态分布:
3. 模型预测
(1) 预测概率值计算
在模型训练完成后,下一步就是进行预测。
- 对于给定的观测样本,带入模型,计算如下概率值:
p ^ ( x 0 ) = e x 0 ′ β ^ 1 + e x 0 ′ β ^ \hat{p}\left(x_{0}\right)=\frac{e^{x_{0}^{\prime} \hat{\beta}}}{1+e^{x_{0}^{\prime} \hat{\beta}}} p^(x0)=1+ex0′β^ex0′β^ - 规定一个阈值,当概率时,样本被划分为1类,否则划分为0类。即:
y ^ 0 = { 1 , p ^ ( x 0 ) > α 0 , Otherwise \hat{y}_{0}= \begin{cases}1, & \hat{p}\left(x_{0}\right)>\alpha \\ 0, & \text { Otherwise }\end{cases} y^0={1,0,p^(x0)>α Otherwise
一般情况下,阈值 α \alpha α 默认为0.5。
(2) 模型预测结果评估
- 混淆矩阵
import mglearn
mglearn.plots.plot_binary_confusion_matrix()

- 在分类问题中,negative通常指代“反类”,分类标签通常设置为0;positive通常指代“正类”,分类标签通常设置为1。
- 横行表示样本实际的属性,纵列表示样本被模型预测的属性,如果两者不一致(FN/FP)就意味着预测错误,如果两者一致则意味着预测正确(TN/TP)。
- 多分类指标
a. 在混淆矩阵的基础上,可以计算分类精度(也就是分类正确率),分类精度的公式为:
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
Accuracy=\frac{TP+TN}{TP+TN+FP+FN}
Accuracy=TP+TN+FP+FNTP+TN
- 在正负样本比例不均衡的情况下,会带来样本一种预测精度很高的假象。
比如,负样本量(648)远远大于正样本(36),且“0”的预测正确率高(有647个样本被正确分类,只有1个样本被错误分类),“1”的预测正确率低(35个样本被错误分类,只有一个分类正确),这时就会呈现整体预测正确率很高: ( 647 + 1 ) ( 647 + 1 + 35 + 1 ) ≈ 95 % \frac{(647+1)}{(647+1+35+1)}\approx95\% (647+1+35+1)(647+1)≈95% 。
b. 精确率(Precision),衡量的是所有被预测为正类的样本中,预测正确的比例,公式为:
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision=\frac{TP}{TP+FP}
Precision=TP+FPTP
如果我们的分类目标是 限制假正例(
y
=
0
y=0
y=0被预测为
y
^
=
1
\hat{y}=1
y^=1),那么精确率就可以很好的度量,例如:垃圾短信判断(遗漏正常短信的代价远远大于遗漏垃圾短信)。
c. 召回率(Recall) ,衡量的是所有正类样本中,预测正确的比例,公式为:
R
e
c
a
l
l
=
T
P
T
P
+
F
N
\mathrm{Re}call=\frac{TP}{TP+FN}
Recall=TP+FNTP
如果我们想 限制假反例(
y
=
1
y=1
y=1 被预测为
y
^
=
0
\hat{y}=0
y^=0),那么召回率就可以很好的度量,例如:癌症判断(遗漏有癌症的代价远远大于遗漏无癌症)。
d. F分数(F-score) 是精确率与召回率的调和平均,是两者的综合取舍,公式为:
F
−
s
c
o
r
e
=
2
⋅
p
r
e
c
i
s
i
o
n
⋅
r
e
c
a
l
l
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
F-score=2\cdot \frac{precision\cdot recall}{precision+recall}
F−score=2⋅precision+recallprecision⋅recall
二、 多分类
K类别的多分类Logistic回归主要有两种:
- 一种是修改概率映射函数 ,将其中一个类作为基类,通过修改过后的映射函数获得k-1个对数胜率;
-
可以选取一个类别作为基类(在这里我们选择0类),像上述公式一样分别计算0类与剩余类别之间的对数概率之比:
