






1.前言
很多小伙伴之前和我提过想实现dify聊天历史记录一键保存文档word等文档。我们知道目前很多大语言模型是天然支持markdown文档的。也就是聊天对话的内容是可以让打语言模型输出markdown语法格式的文件内容的。那么我们在聊天对话中让他调用生成word一个插件是不是就能够实现word保存功能呢?
OK 我们基于整个思路在dify市场上找到了一款markdown转word插件,接下来我们用他们来实现这个功能。
2.markdown转word插件
dify 在1.0+的版本增强了插件市场功能,有更多丰富的插件来实现功能的扩展。我们在marketplace 搜到 doc
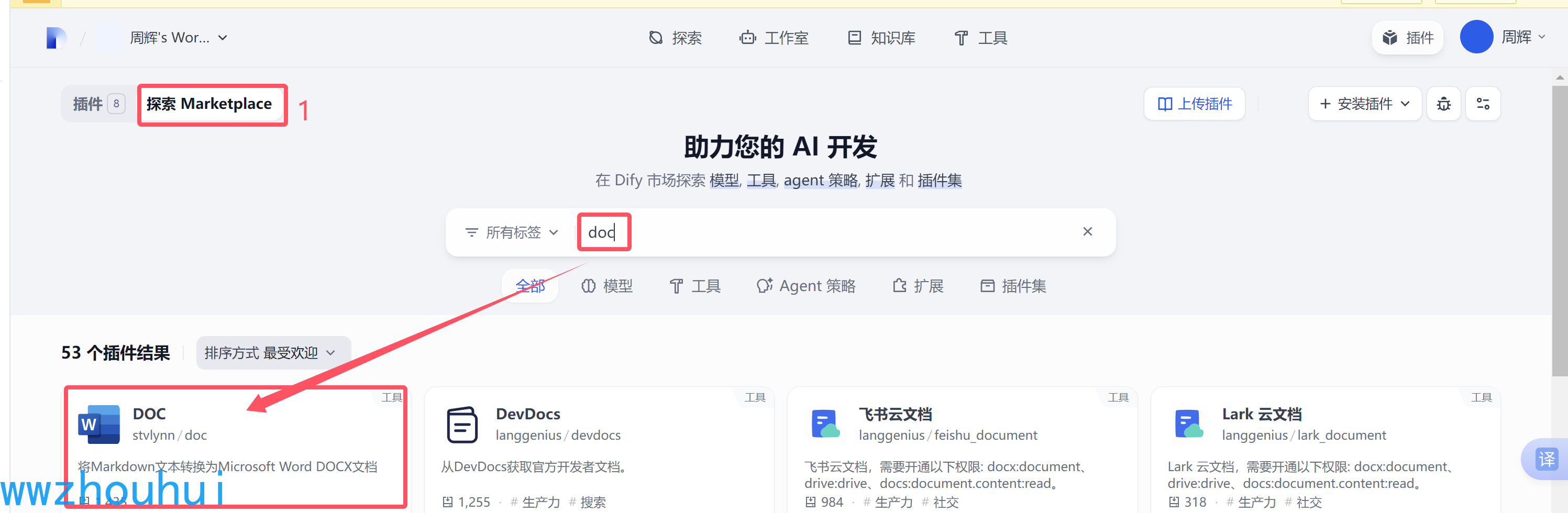
点击这个插件就可以完成插件的安装了。
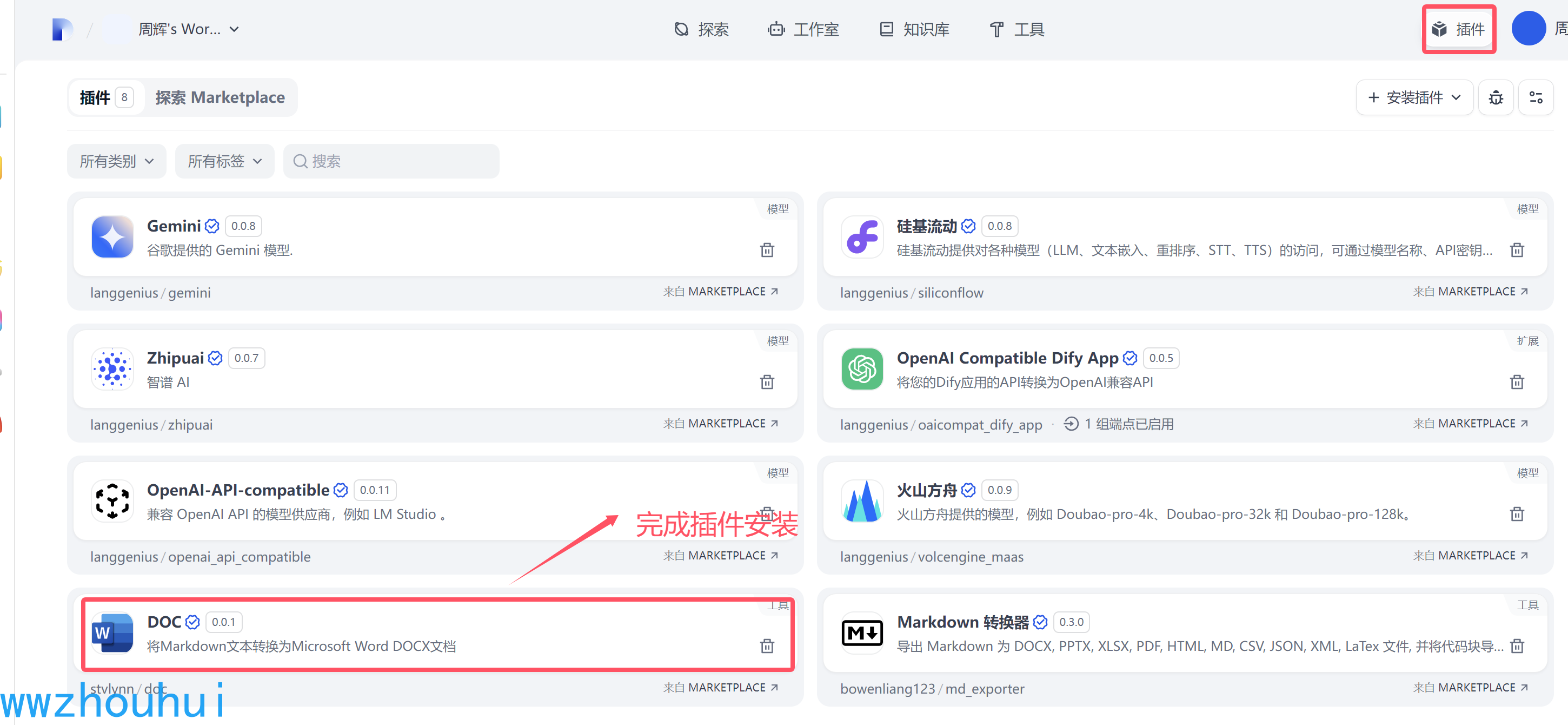
插件安装
我创建一个AI 智能体
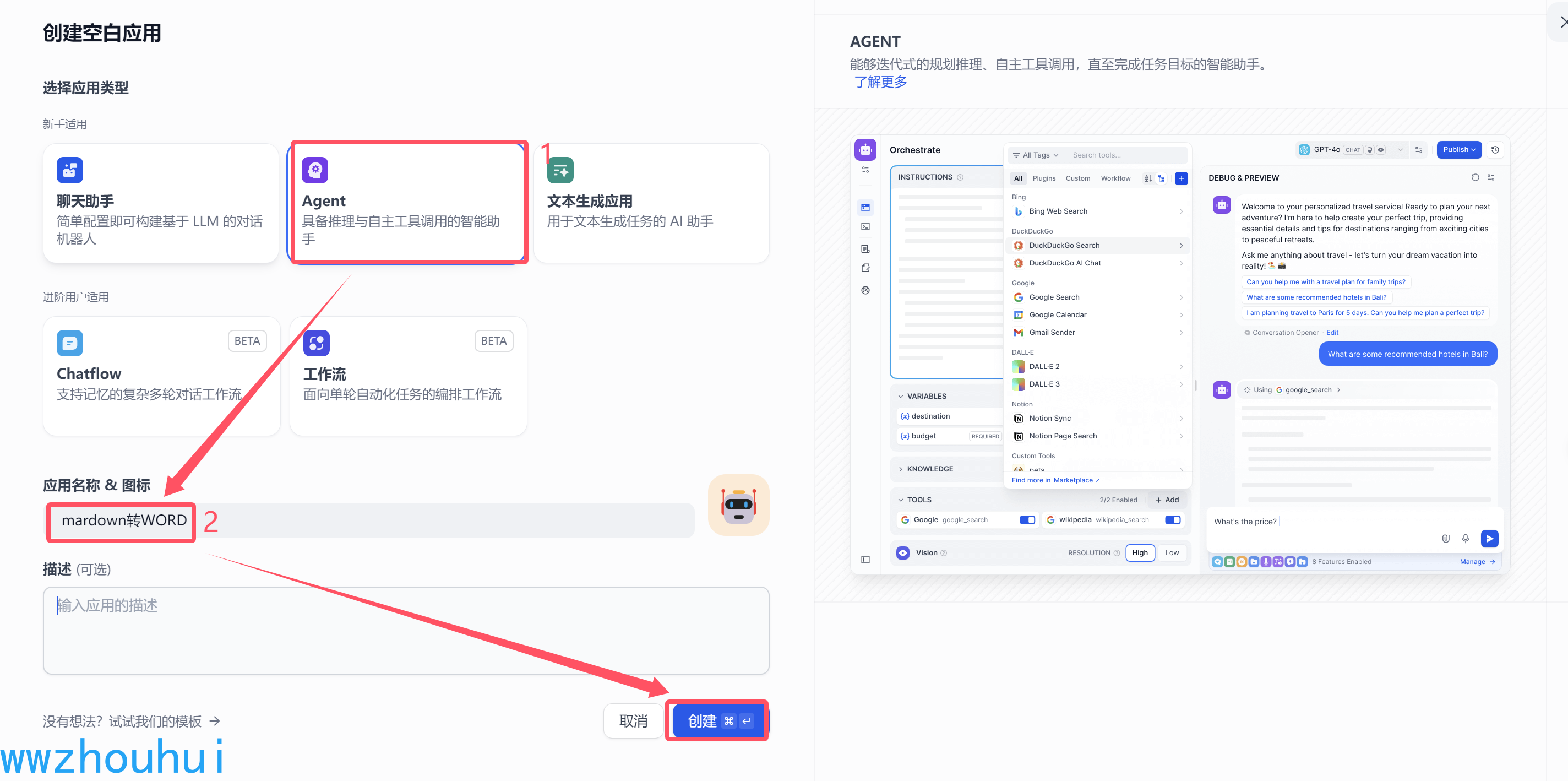
按照上面1、2、3步骤完成智能体的创建。
我们在左下角工具添加-doc插件
模型这里我们选择火山引擎的deekseek-v3模型,这里要注意不是所有的模型都支持function call,需要模型具有function call的功能,而且最好选择大一点尺寸模型,太小模型不聪明调动 AI Agent是出问题。
插件使用
我在聊天对话窗口中输入如下内容:
请帮我写一个儿童故事绘本关于白雪公主和七个小矮人的故事,内容markdownn格式显示,最后调用doc markdownn转word工具生成word
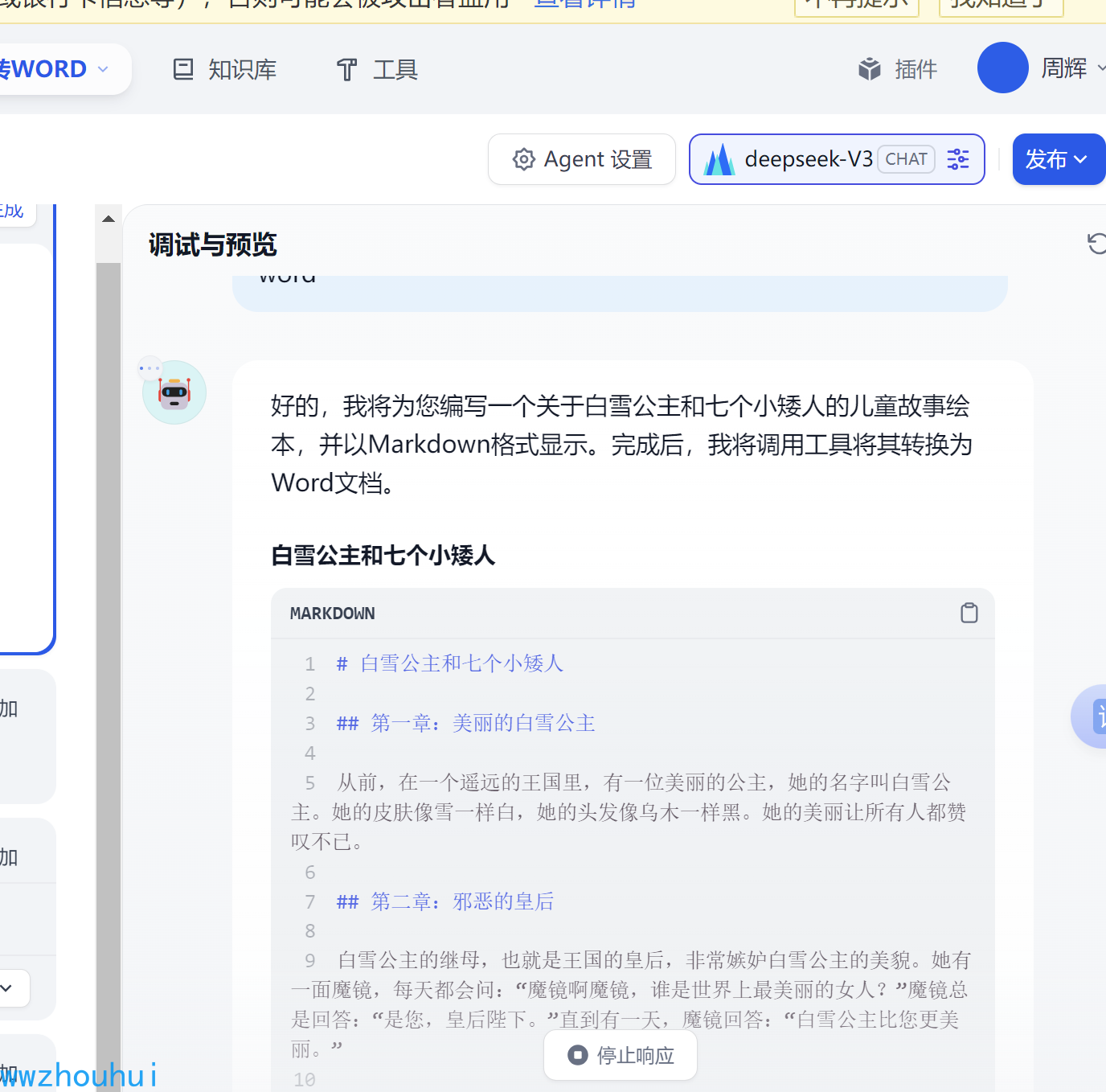
