






前言:
我们整个es的学习全程都在拿es和mysql做对比,今天我们再比较下二者的速度,为啥es比数据库mysql查询快那么多?首先ES是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎,而正巧,mysql最不擅长的就是全文检索,分析如下
从es读数据的流程
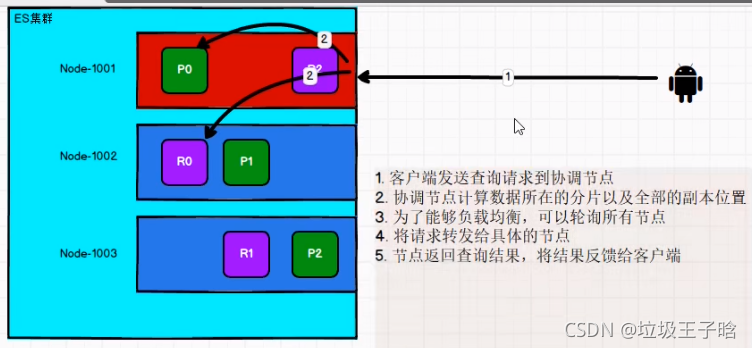
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
总延时 = 把数据写入主分片的数量+数据同步到副本中的数量(这部分可以通过更改es的配置变为0)
1、正排索引 VS 倒排索引
es采用的是倒序索引,这种索引方式和我们的正常索引不太一样,我们以一张表来说明,看一下对比,所谓的正向索引,就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数。说人话就是mysql中的数据表用的就是正向索引,概念听不明白的话,打开你的mysql搂几眼你的数据表就懂了
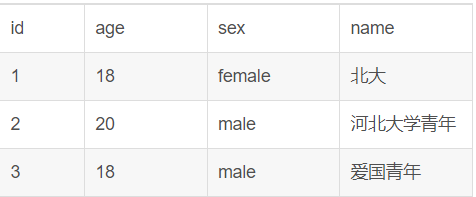
在mysql中,是以id简历b+树索引,然后通过目录页对应到数据页,然后找到数据。对于传统的增删改查(用id)没有任何问题,速度也很快,但是对于全文检索来说,就很尴尬。比如查询like %北大%。这样是走不到索引的,需要全表扫描,但实际企业开发中,我们往往需要对万级的文档进行检索,那mysql直接靠边站吧
这对于es来说,这就好办多了。
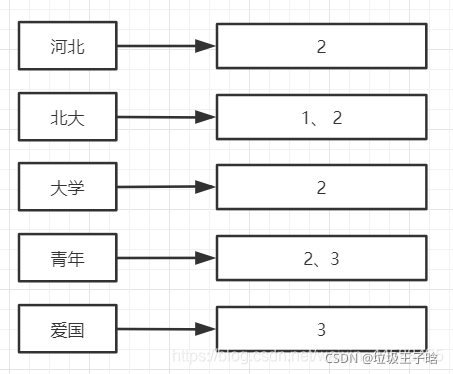
首先我们是将内容进行了分词(这里是最细粒划分)。再根据关键字和文档的映射关系建立起倒排索引,也就是让关键字指向了我们document的一个唯一的标识,能够找到位置的地址。
倒排索引建立完毕后,当我们在程序发出一个查询请求后,比如“北大青年”。首先会把这个查询内容分词:“北大”、“青年”。然后就找到对应的数据[1,2,3]。这三条数据了,比我们在mysql中模糊查询快的多。这是其中的一个原因。
我们将“北大”、“河北”、“大学…这样的叫做term。如果有很多个term,那么我们如何找到对应的term呢,首先排查遍历这种笨方法,那么能否采用二分查找呢?事实上二分查找mysql的inndb中在目录页的查找过程中和数据页的查找对应的数据中均有体现,以 logN 次磁盘的代价查找得到目标的看起来还是不错的,但是磁盘的随机读操作仍然是非常昂贵的(一次random access大概需要10ms的时间)。而相比于mysql,term的dictionary要大得多。无法完整地放到内存里。term index。term index有点像一本字典的大的章节表。如果所有的term都是英文字符的话,可能这个term index就真的是26个英文字符表构成的了。但是实际的情况是,term未必都是英文字符,term可以是任意的byte数组,我们把term index看做是一多叉棵即可
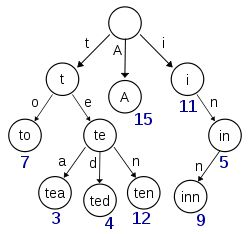