g m ( x ) = log ( p ( y = m ∣ x ) p ( y = 0 ∣ x ) ) = β m 0 + β m 1 x 1 + ⋯ + β m k x k , m = 1 , … , M g_m\left( x \right) =\log \left( \frac{p(y=m|x)}{p(y=0|x)} \right) =\beta _{m0}+\beta _{m1}x_1+\cdots +\beta _{mk}x_k\text{,}m=1,…,M gm(x)=log(p(y=0∣x)p(y=m∣x))=βm0+βm1x1+⋯+βmkxk,m=1,…,M -
有M个类别,就会有M-1个函数,这些函数的实际意义是“目标类别 j j j与基类 0 0 0的对数胜率”。
-
计算出了M-1个函数 g m ( x ) g_m\left( x \right) gm(x) 后,我们便可以使用一个变式的Logit映射函数计算每个类别的条件概率 P ( y = m ∣ x ) P(y=m\mid \mathbf{x}) P(y=m∣x)
P ( y = m ∣ x ) = e g m ( x ) 1 + ∑ m = 1 M − 1 e g m ( x ) P(y=m\mid \mathbf{x})=\frac{e^{g_m(\mathbf{x})}}{1+\sum_{m=1}^{M-1}{e^{g_m(\mathbf{x})}}} P(y=m∣x)=1+∑m=1M−1egm(x)egm(x) -
在进行模型预测的时候,我们可以先选出这M-1个概率中的最大概率者,在用这个概率与阈值 α \alpha α 进行比较。
-
- 另一种是“一对其余”(one-vs-rest) :
- 算法主体思想:就是对每个类别都学习一个二分类模型,将这个类别与所有其余类别尽量分开,这样会生成与类别个数M相同个数的分类器,每个分类器都会输出一个概率,概率最高者“胜出”,并将这个类别的标签返回作为预测结果。
三、 作业
# 加载基础包
import pandas as pd
import numpy as np
import statsmodels.api as sm
from scipy import stats
from statsmodels.stats.anova import anova_lm
作业1——二分类:信贷风险评估
我们想知道银行贷款审批中是否存在种族歧视,这是一个非常典型的“推断”问题,于是可采用线性回归分类模型对该问题进行探究。本次习题使用数据loanapp.dta,所使用的变量解释如下:
因变量:
· approve:贷款是否被批准(0为不批准、1为批准)
自变量:
· white:种族哑变量(0为黑人,1为白人)
· obrat:债务占比
由于数据集含有缺失值,我们先去除含有缺失值的样本(非习题)
使用python进行实操并回答以下问题
(1):先考虑一个线性概率模型
a
p
p
r
o
v
e
=
β
0
+
β
1
w
h
i
t
e
+
u
approve = \beta_0+\beta_1white+u
approve=β0+β1white+u
如果存在种族歧视,那么
β
1
\beta_1
β1的符号应如何?
答:
原始模型为
E
(
approve
)
=
β
0
+
β
1
w
h
i
t
e
+
u
E(\text { approve})=\beta_{0}+\beta_{1} white+u
E( approve)=β0+β1white+u
则black回归函数为:
E
(
approve|black
)
=
β
0
E(\text { approve|black })=\beta_{0}
E( approve|black )=β0
white回归函数为:
E
(
approve|white
)
=
β
0
+
β
1
E(\text { approve|white })=\beta_{0}+\beta_{1}
E( approve|white )=β0+β1
那么,
β
1
\beta_{1}
β1就是
β
1
=
E
(
approve|white
)
−
E
(
approve|black
)
\beta_{1}=E(\text { approve|white })-E(\text { approve|black })
β1=E( approve|white )−E( approve|black )
如果存在种族歧视,即白人通过率高于黑人,那么
β
1
\beta_1
β1的符号应该是正号。
(2):用OLS估计上述模型,解释参数估计的意义,其显著性如何?在该模型下种族歧视的影响大吗?
