






系列文章目录
第二章希尔排序
前言
希尔排序是插入排序的一种,算是对于直接插入排序的一种优化排序算法,我们知道,假设我们需要将已知的序列排成顺序,如果序列中大的数字在前面的较多,小的数字在后面的较多,最极端的情况下,就是我们需要将一个逆序的序列排成顺序,这个时候,所消耗的时间最长,时间复杂度最大。
于是,我们可以通过希尔排序的方式,大大降低程序运行的时常。
一、希尔排序是什么?
希尔排序也叫做缩小增量排序,基本思想是将整个序列分为特定的组,在组间先使用插入排序进行预排序,我们知道假设我们需要将序列排列成顺序,数组越是接近于有序,计算机排序所消耗时间越短。
二、希尔排序过程
假设我们有这样一组数据
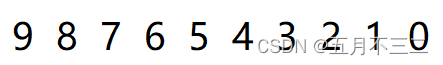
我们可以用希尔排序的方式,将数据分为三组,即第一个数隔三个数据算为一组,如下所示,红色,橙色,绿色分别为一组。组内之间数据下标相差为gap = 3(假定为3,也可以是其他值);
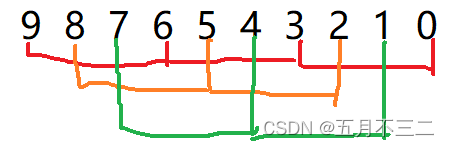
在每组数据中,我们使用插入排序的方式,先对这这几组数据进行预排序。我们以红色组为例,使用tmp将数据保存起来,然后将tmp与end及其之前的数据进行比较,大于tmp的数往后移,然后end=end-gap,知道遇到小于等于的数或者所有数据全部比较完成,end结束,将tmp放在end+gap的位置处,具体看插入排序 https://editor.csdn.net/md/?articleId=126452565。
插入排序
我们将红色组数据排序完成的结果如下,
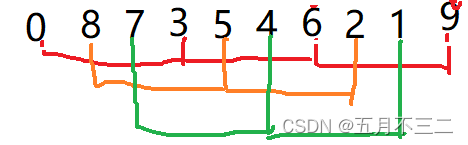
这里和插入排序所不同的一点就是移动距离由1改成了gap,其他和插入排序相同。
我们将这三组数据全部进行在组内插入排序可以得到预排序之后的数组。这种看起来要比直接进行插入排序要快的多。
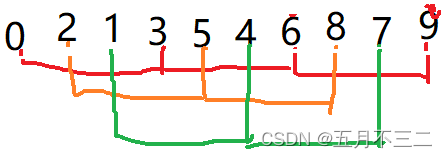
预排序完成之后,我们可以减小gap,再次进行组内的插入排序,最终将gap减少为1,也就是我们普通的插入排序了。但是这时我们所用的经过多次预处理过后的数组,已经很接近顺序的数组了,所以插入排序运算起来也是非常快的
二、希尔排序代码实现
代码实现时,用的是并行的方式,也就是说我们先排红色组第一个,然后是橙色组第一个,然后是绿色组第一个,如图
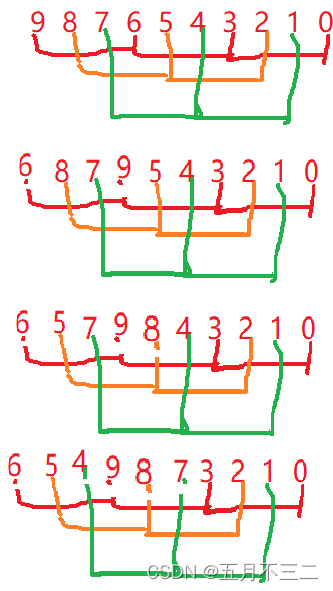
然后,再排红色组第二个,橙色组第二个…
依次类推
直到排到n - gap -1是最后一个结束。
然后减小gap,继续排序
//希尔排序,插入排序的优化
void ShellSort(int a[], int n )
{
int gap = n;
while (gap > 1)
{
gap = gap / 2;//gap先设置为长度一半,依次减半
//注意gap无论怎么设置,最终一次排序,一定是1
for (int i = 0; i < n - gap; i++)
//组内的插入排序,注意他们之间移动是gap
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
void TestShellSort(int a[], int sz)
{
ShellSort(a, sz);
PrintArr(a, sz);
}
int main()
{
int a[10] = { 1,2,2,6,6,7,5,5,6,0 };
//TestInsertSort(a, 10);
TestShellSort(a, 10);
return 0;
}
总结
希尔排序看似较为复杂,但是运行起来要比直接插入排序快很多,首先就是我们假设每次排序后gap按照减半来进行操作,直到gap为1(直接插入排序)。如果假设最大的数据,比如上面提到的9,在第一个位置,那么如果我们使用插入排序,需要走很多步9才能到最后的位置,而希尔排序按照gap=n/2的时候,只要一步就可以走到数组中间,两不就能走到末尾,所以这种方法相较于直接插入排序还是特别快的。















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









