







我是芝士AI吃鱼,原创 NLP、LLM、超长文知识分享
热爱分享前沿技术知识,寻找志同道合小伙伴
公众号 :芝士AI吃鱼
1、引言
大型语言模型(LLMs)在近年来取得了巨大的成功,展现出惊人的能力。然而,随着模型规模的不断增大,LLMs的训练和推理成本也在急剧上升。如何在保持或提升性能的同时降低成本,成为了当前LLM研究的一个重要方向。
在这篇技术博客中,我们将详细介绍一种名为Memory3的创新模型,它通过引入显式记忆机制来优化知识存储,从而大幅提高模型效率。Memory3的核心思想是:
- 将部分知识从模型参数外化到显式记忆中,降低模型参数量和训练成本。
- 设计高效的显式记忆读写机制,在推理时动态调用所需知识,避免知识遍历问题。
Memory3模型的主要贡献包括:
- 提出了记忆电路理论,为知识外化提供了理论支持。
- 设计了高效的显式记忆机制,包括记忆稀疏化、并行位置编码等技术。
- 提出了两阶段预训练方案,有效促进记忆形成。
- 在多项任务上超越了更大规模的模型,同时保持较快的推理速度。
2、理论基础
Memory3模型的核心创新在于引入显式记忆机制,为此,研究团队提出了一套完整的理论框架,包括知识和记忆的定义、记忆电路理论、以及可分离知识和可模仿知识的概念。这些理论为知识外化和显式记忆机制提供了坚实的基础。
2.1 知识和记忆的定义
在Memory3的理论框架中,知识被定义为LLM计算图中的一个电路。具体来说:
- 计算图:
- 节点:所有注意力层和MLP层的隐藏向量
- 边:这些层内的所有激活函数
- 电路:
- 计算图中同态子图的等价类
- 具有非可忽略边权重
- 具有可解释的输入-输出关系
- 知识:
- 特定知识:输入具有可解释含义,输出基本固定
- 抽象知识:其他情况
这种定义将知识与LLM的内部计算机制直接关联,为后续的知识外化奠定了基础。
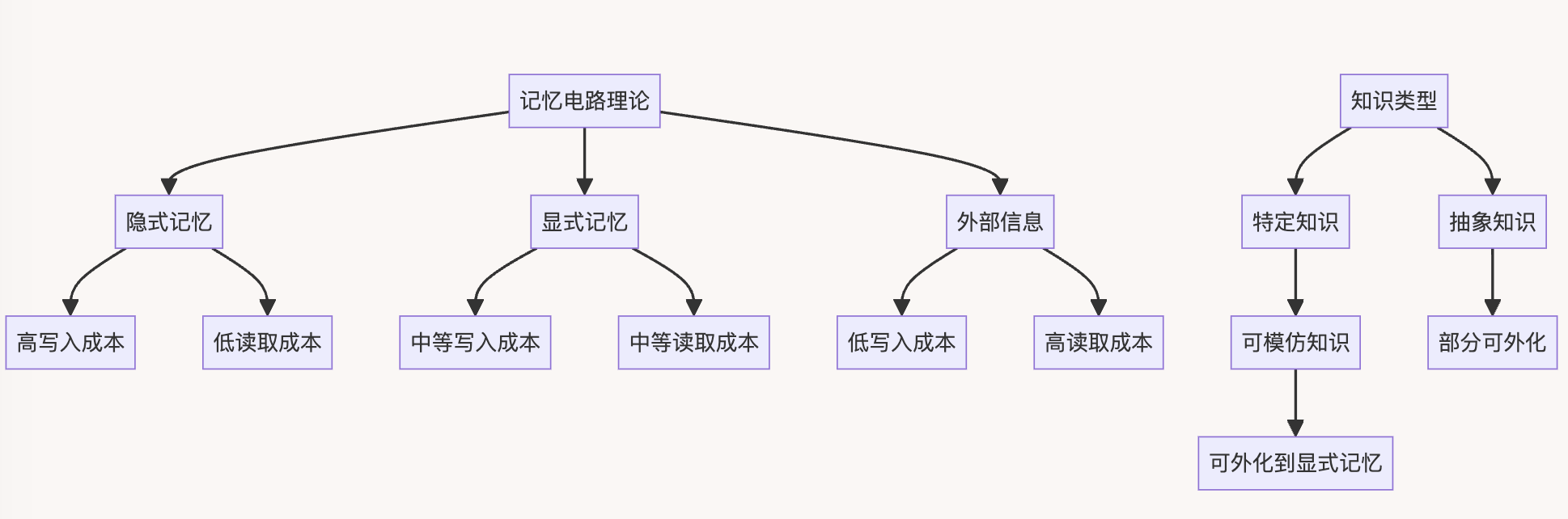
2.2 记忆电路理论
记忆电路理论是Memory3模型的核心理论基础,它定义了不同类型的记忆及其特性:
- 隐式记忆(模型参数):
- 写入成本高,读取成本低
- 适合存储频繁使用的知识
- 显式记忆(Memory3引入):
- 写入和读取成本适中
- 适合存储使用频率中等的知识
- 外部信息(RAG中的文本检索):
- 写入成本低,读取成本高
- 适合存储很少使用的知识
这种记忆层次结构类似于人脑的记忆机制,为LLM提供了更灵活和高效的知识存储方案。
2.3 可分离知识和可模仿知识
为了确定哪些知识可以外化到显式记忆中,研究团队引入了可分离知识和可模仿知识的概念:
- 可分离知识:
- 定义:存在另一个LLM M,在没有该知识时无法高概率生成正确输出,但在给定特定前缀后可以高概率生成正确输出
- 特点:可以通过检索示例或抽象描述来激活
- 可模仿知识:
- 定义:任何该知识的实现都可以作为激活前缀
- 特点:是可分离知识的一个子集
研究发现,所有特定知识都是可模仿的,因此可以被外化到显式记忆中。这一发现为Memory3模型的设计提供了理论依据。
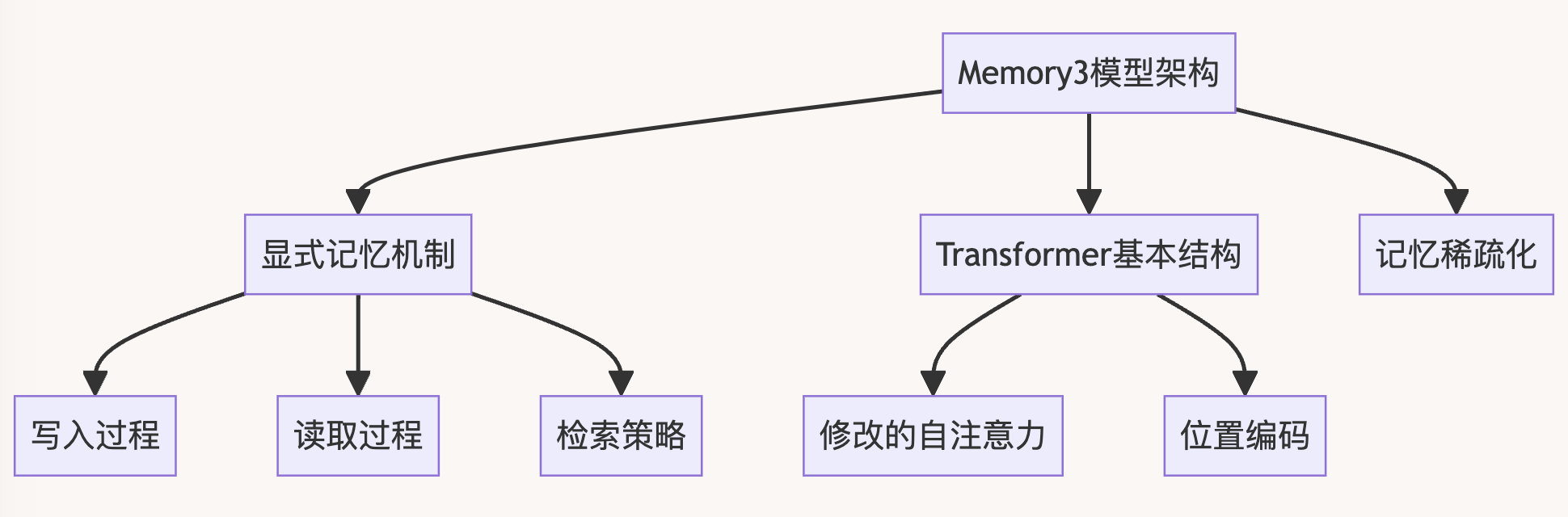
3、Memory3模型架构