loan=pd.read_stata('./data/loanapp.dta')
# 选取要用的变量组成新的数据集
loan=loan[["approve","white","hrat","obrat","loanprc","unem","male","married","dep","sch","cosign","chist","pubrec","mortlat1","mortlat2","vr"]]
# print(loan.dropna()) #去除含缺失值样本
loan.describe().transpose()
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| approve | 1989.0 | 0.877325 | 0.328145 | 0.000000 | 1.0 | 1.00 | 1.000000 | 1.000000 |
| white | 1989.0 | 0.845148 | 0.361850 | 0.000000 | 1.0 | 1.00 | 1.000000 | 1.000000 |
| hrat | 1989.0 | 24.790895 | 7.119463 | 1.000000 | 21.0 | 25.77 | 29.000000 | 72.000000 |
| obrat | 1989.0 | 32.389023 | 8.263029 | 0.000000 | 28.0 | 33.00 | 37.000000 | 95.000000 |
| loanprc | 1989.0 | 0.770640 | 0.189174 | 0.021053 | 0.7 | 0.80 | 0.898936 | 2.571429 |
| unem | 1989.0 | 3.882325 | 2.164120 | 1.800000 | 3.1 | 3.20 | 3.900000 | 10.600000 |
| male | 1974.0 | 0.813070 | 0.389954 | 0.000000 | 1.0 | 1.00 | 1.000000 | 1.000000 |
| married | 1986.0 | 0.658610 | 0.474296 | 0.000000 | 0.0 | 1.00 | 1.000000 | 1.000000 |
| dep | 1986.0 | 0.770896 | 1.104317 | 0.000000 | 0.0 | 0.00 | 1.000000 | 8.000000 |
| sch | 1989.0 | 0.771745 | 0.419810 | 0.000000 | 1.0 | 1.00 | 1.000000 | 1.000000 |
| cosign | 1989.0 | 0.028658 | 0.166883 | 0.000000 | 0.0 | 0.00 | 0.000000 | 1.000000 |
| chist | 1989.0 | 0.837607 | 0.368902 | 0.000000 | 1.0 | 1.00 | 1.000000 | 1.000000 |
| pubrec | 1989.0 | 0.068879 | 0.253313 | 0.000000 | 0.0 | 0.00 | 0.000000 | 1.000000 |
| mortlat1 | 1989.0 | 0.019105 | 0.136929 | 0.000000 | 0.0 | 0.00 | 0.000000 | 1.000000 |
| mortlat2 | 1989.0 | 0.010558 | 0.102234 | 0.000000 | 0.0 | 0.00 | 0.000000 | 1.000000 |
| vr | 1989.0 | 0.409754 | 0.491913 | 0.000000 | 0.0 | 0.00 | 1.000000 | 1.000000 |
loan_lm_ols=sm.formula.ols('approve~white+obrat',data=loan.dropna()).fit()
print(loan_lm_ols.summary())
OLS Regression Results
==============================================================================
Dep. Variable: approve R-squared: 0.074
Model: OLS Adj. R-squared: 0.073
Method: Least Squares F-statistic: 78.37
Date: Tue, 27 Sep 2022 Prob (F-statistic): 1.79e-33
Time: 14:22:09 Log-Likelihood: -532.13
No. Observations: 1971 AIC: 1070.
Df Residuals: 1968 BIC: 1087.
