






1.前言
错题本是一种学习工具,用于记录和总结学生在学习过程中做错的题目,以便找出学习中的薄弱环节,提高学习效率和成绩。
一下是错题本定义、作用、建立方法、使用技巧等内容。
-
定义:错题本是指中小学学生在学习过程中,把自己做过的作业、习题、试卷中的错题整理成册,便于找出自己学习中的薄弱环节,使得学习重点突出、学习更加有针对性、进而提高学习效率和学习成绩的作业本。错题本也叫“摘错本”、“纠错本”、“改错本”或“错题集”。
-
作用:
- 查漏补缺:通过记录错题,学生可以发现自己的知识盲点,及时调整学习策略,有针对性地进行复习和提升。
- 提高学习效率:错题本帮助学生集中注意力在错误上,而不是分散在大量练习中,从而提高复习效率。
- 避免重复错误:通过反复回顾和重新解答错误的题目,学生可以加深对相关知识点的理解,避免在同样的问题上犯错。
- 培养良好的学习习惯:错题本的使用可以改变学生对错误的态度,使他们对待错误更加积极,从而改掉马马虎的习惯。
-
建立方法:
- 分类整理:将错题按错误的原因(如概念模糊、思路错误、运算错误、审题错误、粗心大意等)或知识点进行分类整理。
- 记录方法:在错题本上记录原题、正确答案、错误原因分析和正确解法。
- 定期回顾:定期回顾错题本,重新做一遍这些题目,看看自己是否已经掌握之前的知识点,这样可以有效地巩固知识,防止再犯同样的错误。
-
使用技巧:
- 及时整理:错题本应在做完题后立即整理,这样可以加强记忆。
- 注重效率:不要过于追求错题本的美观,而应该注重效率,用最短的时间做好错题本。
- 相互交流:通过与同学交流错题本,可以借鉴彼此的优点,共同提高学习效果

我们通过错题本记录,分析、复习 差缺补漏 从而帮助学生提高成绩。今天就带大家使用dify工作流来实现一个中小学数学错题本功能。
因为时间关系这里我们只实现了一个错题本的收集整理,所以本次分享我们计划通过2篇文章来实现一个一个中小学数学错题本功能。
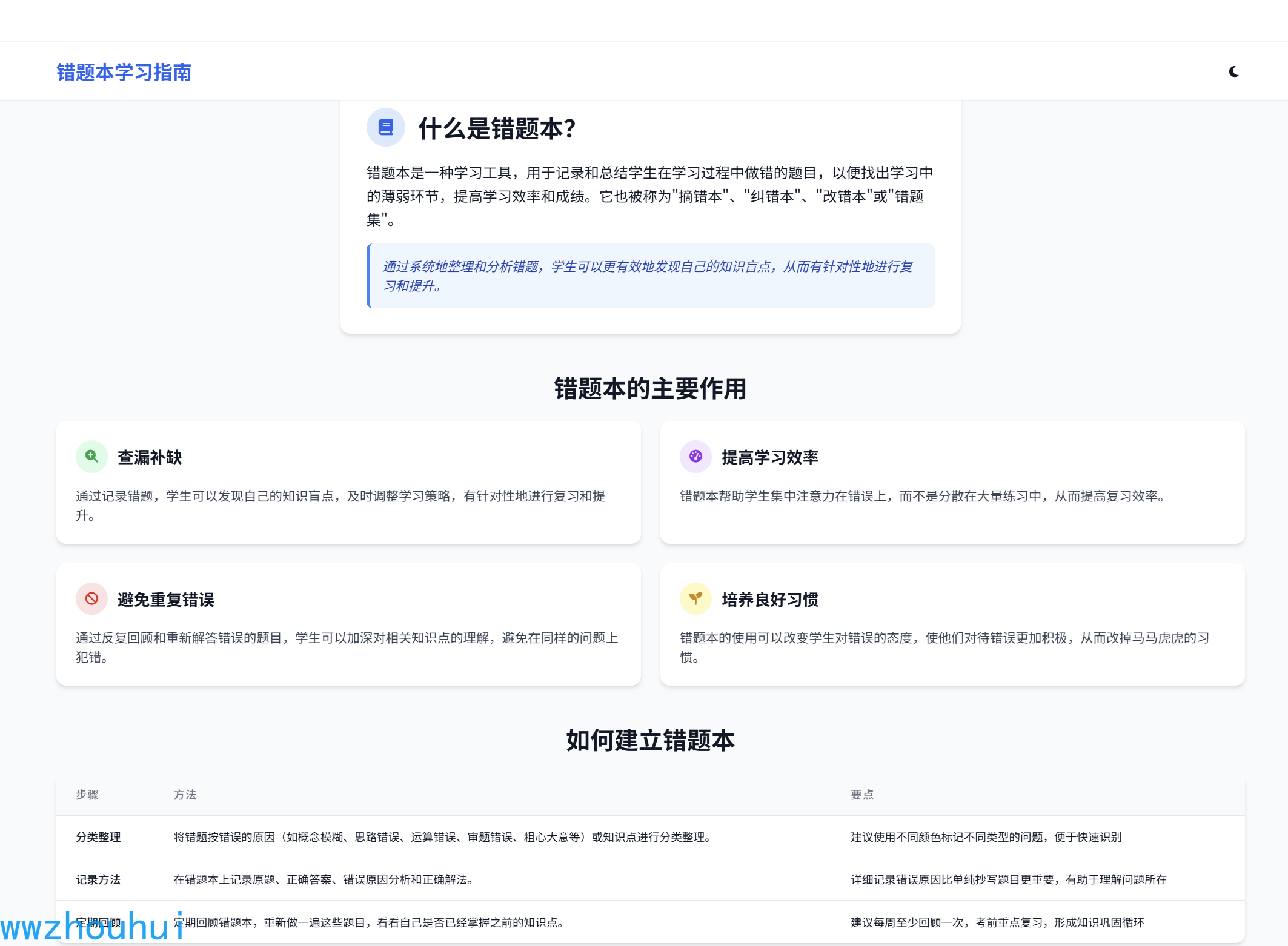
我们先看一下制作好的工作流大概是什么样子:
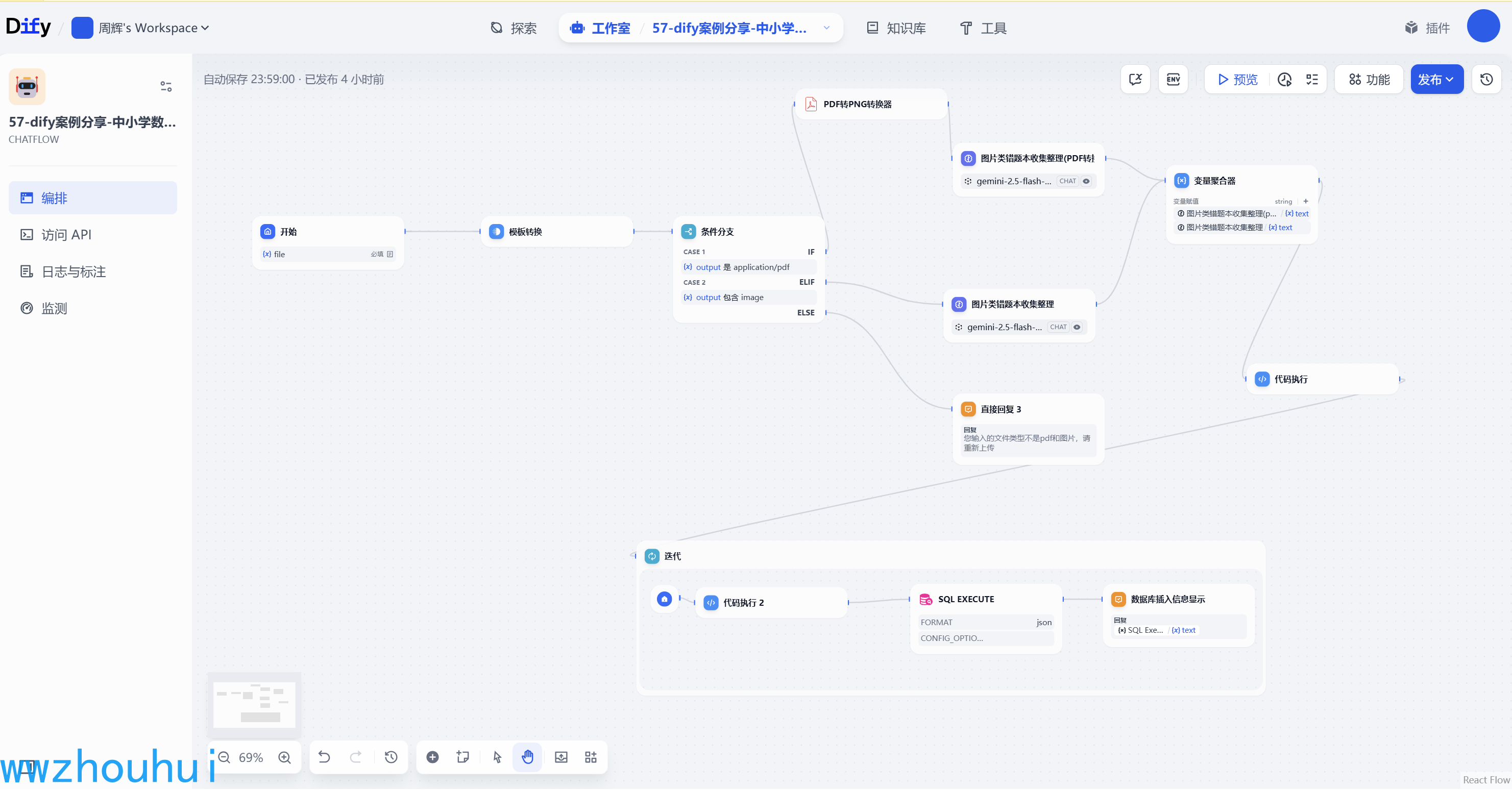
以上错题本主要的目的是收集学生或者家长上传的PDF和图片格式的错题信息,使用多模态大模型OCR识别功能把错题收集整理写入到数据库中,相当于错题本记录收集功能。后面我们在基于上面的错题本进行同类型题型出题,实现同类型错题的强化学习从而帮助中小学生差缺补漏。
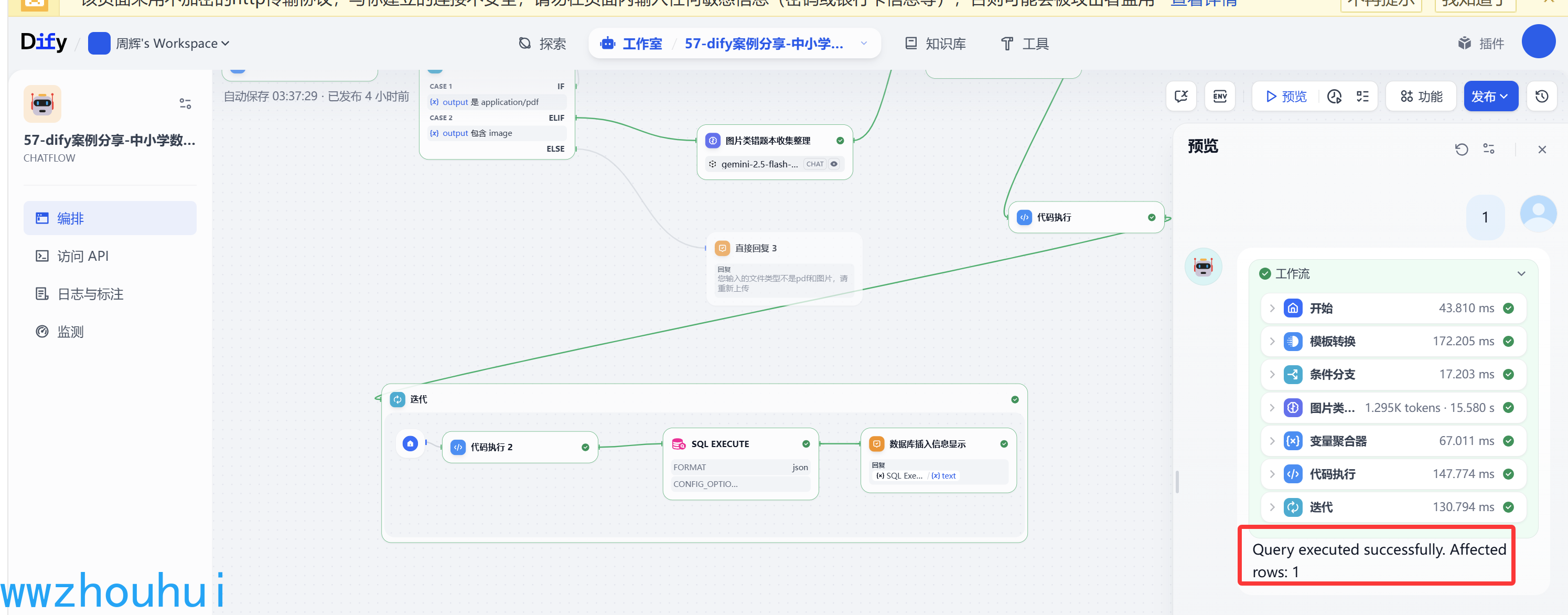
下面看一下实现的效果:
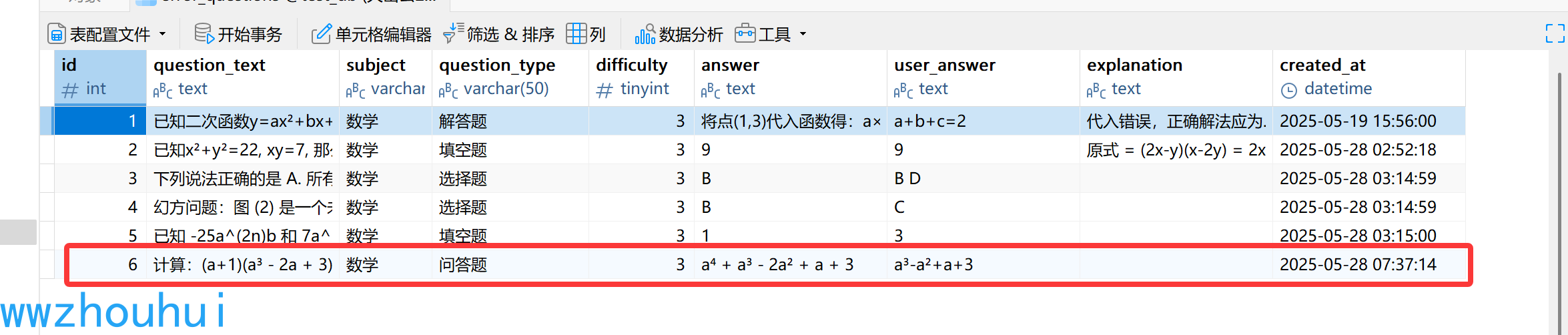
