







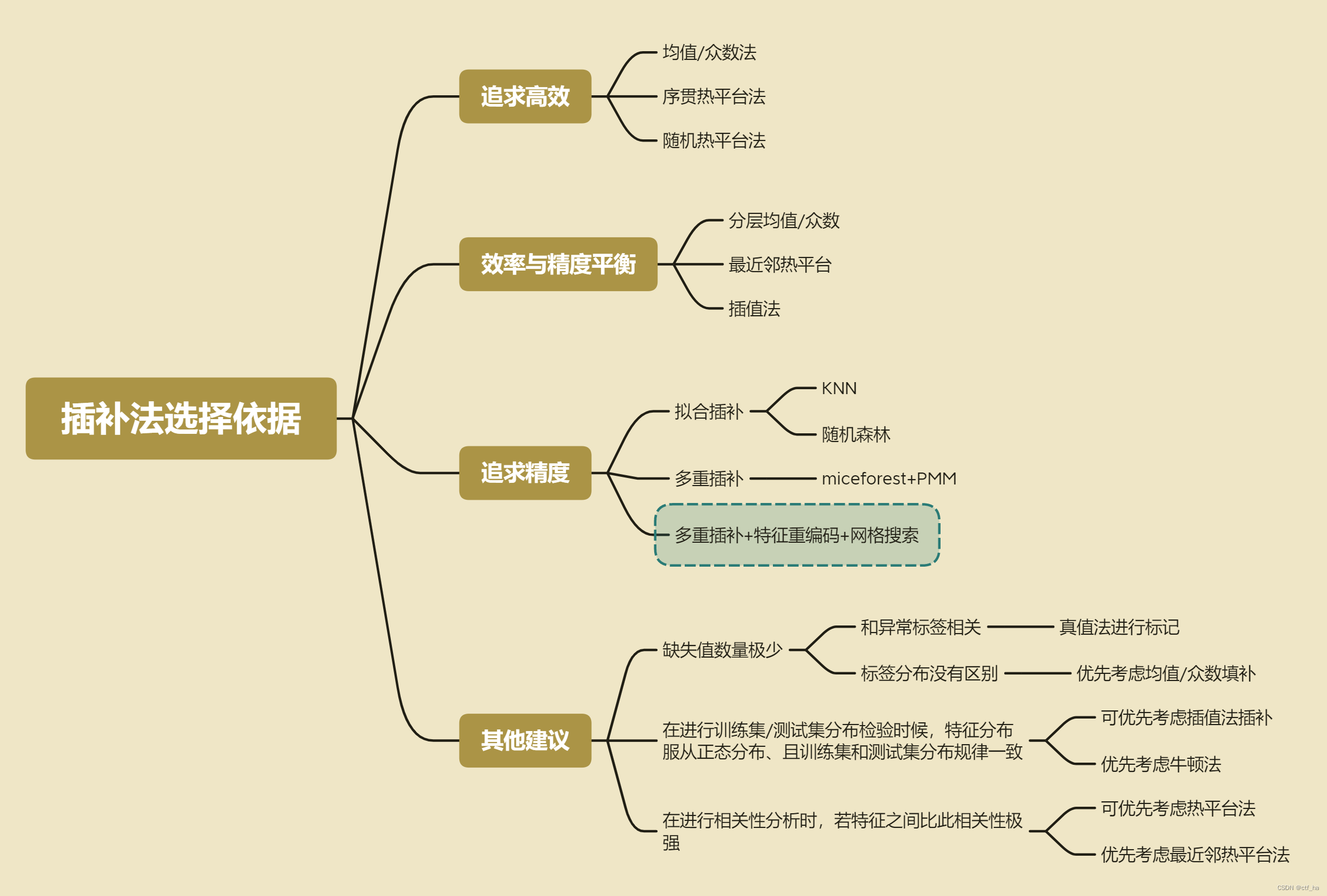
一、数据缺失情况分类
数据缺失是一种非常常见的问题,由于数据的缺失,可能导致正负样本标签的颠倒,数据缺失类型可以总结为三种:
-
完全随机缺失(missing completely at random,MCAR):指的是数据的缺失是完全随机的,不依赖于任何不完全变量或完全变量,不影响样本的无偏性,如家庭地址缺失
-
随机缺失(missing at random,MAR):指的是数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量,如财务数据缺失情况与企业的大小有关
-
非随机缺失(missing not at random,MNAR):指的是数据的缺失与不完全变量自身的取值有关,如高收入人群不愿意提供家庭收入
针对特征缺失,一般处理方法可以分为三种:
-
忽略:针对获取的数据,不做处理,使用获取到的默认值
-
填充:对缺失值进行一定的推断填充
-
丢弃:将含有缺失的样本或者特征丢弃

从训练数据和实际应用的推理数据上划分,可能存在的情况是:
-
训练数据完备,实际的推理数据存在缺失:一般不存在,如果已知推理过程存在缺失值,在训练过程会增加缺失值情况
-
训练数据存在缺失,实际的推理数据是完备的
-
训练数据和推理数据都是存在缺失的

备注:It is important to differentiate between random and systematic missing values. Random missing values are assumed