基于前面介绍的理论基础,Memory3模型设计了一套创新的架构,其核心是显式记忆机制。这一章节将详细介绍Memory3的模型结构、显式记忆机制的实现,以及记忆稀疏化和存储方法。
3.1 显式记忆机制
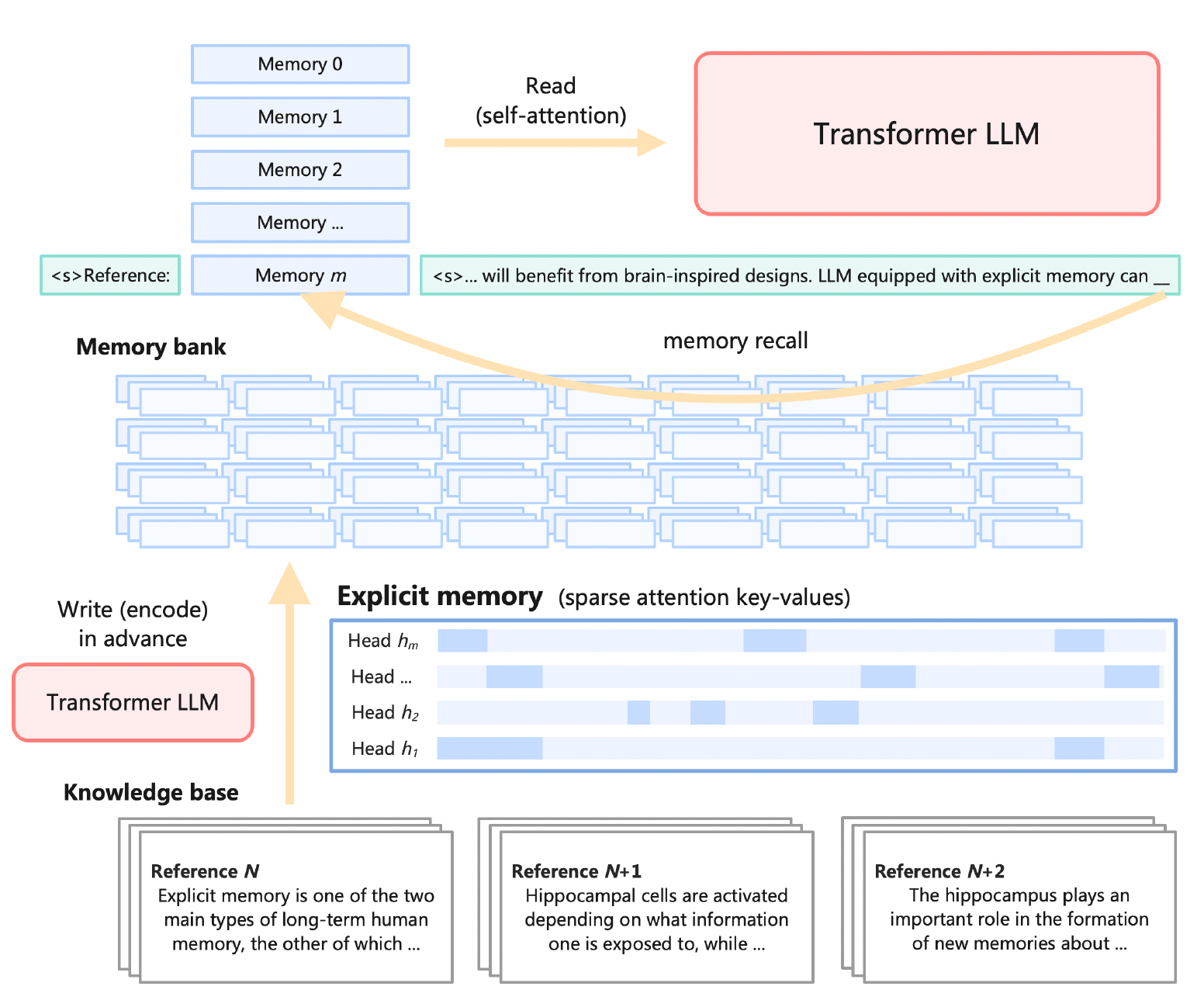
Memory3的显式记忆机制设计目标是实现适中的写入和读取成本,同时尽可能减少对现有Transformer架构的修改。其主要特点包括:
- 写入过程:
- 在推理前,将每个参考文本转换为显式记忆
- 显式记忆是从自注意力层的key-value向量中选择得到
- 每个参考文本独立处理,避免长上下文注意力计算
- 读取过程:
- 在推理时,从存储设备加载检索到的显式记忆
- 将显式记忆与常规上下文key-value向量连接,通过自注意力层读取
- 每个记忆只包含少量key-value,大幅减少额外计算和存储需求
- 检索频率:
- 每生成64个token,丢弃当前记忆,检索5个新记忆
- 处理prompt时,每64个token检索5个记忆
- 检索方法:
- 使用BGE-M3多语言BERT模型进行向量嵌入
- 采用FAISS进行向量索引和检索
def memory_retrieval(query_chunk):
# 使用BGE-M3模型进行向量嵌入
query_embedding = bge_m3_model.encode(query_chunk)
# 使用FAISS检索最相关的5个记忆
_, memory_ids = faiss_index.search(query_embedding, k=5)
# 从存储设备加载显式记忆
explicit_memories = load_memories(memory_ids)
return explicit_memories
def memory_augmented_generation(input_text):
tokens = tokenize(input_text)
generated_tokens = []
for i in range(0, len(tokens), 64):
chunk = tokens[i:i+64]
memories = memory_retrieval(chunk)
# 将显式记忆与上下文连接,进行生成
output = generate_with_memories(chunk, memories)
generated_tokens.extend(output)
return detokenize(generated_tokens)
每64个token进行一次记忆检索,然后将检索到的显式记忆与当前上下文结合进行生成。
3.2 模型结构
Memory3模型的基本结构仍然是Transformer,但在自注意力机制上进行了修改以支持显式记忆。主要特点包括:
- 参数配置:
- Transformer块数: L = 44
- 查询头数: H = 40
- Key-Value头数: H_kv = 8 (使用分组查询注意力, GQA)
- 头维度: d_h = 80
- 隐藏维度: d = H * d_h = 3200
- MLP宽度: W = d = 3200