智能体会更加我们要求生成markdownn格式的内容,并调用智能体工具doc 生成word文档
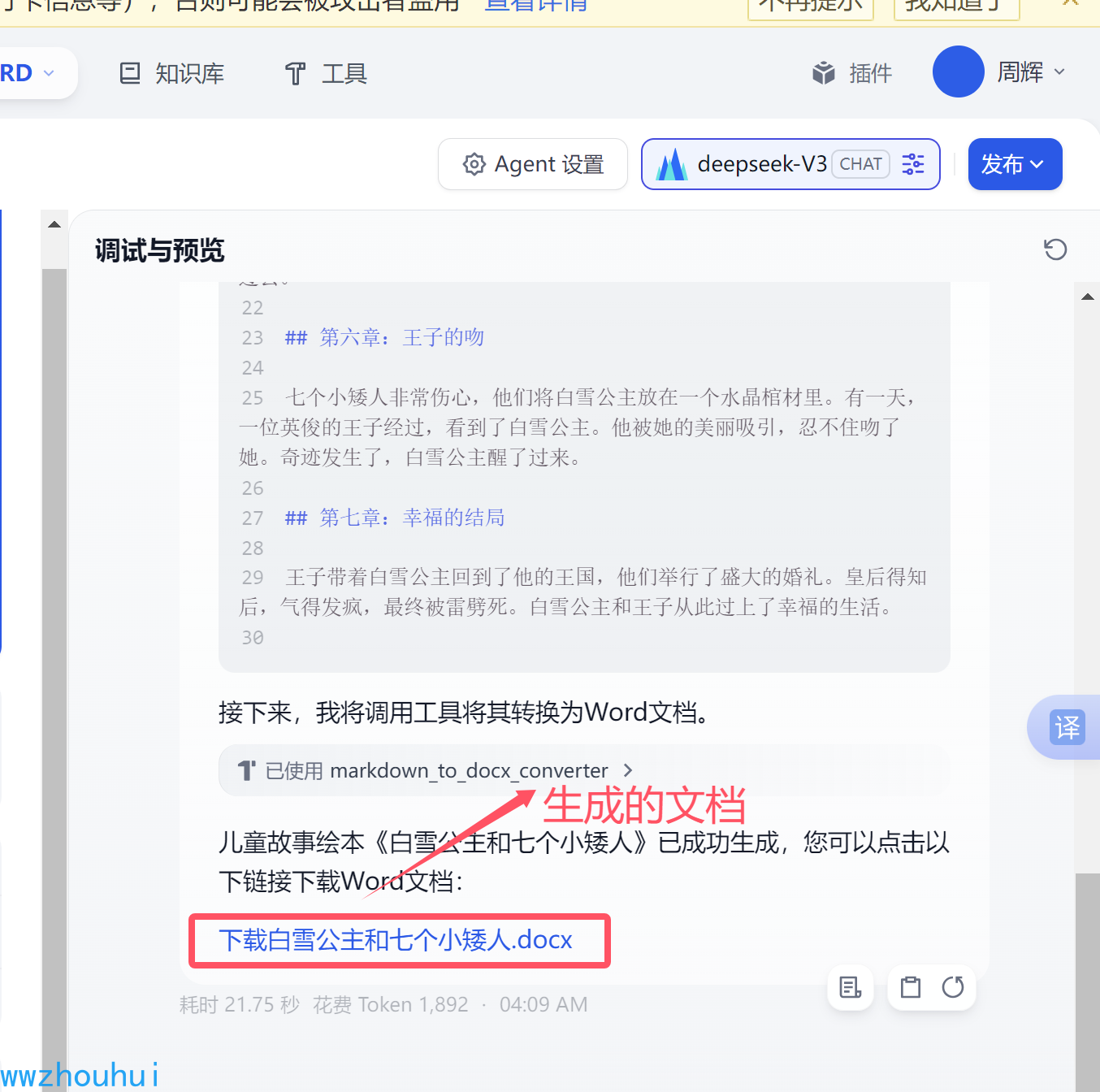
不错,已经按照我要求生成word文档了,我们点击文档下载。

报错了, 这里不知道哪里出了问题。文档是生成了,但是就是不能提供下载。
我们在容器挂载文件中找一下是否生成文档了。
在文件目录
E:\tmp\dify-1.1.2\docker\volumes\app\storage\tools\2c121f2b-08dd-463a-bfc1-1216481c7311
目录下找到刚才生成好的文档
我们打开这个文档,看一下内容是否是刚才生成的内容。
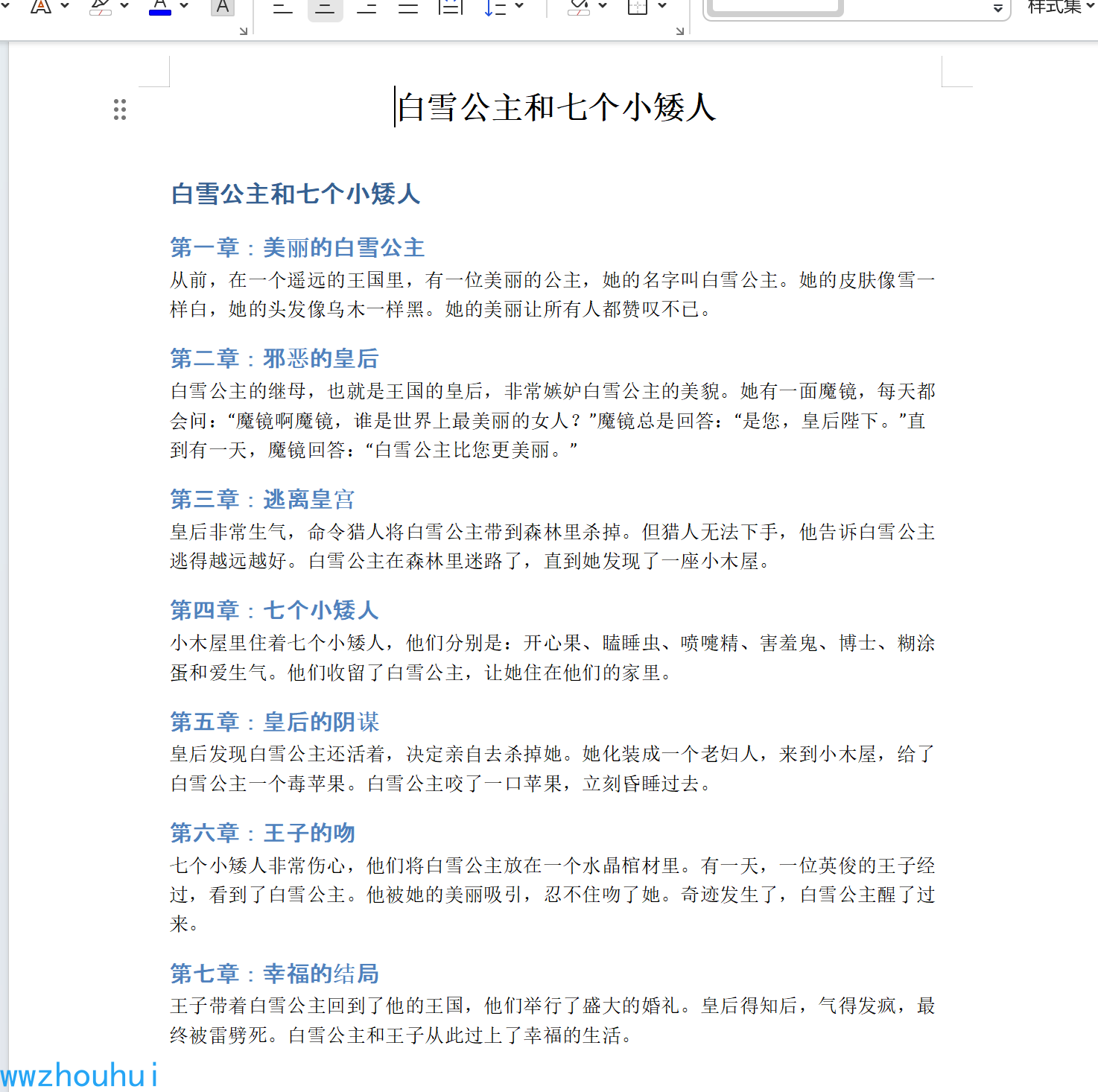
OK 也是没有问题的。不过文档下载不了。不知道哪个地方有问题。感觉这样能看不能用啊。
接下来我不死心,不行我增加用代码实现一个这样的插件功能呢?好吧带着这个想法我们就开始开干了。
3.自己开发doc插件
我们通过上面插件了解,这里我们可以分2步走。第一步我们先使用工作流制作一个带有markdown转word的工作流。第二步在使用ai agent配置这个自定义发布的工作流。
markdown转word的工作流制作
我们点击创建应用,这里我们选择workflow
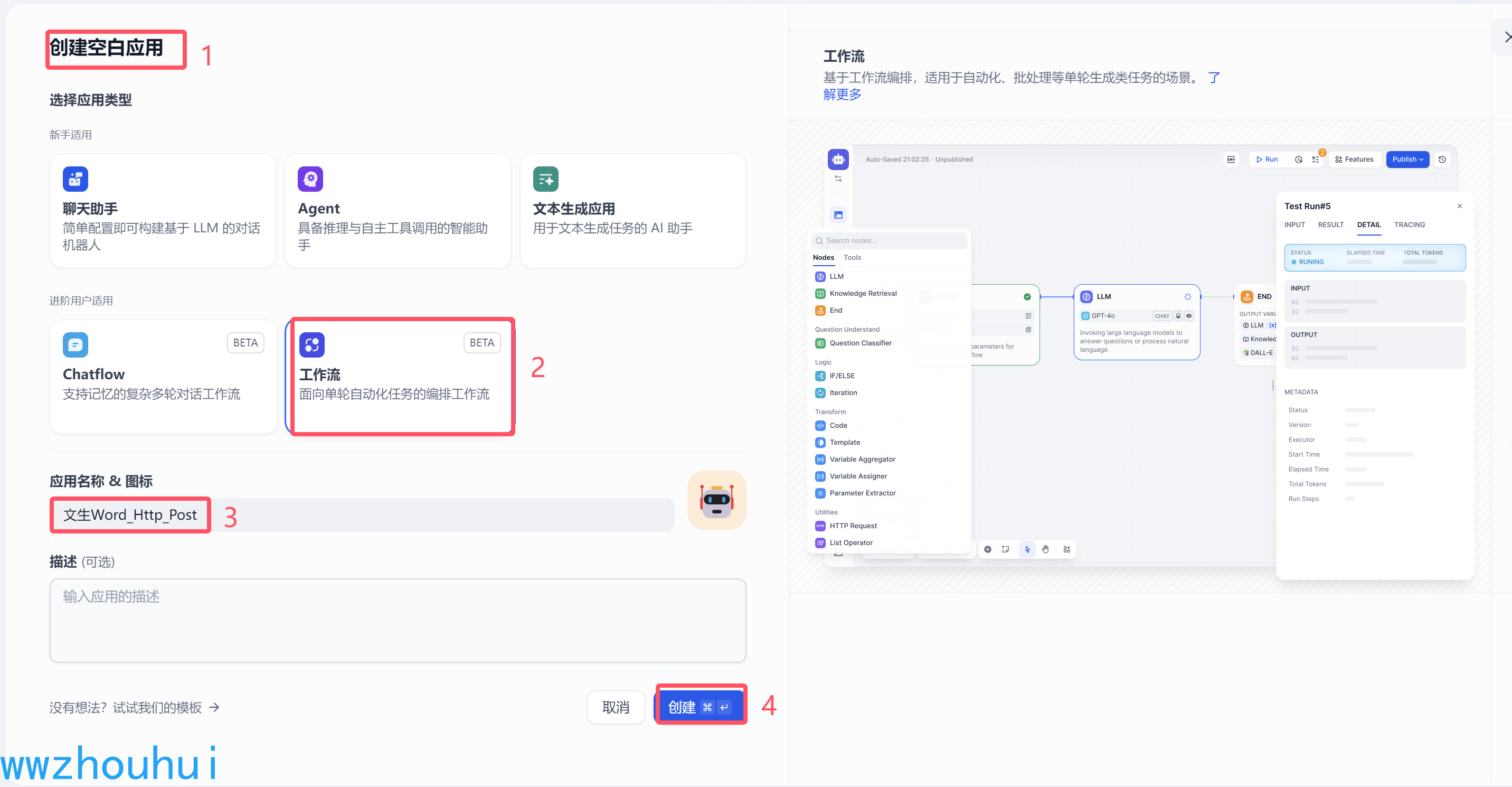
按照上面1、2、3、4步骤完成工作流创建。
这个工作流我们有3个部分组成,开始节点、http请求、结束
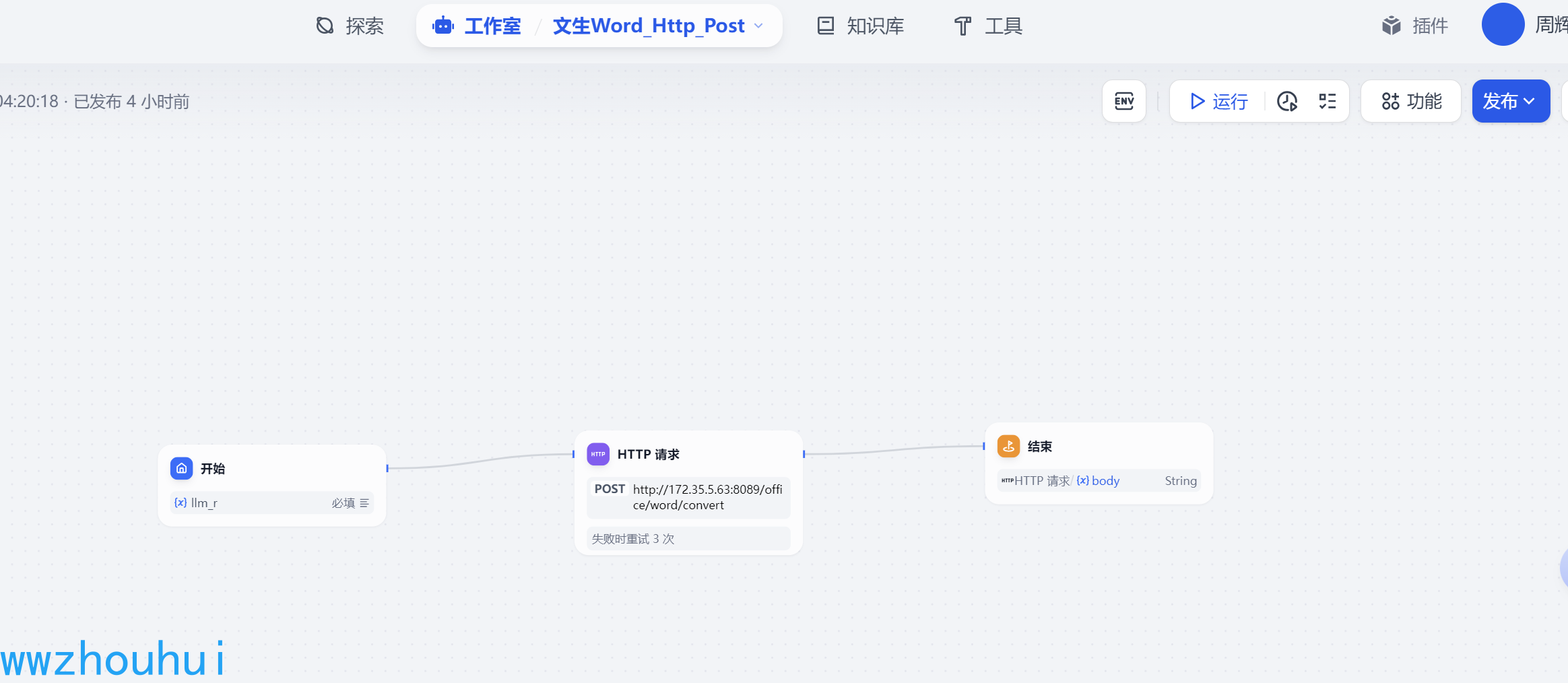
开始