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.9140 0.035 26.131 0.000 0.845 0.983
white 0.1902 0.020 9.551 0.000 0.151 0.229
obrat -0.0061 0.001 -7.068 0.000 -0.008 -0.004
==============================================================================
Omnibus: 763.459 Durbin-Watson: 1.991
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2203.837
Skew: -2.085 Prob(JB): 0.00
Kurtosis: 6.074 Cond. No. 174.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
# F检验
loan_lm_ols_r=sm.formula.ols('approve~obrat',data=loan.dropna()).fit()
anova_lm(loan_lm_ols_r,loan_lm_ols)
| df_resid | ssr | df_diff | ss_diff | F | Pr(>F) | |
|---|---|---|---|---|---|---|
| 0 | 1969.0 | 207.201843 | 0.0 | NaN | NaN | NaN |
| 1 | 1968.0 | 198.022879 | 1.0 | 9.178964 | 91.222802 | 3.661402e-21 |
- t检验结果表明,变量 white 的系数估计值是显著的,但模型 R 2 R^2 R2仅为7%,模型拟合优度很低。
- F检验结果是非常显著的,即种族之间存在贷款通过差异。
(3):在上述模型中加入数据集中的其他所有自变量,此时white系数发生了什么变化?我们仍然可以认为存在黑人歧视现象吗?
loan_lm_ols_all=sm.formula.ols('approve~white+hrat+obrat+loanprc+unem+male+married+dep+sch+cosign+chist+pubrec+mortlat1+mortlat2+vr',data=loan.dropna()).fit()
print(loan_lm_ols_all.summary())
OLS Regression Results
==============================================================================
Dep. Variable: approve R-squared: 0.166
Model: OLS Adj. R-squared: 0.159
Method: Least Squares F-statistic: 25.86
Date: Tue, 27 Sep 2022 Prob (F-statistic): 1.84e-66
Time: 14:22:13 Log-Likelihood: -429.26
No. Observations: 1971 AIC: 890.5
Df Residuals: 1955 BIC: 979.9
Df Model: 15
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.9367 0.053 17.763 0.000 0.833 1.040
white 0.1288 0.020 6.529 0.000 0.090 0.168
hrat 0.0018 0.001 1.451 0.147 -0.001 0.004
obrat -0.0054 0.001 -4.930 0.000 -0.008 -0.003
loanprc -0.1473 0.038 -3.926 0.000 -0.221 -0.074
unem -0.0073 0.003 -2.282 0.023 -0.014 -0.001
male -0.0041 0.019 -0.220 0.826 -0.041 0.033
married 0.0458 0.016 2.810 0.005 0.014 0.078
dep -0.0068 0.007 -1.019 0.308 -0.020 0.006
sch 0.0018 0.017 0.105 0.916 -0.031 0.034
cosign 0.0098 0.041 0.238 0.812 -0.071 0.090
chist 0.1330 0.019 6.906 0.000 0.095 0.171
pubrec -0.2419 0.028 -8.571 0.000 -0.297 -0.187
mortlat1 -0.0573 0.050 -1.145 0.252 -0.155 0.041
mortlat2 -0.1137 0.067 -1.698 0.090 -0.245 0.018
vr -0.0314 0.014 -2.241 0.025 -0.059 -0.004
==============================================================================
Omnibus: 685.691 Durbin-Watson: 2.001
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1902.139
Skew: -1.855 Prob(JB): 0.00
Kurtosis: 6.066 Cond. No. 417.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
# F检验
loan_lm_ols_all_r=sm.formula.ols('approve~hrat+obrat+loanprc+unem+male+married+dep+sch+cosign+chist+pubrec+mortlat1+mortlat2+vr',data=loan.dropna()).fit()