写入数据库信息:
那么这个工作流是如何实现的呢?话不多说下面带大家手把手搭建这个工作流。
如果大家懒的看文章,我们这里也提供的一个文章的博客,感兴趣小伙伴也可以先听一下这个博客
添加链接描述
2.工作流的制作
这个工作流我们首先给大家拆解一下,它用到了开始节点、模板转换、条件分支、pdf转png转换器(第三方工具)、基于多模态llm大语言模型、变量聚合器、代码执行、迭代、SQL Execute(第三方工具)等功能,下面我们逐一给大家讲解一下。
首先我们用到了2个第三方工具 一个是pdf转png转换器,一个是database。
关于database 插件安装可以看我前期文章《dify案例分享-基于database插件实现Text2sql的数据库查询图表工作流》
这里我们介绍一下pdf转png转换器安装安装。
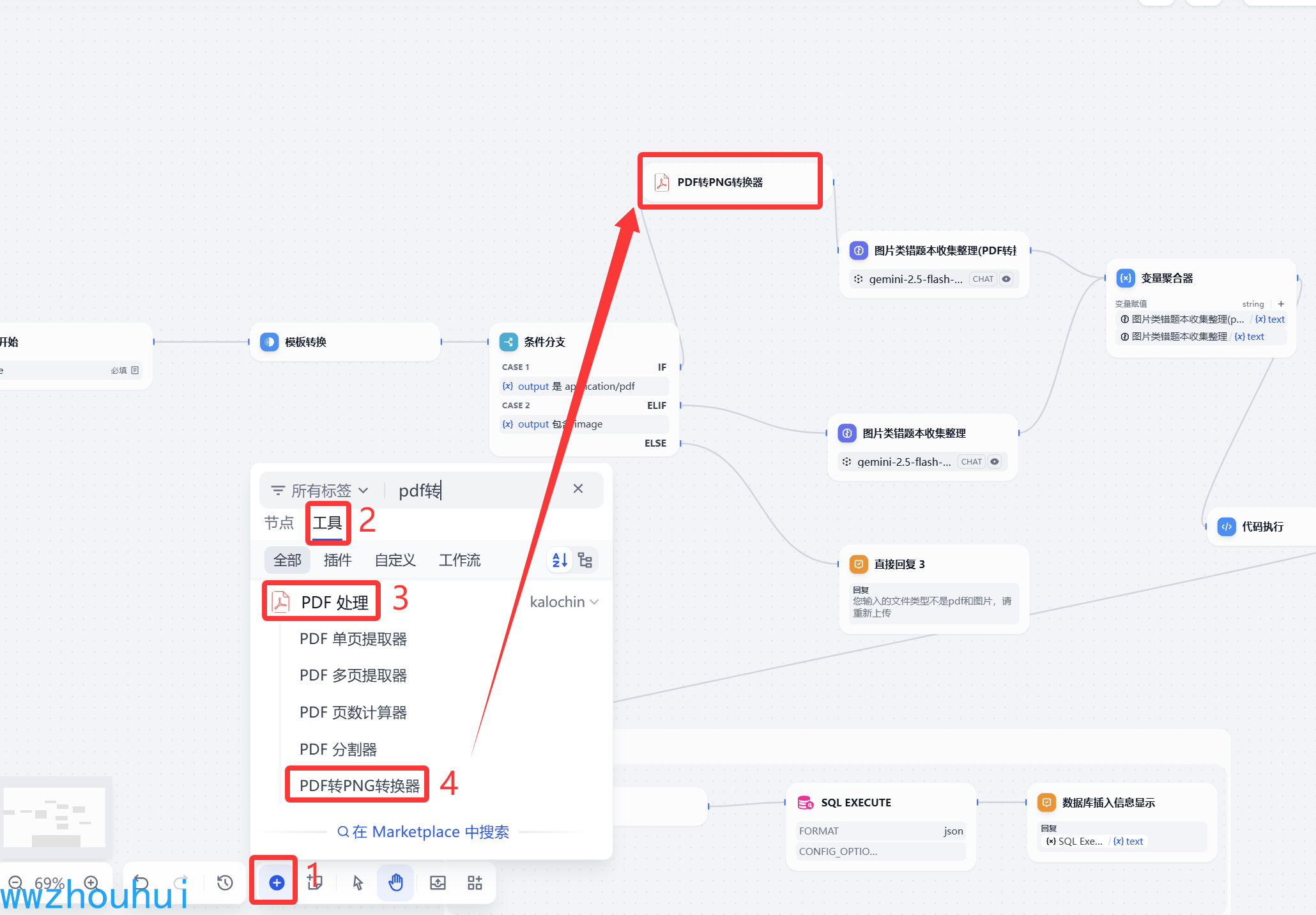
pdf转png转换器安装
我们在插件市场搜索pdf处理
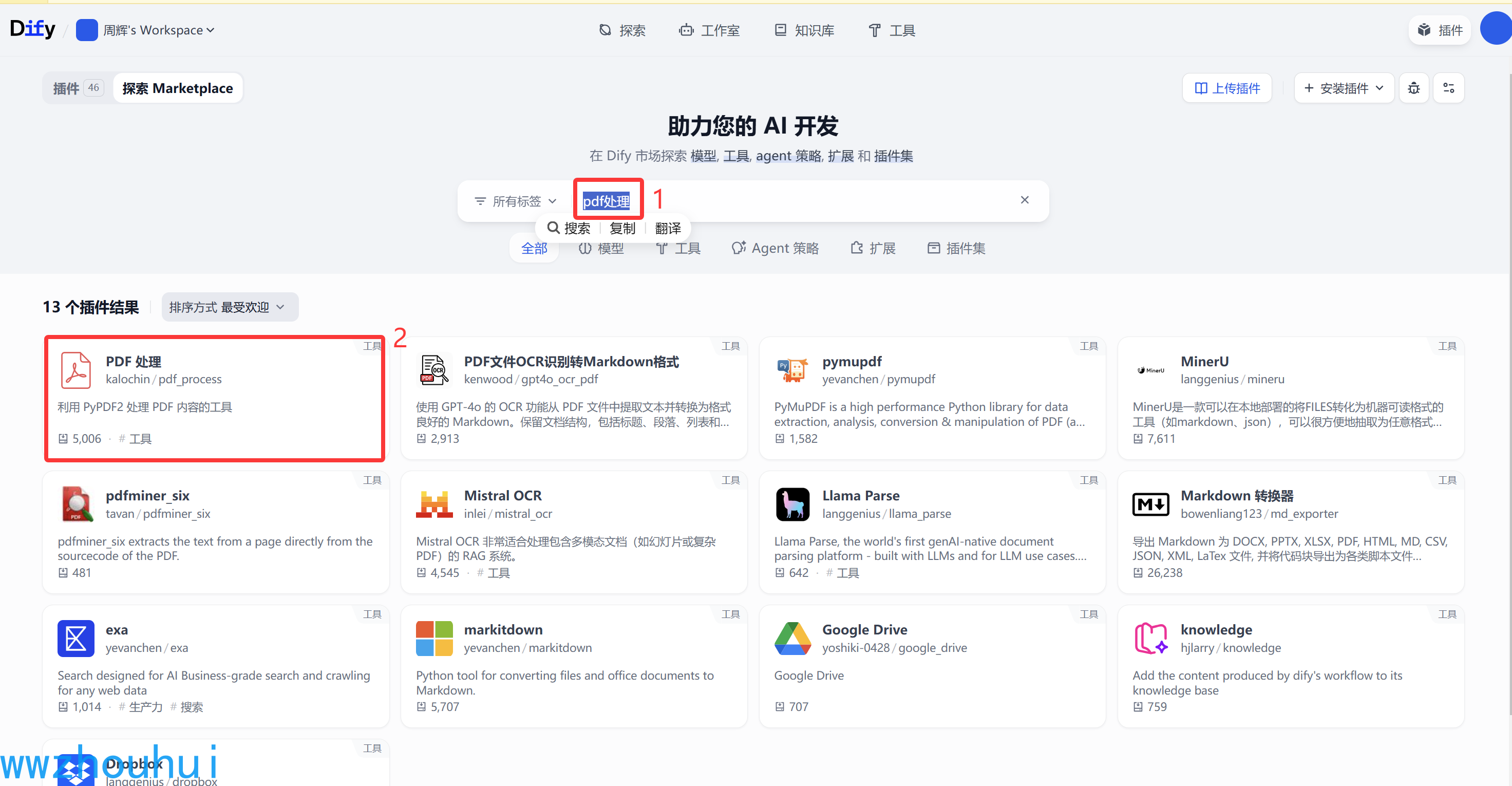
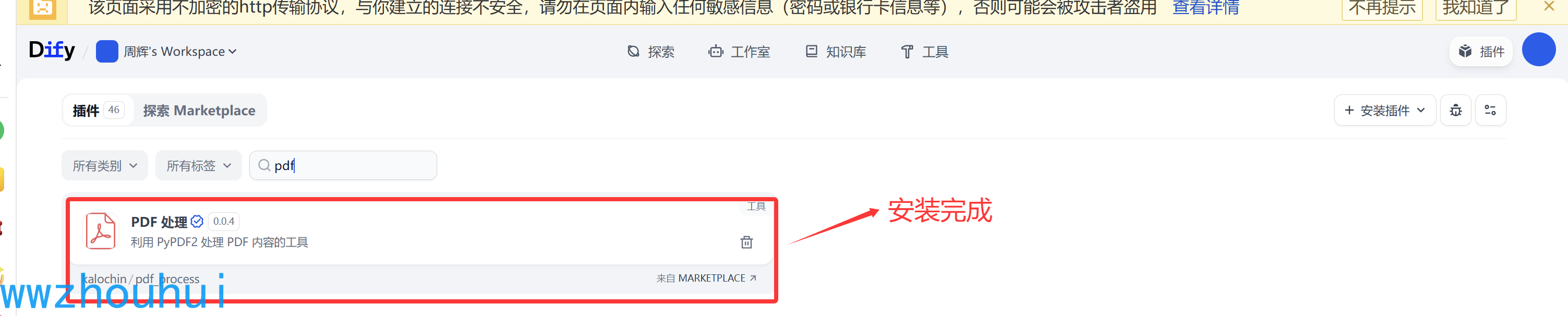
找到这个插件安装。安装完成后我们在插件列表中查找到,看到下图信息说明插件安装完成。
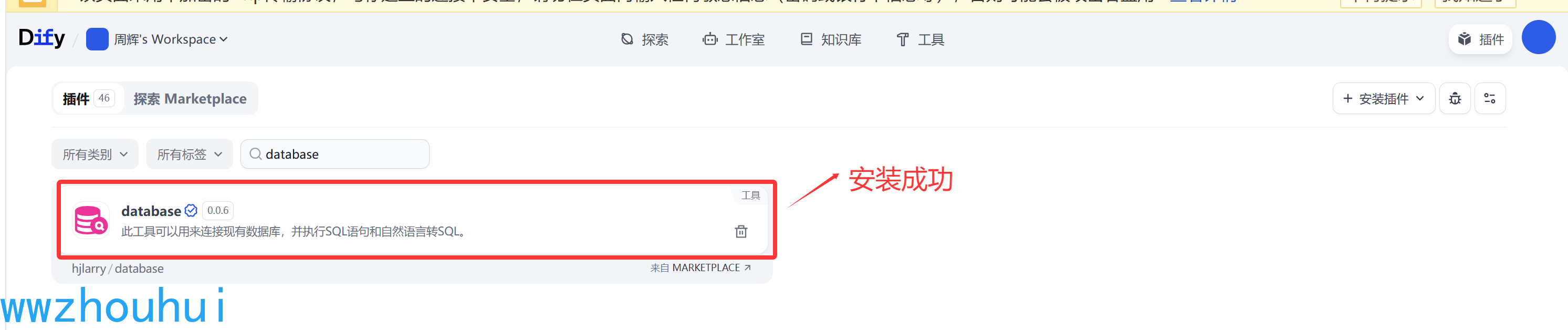
同样的道理我们也能搜索到database这个插件。
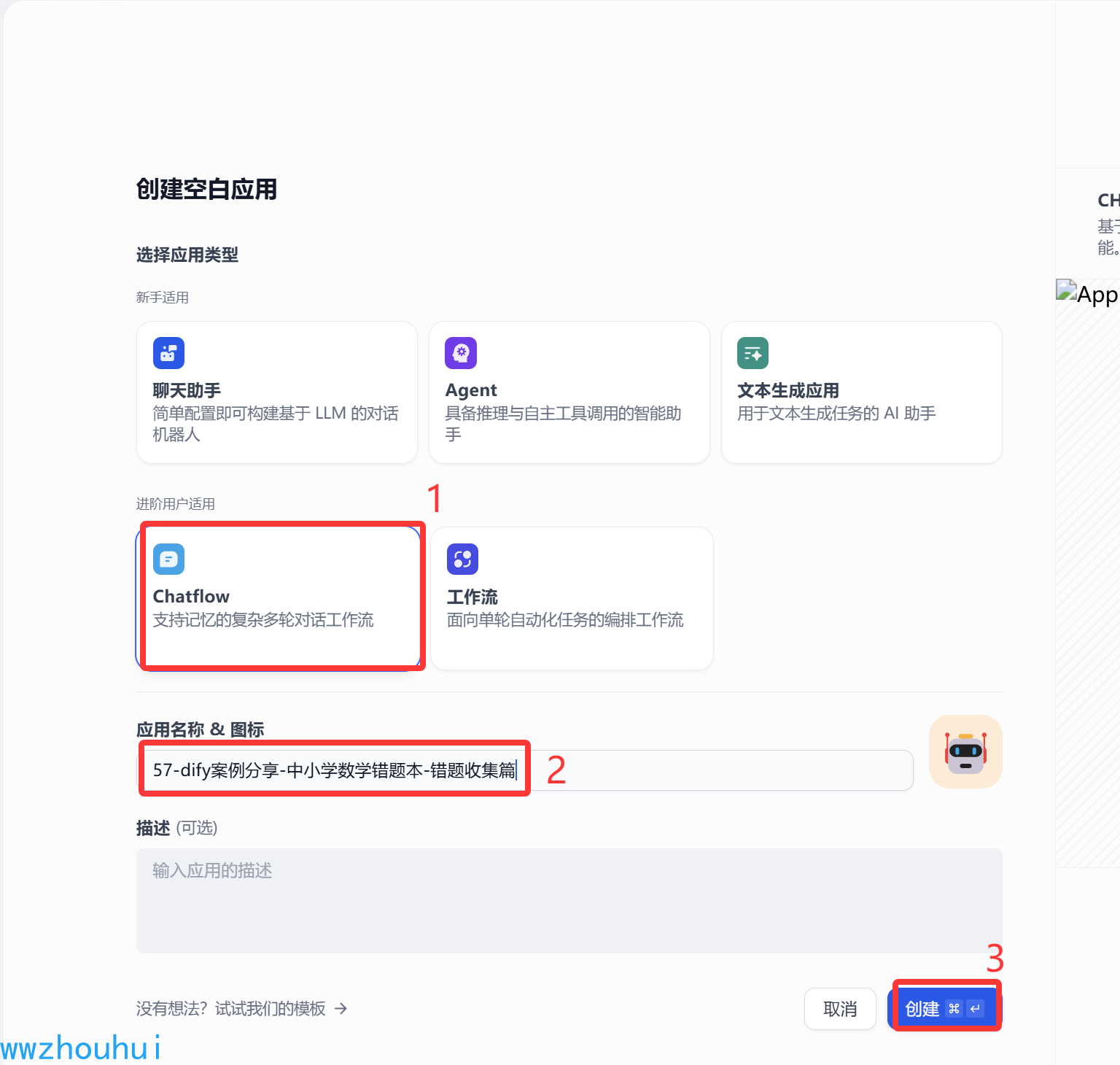
我们创建工作流,使用chatflow
开始
这个开始节点参数就是文件,这个文件支持图片和PDF两种格式的文件。
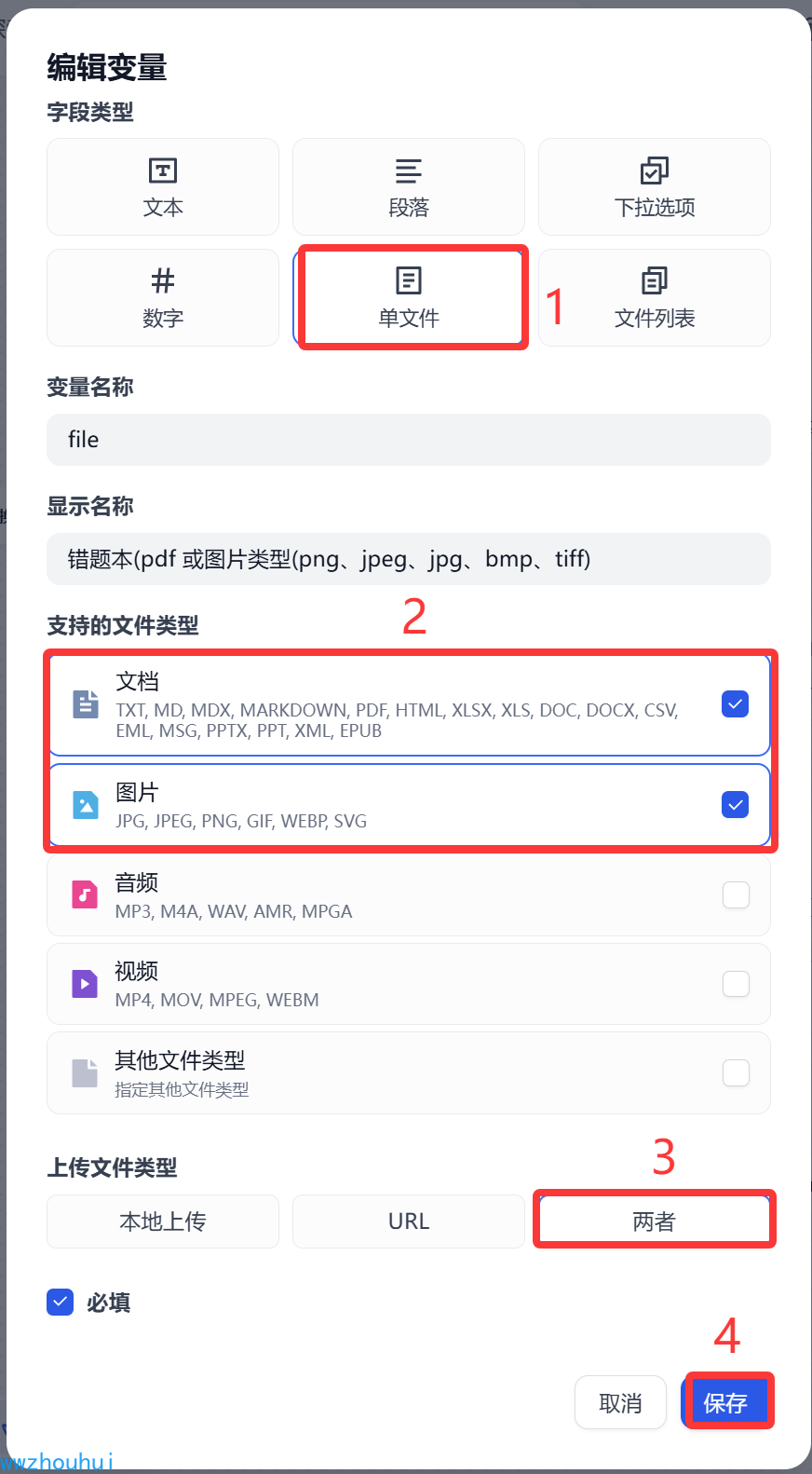
其他就没有相关设置了,我们看一下开始节点设置后的截图。
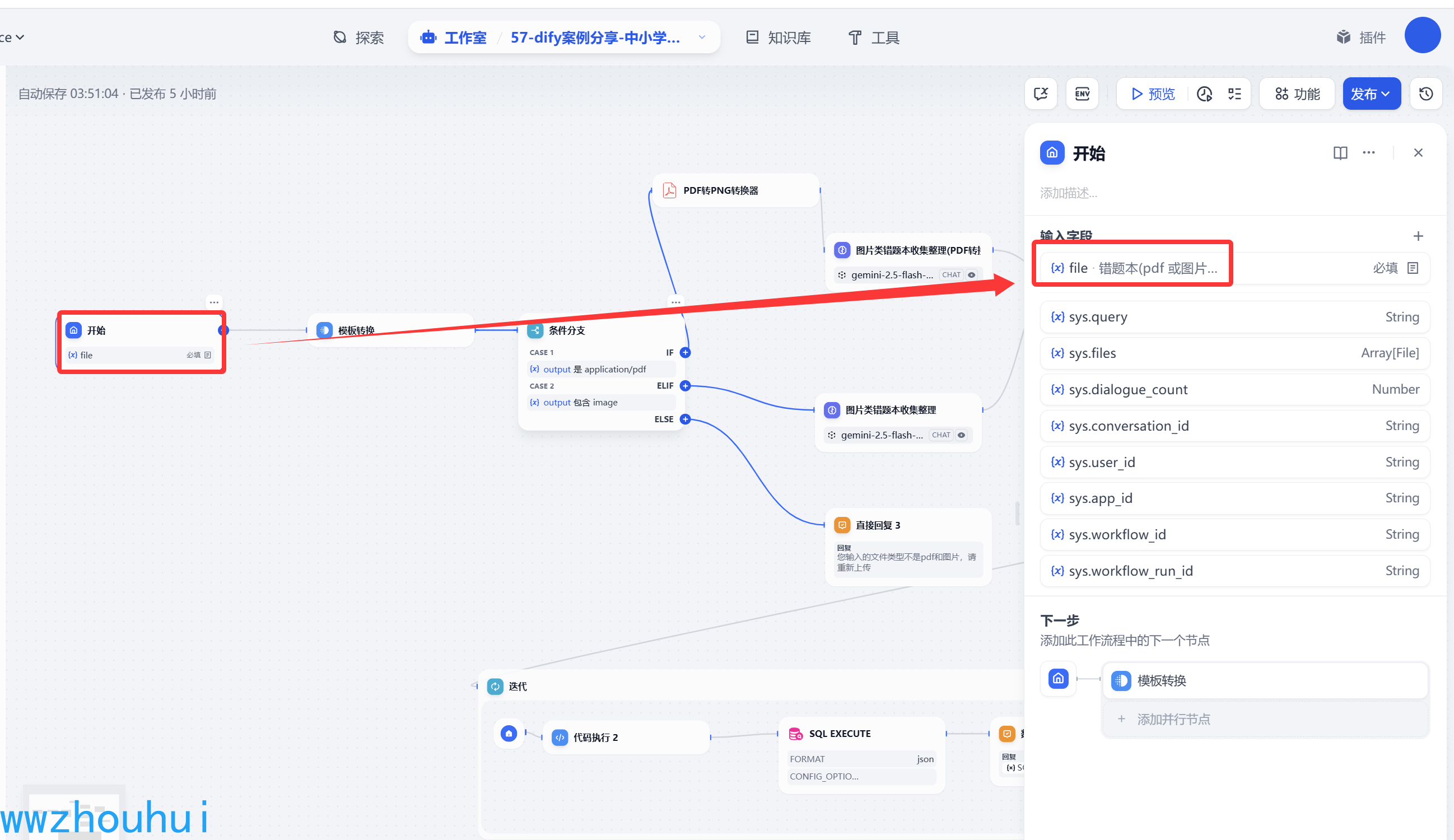
模板转换
这里我们考虑到用户输入的有可能是PDF、也有可能是图片,我们需要通过模板转换获取filetype 这个文件的类型。
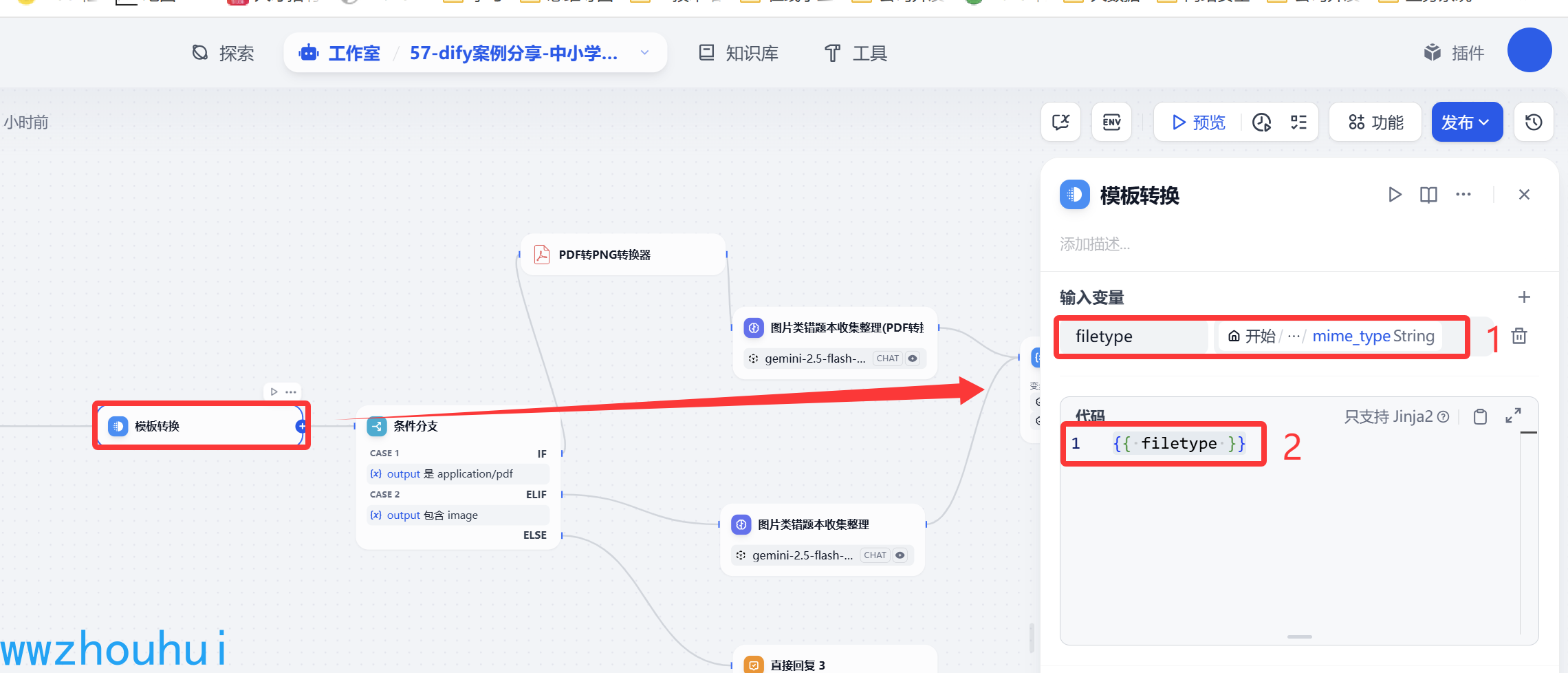
输入变量这里我们设定一个参数:filetype 对应的值 从file 文件中获取mime-type
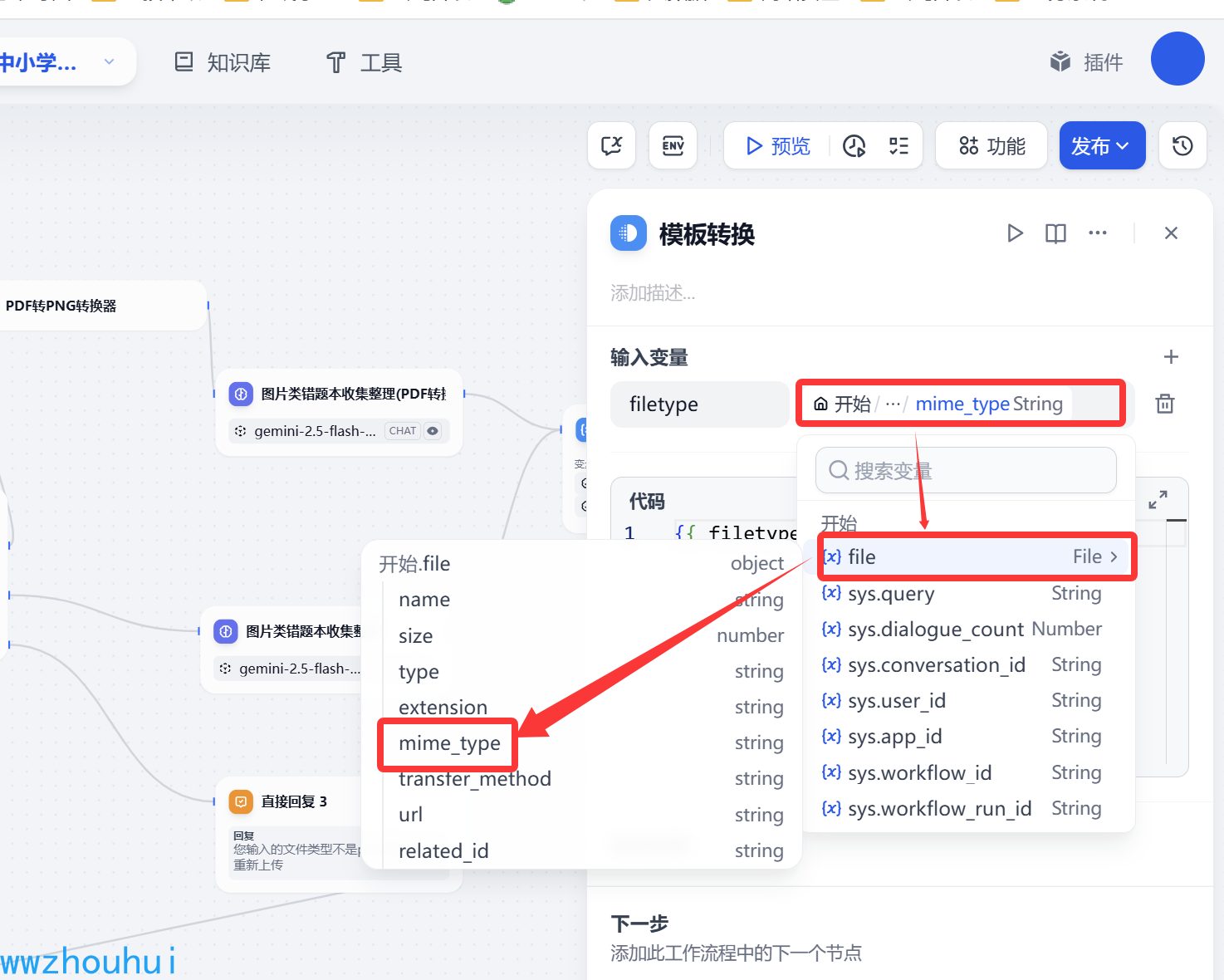
模板转换 代码部分内容如下:
{{ filetype }}
条件分支
这个地方主要的是目的是通过前面模板转换获取的filetype 判断文件属性是PDF 还是image
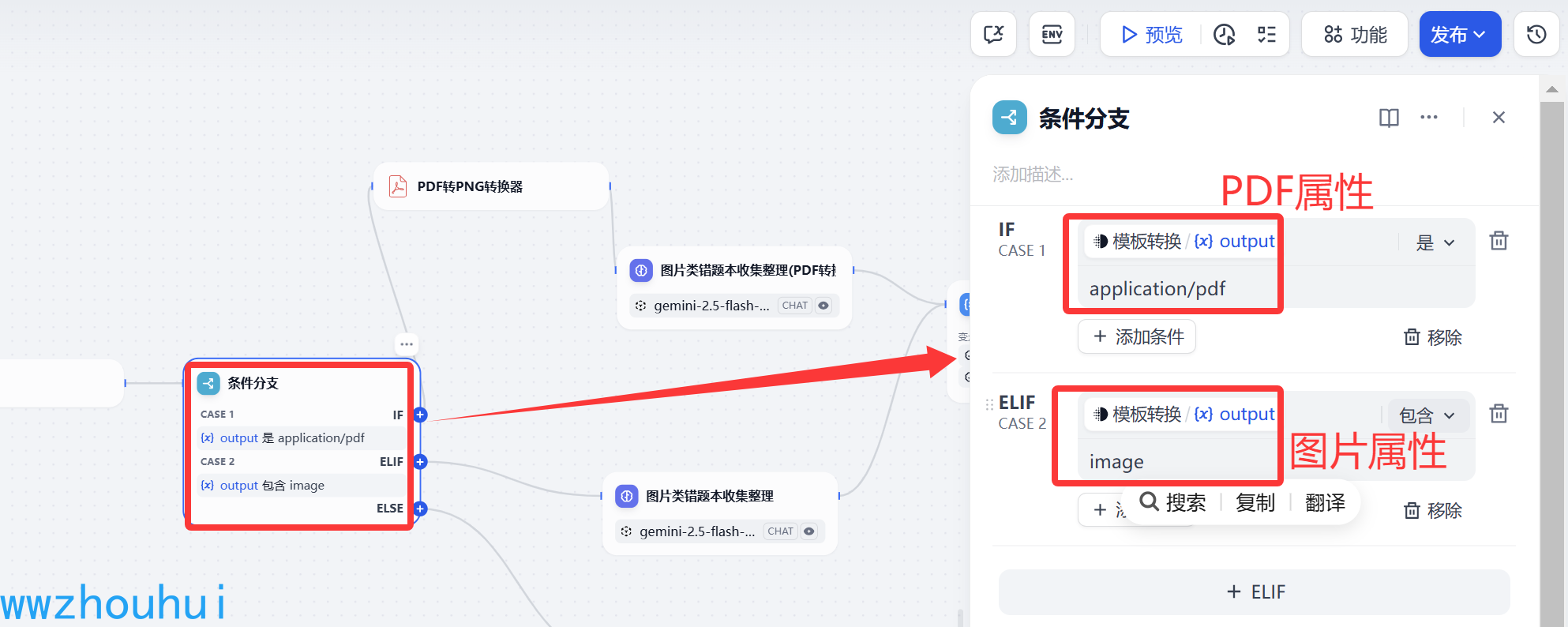