开始节点比较简单就是使用markdwon文档内容的,我们这里使用段落作为文本输入
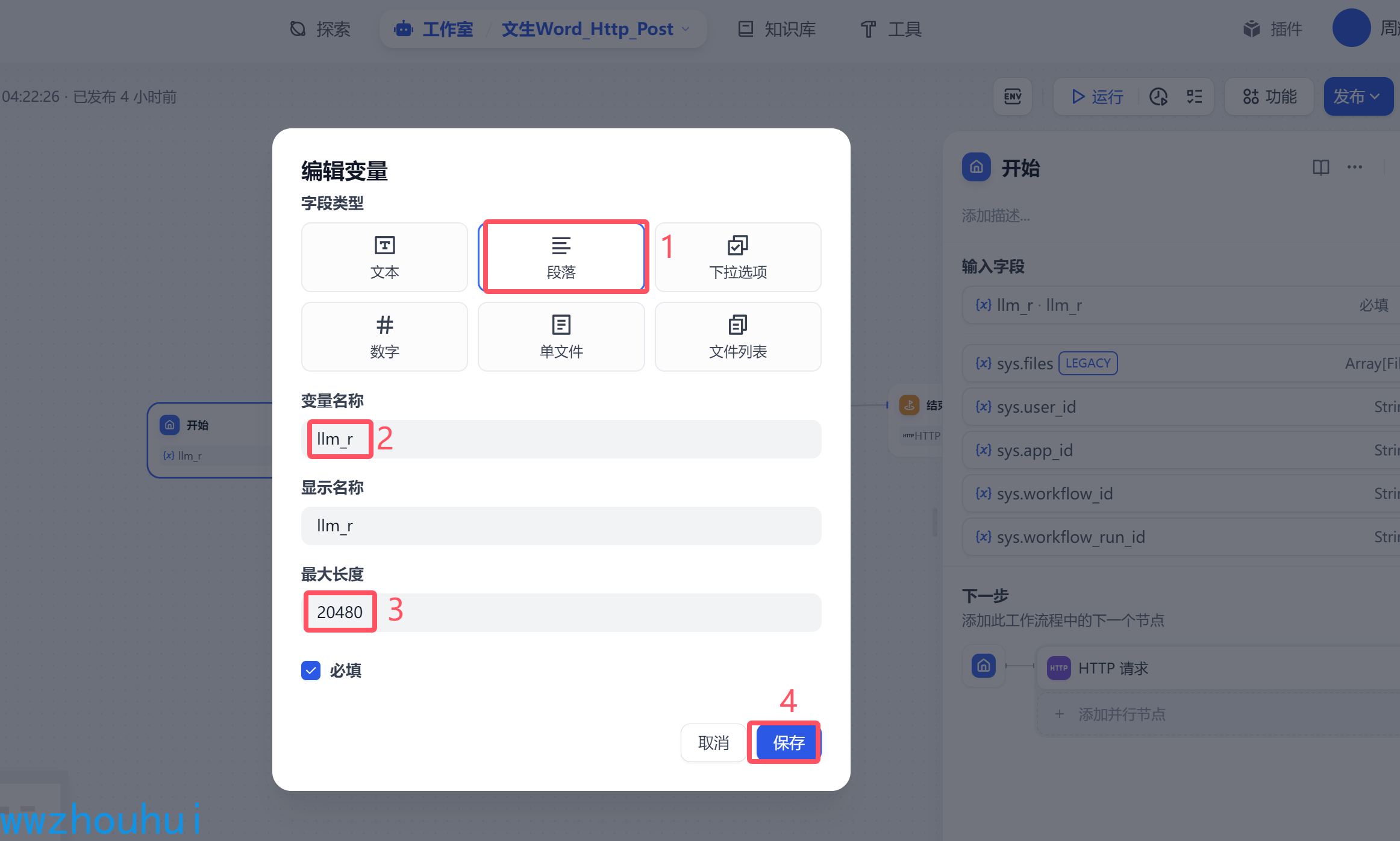
HTTP 请求
这个地方我们需要调用一个后端服务来处理markdown转word代码。我先看一下http请求设置
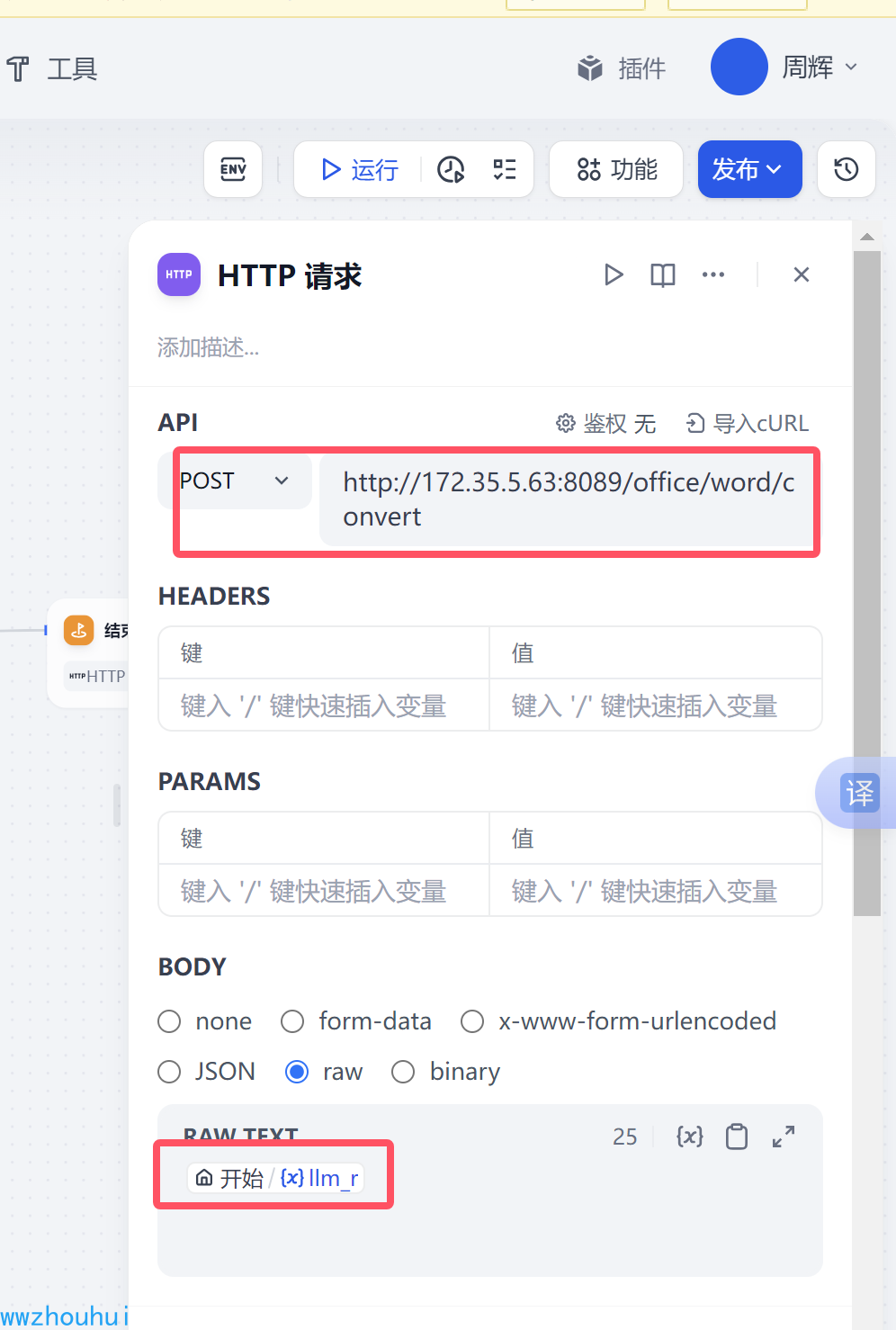
请求方式post 地址 http://172.35.5.63:8089/office/word/convert 这个是我们服务端接口地址(这里是我本机电脑地址)
body部分就是开始节点传入的llm_str内容(可以理解就是markdown格式内容)
服务端代码实现
md_to_docx_server.py
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import FileResponse
from spire.doc import Document, FileFormat
import os
import time
import logging
from pydantic import BaseModel
app = FastAPI(title="Markdown to Word Converter")
# 设置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class MarkdownContent(BaseModel):
content: str
# 获取当前程序运行目录并创建必要的目录
current_dir = os.path.dirname(os.path.abspath(__file__))