anova_lm(loan_lm_ols_all_r,loan_lm_ols_all)
| df_resid | ssr | df_diff | ss_diff | F | Pr(>F) | |
|---|---|---|---|---|---|---|
| 0 | 1956.0 | 182.282812 | 0.0 | NaN | NaN | NaN |
| 1 | 1955.0 | 178.393534 | 1.0 | 3.889277 | 42.62227 | 8.438135e-11 |
加入所有变量后:
- t检验结果表明,变量 white 仍然是显著的,虽然整体模型的 R 2 R^2 R2变大,拟合优度变好,但white系数变小,对模型的影响程度变小。
- F检验结果是非常显著的,即种族之间存在贷款通过差异。
(4):允许种族效应与债务占比(obrat)有交互效应,请问交互效应显著吗?请解读这种交互效应。
对交互效应的分析过程如下:
原始模型为
E
(
approve
)
=
β
0
+
δ
0
w
h
i
t
e
+
β
1
o
b
r
a
t
E(\text { approve})=\beta_{0}+\delta_{0} white+\beta_{1} obrat
E( approve)=β0+δ0white+β1obrat
则black回归函数为:
E
(
approve|black
,
o
b
r
a
t
)
=
β
0
+
β
1
o
b
r
a
t
E(\text { approve|black }, obrat)=\beta_{0}+\beta_{1} obrat
E( approve|black ,obrat)=β0+β1obrat
white回归函数为:
E
(
approve|white
,
o
b
r
a
t
)
=
β
0
+
δ
0
+
β
1
o
b
r
a
t
E(\text { approve|white }, obrat)=\beta_{0}+\delta_{0}+\beta_{1} obrat
E( approve|white ,obrat)=β0+δ0+β1obrat
- 两者相差的数值处处为常数,它们的差本质上源于截距的不同。这两条回归线是平行的。
- 这两条回归线是平行的,即它们的斜率——债务占比(obrat) 对贷款是否通过 approve 的偏效应是恒定的,这意味着种族不会对债务占比的边际回报产生影响。
加入了交互项以后的模型:
approve
=
β
0
+
δ
0
white
+
β
1
obrat
+
δ
1
white
∗
obrat
+
u
\text { approve }=\beta_{0}+\delta_{0} \text { white }+\beta_{1} \text { obrat }+\delta_{1} \text { white } * \text { obrat }+u
approve =β0+δ0 white +β1 obrat +δ1 white ∗ obrat +u
于是,white与black的薪资差异如下
E
(
approve|black
,
o
b
r
a
t
)
=
β
0
+
β
1
o
b
r
a
t
E(\text { approve|black },obrat)=\beta_{0}+\beta_{1}obrat
E( approve|black ,obrat)=β0+β1obrat
E
(
approve|white
,
o
b
r
a
t
)
=
β
0
+
δ
0
+
(
β
1
+
δ
1
)
o
b
r
a
t
E(\text { approve|white },obrat)=\beta_{0}+\delta_{0}+\left(\beta_{1}+\delta_{1}\right) obrat
E( approve|white ,obrat)=β0+δ0+(β1+δ1)obrat
比起之前只有截距上的不同,这里两个回归函数的斜率也不同了。
对于这个模型,我们可以做两种假设检验:
1、检验black与white的边际债务回报是否相同。这等价于检验假设
H
0
:
δ
1
=
0
↔
H
1
:
δ
1
≠
0
H_{0}: \delta_{1}=0 \leftrightarrow H_{1}: \delta_{1} \neq 0
H0:δ1=0↔H1:δ1=0
2、检验black与white的贷款通过是否存在种族差异。这等价于检验假设
H
0
:
δ
0
=
δ
1
=
0
↔
H
1
:
∃
δ
j
≠
0
,
j
=
0
,
1
H_{0}: \delta_{0}=\delta_{1}=0 \leftrightarrow H_{1}: \exists \delta_{j} \neq 0, j=0,1
H0:δ0=δ1=0↔H1:∃δj=0,j=0,1
显然,对于第一个问题,我们可以使用t检验;对于第二个问题,我们可以使用F检验。
loan_lm_ols_1=sm.formula.ols('approve~white+obrat+I(white*obrat)',data=loan.dropna()).fit()
print(loan_lm_ols_1.summary())
OLS Regression Results
==============================================================================
Dep. Variable: approve R-squared: 0.080
Model: OLS Adj. R-squared: 0.078
Method: Least Squares F-statistic: 56.85
Date: Tue, 27 Sep 2022 Prob (F-statistic): 3.06e-35
Time: 14:29:50 Log-Likelihood: -525.71
No. Observations: 1971 AIC: 1059.