to occur for each analysis subject with the same probability irrespective of the other variables. Systematic missing values are not assumed to occur for each analysis subject with the same probability.
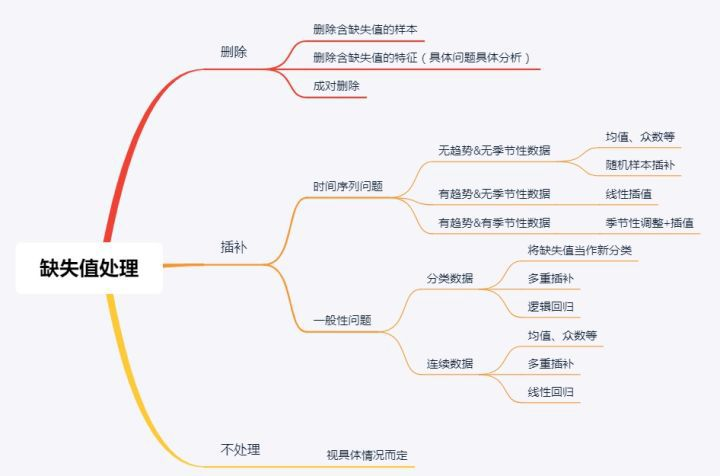
二、缺失值一般的处理方法

2.1 删除样本数据
即将含有缺失值的样本删除掉即可,是对缺失值处理的最原始的办法。如果数据缺失问题可以通过简单的删除小部分样本来达到目标,那么这个方法是最有效的。但是当缺失的样本占比比较高时,则是不合适的。
2.2 特殊值填充
用一个特征的字符串进行表示,比如「unknown」、「null」等,这和原来的缺失值的意思还是有一点差别的。在这里unknown、null可以当做一种取值的可能性。
2.3 虚拟变量
2.4 单变量特征处理
-
平均值填充:对于数字类型的变量,可以使用没有缺失值的一些信息进行估计,使用用平均值进行的估计称为平均值填充
-
中位数填充:和平均值填充类似,使用中位数填充的估计称为中位数填充
-
众数填充:对于分类变量可以使用众数来进行填充
-
范围内随机填充:即使用某个范围内的值进行随机填充
-
均值加减标准差:即划分一个置信区间,在置信区间内随机取值进行填充
-
Q2、Q3:即使用数据的分位数范围内的值进行随机填充
2.5 多元特征处理
2.5.1 热卡填补
