







 本文基于《Python数据分析与挖掘实战》实战,聚焦用水事件属性构造和模型构建。通过去除短时用水事件及水量条件,筛选出候选洗浴事件,并展示模型效果。
本文基于《Python数据分析与挖掘实战》实战,聚焦用水事件属性构造和模型构建。通过去除短时用水事件及水量条件,筛选出候选洗浴事件,并展示模型效果。
本文是基于《Python数据分析与挖掘实战》的实战部分的第10章的数据——《家用电器用户行为分析与事件识别》 做的分析。
接着前一篇文章的内容,本篇博文重点是处理用水事件中的属性构造部分,然后进行构建模型分析。
1 属性构造
由文中可知:需要构造的属性如下:
热水事件起始数据编号、终止数据编号、开始时间(begin_time)、根据日志判断是否为洗浴(1表示是,0表示否)、洗浴时间点、总用水时长(w_time)、总停顿时长(w_pause_time)、平均停顿时长(avg_pause_time)、停顿次数(pause)、用水时长(use_water_time)、用水/总时长(use_water_rate)、总用水量(w_water)、平均水流量(water_rate)、水流量波动(flow_volatility)、停顿时长波动(pause_volatility)
此部分博主花了较长时间,其中很大原因是因为对文中作者描述的属性的相关定义进行的探索确定,以及编程实现。
**由于一次用水中可能存在停顿,因此,在实现属性构造之前,需要进行以下数据连接工作。 **
inputfile = 'dataExchange_divideEvent.xlsx'
data = pd.read_excel(inputfile)
# len(data)# 7696
inputfile1 = 'data_guiyue.xlsx'
data1 = pd.read_excel(inputfile1)
x = pd.merge(data1,data[[u'事件编号']],left_index = True, right_index=True,how='outer')
# 连接'data_guiyue.xlsx'和 'dataexchange_divideEvent.xlsx'的后两列,因为,属性规约里面包含水流量为0的数值,后一个表中,只含有水流量不为0的值,需要将两边进行连接,获知规约后的数据中的数据所属的事件数,利用处理后的数开始进行数据构造工作
x.head()#18840
x.to_excel('data_for_attr_const.xlsx')
[/code]
## 1.1 准备工作:
```code
df = pd.read_excel('data_for_attr_const.xlsx')
# 将数据划分成一次用水事件!(*****)
#-----第*1*步-----做基本处理,获取用于构造属性的数据表
# 将数据划分成一次用水事件!(*****)
# 思路:获取每个事件的序号值所在的最小的index值和最大的index值,然后将其连接,
# 即: 去掉不同事件间的“事件编号”为空的值,保留同一个事件内的“事件编号”为空的值
l=list(df[u'事件编号'])
Adf = DataFrame([], columns = df.columns)# 创建一个空列表
pos=-1
MX = int(df[u'事件编号'].max())
for j in range(MX):
y = []
for i in range(l.count(j+1)):
pos=l.index(j+1,pos+1)
y.append(pos)
a = min(y)
b = max(y)
temp = df.iloc[a:b+1,:]
Adf = pd.concat([Adf,temp])
Adf[u'事件编号'].fillna(method='ffill',inplace = True) # 向后填充,填上了事件编号的空值
Adf[[u'水流量']] = Adf[[u'水流量']].astype('float64')
Adf.to_excel('1TimeWaterDivide.xlsx')
Adf.head()
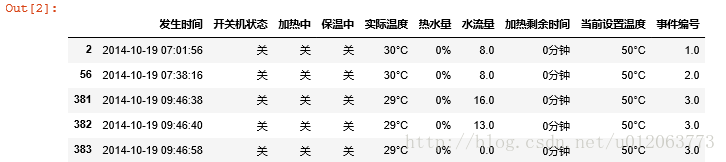
#-----第*2*步-----建立存放构造的属性的表
df2 = pd.read_excel('1TimeWaterDivide.xlsx')
df2['gap'] = df2[u'发生时间'].diff()
MX = int(df2[u'事件编号'].max())# 获取当前事件数172
fdf2 = DataFrame([], index = range(1,MX+1))# 创建一个空列表 用来存放属性规约结果
[/code]
## 1.2 开始构造属性
### 1.2.1 构造属性第一部分
包含用水事件开始编号、用水事件结束编号、用水开始时间、用水结束时间、用水总时间、用水间隔时间、一次用水期间“水流量”为0的记录数
```code
fdf2.index.names = ['eventNUM']
fdf2['stDataIndex'] = np.nan #用水事件开始编号
fdf2['edDataIndex'] = np.nan #用水事件结束编号
fdf2['stUseTime'] = np.nan #用水开始时间
fdf2['enUseTime'] = np.nan #用水结束时间
fdf2['AllUseTime'] = np.nan #用水总时间
fdf2['gapTimes'] = np.nan #用水间隔时间
fdf2['stopLines'] = np.nan # 一次用水期间“水流量”为0的记录数
ds = pd.Timedelta(seconds = 2) # 发送阈值时间设置为2秒
pos=-1# 标记变量 ******
l=list(df2[u'事件编号'])
# 以下空列表均是暂时存储数据
stUI = []
enUI = []
startU = []
endU = []
allUT = []
gapTS = []
stopLines = []
for j in range(MX):
# 计算事件编号j在列表中的最开始出现的index和最后出现的index
y = []# 存储时间编号j出现的所有的index(临时存储)
for i in range(l.count(j+1)):
pos=l.index(j+1,pos+1)
y.append(pos)
a = min(y)#出现值i最小的index
b = max(y)#出现值i最大的index
#记录一次用水的开始事件编号、结束事件编号
stui= df2.index[a]
enui= df2.index[b]
stUI.append(stui)
enUI.append(enui)
#记录一次用水开始时间、结束时间
stu = df2.iloc[a,0]-ds/2 # 设置用水开始时间=起始数据时间-发送阈值/2
enu = df2.iloc[b,0]+ds/2 # 设置结束用水时间=结束数据时间+发送阈值/2
startU.append(stu)
endU.append(enu)
#记录一次用水总时长
allut = enu-stu
allUT.append(allut)
#判断停顿的行数(一次事件中水流量为0的记录的条数)
stpts = df2.iloc[a:b+1,:]
f =list(stpts[u'水流量'])
stpt = f.count(0)#计算空值的个数
stopLines.append(stpt)
n =0
#判断停顿次数,中间有一个或多个空值均算作一次停顿
if a==b :
n=0
else:
tgap = df2.iloc[a:b+1,:]
for t in range(a,b):
g = tgap.ix[df2.index[t],[u'水流量']].values
g1 = tgap.ix[df2.index[t+1],[u'水流量']].values
if g1 == 0 and g!= 0:
n+=1
gapTS.append(n)
fdf2['stUseTime'] = startU
fdf2['enUseTime'] = endU
fdf2['stDataIndex'] = stUI
fdf2['edDataIndex'] = enUI
fdf2['AllUseTime'] = allUT
fdf2['gapTimes'] =gapTS
# 将一次用水事件的总时间转成以秒计
fdf2['AllUs 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