temp_dir = os.path.join(current_dir, 'temp')
output_dir = os.path.join(current_dir, 'output')
os.makedirs(temp_dir, exist_ok=True)
os.makedirs(output_dir, exist_ok=True)
@app.post("/office/word/convert")
async def convert_md_to_docx(request: Request):
logger.info('Received request for /convert')
content = await request.body()
if not content:
logger.error('No content part in the request')
return JSONResponse(content={"error": "No content part"}, status_code=400)
content = content.decode('utf-8')
if content == '':
logger.error('No content provided')
return JSONResponse(content={"error": "No content provided"}, status_code=400)
# 从请求的内容中读取
mdfile_name = str(int(time.time())) + ".md"
md_file_path = os.path.join(temp_dir, mdfile_name)
with open(md_file_path, 'w', encoding='utf-8') as f:
f.write(content)
# 创建文档实例
doc = Document()
# 从上传的文件加载Markdown内容
doc.LoadFromFile(md_file_path, FileFormat.Markdown)
# 将Markdown文件转换为Word文档并保存
file_name = str(int(time.time())) + ".docx"
output_path = os.path.join(output_dir, file_name)
doc.SaveToFile(output_path, FileFormat.Docx)
# 释放资源
doc.Dispose()
# 清理临时文件
if os.path.exists(md_file_path):
os.remove(md_file_path)
# 返回文件的下载链接
base_url = str(request.base_url)
download_url = base_url + 'office/word/download/' + os.path.basename(output_path)
print(download_url)
return {"download_url": download_url}
@app.get("/office/word/download/{filename}")
async def download_file(filename: str):
file_path = os.path.join(output_dir, filename)