对于一条包含缺失值的样本,热卡填充法是在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。
其优点为:该方法概念上很简单,且利用了数据间的关系来进行空值估计,缺点:在于难以定义相似标准,主观因素较多。
2.5.2 K近邻
先根据某种距离度量方式来确定距离具有缺失数据样本最近的 个样本,将这 个值加权平均来估计该样本的缺失数据。
这个方法与热卡填充有些相似,如果最近邻法仅仅考虑最近的一个样本,那么就会退化成热卡填充。不过最近邻法和热卡填充面临同样的问题,如何衡量相似度。
2.5.3 回归拟合
基于完整的数据集,建立回归方程,或利用机器学习中的回归算法。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关时会导致有偏差的估计。
2.5.4 极大似然估计
在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,那么通过观测数据的边际分布可以对未知参数进行极大似然估计(Little and Rubin)。这种方法也被称为忽略缺失值的极大似然估计,对于极大似然的参数估计实际中常采用的计算方法是期望值最大化(Expectation Maximization,EM)。该方法比删除个案和单值插补更有吸引力,它一个重要前提:适用于大样本。有效样本的数量足够以保证ML估计值是渐近无偏的并服从正态分布。但是这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。
2.5.5 基于决策树
通过寻找属性间的关系来对遗失值填充。它寻找之间具有最大相关性的两个属性,其中没有遗失值的一个称为代理属性,另一个称为原始属性,用代理属性决定原始属性中的遗失值。这种基于规则归纳的方法只能处理基数较小的名词型属性。
2.5.6 基于随机森林
随机森林是由很多个决策树组成的,首先要建立Bootstrap数据集,即从原始的数据中有放回地随机选取一些,作为新的数据集,新数据集中会存在重复的数据,然后对每个数据集构造一个决策树,但是不是直接用所有的特征来建造决策树,而是对于每一步,都从中随机的选择一些特征,来构造决策树,这样我们就构建了多个决策树,组成随机森林,把数据输入各个决策树中,看一看每个决策树的判断结果,统计一下所有决策树的预测结果,Bagging整合结果,得到最终输出。
那么,随机森林中如何处理缺失值呢?根据随机森林创建和训练的特点,随机森林对缺失值的处理还是比较特殊的。首先,给缺失值预设一些估计值,比如数值型特征,选择其余数据的中位数或众数作为当前的估计值,然后,根据估计的数值,建立随机森林,把所有的数据放进随机森林里面跑一遍。记录每一组数据在决策树中一步一步分类的路径,然后来判断哪组数据和缺失数据路径最相似,引入一个相似度矩阵,来记录数据之间的相似度,比如有N组数据,相似度矩阵大小就是N*N,如果缺失值是类别变量,通过权重投票得到新估计值,如果是数值型变量,通过加权平均得到新的估计值,如此迭代,直到得到稳定的估计值。
其实,该缺失值填补过程类似于推荐系统中采用协同过滤进行评分预测,先计算缺失特征与其他特征的相似度,再加权得到缺失值的估计,而随机森林中计算相似度的方法(数据在决策树中一步一步分类的路径)乃其独特之处。
2.5.7 多重插补