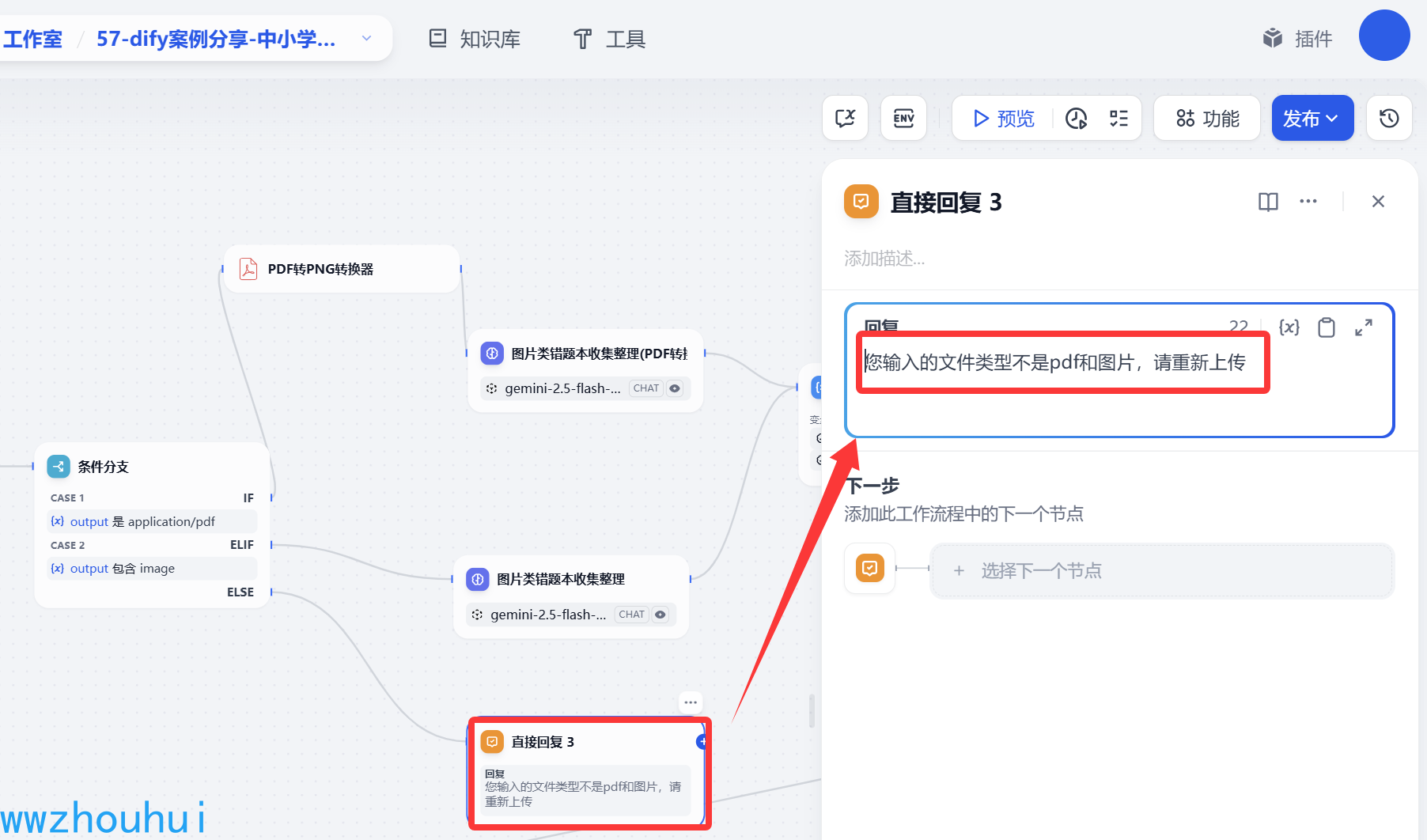
2个添加分之分别对应 PDF处理和图片处理,当然后面如果用户输入的不是这个两个文件格式类型,系统为了保证系统可用不是这2个文件类型直接返回一个错题信息提醒,我们这里直接使用回复提醒用户:
PDF转PNG转换器
上面IF条件分支如果用户上传的PDF文件,我们需要借助PDF转换工具实现PDF转图片功能。
llm大语言模型
接下来我们使用多模态大语言模型实现用户上传的图片或者PDF转PNG转换后的图片进行OCR识别。
这里我们使用的了google gemini2.5-flash-preview-05-20模型,当然如果你需要效果好可以使用付费版本的gemini-2.5-pro-preview-05-20。这个模型是需要google 付费会员的,如果大家没有也可以推荐大家使用302.AI网站上提供的gemini-2.5-pro-preview-05-06版本的模型。
网站地址https://share.302.ai/TjtOq6
在api超市里面可以选择 gemini模型
点开模型列表选择gemini-2.5-pro-preview-05-06
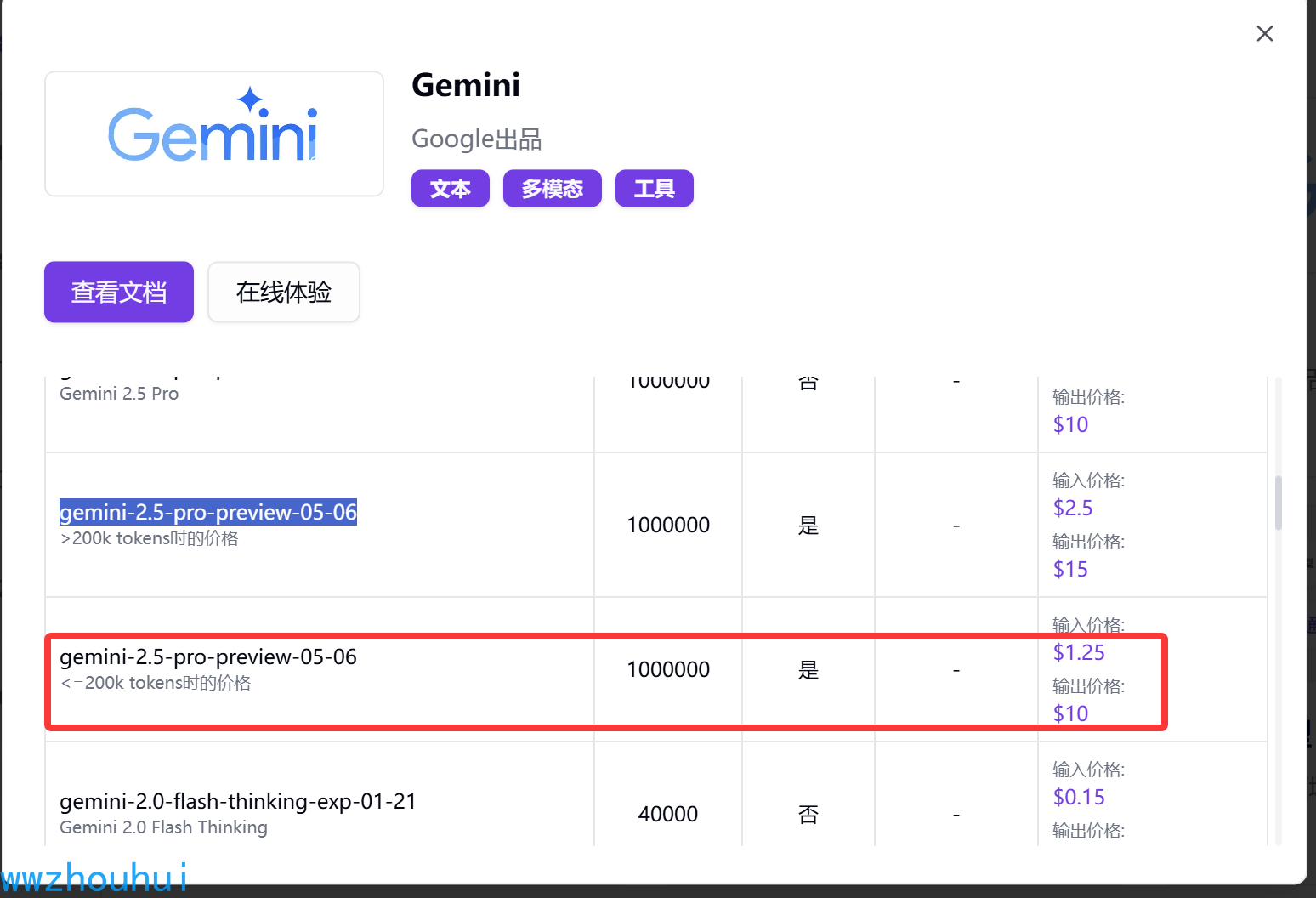
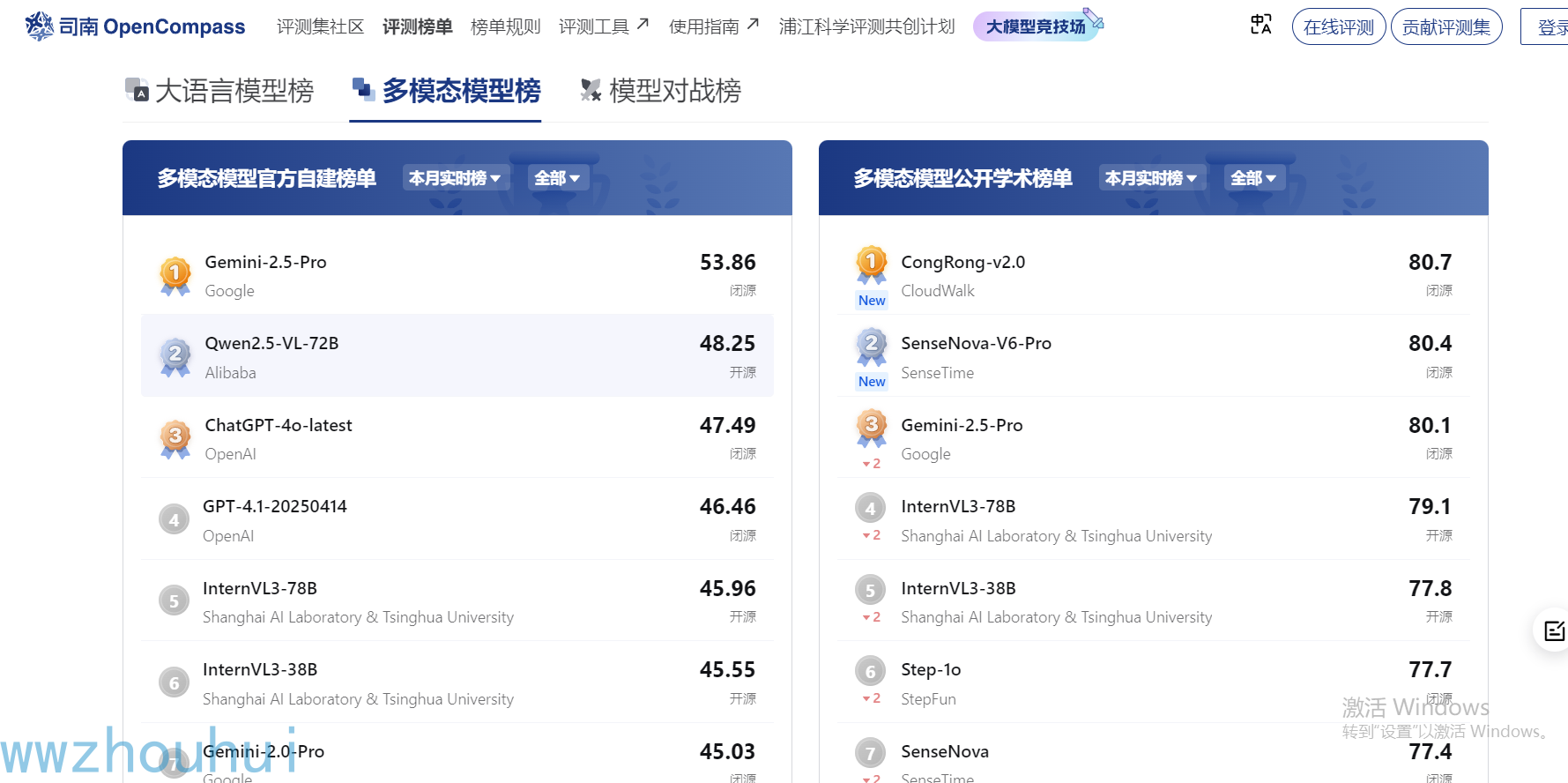
为什么推荐大家使用google gemini-2.5-pro-preview-05-06或者gemini-2.5-pro-preview-05-20 模型,因为错题本的识别我测试下来它应该是最好的,大家也可以查看上海人工智能实验室一个模型评测平台https://rank.opencompass.org.cn/home
系统提示词
# 角色定义
你是一位中小学错题收集与整理专家,擅长从学生的考试题目中提取错误题目,并按照题型(选择题、填空题、判断题、问答题)进行分类归纳。你会为每道错题提供正确答案,并生成一份结构化的错题本,以JSON格式呈现
,便于学生复习和存入数据库。
# 任务目标
根据用户提供的考试题目和错误信息,完成以下任务:
1. **提取错误题目**:识别并提取所有答错的题目。
2. **分类整理**:将错误题目按照以下四类进行分类:
- **选择题**
- **填空题**
- **判断题**
- **问答题**
3. **JSON格式输出**:
- 生成一个包含所有题目的JSON对象。
- 即使某类题型没有错题,也保留该类型的空数组。
4. **符合数据库结构**:确保输出的JSON格式符合给定的数据库表结构。
# 输入格式
请提供以下信息:
- 考试题目列表(包括题干、选项(如有)、学生答案和正确答案)。
