






文章目录
1.Kafka 核心概念
ConsumerGroup 消费者组
● 同个topic,广播发送给不同的group,一个group中只有一个consumer可以消费此消息
Topic
● 每条发布到kafka集群的消息都有一个类别,这个类别被称为topic,主题的意思
Partition:
● topic更多是一个逻辑层面的概念,topic的实际承载就是Partiton。topic中的数据被划分为一个或者多个partiton,每个topic至少有个partition,并且是有序的。以文件夹的形式存在brokern机器上面
● 一个Topic的多个partions,被分布在kafka的集群多个server上
● 消费者数量 <= partion数量
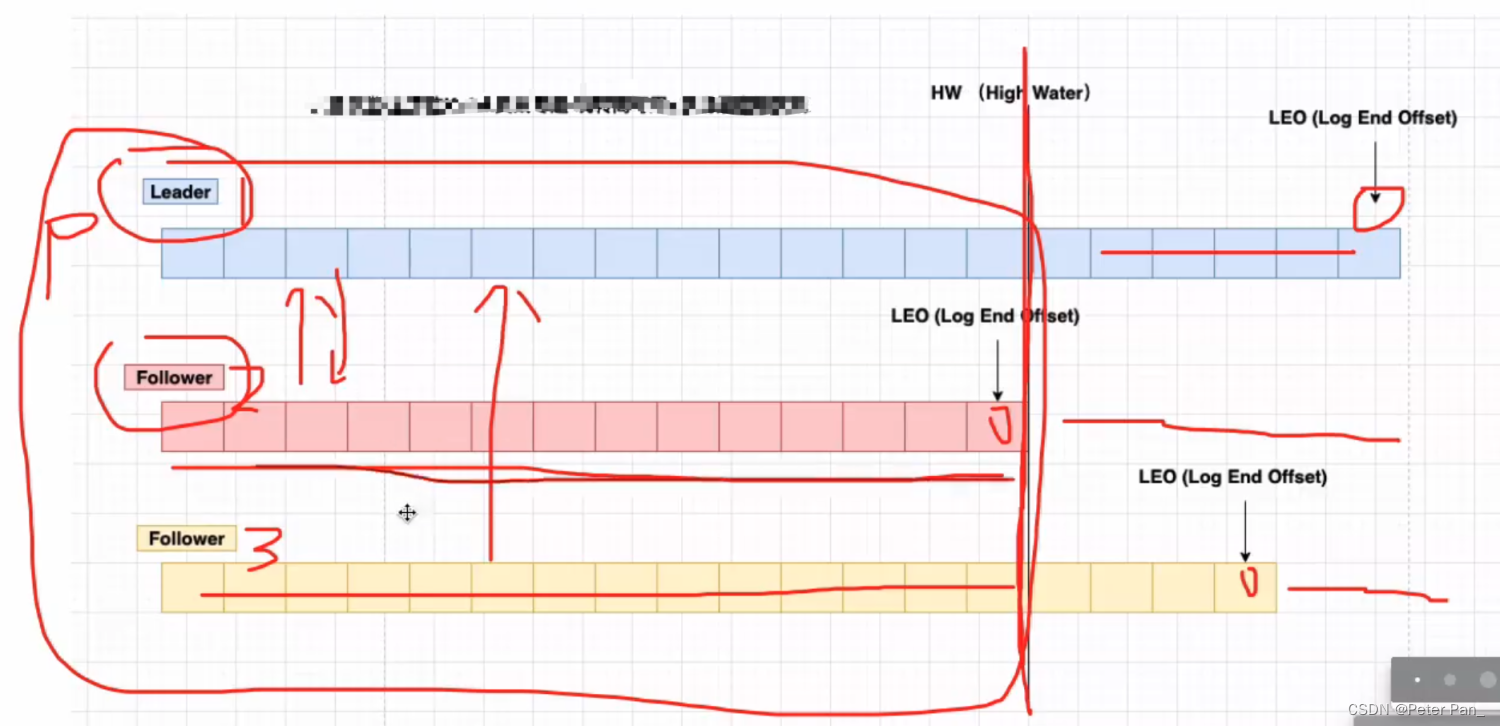
LEO (LogEndOffset):
● 表示每个partition的log的最后一条message的位置
HW(Highwatermark):
● 表示partition各个replicas数据间同步且一致的offset位置,即表示allreplicas已经commit的位置;HW之前的数据才是commit后的,才是对消费者可见的。
offset:
● 每个partition都是由一系列有序,不可变的消息组成,这些消息被主驾到partion中
● partion中的每个消息都有一个连续的序号叫做offset。用于唯一标识一条消息,类似于数据库表中的id
Segment file:
● segment file由两部分组成,分别是index file和data file(log file)
● 两个文件是一一对应的,后缀".index"和".log"分别标识索引文件和数据文件
● 命名规则:partition的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset+1。
Replication 副本
● 同个partition会有多个副本,多个副本的数据是一样的,当其他broker挂掉后,系统会主动使用副本提供服务
● 默认每个topic的副本都是1(默认没有副本,节省资源),也可以在创建topic的时候指定
● 如果当前kafka集群只有3个broker节点,则replication-factor最大就是3了,如果创建副本是4,则会报错
Kafka高效文件存储设计的特点:
- topic中一个partition大文件被分成了多个小文件段,易于定期清除或删除已经消费的文件件,减少磁盘占用
- 通过索引可以快速定位message
- produce生产数据,要写入到log文件中,写的过程中一直追加到文件尾,顺序写。顺序能写到600M/s
2. 生产消费模型讲解
2.1 点对点
特点:
● 消息生产之后被发送到queue中,然后被消费者从queue中取出并消费
● 消息被消费之后,queue中删除,即消费者不可能消费已经被消费的消息,queue支持对接多个消费者,但是对于一个消息而言,只能被唯一的消费者消费
2.2 发布、订阅模型

特点
● 消息生产之后发布到topic中,同时有多个消费者订阅消费该消息
● 和点对点的方式不同,发布到topic的消息会被所有消费者消费
3. 生产者实战讲解
3.1 生产者投递数据到broker分区的策略
● 生产者发送到broker里面的流程是怎样的呢,一个 topic 有多个 partition分区,每个分区又有多个副本
○ 如果指定Partition ID,则PR被发送至指定Partition (ProducerRecord)
○ 如果未指定Partition ID,但指定了Key, PR会按照hash(key)发送至对应Partition
○ 如果未指定Partition ID也没指定Key,PR会按照默认 round-robin轮训模式发送到每个Partition
■ 消费者消费partition分区默认是range模式