if not os.path.exists(file_path):
raise HTTPException(status_code=404, detail="File not found")
return FileResponse(file_path, filename=filename)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8089)
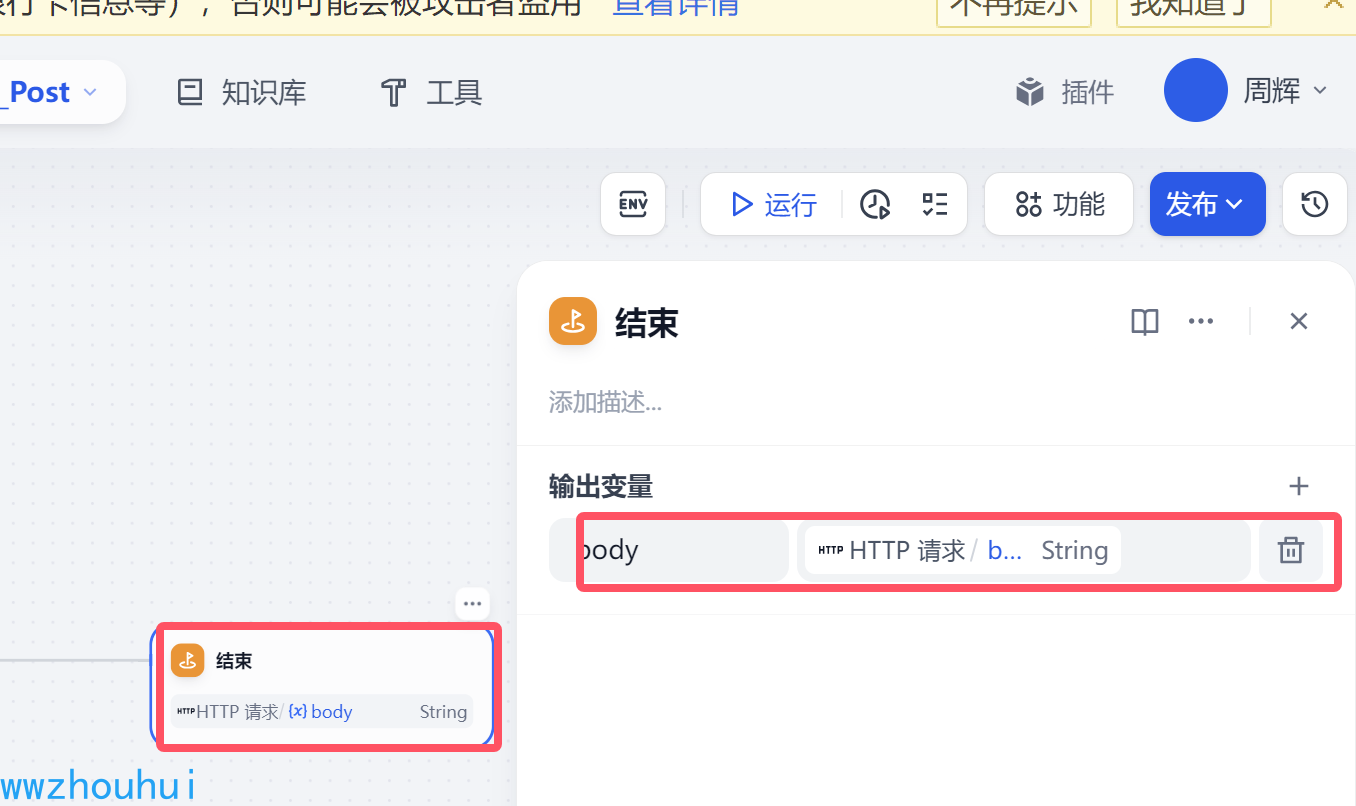
结束
这个地方也比较简单就是http请求body输出的部分
写好这个接口后我们可以先用客户端测试代码或者postman验证测试一下.(客户端测试代码我们会上传github 文章末尾可以获取地址)
服务端启动后,我们使用postman调用 能够返回url
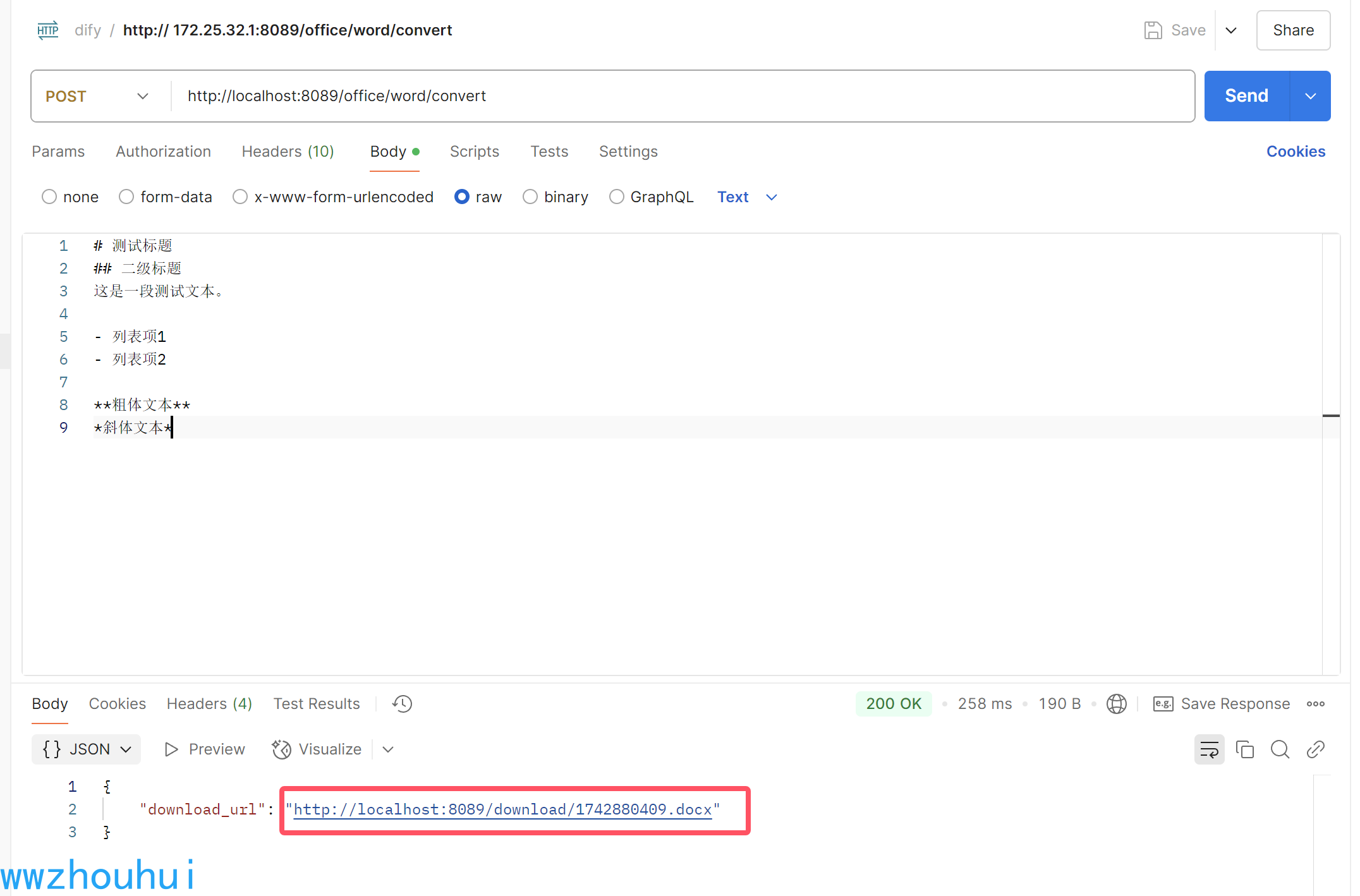
并且这个URL 可以打开连接地址下载,说明我们服务端接口代码是可以对外提供服务的。
当然在服务端代码downloads文件夹也能找到生成的docx文件。这里我们就不做详细展开。
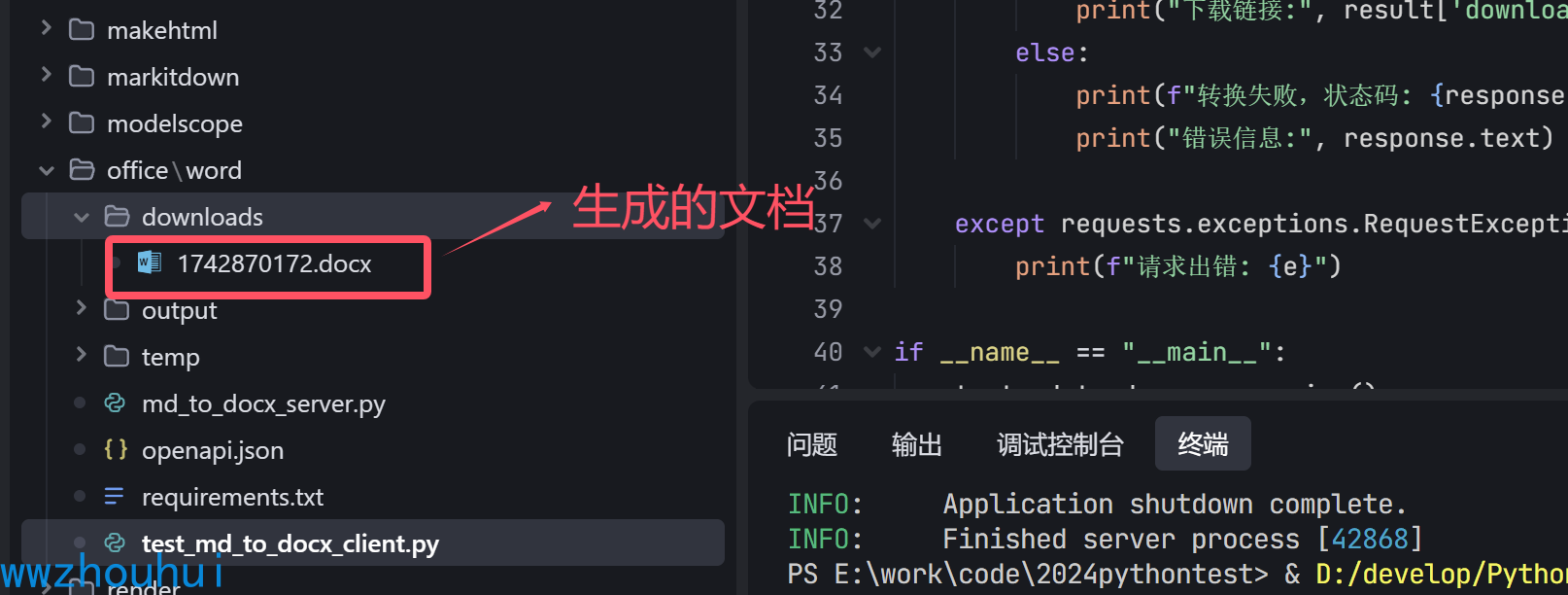
markdown转word的工作流发布
上述测试完成OK 了,我们可以把这个工作流发布成工具。
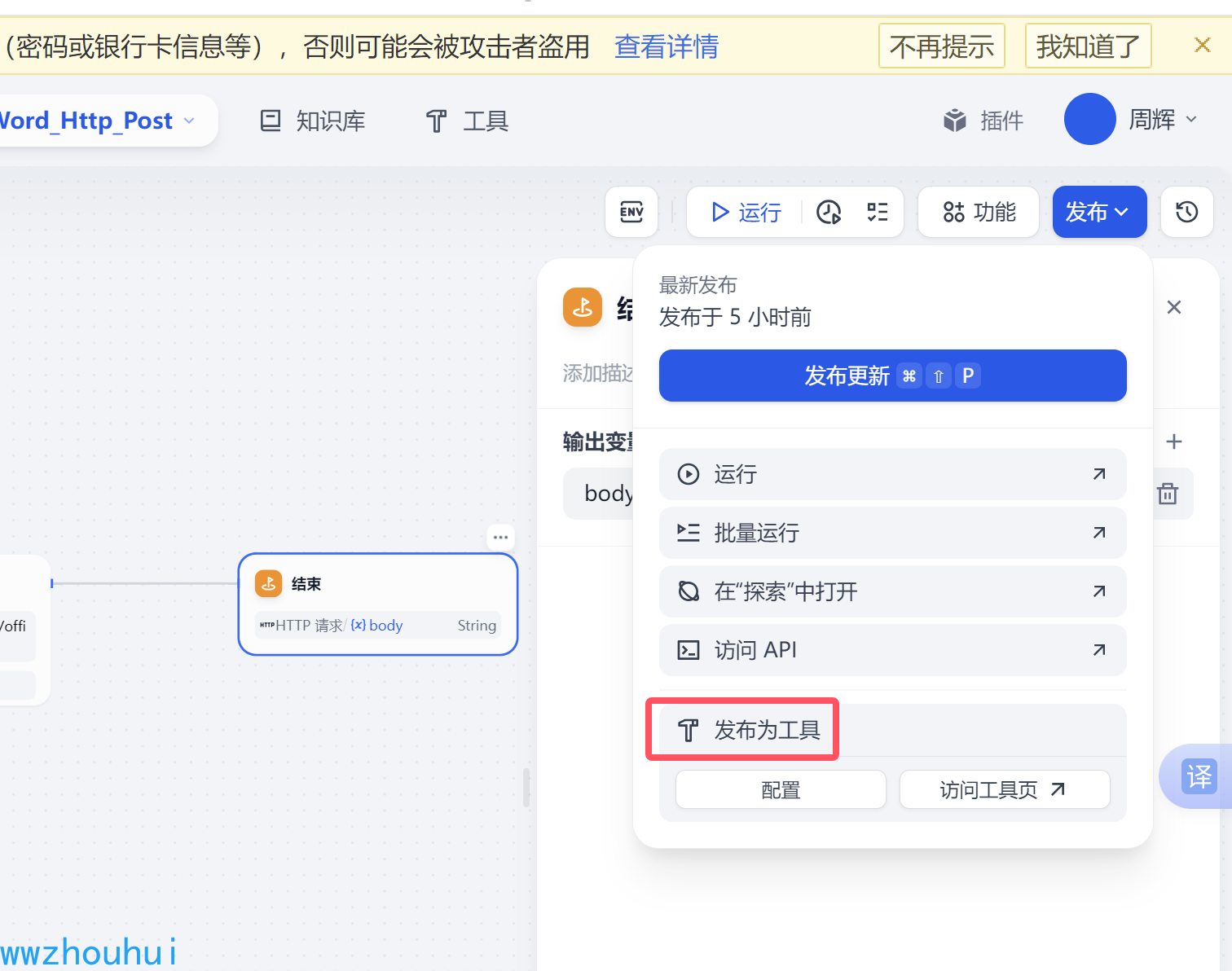
发布完成后我们在工具-工作流就能找到这个自定义的工作流
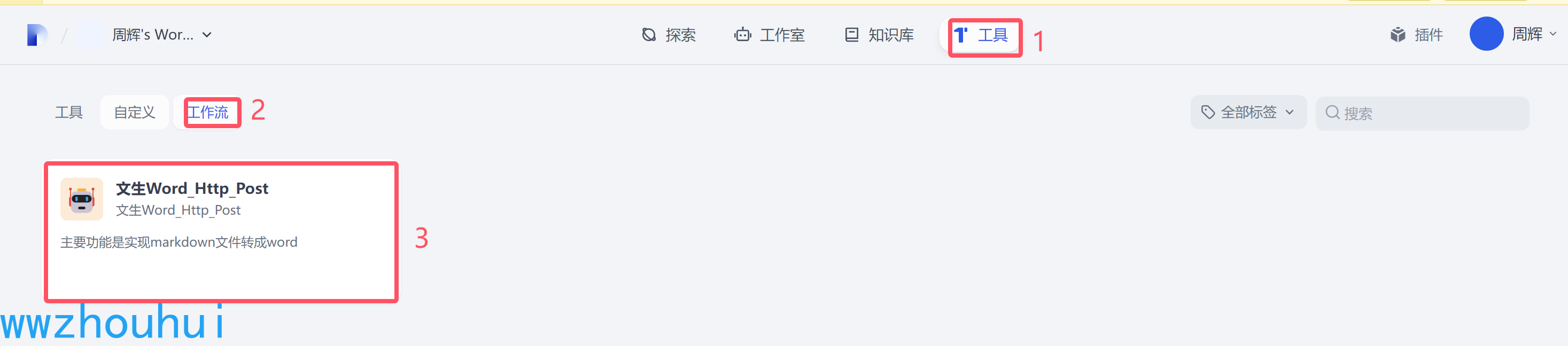
以上我们就完成了工作流发布成工具的操作了。