Df Residuals: 1967 BIC: 1082.
Df Model: 3
Covariance Type: nonrobust
====================================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------------
Intercept 1.1625 0.078 14.991 0.000 1.010 1.315
white -0.1010 0.084 -1.209 0.227 -0.265 0.063
obrat -0.0134 0.002 -6.095 0.000 -0.018 -0.009
I(white * obrat) 0.0086 0.002 3.588 0.000 0.004 0.013
==============================================================================
Omnibus: 778.161 Durbin-Watson: 1.998
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2321.458
Skew: -2.106 Prob(JB): 0.00
Kurtosis: 6.244 Cond. No. 695.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
# F检验
loan_lm_ols_r=sm.formula.ols('approve~obrat',data=loan.dropna()).fit()
anova_lm(loan_lm_ols_r,loan_lm_ols_1)
| df_resid | ssr | df_diff | ss_diff | F | Pr(>F) | |
|---|---|---|---|---|---|---|
| 0 | 1969.0 | 207.201843 | 0.0 | NaN | NaN | NaN |
| 1 | 1967.0 | 196.735328 | 2.0 | 10.466515 | 52.323178 | 7.247283e-23 |
- t检验结果表明,种族之间债务占比边际回报相等的假设是可以被拒绝的,即不同种族的边际回报可以是不相等的;
- F检验结果是非常显著的,即种族之间存在贷款通过差异。这可能说明引起种族贷款通过率不等的原因可能来自债务占比。
(5):使用logit模型与probit模型重新(3)中的模型,观察变量系数及其显著性的变化。
# logit 模型
loan_logit=sm.formula.logit('approve~white+hrat+obrat+loanprc+unem+male+married+dep+sch+cosign+chist+pubrec+mortlat1+mortlat2+vr',data=loan.dropna()).fit()
print(loan_logit.summary())
Optimization terminated successfully.
Current function value: 0.304666
Iterations 7
Logit Regression Results
==============================================================================
Dep. Variable: approve No. Observations: 1971
Model: Logit Df Residuals: 1955
Method: MLE Df Model: 15
Date: Mon, 26 Sep 2022 Pseudo R-squ.: 0.1863
Time: 17:40:36 Log-Likelihood: -600.50
converged: True LL-Null: -737.98
Covariance Type: nonrobust LLR p-value: 8.693e-50
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 3.8017 0.595 6.393 0.000 2.636 4.967
white 0.9378 0.173 5.424 0.000 0.599 1.277
hrat 0.0133 0.013 1.030 0.303 -0.012 0.039
obrat -0.0530 0.011 -4.701 0.000 -0.075 -0.031
loanprc -1.9050 0.460 -4.137 0.000 -2.807 -1.002
unem -0.0666 0.033 -2.029 0.042 -0.131 -0.002
male -0.0664 0.206 -0.322 0.748 -0.471 0.338
married 0.5033 0.178 2.827 0.005 0.154 0.852
dep -0.0907 0.073 -1.237 0.216 -0.234 0.053
sch 0.0412 0.178 0.231 0.817 -0.308 0.391
cosign 0.1321 0.446 0.296 0.767 -0.742 1.006
chist 1.0666 0.171 6.230 0.000 0.731 1.402
pubrec -1.3407 0.217 -6.168 0.000 -1.767 -0.915
mortlat1 -0.3099 0.464 -0.669 0.504 -1.218 0.599
mortlat2 -0.8947 0.569 -1.574 0.116 -2.009 0.220
vr -0.3498 0.154 -2.276 0.023 -0.651 -0.049
==============================================================================
# probit 模型
loan_probit=sm.formula.probit('approve~white+hrat+obrat+loanprc+unem+male+married+dep+sch+cosign+chist+pubrec+mortlat1+mortlat2+vr',data=loan.dropna()).fit()
print(loan_probit.summary())
Optimization terminated successfully.