多值插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
多重插补方法分为三个步骤:
-
1.为每个空值产生一套可能的插补值,这些值反映了无响应模型的不确定性;每个值都可以被用来插补数据集中的缺失值,产生若干个完整数据集合
-
2.每个插补数据集合都用针对完整数据集的统计方法进行统计分析
-
3.对来自各个插补数据集的结果,根据评分函数进行选择,产生最终的插补值
假设一组数据,包括三个变量 ,,,它们的联合分布为正态分布,将这组数据处理成三组, 组保持原始数据, 组仅缺失 , 组缺失 和 。在多值插补时,对 组将不进行任何处理,对 组产生 的一组估计值(作 关于 , 的回归),对 组作产生 和 的一组成对估计值(作, 关于 的回归)。
当用多值插补时,对 组将不进行处理,对 、 组将完整的样本随机抽取形成为 组( 为可选择的 组插补值),每组个数只要能够有效估计参数就可以了。对存在缺失值的属性的分布作出估计,然后基于这 组观测值,对于这 组样本分别产生关于参数的 组估计值,给出相应的预测即可,这时采用的估计方法为极大似然法,在计算机中具体的实现算法为期望最大化法(EM)。对 组估计出一组 的值,对 将利用 它们的联合分布为正态分布这一前提,估计出一组(,)。
上例中假定了 的联合分布为正态分布。这个假设是人为的,但是已经通过验证(Graham和Schafer于1999),非正态联合分布的变量,在这个假定下仍然可以估计到很接近真实值的结果。
多重插补和贝叶斯估计的思想是一致的,但是多重插补弥补了贝叶斯估计的几个不足。
-