○ 如果同时指定了Partition ID和Key, PR只会发送到指定的Partition (Key不起作用,代码逻辑决定)
○ 注意:Partition有多个副本,但只有一个replicationLeader负责该Partition和生产者消费者交互
3.2 生产者常见配置
#kafka地址,即broker地址
bootstrap.servers
#当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
acks
#请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
retries
#每个分区未发送消息总字节大小,单位:字节,超过设置的值就会提交数据到服务端,默认值是16KB
batch.size
# 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满,如果想减少请求的数量,可以设置 linger.ms 大于#0,即消息在缓冲区保留的时间,超过设置的值就会被提交到服务端
# 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送 减少请求
#如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
linger.ms
# buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
# 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到Kafka服务器
# 会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了
# buffer.memory要大于batch.size,否则会报申请内存不足的错误,不要超过物理内存,根据实际情况调整
buffer.memory
# key的序列化器,将用户提供的 key和value对象ProducerRecord 进行序列化处理,key.serializer必须被设置,即使
#消息中没有指定key,序列化器必须是一个实现org.apache.kafka.common.serialization.Serializer接口的类,将#key序列化成字节数组。
key.serializer
value.serializer
kafka实战:
// 定义一个配置对象,在里面存放所有我们意图配置的属性
Properties props = new Properties();
3.2 ProduceRecord 介绍
定义: 发送给broker的信息并不是只有key-value,kafka是份封装成ProduceRecord(PR)对象发出
– Topic (名字)
– PartitionID (可选) # 决定发送某个分区的策略
– Key(可选)
– Value
key默认是null,大多数应用程序会用到key
● 如果key为空,kafka使用默认的partitioner,使用RoundRobin算法将消息均衡地分布在各个partition上
● 如果key不为空,kafka使用自己实现的hash方法对key进行散列,决定消息该被写到Topic的哪个partition,拥有相同key的消息会被写到同一个partition,实现顺序消息
kafka默认分区器:org.apache.kafka.clients.producer.internals.DefaultPartitioner
如果需要自定义分区算法,可以重写Partitioner接口。 并把实现类以配置参数的形式做指定:
props.put(“partitioner.class”, “net.xdclass.xdclassredis.XdclassPartitioner”);、
4. 消费者实战讲解
4.1 Consumer消费者机制和分区策略
- 消费者采用pull数据的动作,而不是从broker去push。 why ?