- 词汇表大小: n_vocab = 60416
- 记忆层数: L_mem = 22 (前半部分层为记忆层)
- 注意力计算:
对于每个记忆头h在层l,其输出Y^l,h计算如下:
Y l , h i = softmax ( ( X l , h i W l , h Q ) ⋅ concat ( K l , h 0 , … , K l , h 4 , X l , h [ : i ] W l , h K ) T d h ) ⋅ concat ( V l , h 0 , … , V l , h 4 , X l , h [ : i ] W l , h V ) W l , h O Y^{l,h_i} = \text{softmax}\left(\frac{(X^{l,h_i} W^{l,h_Q}) \cdot \text{concat}(K^{l,h_0}, \ldots, K^{l,h_4}, X^{l,h_{[:i]}} W^{l,h_K})^T}{\sqrt{d_h}}\right) \cdot \text{concat}(V^{l,h_0}, \ldots, V^{l,h_4}, X^{l,h_{[:i]}} W^{l,h_V}) W^{l,h_O} Yl,hi=softmax(dh(Xl,hiWl,hQ)⋅concat(Kl,h0,…,Kl,h4,Xl,h[:i]Wl,hK)T)⋅concat(Vl,h0,…,Vl,h4,Xl,h[:i]Wl,hV)Wl,hO
其中Kl,h_j和Vl,h_j是显式记忆的key和value。
- 位置编码:
- 采用旋转位置编码(RoPE)
- 所有显式记忆使用并行位置编码,位置都在0-127范围内
- 优化设计:
- 仅在前半部分层使用显式记忆
- 使用分组查询注意力(GQA)减少key-value头数
- 对每个记忆头只选择8个token参与注意力计算
- 记忆整合:
为了更好地整合显式记忆和常规上下文,Memory3引入了一个特殊的BOS token:
class Memory3Model(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embed = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([TransformerLayer(config) for _ in range(config.num_layers)])
self.ln_f = nn.LayerNorm(config.hidden_size)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# 特殊的BOS token嵌入
self.reference_bos = nn.Parameter(torch.randn(config.hidden_size))
def forward(self, input_ids, attention_mask, memories=None):
x = self.embed(input_ids)
# 插入特殊的Reference BOS
if memories is not None:
x = torch.cat([self.reference_bos.unsqueeze(0).unsqueeze(0), x], dim=1)
attention_mask = torch.cat([torch.ones(attention_mask.shape[0], 1, device=attention_mask.device), attention_mask], dim=1)
for i, layer in enumerate(self.layers):
x = layer(x, attention_mask, memories if i < self.config.num_memory_layers else None)
x = self.ln_f(x)
logits = self.lm_head(x)
return logits
- 并行位置编码:
Memory3使用旋转位置编码(RoPE),并为所有显式记忆应用并行位置编码:
class RotaryEmbedding(nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000):
super().__init__()
inv_freq = 1. / (base ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer('inv_freq', inv_freq)
self.max_seq_len_cached = max_position_embeddings
t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device).type_as(self.inv_freq)
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer('cos_cached', emb.cos()[None, None, :, :])
self.register_buffer('sin_cached', emb.sin()[None, None, :, :])
def forward(self, x, seq_len=None):
if seq_len > self.max_seq_len_cached:
self._set_cos_sin_cache(seq_len)
return (
self.cos_cached[:, :, :seq_len, ...],
self.sin_cached[:, :, :seq_len, ...]
)
def apply_rotary_pos_emb(q, k, cos, sin):
return (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)
class TransformerLayer(nn.Module):
def __init__(self, config):
super().__init__()
# ... 其他初始化代码 ...
self.rotary_emb = RotaryEmbedding(config.head_dim)