贝叶斯估计以极大似然的方法估计,极大似然的方法要求模型的形式必须准确,如果参数形式不正确,将得到错误得结论,即先验分布将影响后验分布的准确性。而多重插补所依据的是大样本渐近完整的数据的理论,在数据挖掘中的数据量都很大,先验分布将极小的影响结果,所以先验分布的对结果的影响不大。
-
贝叶斯估计仅要求知道未知参数的先验分布,没有利用与参数的关系。而多重插补对参数的联合分布作出了估计,利用了参数间的相互关系。
2.6 人工填写
大数据场景下的智障操作方式。
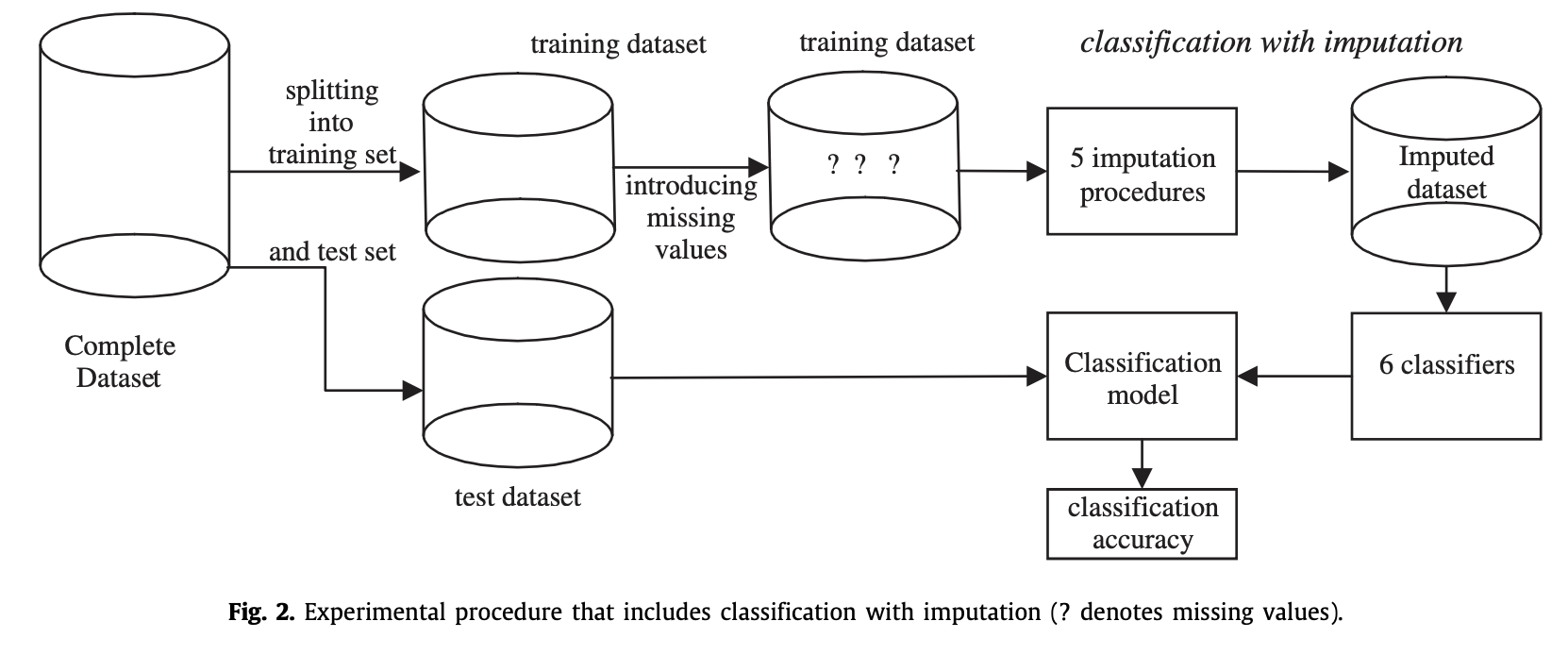
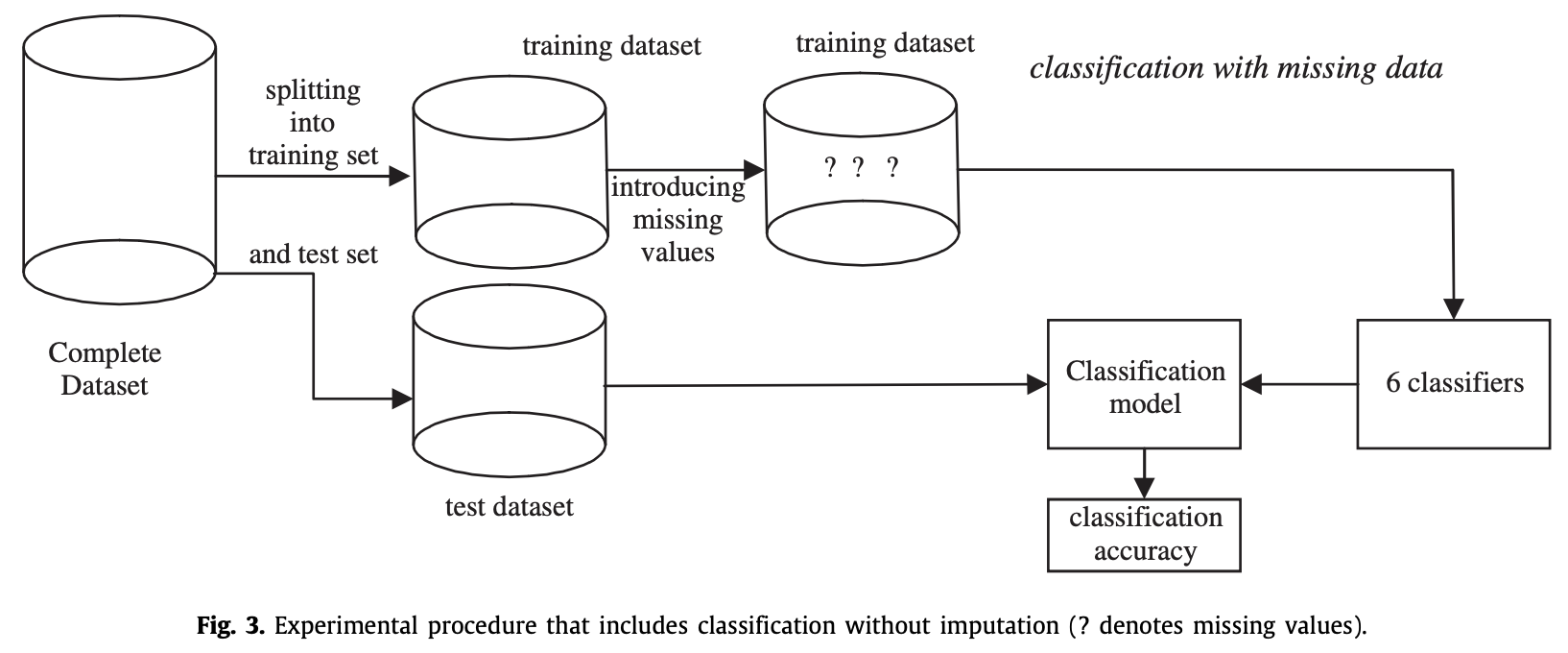
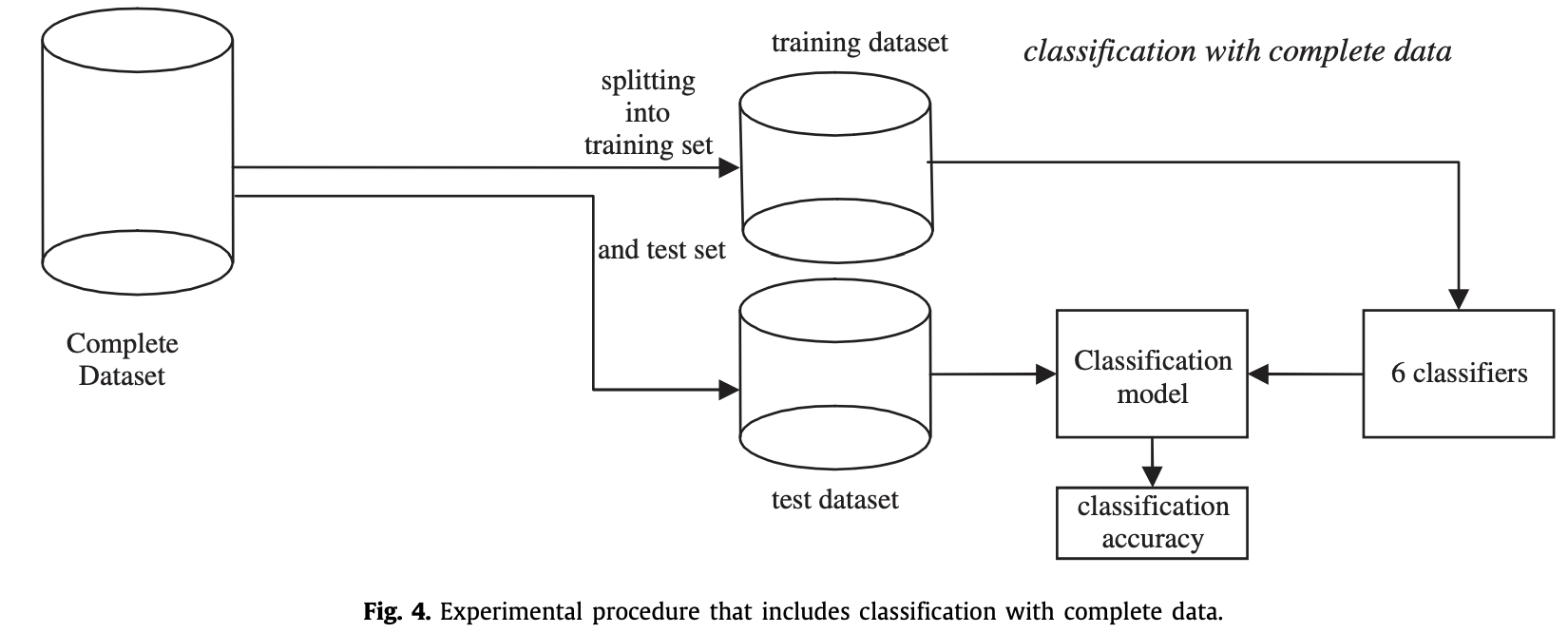
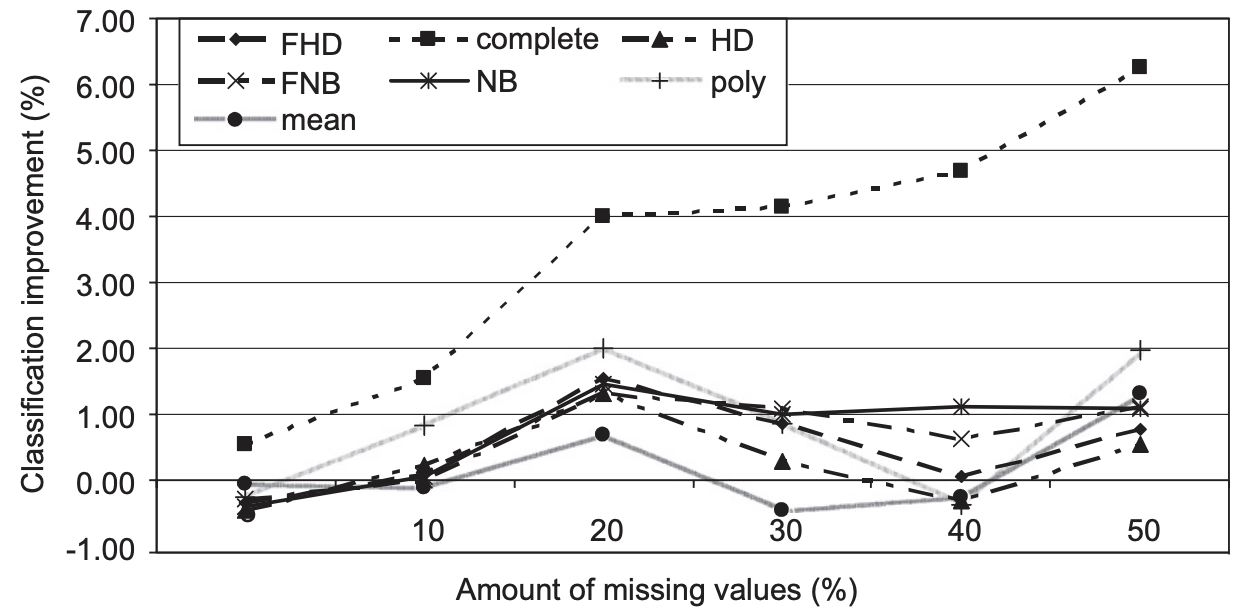
参考论文
三、特征
在数据中,包含不同的特征类型,常见的如下:
-
类别特征:即特征的属性值是一个有限的集合,比如用户性别、事物的类别、事物的ID编码类特征等
-
连续特征:即用户行为、类别、组合特征之类的统计值,比如用户观看的视频部数、某类别下事物的个数等
-
时间序列特征:即和时间相关的特征,比如用户来访时间、用户停留时长、当前时间等。
-
组合特征:即多种类别的组合特征,比如用户在某个类别下的行为统计特征、当天内事物被访问次数特征等
-
文本特征:即和文本相关的特征,比如评论数据、商品描述、新闻内容等。
不同类型的特征发生缺失时候,处理方法也一般不同:
-
连续的特征
-
缺失比例比较严重 可以考虑舍弃
-
可以考虑使用平均值 中位数 分位数填充
-