- 学生的错误标记(哪些题目是错误的)。
- 学科信息。
- 难度等级(1-5)。
# 输出格式
生成一份JSON格式的错题本,结构如下:
```json
{
"error_questions": [
{
"question_text": "题目内容",
"subject": "学科名称",
"question_type": "题目类型",
"difficulty": "难度等级",
"answer": "正确答案",
"user_answer": "用户答案",
"explanation": "解析(如有)"
},
// ... 更多题目
]
}
视觉模型我们需要开启,另外我们需要选择转换后的图片
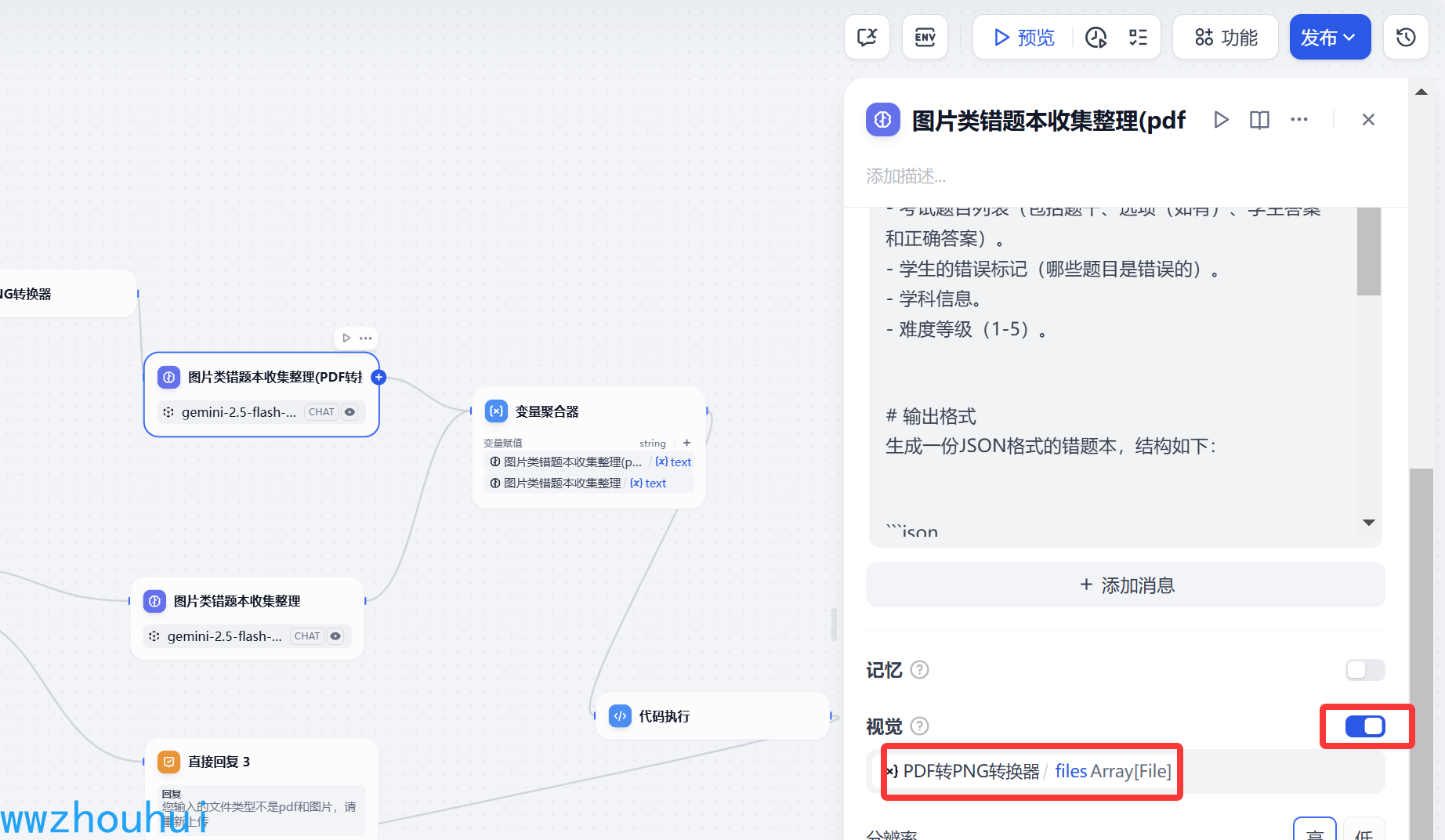
下面的多模型模型设置也是一样的。
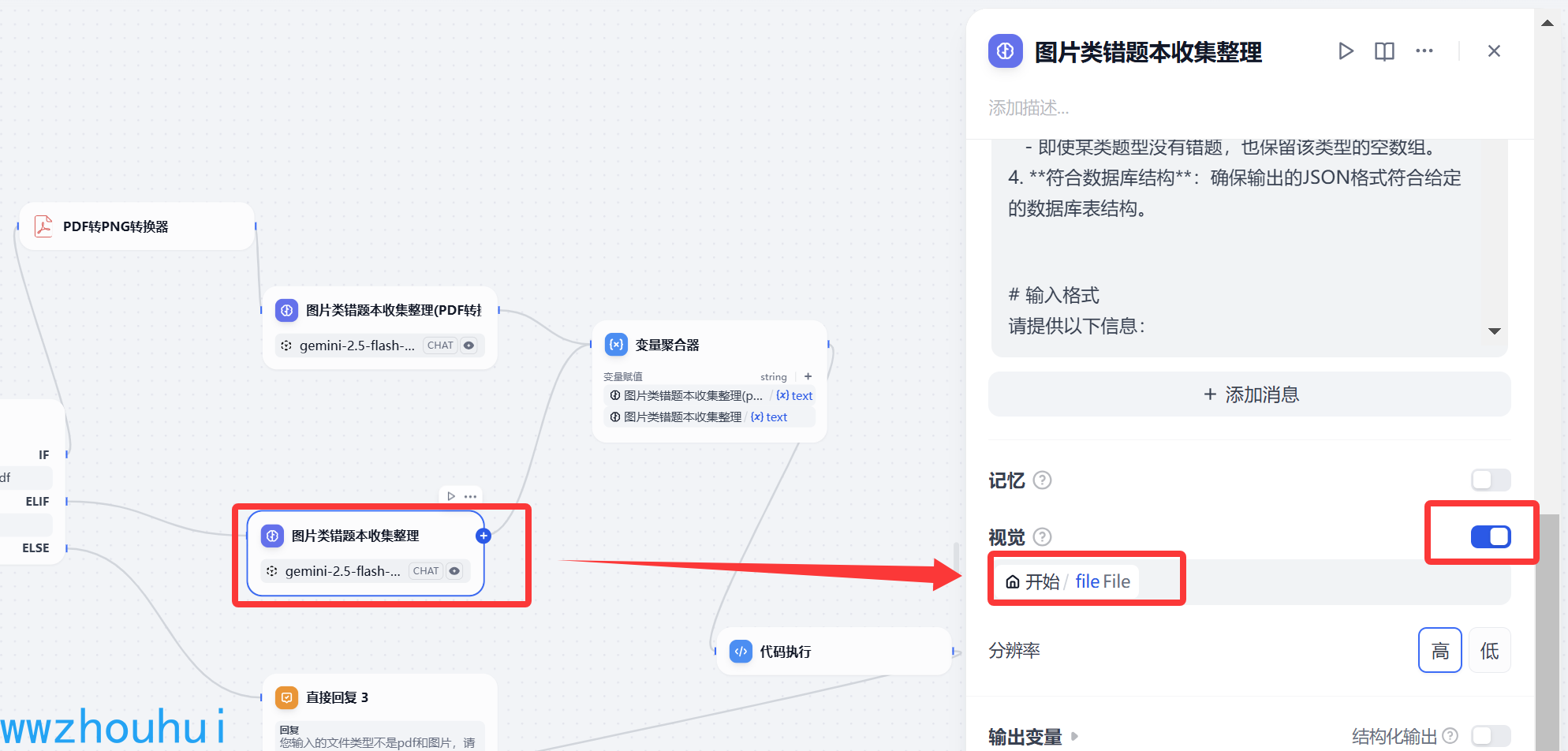
这里我们强调一下,我们使用提示词让多模态大模型把错题识别解析出来并生成固定格式的数据,方便我们后面把信息写入到数据库中。
# 输出格式
生成一份JSON格式的错题本,结构如下:
```json
{
"error_questions": [
{
"question_text": "题目内容",
"subject": "学科名称",
"question_type": "题目类型",
"difficulty": "难度等级",
"answer": "正确答案",
"user_answer": "用户答案",
"explanation": "解析(如有)"
},
// ... 更多题目
]
}
注意只需要返回json格式的内容信息,不要输出其他内容
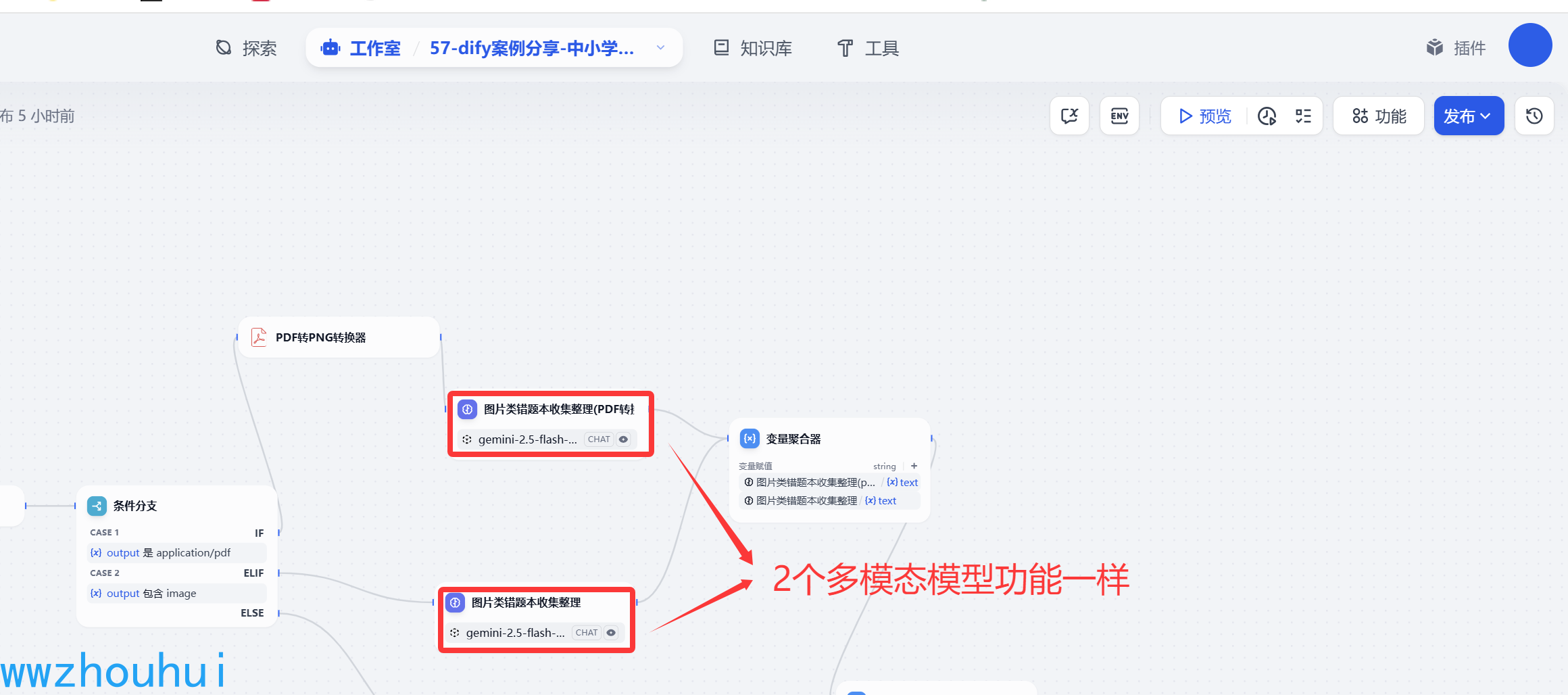
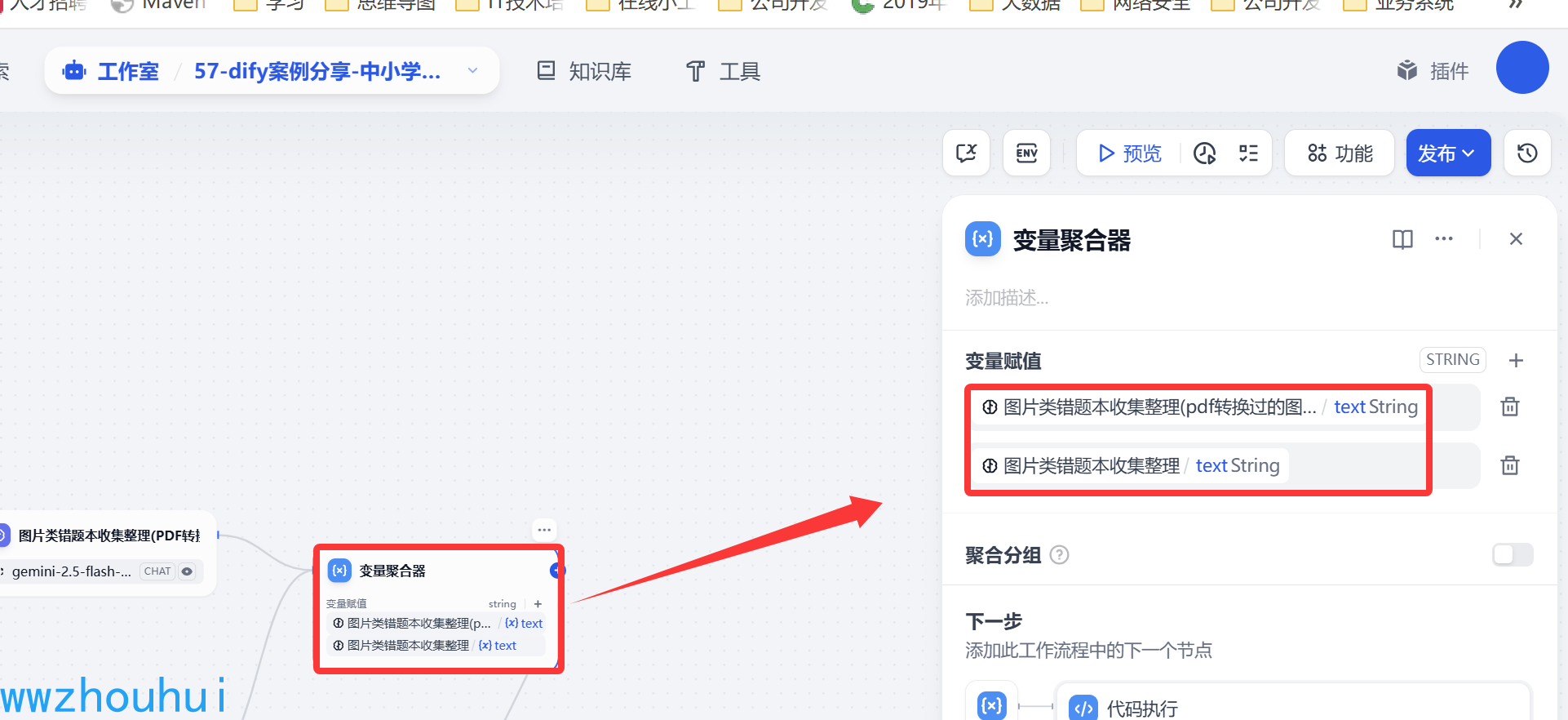
变量聚合器
2个多模态模型输出的内容是一样的,所以我们把2个流程合并,使用一个叫做变量聚合器的工具把输出结果统一。
变量赋值的部分是2个多模态模型的输出
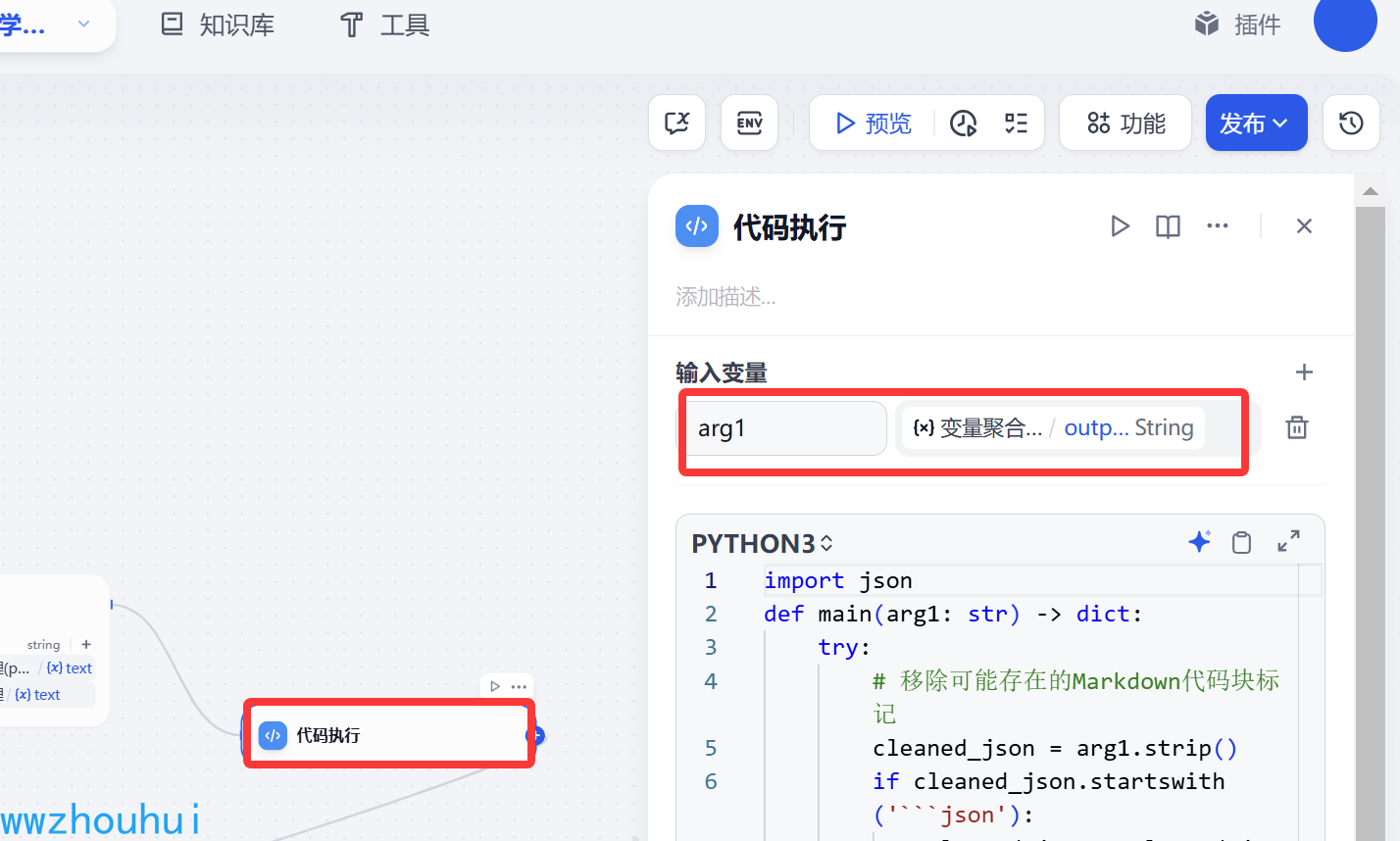
代码执行
这个代码执行目的是把变量聚合器输出的信息转换成字典信息,方便后面处理。
输入的参数arg1 输入的内容是上个流程节点的输出(变量聚合器输出)
变量聚合器输出内容大概是下面数据格式
{
"error_questions": [
{
"question_text": "若 x+y=1, xy=-2,则 (2-x)(2-y) 的值为",
"subject": "数学",
"question_type": "选择题",