def forward(self, hidden_states, attention_mask, memories=None):
# ... 其他前向传播代码 ...
# 应用RoPE
q, k = self.rotary_emb(q, k)
if memories is not None:
# 为显式记忆应用并行位置编码
mem_pos = torch.arange(128, device=q.device)
mem_cos, mem_sin = self.rotary_emb(mem_pos)
for mem in memories:
mem.k, mem.v = apply_rotary_pos_emb(mem.k, mem.v, mem_cos, mem_sin)
# ... 继续注意力计算 ...
3.3 记忆稀疏化和存储
为了解决显式记忆占用空间过大的问题,Memory3采用了多维度的稀疏化策略:
- 层维度:
- 只在前22层(共44层)使用显式记忆
- 头维度:
- 使用分组查询注意力,将key-value头数减少到8个
- token维度:
- 每个key-value头只选择8个最重要的token
- 选择标准:基于无mask和位置编码的注意力权重
- 向量维度:
- 可选使用向量量化器进行压缩
- 压缩率约为11.4倍
通过这些稀疏化策略,Memory3将显式记忆的存储需求从7.17PB压缩到了45.9TB(不使用向量压缩)或4.02TB(使用向量压缩)。
- 稀疏化实现:
以下代码展示了如何实现token维度的稀疏化:
def sparsify_memory(memory, top_k=8):
# 计算注意力权重
attn_weights = torch.einsum('bhid,bhjd->bhij', memory.q, memory.k.transpose(2, 3)) / math.sqrt(memory.q.size(-1))
attn_weights = attn_weights.softmax(dim=-1)
# 选择top-k的token
_, top_indices = torch.topk(attn_weights.sum(dim=(0, 1)), k=top_k, dim=-1)
# 稀疏化memory
memory.k = memory.k[:, :, top_indices, :]
memory.v = memory.v[:, :, top_indices, :]
return memory
class Memory3Model(nn.Module):
# ... 其他代码 ...
def retrieve_and_sparsify_memories(self, query):
memories = self.retrieve_memories(query)
return [sparsify_memory(mem) for mem in memories]
- 向量压缩:
使用FAISS库实现向量量化压缩:
import faiss
class VectorCompressor:
def __init__ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