算法预测 (利用样本中的其它特征作为 特征值,有缺失的特征作为目标值)
-
类别的特征
-
缺失比例比较严重 可以考虑舍弃
-
把缺失作为单独的分类, 如果之前的数据只有两个分类,那么把缺失考虑进来就变成3个分类
-
算法预测 利用算法预测缺失值 其它特征和要预测的特征之间是否有联系 样本数据是否足够 利用算法预测缺失值会引入噪声
-
时序的特征
-
缺失比例比较严重 可以考虑舍弃
-
根据时序,进行推断,例如季节周期性等
四、什么样的模型对缺失值更敏感?
有一些经验法则供参考:
-
树模型对于缺失值的敏感度较低,大部分时候可以在数据有缺失时使用。
-
涉及到距离度量(distance measurement)时,如计算两个点之间的距离,缺失数据就变得比较重要。因为涉及到“距离”这个概念,那么缺失值处理不当就会导致效果很差,如K近邻算法(KNN)和支持向量机(SVM)。
-
线性模型的代价函数(loss function)往往涉及到距离(distance)的计算,计算预测值和真实值之间的差别,这容易导致对缺失值敏感。
-
神经网络的鲁棒性强,对于缺失数据不是非常敏感,但一般没有那么多数据可供使用。
-
贝叶斯模型对于缺失数据也比较稳定,数据量很小的时候首推贝叶斯模型。
总结来看,对于有缺失值的数据缺失值处理:
-
数据量很小,用朴素贝叶斯
-
数据量适中或者较大,用树模型,优先 xgboost
-
数据量较大,也可以用神经网络
-
避免使用距离度量相关的模型,如KNN和SVM
















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