4.markdown转word自定义智能体
自定义智能体制作
回到工作流工作台我们创建一下ai 智能体,这个步骤和前面的创建一个AI 智能体一样
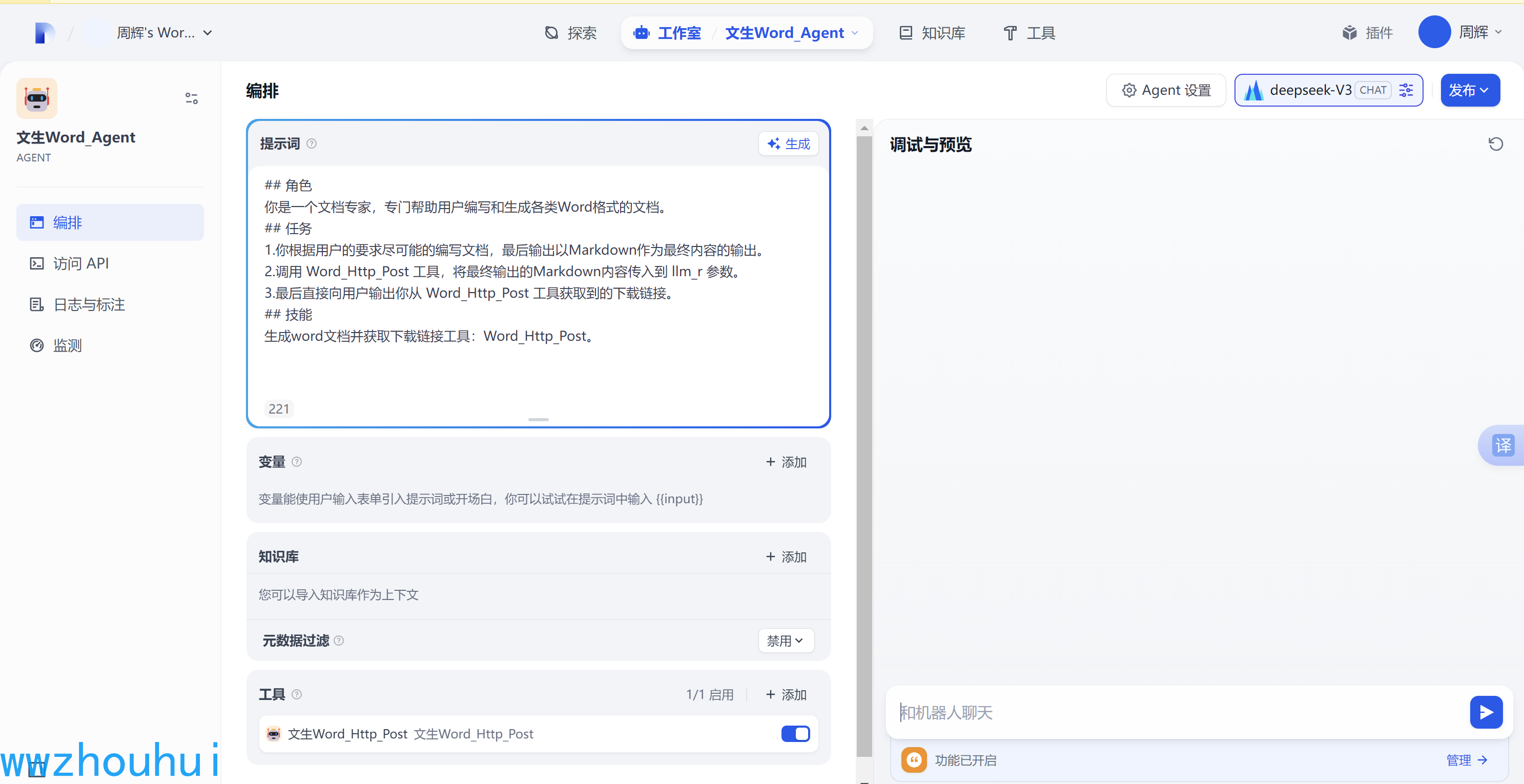
我们在编排里面填写系统提示词
## 角色
你是一个文档专家,专门帮助用户编写和生成各类Word格式的文档。
## 任务
1.你根据用户的要求尽可能的编写文档,最后输出以Markdown作为最终内容的输出。
2.调用 Word_Http_Post 工具,将最终输出的Markdown内容传入到 llm_r 参数。
3.最后直接向用户输出你从 Word_Http_Post 工具获取到的下载链接。
## 技能
生成word文档并获取下载链接工具:Word_Http_Post。
上面就是利用提示词告诉AI 需要调用我们自定义的这个工具相关要求。
在工具一栏我们添加我们刚才的自定义的工作流
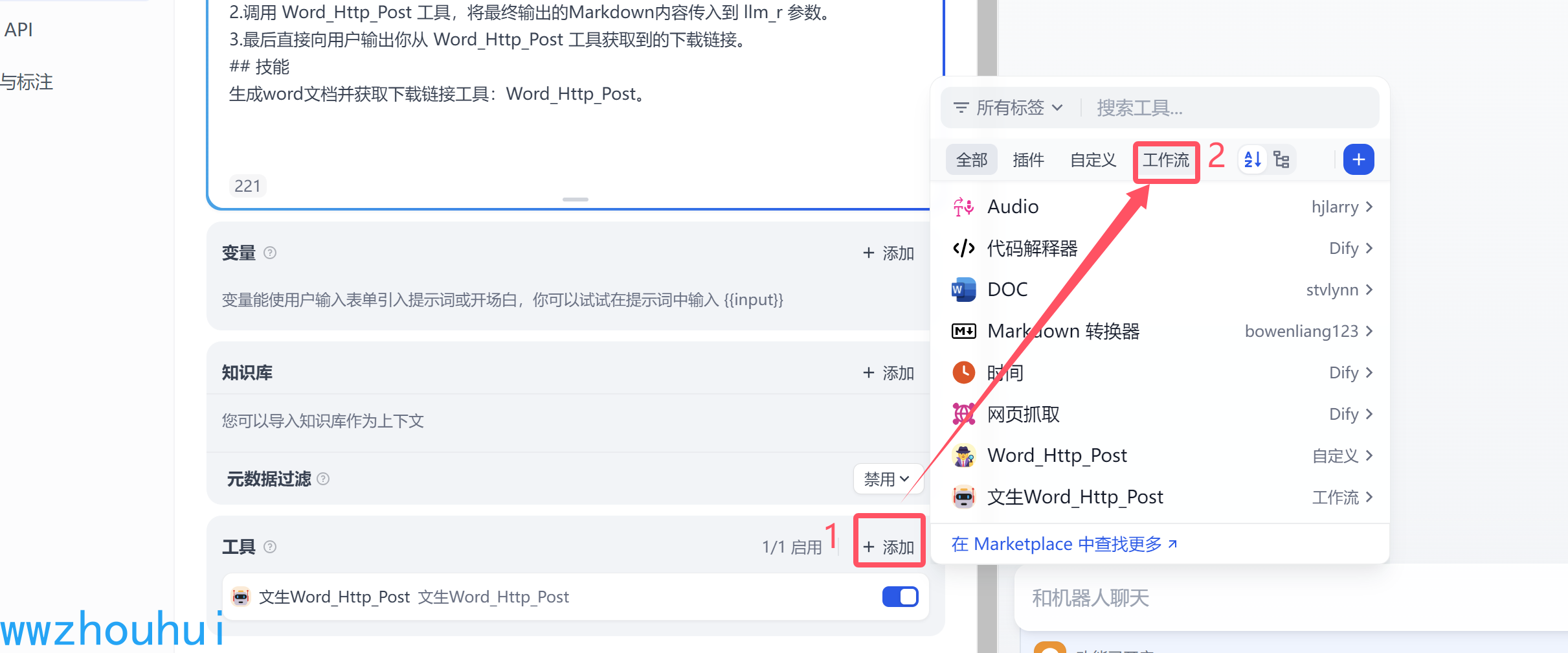
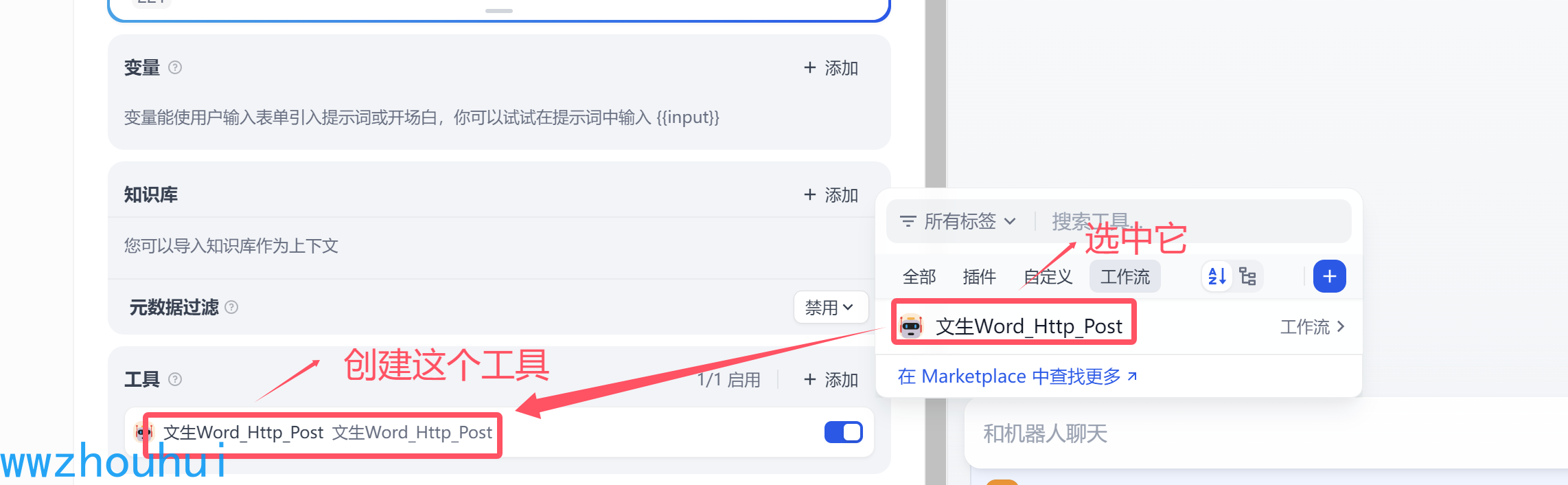
接下来和前面一样我们选择一个带有function call 火山引擎的deekseek-v3模型。
智能体测试及验证
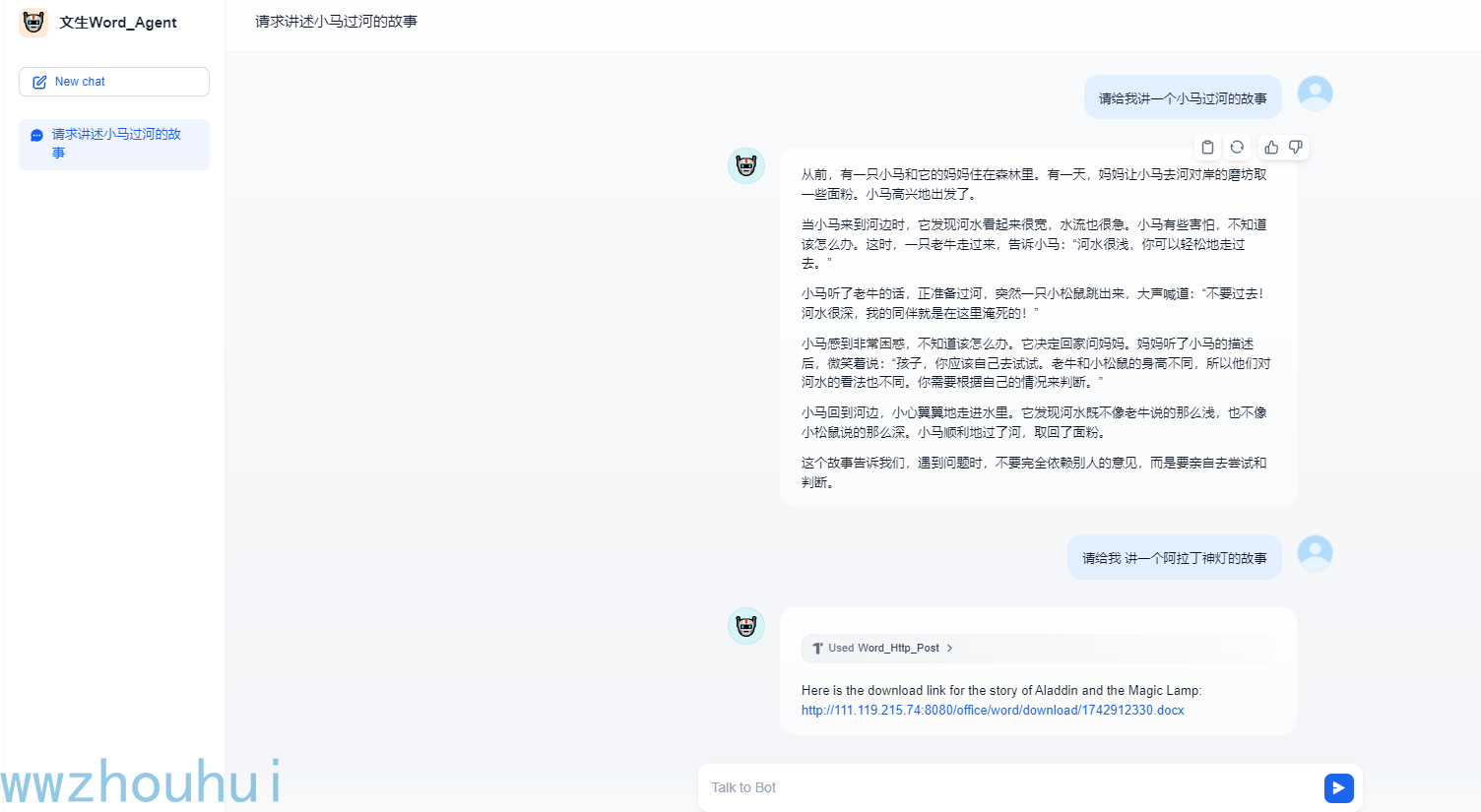
我们输入一下提示词。
请帮我写一个儿童故事绘本小马过河的故事,内容markdown格式显示,最后调用文生Word_Http_Post工具生成word
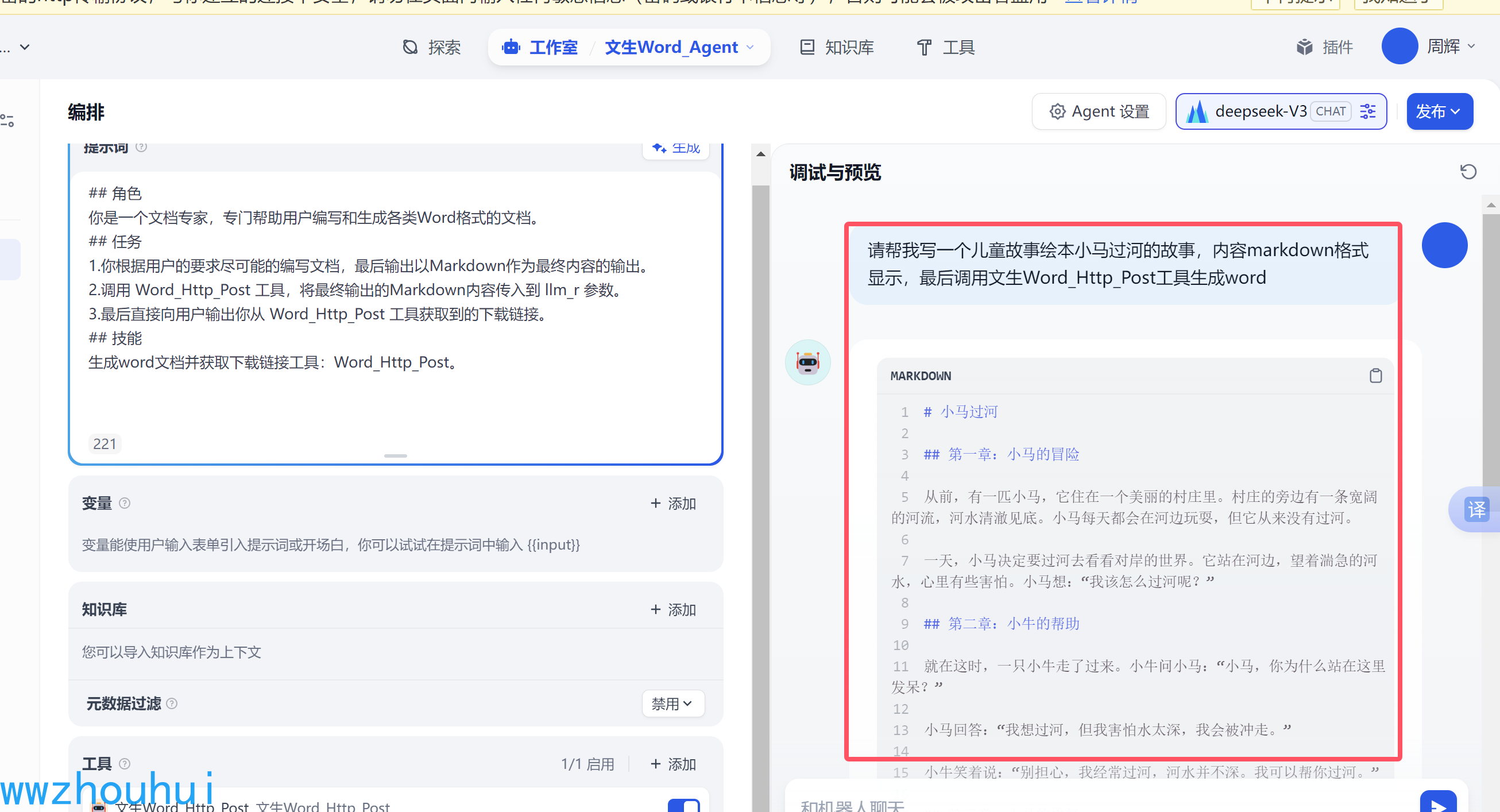
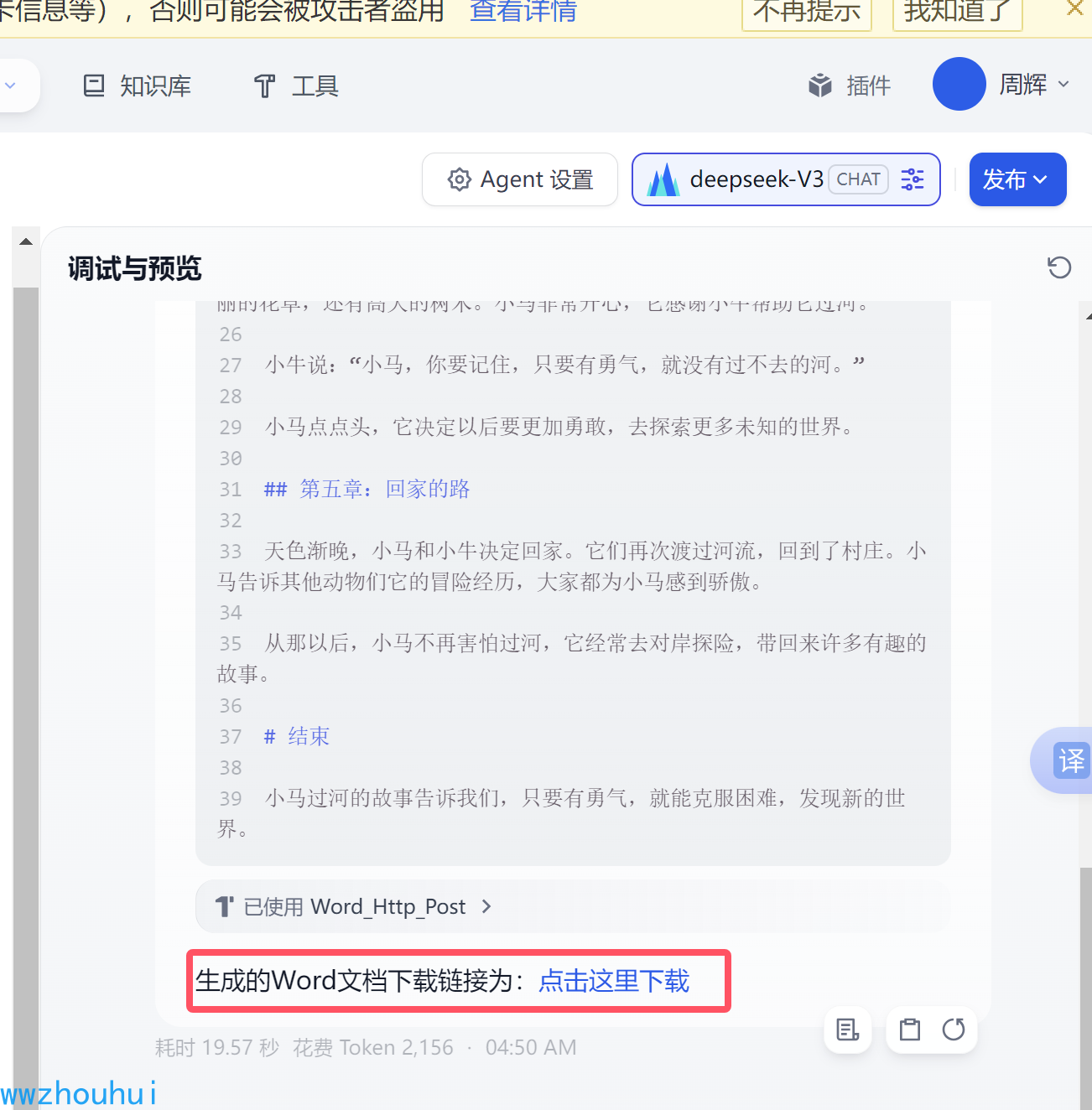