这里只考虑前缀并不考虑完整的分词字,例子是一个包含 “A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 的 trie 树。这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。再加上一些压缩技术(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有term的尺寸的几十分之一,使得用内存缓存整个term index变成可能。整体上来说就是这样的效果。
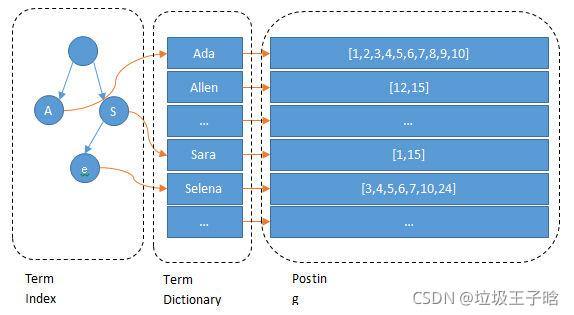
这种方式就很快就能够查找到对应的分词,然后在对应的分词就找到了对应的主键,然后就可以直接找到对应的数据了。
2 不可改变的倒排索引
早期的全文检索会为整个文档集合建立一个很大的倒排索引并将其写入到磁盘。 一旦新的索引就绪,旧的就会被其替换,这样最近的变化便可以被检索到。
倒排索引被写入磁盘后是不可改变的:它永远不会修改,好处是
- 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
- 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
- 其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
- 写入单个大的倒排索引允许数据被压缩,减少磁盘IO和需要被缓存到内存的索引的使用量。
缺点很简单:一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
3、ES集群的设计思路 磁盘在这里成为了瓶颈
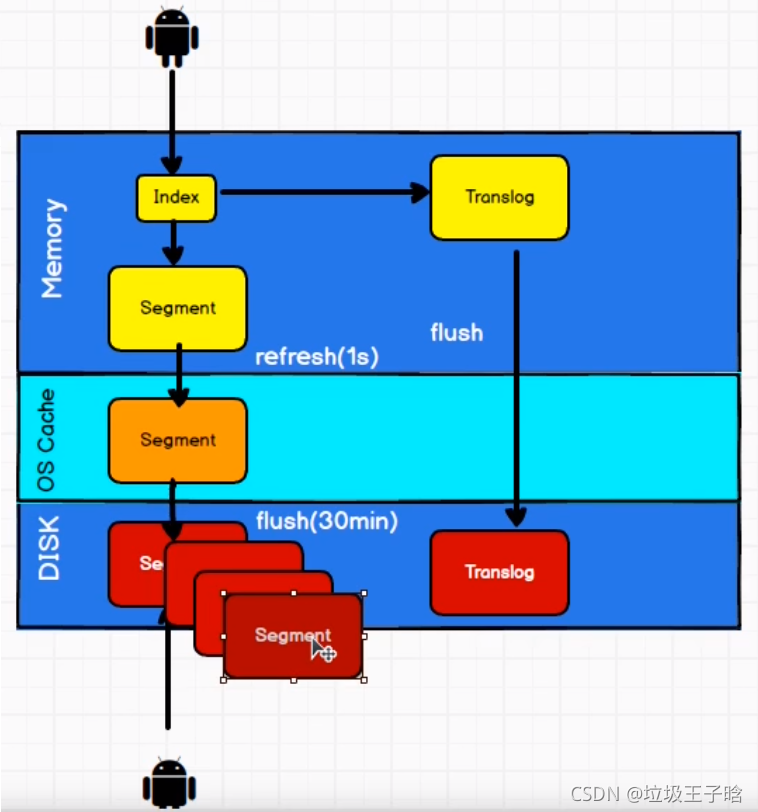
随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。磁盘在这里成为了瓶颈。提交(Commiting)一个新的段到磁盘需要一个fsync来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。但是fsync操作代价很大;如果每次索引一个文档都去执行一次的话会造成很大的性能问题。
我们需要的是一个更轻量的方式来使一个文档可被搜索,这意味着fsync要从整个过程中被移除。在Elasticsearch和磁盘之间是文件系统缓存。像之前描述的一样,在内存索引缓冲区中的文档会被写入到一个新的段中。但是这里新段会被先写入到文件系统缓存—这一步代价会比较低,稍后再被刷新到磁盘—这一步代价比较高。不过只要文件已经在缓存中,就可以像其它文件一样被打开和读取了。
4 ES数据同步策略
在默认设置下,即使仅仅是在试图执行一个写操作之前,主分片都会要求必须要有规定数量quorum的分片副本处于活跃可用状态,才会去执行写操作(其中分片副本 可以是主分片或者副本分片)。这是为了避免在发生网络分区故障的时候进行写操作,进而导致数据不一致。 规定数量即
consistency 参数的值可以设为:
- one :只要主分片状态 ok 就允许执行写操作。
- all:必须要主分片和所有副本分片的状态没问题才允许执行写操作。
- quorum:默认值为quorum , 即大多数的分片副本状态没问题就允许执行写操作
one的时候速度是最快的














 3792
3792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