"difficulty": 3,
"answer": "0",
"user_answer": "B",
"explanation": ""
},
{
"question_text": "已知 x²+y²=22, xy=7,那么 (2x-y)(x-2y) 的值为",
"subject": "数学",
"question_type": "填空题",
"difficulty": 3,
"answer": "9",
"user_answer": "-139",
"explanation": ""
},
{
"question_text": "计算: (a+1)(a²-2a+3)",
"subject": "数学",
"question_type": "问答题",
"difficulty": 2,
"answer": "a³ - a² + a + 3",
"user_answer": "a³ - a² + a + 3",
"explanation": ""
}
]
}
处理的代码如下:
import json
def main(arg1: str) -> dict:
try:
# 移除可能存在的Markdown代码块标记
cleaned_json = arg1.strip()
if cleaned_json.startswith('```json'):
cleaned_json = cleaned_json[7:]
if cleaned_json.endswith('```'):
cleaned_json = cleaned_json[:-3]
# 处理转义字符,并确保正确的编码处理
# cleaned_json = cleaned_json.encode('utf-8').decode('unicode_escape').encode('latin1').decode('utf-8')
# **替换转义符**:将 \\n 转为 \n(适用于 JSON 中用双反斜杠表示换行的场景)
cleaned_json = cleaned_json.replace('\\\\n', '\\n') # 将四个反斜杠转为两个(JSON 标准转义)
# 将 JSON 字符串解析为 Python 字典
result_dict = json.loads(cleaned_json)
return {"error_questions": result_dict["error_questions"]} # 返回解析结果
except json.JSONDecodeError as e:
return {"error": f"JSON 解析失败: {e}"}
except Exception as e:
return {"error": f"发生未知错误: {e}"}
输出变量是error_questions 是一个数组对象。(因为一张图片 可能会出现多个错题,所以我们用数组对象输出)
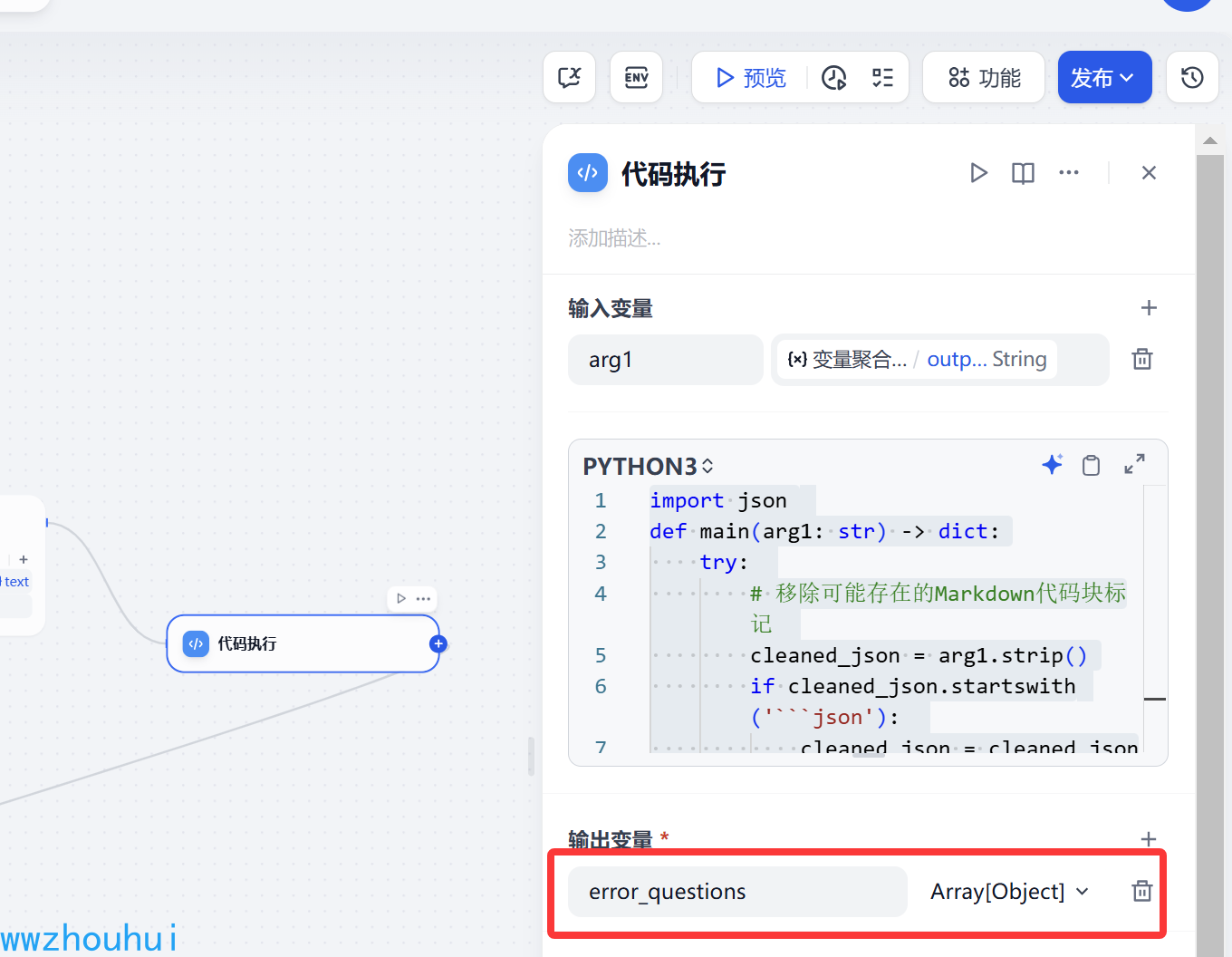
迭代
这里我们用到了dify工作流的迭代。
输入参数:error_questions 数据对象
输出参数:sql Execute
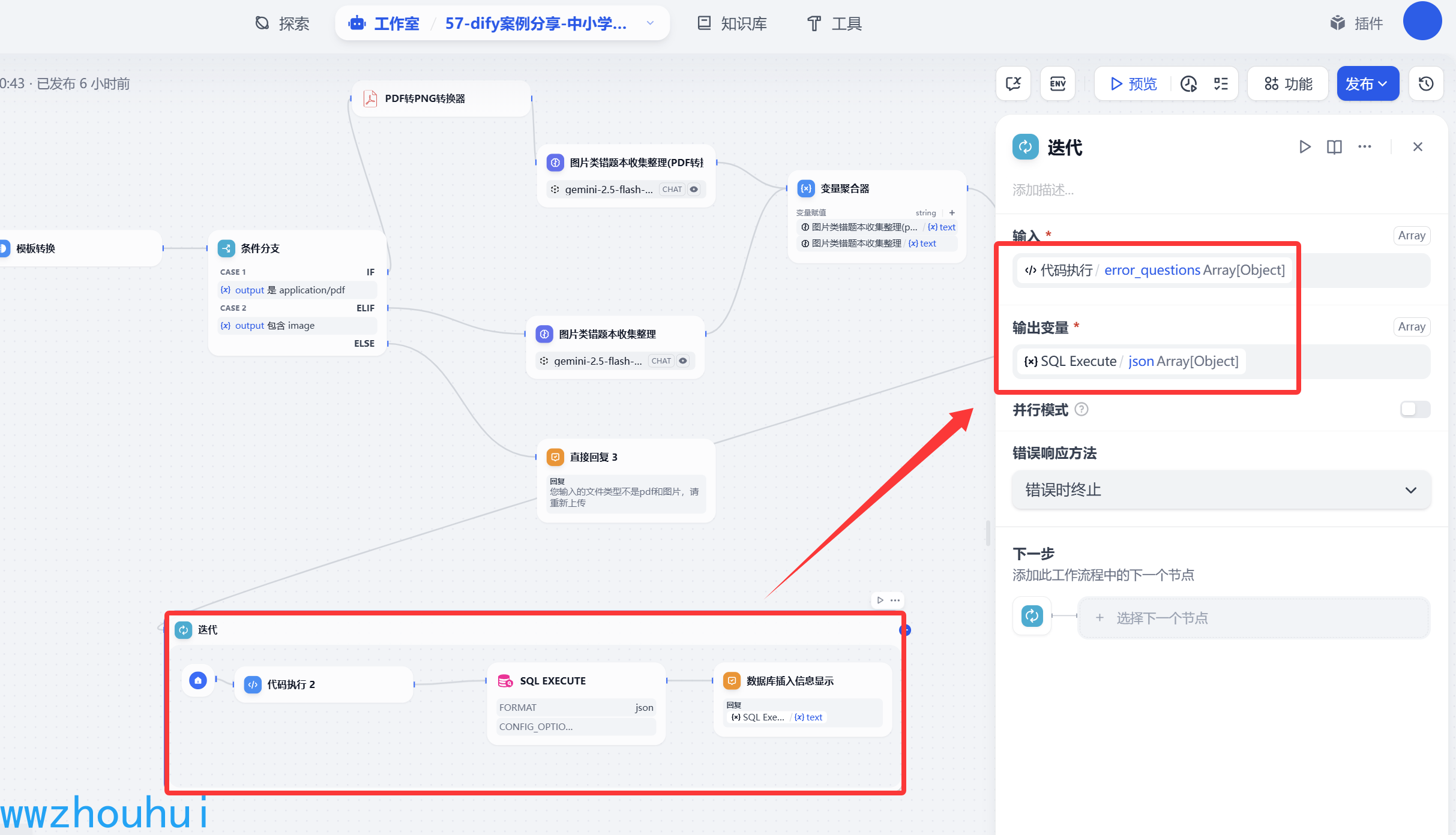
在迭代里面我们大概有3个子组件实现迭代出来
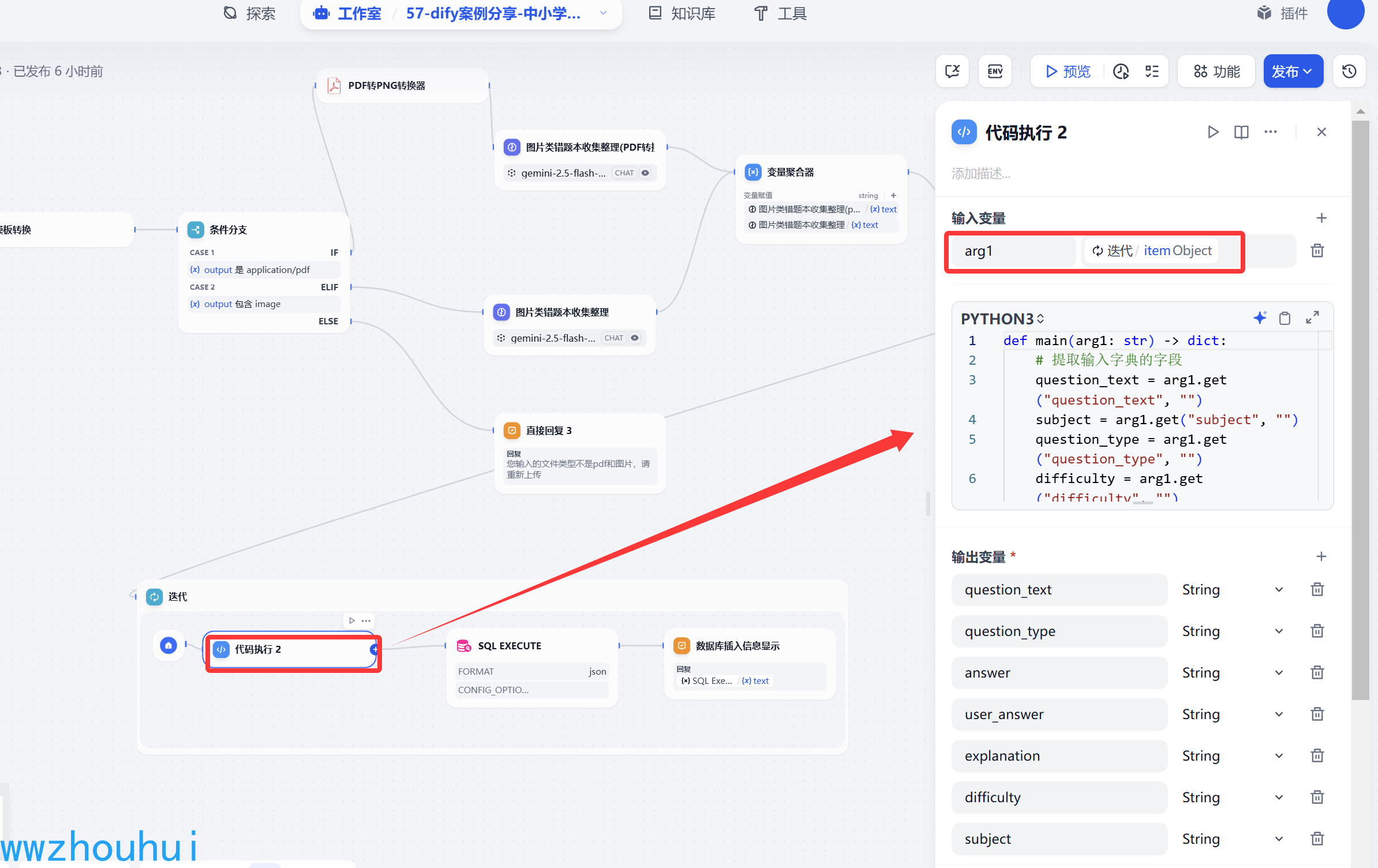
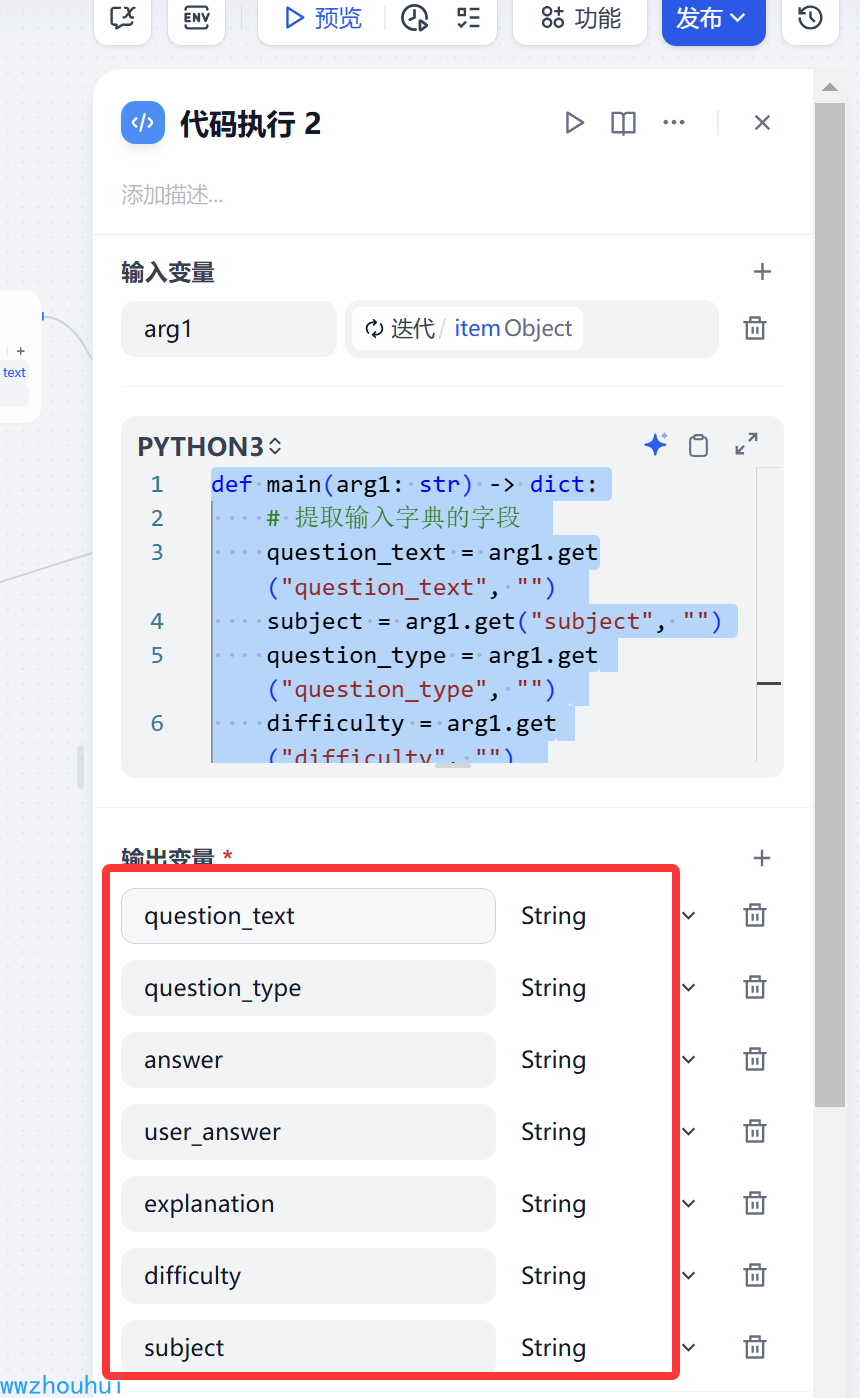
代码执行
这个代码执行可以理解就是我们通过循环数组把数组里面的字典数据取出
输入变量 arg1 输入参数 迭代/item object
处理的代码
def main(arg1: dict) -> dict:
# 提取输入字典的字段
question_text = arg1.get("question_text", "")
subject = arg1.get("subject", "")
question_type = arg1.get("question_type", "")
# 确保 difficulty 是字符串类型
difficulty = arg1.get("difficulty", "")
if not isinstance(difficulty, str):
difficulty = str(difficulty)
answer = arg1.get("answer", "")
user_answer = arg1.get("user_answer", "")
explanation = arg1.get("explanation", "")
# 返回包含所有字段的字典
return {
"question_text": question_text,
"subject": subject,
"question_type": question_type,
"difficulty": difficulty, # 确保此处为字符串
"answer": answer,
"user_answer": user_answer,
"explanation": explanation
}
返回,这个返回字段内容比较多,对应上面的return返回
SQL Execute
这里我们需要用的database 第三方组件。
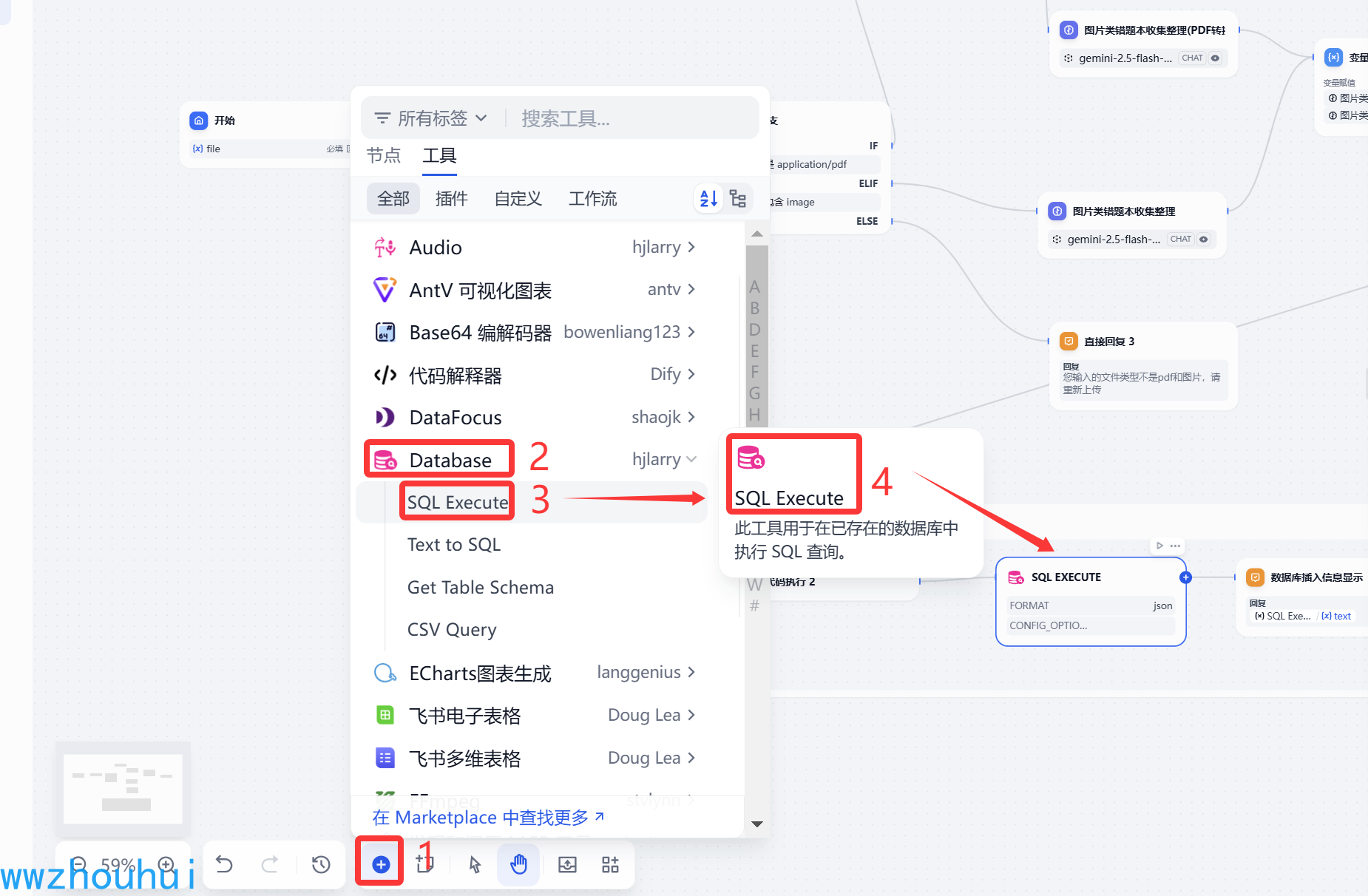