● pull模式可以根据consumer的消费能力自己进行调整,不同的消费者性能不一样
○ 时间:如果broker没有数据,consumer可以配置timeout时间,阻塞等待一段时间后再返回
● 如果是broker主动push,可以快速消费消息,但是由于多节点,消费能力不相同,容易造成消费者处理不过来,造成延时堆积。
由上,既然是消费者主动拉取的,那么从哪个partition分区拉取数据就成为了一个问题。这就是分区策略。 - 消费者从哪个分区进行消费主要有两个策略:
顶层策略接口:
org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor
● 轮询消费(RoundRobinAssignor)
进行轮训分配,同个消费者组监听不同主题也一样,是把所有的 partition 和所有的 consumer 都列出来, 所以消费者组里面订阅的主题是一样的才行,主题不一样则会出现分配不均问题,例如7个分区,同组内2个消费者。
由于同一个topic下的消息只能被同一个消费者组里面的一个消费者进行消费。因此轮询分配存在一个缺点:
【按照消费者组】
● 如果同一消费者组内,所订阅的消息是不相同的,在执行分区分配的时候不是轮询分配,可能会导致分区分配的不均匀
● 有3个消费者C0、C1和C2,他们共订阅了 3 个主题:t0、t1 和 t2
● t0有1个分区(p0),t1有2个分区(p0、p1),t2有3个分区(p0、p1、p2))
● 消费者C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2。
【按照主题】
● 如果不平均分配,则第一个消费者会分配比较多分区, 一个消费者监听不同主题也不影响,例如7个分区,同组内2个消费者
● 只是针对 1 个 topic 而言,c-1多消费一个分区影响不大
● 如果有 N 多个 topic,那么针对每个 topic,消费者 C-1 都将多消费 1 个分区,topic越多则消费的分区也越多,则性能有所下降
4.2 消费者常用配置
#消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
group.id
#为true则自动提交偏移量
enable.auto.commit
#自动提交offset存在如下两个问题:
## 1.没法控制消息是否被正常消费,可能消费宕机了
## 2.适合非严谨的场景,比如日志的处理,因为日志对数据的准确性没那么高
#自动提交offset周期
auto.commit.interval.ms
#重置消费偏移量策略,消费者在读取一个没有偏移量的分区或者偏移量无效情况下(因消费者长时间失效、包含偏移量的记录已经过时并被删除)该如何处理,
#默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更 才可以
auto.offset.reset
#序列化器
key.deserializer
5. Kafka数据文件存储-ISR核心讲解
5.1 Kafka数据存储流程和log日志
● Kafka采用分片与索引机制,每个partition分为多个segment,每个segment由log文件和index文件组成
○ index:存储索引信息
○ log:存储数据信息
Index文件,例如:00032.index
第一列是offset,第二列是这个数据所对应的log文件中的物理偏移量
0 0
2 43
4 234
6 1345
log文件,例如00032.log
message-32 0
message-1133 131
message-2334 211
message-3355 234
以(4,234)为例。 先通过二分法找到该数据在哪个index文件中,然后通过offset=4, 查到了该数据在log文件中从上到下第4个数据,可以看到对应的是3355,代表全局partition第3355个消息。 234表示该消息的物理偏移地址是234。
● index和log文件的命名也是有含义的。32说明当前文件的最小偏移量(全局partition的偏移量)是32。同时也说明上一个文件的最大偏移量是31。
segment的大小是可以指定的。 server.properties
# The maximum size of a log segment file. When this size is reached a new log segment will be created. 默认是1G,当log数据文件大于1g后,会创建一个新的log文件(即segment,包括index和log)
log.segment.bytes=1073741824
6. SpringBoot整合 Kafka
6.1 添加pom文件
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
6.2 配置文件配置增加消费者和生产者的配置信息
其实就是整合了前面提到的常用配置
spring:
kafka:
bootstrap-servers: 112.74.55.160:9092,112.74.55.160:9093,112.74.55.160:9094
producer:
# 消息重发的次数。
retries: 0
#一个批次可以使用的内存大小
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
acks: all
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
## 配置之后可以直接使用注解监听topic
listener:
#手工ack,调用ack后立刻提交offset
ack-mode: manual_immediate
#容器运行的线程数
concurrency: 4
@KafkaListner 注解的使用, 样例代码如下:
/**
* 消费监听
* @param record
*/
@KafkaListener(topics = {"user.register.topic"},groupId = "xdlcass-test-gp")
public void onMessage1(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){
// 打印出消息内容
System.out.println("消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
ack.acknowledge();
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