Current function value: 0.304551
Iterations 6
Probit Regression Results
==============================================================================
Dep. Variable: approve No. Observations: 1971
Model: Probit Df Residuals: 1955
Method: MLE Df Model: 15
Date: Mon, 26 Sep 2022 Pseudo R-squ.: 0.1866
Time: 17:43:41 Log-Likelihood: -600.27
converged: True LL-Null: -737.98
Covariance Type: nonrobust LLR p-value: 7.014e-50
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 2.0623 0.313 6.585 0.000 1.449 2.676
white 0.5203 0.097 5.366 0.000 0.330 0.710
hrat 0.0079 0.007 1.131 0.258 -0.006 0.022
obrat -0.0277 0.006 -4.578 0.000 -0.040 -0.016
loanprc -1.0120 0.237 -4.266 0.000 -1.477 -0.547
unem -0.0367 0.017 -2.099 0.036 -0.071 -0.002
male -0.0370 0.110 -0.337 0.736 -0.252 0.178
married 0.2657 0.094 2.820 0.005 0.081 0.450
dep -0.0496 0.039 -1.269 0.204 -0.126 0.027
sch 0.0146 0.096 0.153 0.879 -0.173 0.202
cosign 0.0861 0.246 0.350 0.726 -0.396 0.568
chist 0.5853 0.096 6.098 0.000 0.397 0.773
pubrec -0.7787 0.126 -6.165 0.000 -1.026 -0.531
mortlat1 -0.1876 0.253 -0.741 0.459 -0.684 0.308
mortlat2 -0.4944 0.327 -1.514 0.130 -1.134 0.146
vr -0.2011 0.081 -2.467 0.014 -0.361 -0.041
==============================================================================
- 使用了probit和logit模型以后,t检验下, white 和 obrat 依然是显著的。且两个变量的系数绝对值都变大了,obrat的系数增大了一个量级,即对模型的影响程度增大。整体模型的R-Square也增大一个量级,拟合优度有改进。
作业2——多分类:鸢尾花分类问题
鸢尾花分类问题是经典的多分类问题,我们使用sklearn的logisticRegression求解该问题。
# 加载基础包
import mglearn
import matplotlib.pyplot as plt
from IPython.display import display
# 下载数据集
from sklearn.datasets import load_iris
iris_dataset=load_iris()
# 提取数据集中的自变量集与标签集
iris_data=iris_dataset['data'] # 自变量
iris_target=iris_dataset['target'] # 标签集
print(iris_dataset['feature_names'])
print(iris_dataset['target_names'])
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
['setosa' 'versicolor' 'virginica']
使用python进行实操并回答以下问题
(1):将原数据集划分为训练集与测试集,两者样本比例为3:1。
# 加载函数
from sklearn.model_selection import train_test_split
# 数据集切分
X_train,X_test,y_train,y_test=train_test_split(iris_data,iris_target,test_size=0.25,random_state=0) # test_size为测试集数据量占原始数据的比例
print('train_size',round(len(X_train)/len(iris_data),2))
print('test_size',round(len(X_test)/len(iris_data),2))
print('test_size',round(len(X_train)/len(X_test),2))
train_size 0.75
test_size 0.25
test_size 2.95
(2):使用训练集数据训练logistic回归模型,并分别对训练集与测试集数据进行预测,并将预测的结果分别储存在两个自定义的变量中。
from sklearn.linear_model import LogisticRegression
