








在快速发展的人工智能领域中,高效、有效地使用大型语言模型变得日益重要,参数高效微调是这一追求的前沿技术,它允许研究人员和实践者在最小化计算和资源占用的同时,重复使用预训练模型。这还使我们能够在更广泛的硬件范围内训练AI模型,包括计算能力有限的设备,如笔记本电脑、智能手机和物联网设备。
本文解释了微调的广义概念,并讨论了流行的参数高效微调方法,如Prefix Tuning和Adapter。最后,我们将关注最新的LLaMA-Adapter方法,并探讨其实际应用。
1. 大语言模型的微调
自GPT-2和GPT-3以来,我们已经看到,预训练在通用文本语料库上的生成性大型语言模型(LLM)能够进行上下文学习,这不需要我们进一步训练或微调预训练的LLM,就能执行LLM未显式训练过的特定或新任务。相反,我们可以直接通过输入提示提供目标任务的一些示例,如下面的例子所示。
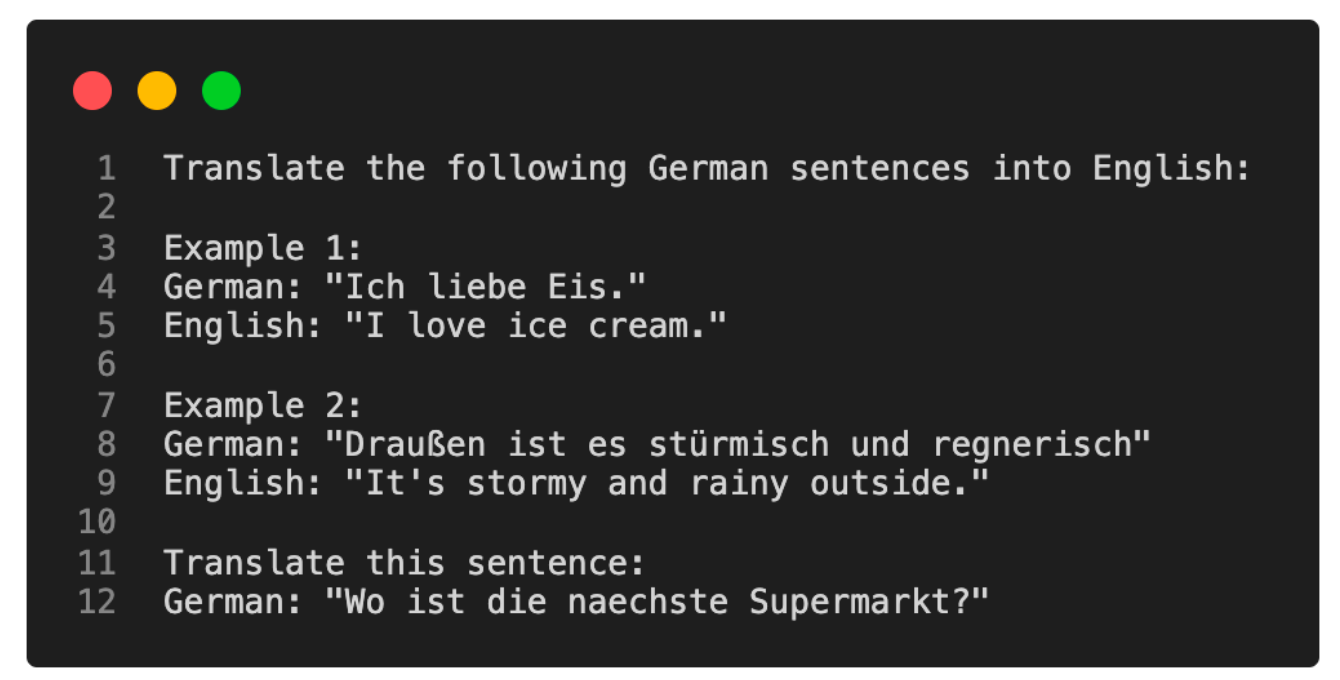
上下文学习是一种用户友好的方法,适用于直接访问大型语言模型(LLM)受限的情况,比如通过API或用户界面与LLM交互时。
然而,如果我们能够访问LLM,在目标领域的数据上对其进行适应和微调,通常会带来更好的结果。那么,我们如何使模型适应特定任务呢?下面的图表概述了三种常规的方法。
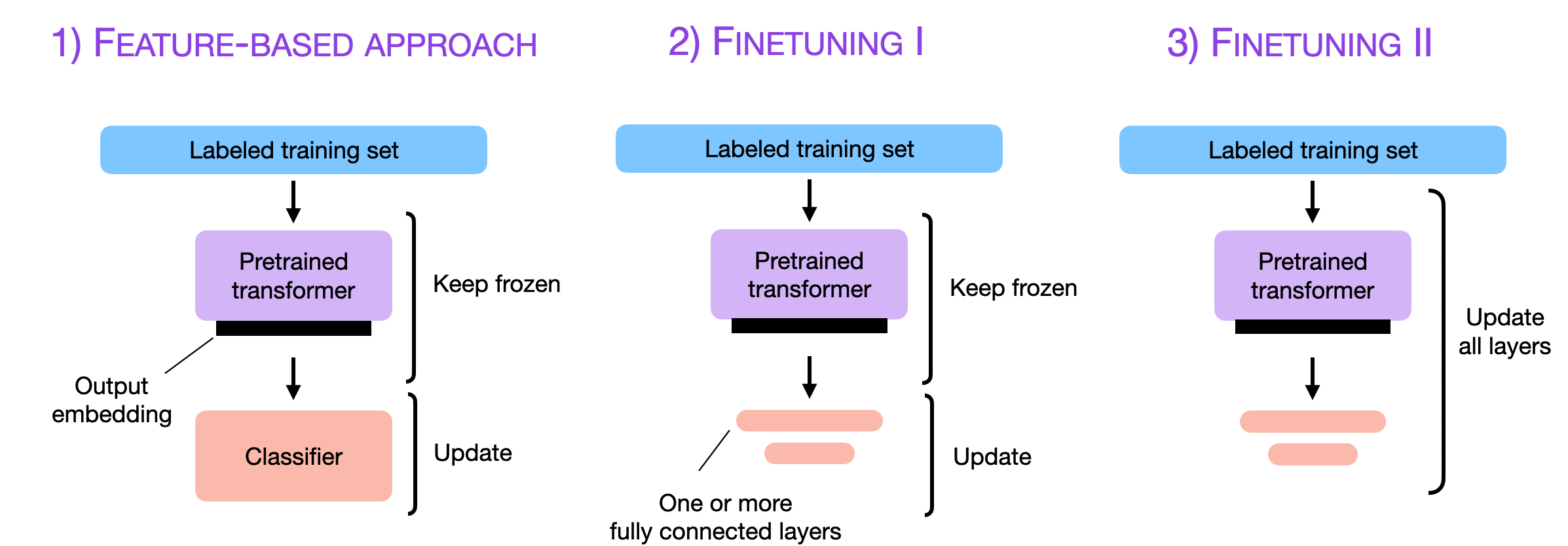
上述方法适用于生成式(解码器风格)模型,如GPT,以及重点关注嵌入的(编码器风格)模型,如BERT。与这三种方法相比,上下文学习只适用于生成式模型。值得强调的是,当我们对生成式模型进行微调时,我们使用并构建它们创建的嵌入,而不是生成的输出文本。
2. Feature-based: 基于特征的方法
在基于特征的方法中,我们加载一个预训练的LLM,并将其应用于我们的目标数据集。在这里,我们特别感兴趣的是为训练集生成输出嵌入,我们可以将其用作训练分类模型的输入特征。虽然这种方法对于重点关注嵌入的BERT来说特别常见,但我们也可以从生成式GPT风格模型中提取嵌入。
然后,分类模型可以是逻辑回归模型、随机森林或XGBoost —— 任何我们心之所向的模型。
从概念上讲,我们可以用以下代码来说明基于特征的方法:
model = AutoModel.from_pretrained("distilbert-base-uncased")
# ...
# tokenize dataset
# ...
# generate embeddings
@torch.inference_mode()
def get_output_embeddings(batch):
output = model(
batch["input_ids"],
attention_mask=batch["attention_mask"]
).last_hidden_state[:, 0]
return {"features": output}
dataset_features = dataset_tokenized.map(
get_output_embeddings, batched=True, batch_size=10)
X_train = np.array(dataset_features["train"]["featu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