输入变量这里我们填写下面的SQL
INSERT INTO error_questions
(question_text, subject, question_type, difficulty, answer, user_answer, explanation)
VALUES
('{{#1747669724911.question_text#}}','{{#1747669724911.subject#}}','{{#1747669724911.question_type#}}','{{#1747669724911.difficulty#}}','{{#1747669724911.answer#}}','{{#1747669724911.user_answer#}}','{{#1747669724911.explanation#}}');
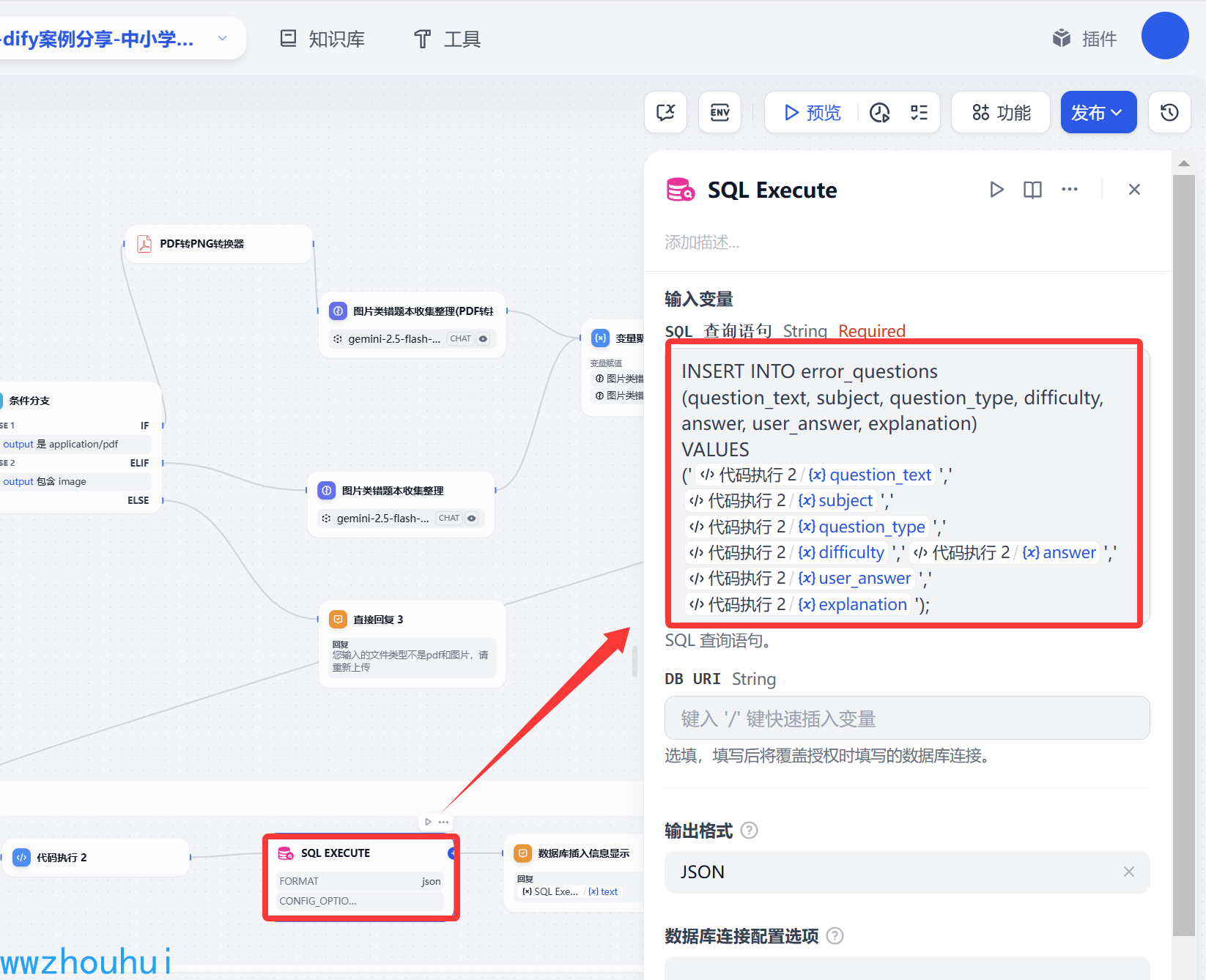
这里我们用到了数据库相关知识,我们需要提前在数据库创建一个叫做error_questions 表。
表结构内容如下:
CREATE TABLE error_questions (
id INT PRIMARY KEY AUTO_INCREMENT,
question_text TEXT NOT NULL COMMENT '题目内容',
subject VARCHAR(50) NOT NULL COMMENT '学科',
question_type VARCHAR(50) NOT NULL COMMENT '题目类型',
difficulty TINYINT NOT NULL COMMENT '难度等级(1-5)',
answer TEXT COMMENT '答案',
user_answer TEXT COMMENT '用户答案',
explanation TEXT COMMENT '解析',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
);
我们需要用数据库客户端工具,比如Navicat Premium 把表创建好。
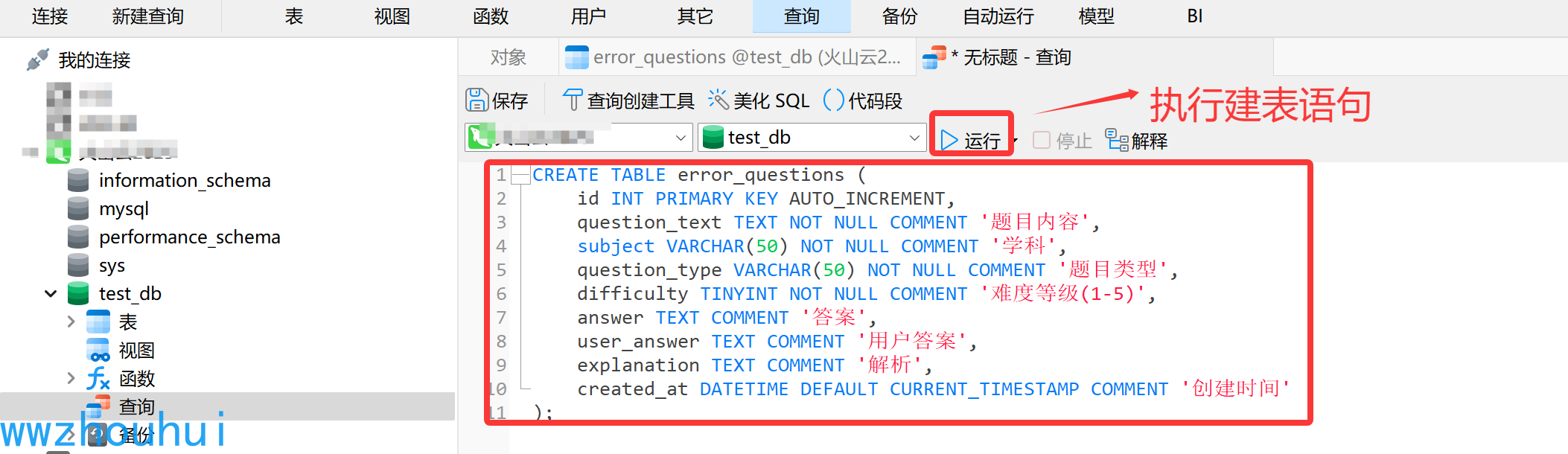
数据库链接配置这块 可以看我前面的文章《dify案例分享-基于database插件实现Text2sql的数据库查询图表工作流》 这里就不做详细展开。
直接回复
这里我们为了方便调试,在循环迭代里面使用直接回复。里面有2个值1个是变量聚合器输出,1个是SQL 执行输出
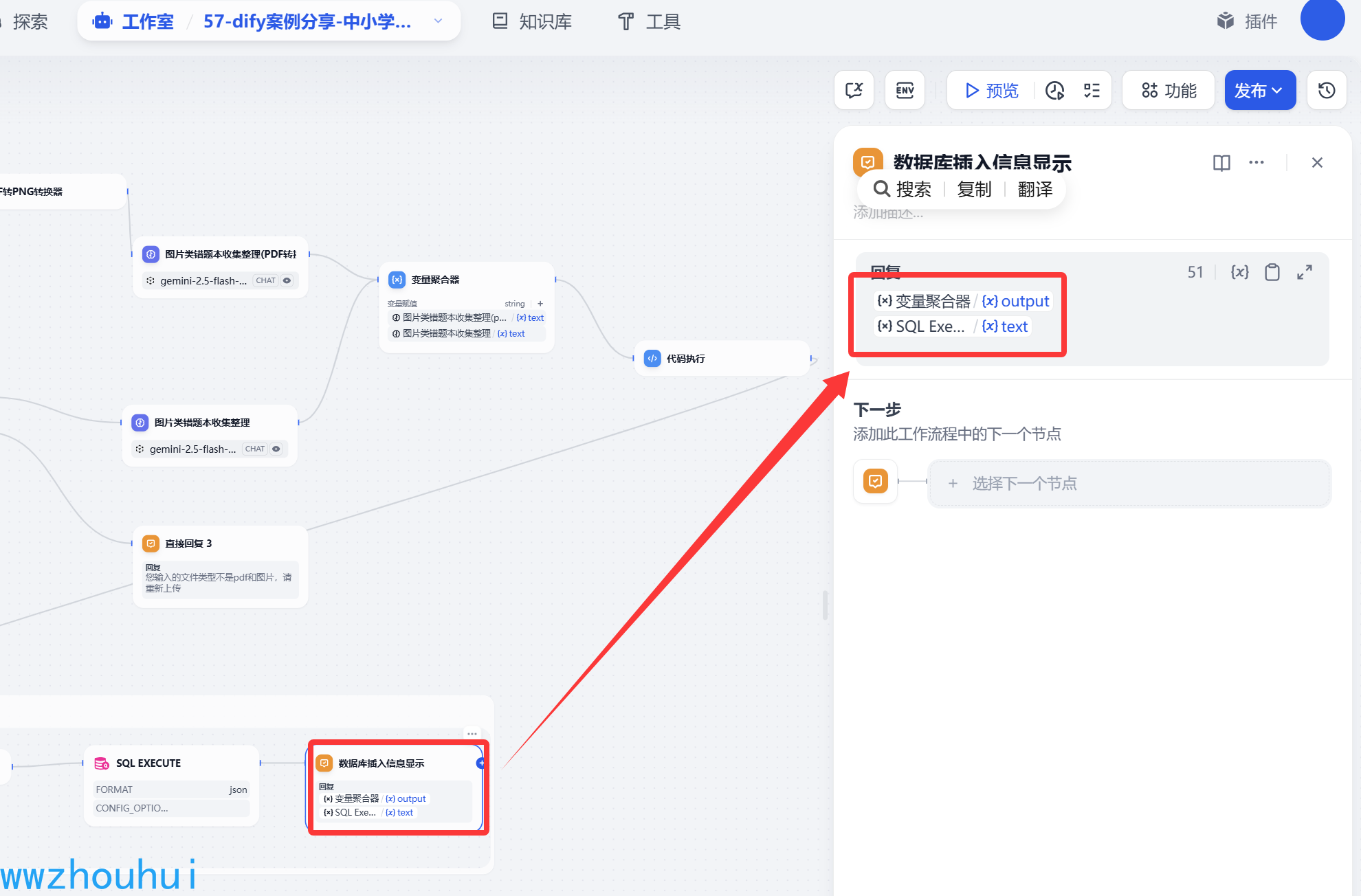
以上我们就完成了错题本的收集整理工作流了。