# 使用训练集进行训练
logit_multi=LogisticRegression(multi_class='multinomial').fit(X_train,y_train)
# 使用训练集进行预测
y_train_pred=logit_multi.predict(X_train)
# 使用测试集进行预测
y_pred=logit_multi.predict(X_test)
# 查看预测结果
print('训练集预测结果:',y_train_pred)
# 查看预测结果
print('测试集预测结果:',y_pred)
训练集预测结果: [1 1 2 0 2 0 0 1 2 2 2 2 1 2 1 1 2 2 2 2 1 2 1 0 2 1 1 1 1 2 0 0 2 1 0 0 1
0 2 1 0 1 2 1 0 2 2 2 2 0 0 2 2 0 2 0 2 2 0 0 2 0 0 0 1 2 2 0 0 0 1 1 0 0
1 0 2 1 2 1 0 2 0 2 0 0 2 0 2 1 1 1 2 2 1 2 0 1 2 2 0 1 1 2 1 0 0 0 2 1 2
0]
测试集预测结果: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]
E:\ProgramData\Anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
(3):使用函数接口计算出:模型对训练集数据的分类正确率、模型对测试集数据的分类正确率,比较它们孰高孰低,并思考为什么会有这样的差异。
# 查看分类精度
print('测试集分类精度',logit_multi.score(X_test,y_test)) # 传入需要进行预测数据集自变量与真实标签集
# 查看分类精度
print('测试集分类精度',logit_multi.score(X_train,y_train)) # 传入需要进行预测数据集自变量与真实标签集
测试集分类精度 0.9736842105263158
测试集分类精度 0.9821428571428571
- 分类精度方面,训练集高于测试集。
- 可能原因:模型是由训练集数据训练的;相对于训练集,测试集会存在一定的数据变异性,而对这部分变异性的学习并没有在模型中体现出来。
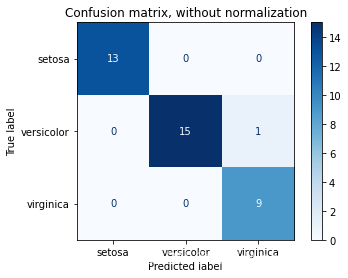
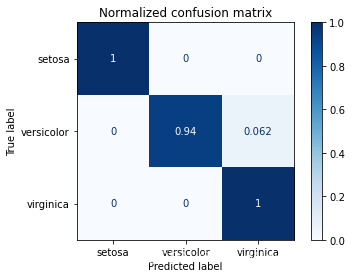
(4):给出测试集数据的混淆矩阵以及精确率、召回率、f分数的综合报告。
- a. 混淆矩阵结果
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
# 混淆矩阵
# display(confusion_matrix(y_test,y_pred))
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
from sklearn.metrics import ConfusionMatrixDisplay
# Run classifier, using a model that is too regularized (C too low) to see
# the impact on the results
# classifier = svm.SVC(kernel="linear", C=0.01).fit(X_train, y_train)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
titles_options = [
("Confusion matrix, without normalization", None),
("Normalized confusion matrix", "true"),
]
for title, normalize in titles_options:
disp = ConfusionMatrixDisplay.from_estimator(
logit_multi,
X_test,
y_test,
display_labels=iris_dataset['target_names'],
cmap=plt.cm.Blues,
normalize=normalize,
)
disp.ax_.set_title(title)
print(title)
print(disp.confusion_matrix)
plt.show()
Confusion matrix, without normalization
[[13 0 0]
[ 0 15 1]
[ 0 0 9]]
Normalized confusion matrix
[[1. 0. 0. ]
[0. 0.94 0.06]
[0. 0. 1. ]]
- b.精确率、召回率、f分数的综合报告
# 综合指标
print(classification_report(y_test,y_pred))
precision recall f1-score support
0 1.00 1.00 1.00 13
1 1.00 0.94 0.97 16
2 0.90 1.00 0.95 9
accuracy 0.97 38
macro avg 0.97 0.98 0.97 38
weighted avg 0.98 0.97 0.97 38
心有猛虎 细嗅蔷薇。















 918
918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









