






注:本文主要介绍使用w3c解析xml,可以使用工具类中提供的方法解析xml中的数据。关于里面的jar包。作者使用的是jdk1.8,在rt.jar中,所以,此处不需要添加jar包。根据自己的使用情况而定。废话不多说,以下是工具类。关于使用w3c生成xml可以查看同类文章的生成使用w3c将ducument生成xml文件
注:以下工具类是考虑到各种异常,封装好的工具类,如果使用的过程中有疑惑可以将整个工具类拷贝,然后根据示例去解析你的xml,如果单纯的拷贝其中的某个方法,则可能会出现问题,因为工具类之间互有关联性。建议直接拷贝使用。
工具类
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import javax.xml.namespace.QName;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class XmlParse {
/**
* 获取Document对象。根据xml文件的名字获取Document对象。
*
* @param file
* 要获取对象的xml文件全路径。
* @return 返回获取到的Document对象。
* @throws IOException
* 如果发生任何 IO 错误时抛出此异常。
* @throws SAXException
* 如果发生任何解析错误时抛出此异常。
* @throws ParserConfigurationException
* 如果无法创建满足所请求配置的 DocumentBuilder,将抛出该异常。
* @exception NullPointerException
* 如果file为空时,抛出此异常。
*/
public static Document parseForDoc(final String file) throws SAXException,
IOException, SecurityException, NullPointerException,
ParserConfigurationException {
return parseForDoc(new FileInputStream(file));
}
/**
* 获取Document对象。根据字节输入流获取一个Document对象。
*
* @param is
* 获取对象的字节输入流。
* @return 返回获取到的Document对象。如果出现异常,返回null。
* @throws IOException
* 如果发生任何 IO 错误时抛出此异常。
* @throws SAXException
* 如果发生任何解析错误时抛出此异常。
* @throws ParserConfigurationException
* 如果无法创建满足所请求配置的 DocumentBuilder,将抛出该异常。
* @exception IllegalArgumentException
* 当 is 为 null 时抛出此异常。
*/
public static Document parseForDoc(final InputStream is)
throws SAXException, IOException, ParserConfigurationException,
IllegalArgumentException {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory
.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
return builder.parse(is);
} finally {
is.close();
}
}
/**
* 通过XPath表达式获取单个节点。
*
* @param obj
* 要被解析的對象。
* @param xPath
* XPath表达式。
* @return 返回获取到的节点。
*
* @throws XPathExpressionException
* 如果不能计算 expression。
*
* @exception RuntimeException
* 创建默认对象模型的 XPathFactory 遇到故障时。
* @exception NullPointerException
* 如果xPath为空时抛出时异常。
*/
public static Node parseForNode(final Object obj, final String xPath)
throws NullPointerException, RuntimeException,
XPathExpressionException
{
return (Node) parseByXpath(obj, xPath, XPathConstants.NODE);
}
/**
* 通过xpath表达式解析某个xml节点。
*
* @param obj
* 要被解析的xml节点对象。
* @param xPath
* xpath表达式。
* @param qName
* 被解析的目标类型。
* @return 返回解析后的对象。
* @throws XPathExpressionException
* 如果不能计算 expression。
*
* @exception RuntimeException
* 创建默认对象模型的 XPathFactory 遇到故障时。
* @exception NullPointerException
* 如果xPath为空时抛出时异常。
*/
private static Object parseByXpath(final Object obj, final String xPath,
QName qName) throws NullPointerException, RuntimeException,
XPathExpressionException {
XPathFactory xpathFactory = XPathFactory.newInstance();
XPath path = xpathFactory.newXPath();
return path.evaluate(xPath, obj, qName);
}
/**
* 通过XPath表达式获取Node列表。
*
* @param obj
* 要被解析的對象。
* @param xPath
* XPath表达式。
* @return 返回获取到的Node列表。
*
* @throws XPathExpressionException
* 如果不能计算 expression。
*
* @exception RuntimeException
* 创建默认对象模型的 XPathFactory 遇到故障时。
* @exception NullPointerException
* 如果xPath为空时抛出时异常。
*/
public static List<Node> parseForNodeList(final Object obj,
final String xPath) throws NullPointerException, RuntimeException,
XPathExpressionException
{
List<Node> lists = new ArrayList<Node>();
NodeList nList = (NodeList) parseByXpath(obj, xPath,
XPathConstants.NODESET);
if (nList != null) {
for (int i = 0; i < nList.getLength(); i++) {
lists.add(nList.item(i));
}
}
return lists;
}
/**
* 通过XPath表达式获取某个xml节点的字符串值。
*
* @param obj
* 要被解析的對象。
* @param xPath
* XPath表达式。
* @return 返回获取到的节点的字符串值。
*
* @throws XPathExpressionException
* 如果不能计算 expression。
*
* @exception RuntimeException
* 创建默认对象模型的 XPathFactory 遇到故障时。
* @exception NullPointerException
* 如果xPath为空时抛出时异常。
*/
public static String parseForString(final Object obj, final String xPath)
throws NullPointerException, RuntimeException,
XPathExpressionException
{
return (String) parseByXpath(obj, xPath, XPathConstants.STRING);
}
}解析示例:关于解析的文件的出处可以查看同类文章(使用w3c将ducument生成xml文件)
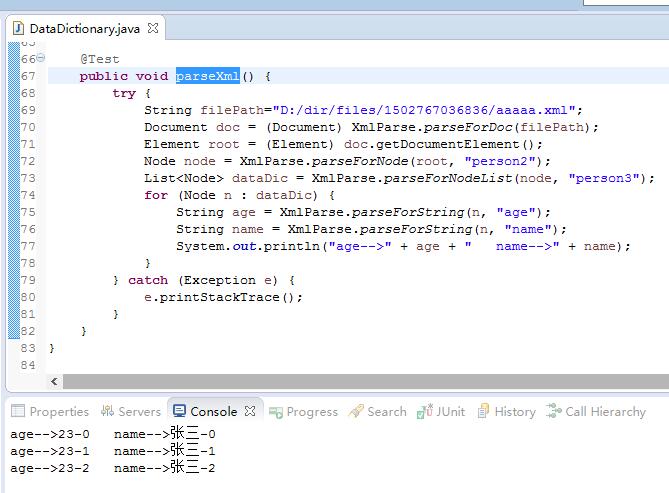
@Test
public void parseXml() {
try {
String filePath = "D:/dir/files/1502767036836/aaaaa.xml";
Document doc = (Document) XmlParse.parseForDoc(filePath);
Element root = (Element) doc.getDocumentElement();
Node node = XmlParse.parseForNode(root, "person2");
List<Node> dataDic = XmlParse.parseForNodeList(node, "person3");
for (Node n : dataDic) {
String age = XmlParse.parseForString(n, "age");
String name = XmlParse.parseForString(n, "name");
System.out.println("age-->" + age + " name-->" + name);
}
} catch (Exception e) {
e.printStackTrace();
}
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