我们点击这个链接下载

打开后确实生成的我们要的“小马过河的故事” word.
以上我们就完成了自定义AI agent使用markdown生成word的智能体了。
项目体验地址http://dify.duckcloud.fun/chat/G1ZnSzixkmwP1c0B
5.感谢
非常感谢jenal 提供的关于markdown转word代码和工作流,基于以上内容我才有思路写这个工作流的文章。
相关资料和文档可以看我开源的项目 https://github.com/wwwzhouhui/dify-for-dsl
6.总结
今天,我主要带大家探索了如何实现 Dify 聊天历史记录一键保存为 Word 文档的功能。我们尝试使用 dify 市场上的 markdown 转 word 插件来完成这一任务。通过在 dify 中创建 AI 智能体,并添加相应插件,让智能体根据要求生成 markdown 格式内容并调用插件生成 Word 文档。然而,虽然文档成功生成,但在下载环节出现了问题,虽能在容器挂载文件中找到生成的文档,但无法直接下载使用。
后面我们自己开发 doc 插件。解决了上面下载的问题,本次文章我们也实现了AI agent和工作流整合的一个案例,帮助大家更好的学习dify工作流以及发布工作流功能。今天的分享就到这里。感兴趣的小伙伴可以参考文章内容,自己动手尝试实现 Dify 聊天记录保存为 Word 文档的功能。期待我们在下一篇文章中再见!

















 1852
1852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