目前这个工作流只完成了第一阶段问题收集整合工作,后面我们需要基于这个错题本生成同类型错题并生成错题和打印功能。感兴趣的小伙伴可以持续关注。
3.验证及测试
我们制作好的工作流可以在工作流平台上验证测试一下,点击左上角“预览”按钮,
测试数据连接地址:
图片版 https://halo-1258720957.cos.ap-shanghai.myqcloud.com/2025test/%E5%8E%9F%E5%A7%8B%E8%AF%95%E5%8D%B71.png
PDF版 https://halo-1258720957.cos.ap-shanghai.myqcloud.com/2025test/2025-02-11%2021.56_11.pdf
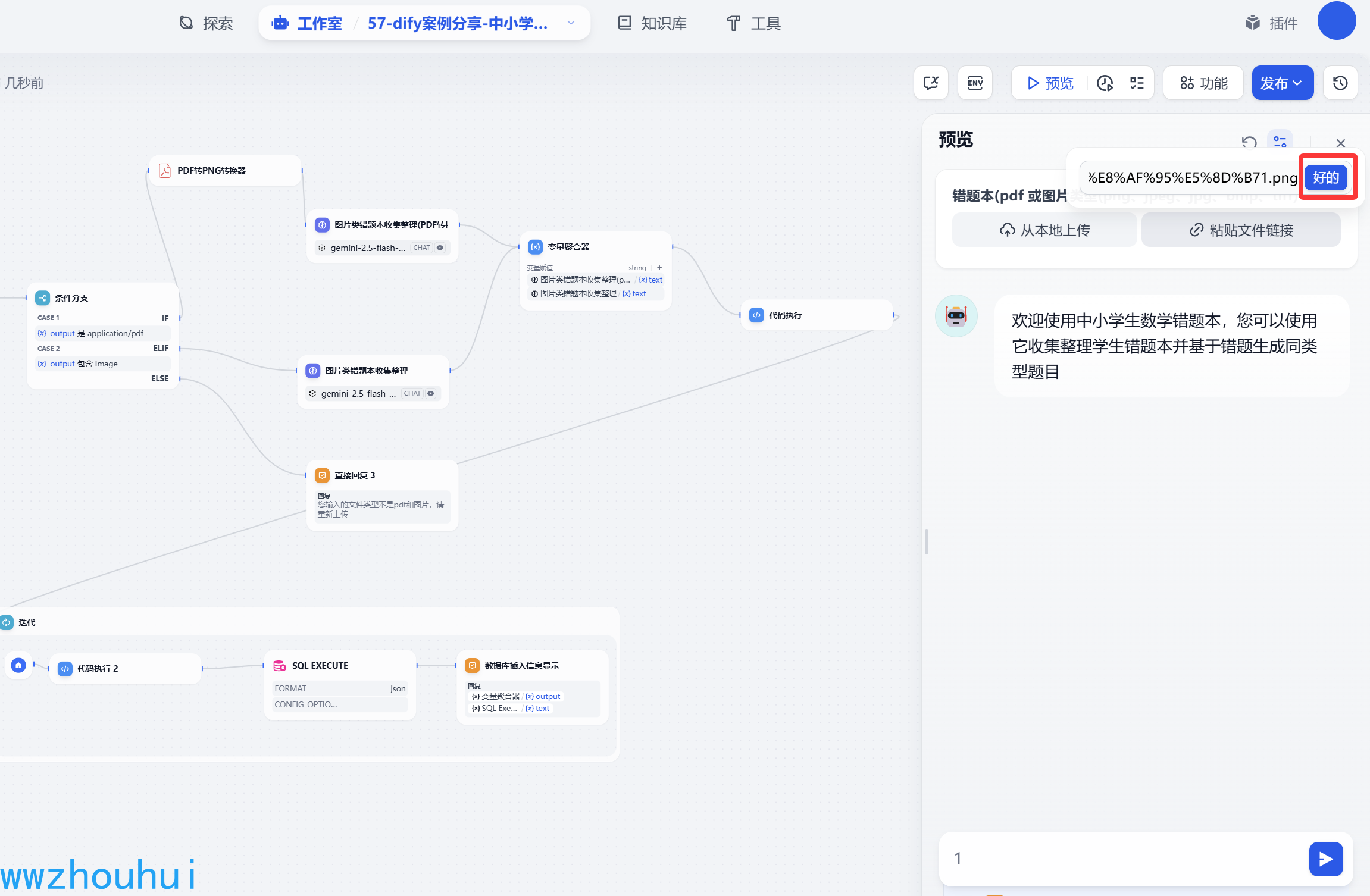
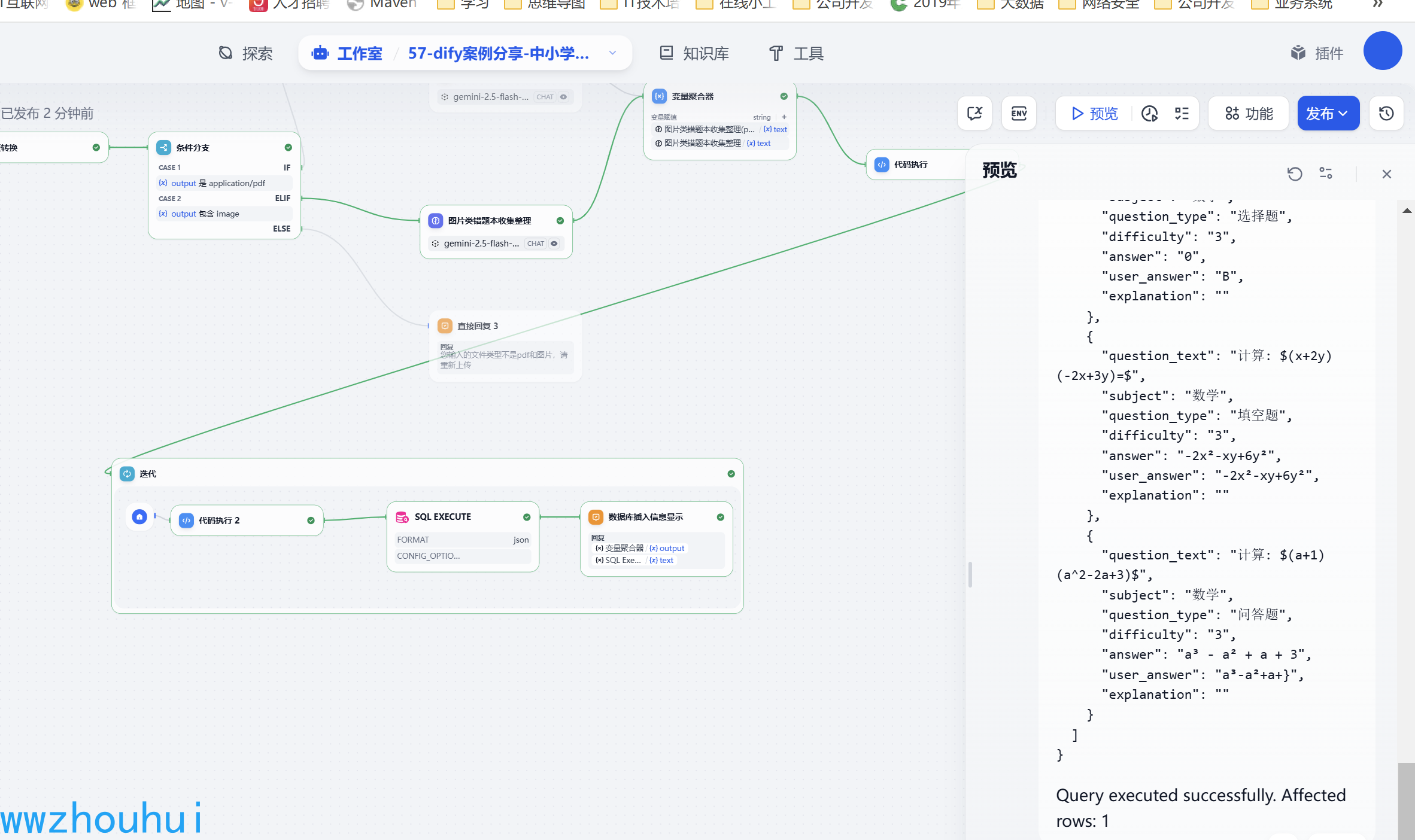
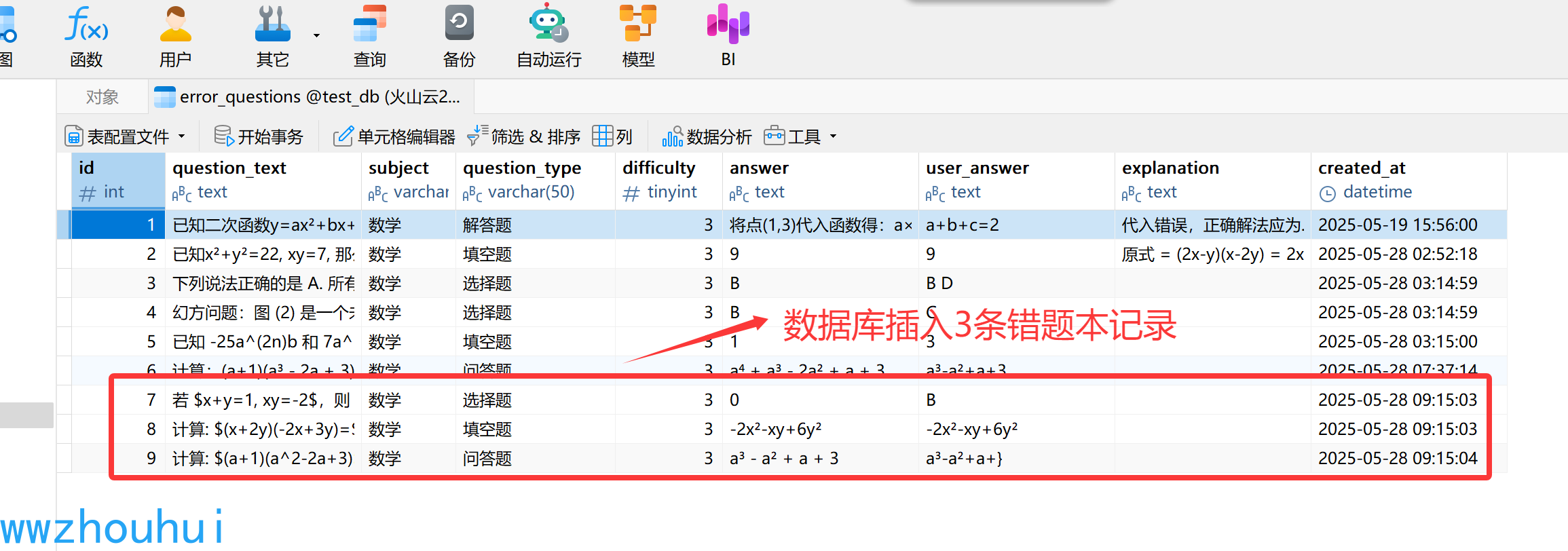
这样我们就完成了中小学错题本收集整理的工作流-第一阶段制作和测试了。 PDF的功能和图片类似,这里就不做举例。
体验地址
工作流地址:https://dify.duckcloud.fun/chat/MXyFiUlFctTnNVtl备用地址(http://14.103.204.132/chat/MXyFiUlFctTnNVtl)
相关资料和文档可以看我开源的项目 https://github.com/wwwzhouhui/dify-for-dsl
4.总结
今天主要带大家了解并实现了利用 Dify 工作流完成中小学数学错题本收集整理的功能。借助 Dify 丰富的插件和灵活的工作流设计能力,我们通过新建工作流,依次添加开始、模板转换、条件分支、pdf 转 png 转换器、基于多模态 llm 大语言模型、变量聚合器、代码执行、迭代、SQL Execute 等节点,成功搭建了一个可以收集学生或家长上传的 PDF 和图片格式错题信息,并使用多模态大模型 OCR 识别功能将错题收集整理写入数据库的工作流。
这个工作流能够大大提高错题收集整理的效率,帮助学生及时发现自己的知识盲点,有针对性地进行复习和提升,避免在同样的问题上犯错。无论是学生自主学习还是家长辅助辅导,都能快速准确地将错题进行分类整理,形成有效的错题本。目前该工作流只完成了第一阶段的错题收集整合工作,后续我们还将基于此错题本生成同类型错题并实现打印功能。感兴趣的小伙伴可以按照本文的步骤进行尝试,相信会为学生的学习带来便利。(未完待续 …)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









