







决策树是一种树型结构,其中每个内部结点表示在一个属性上的测试,每个分支代表一个测试输出,每个叶结点代表一种类别。决策树学习是以实例为基础的归纳学习,采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子结点处的熵值为零,此时每个叶节点中的实例都属于同一类。决策树学习算法的最大优点是,它可以自学习。在学习的过程中,不需要使用者了解过多背景知识,只需要对训练实例进行较好的标注,就能够进行学习。
我们看一个有趣的例子,下面是一位女士准备去相亲时根据男方的条件选择见或不见的决策树示意图:
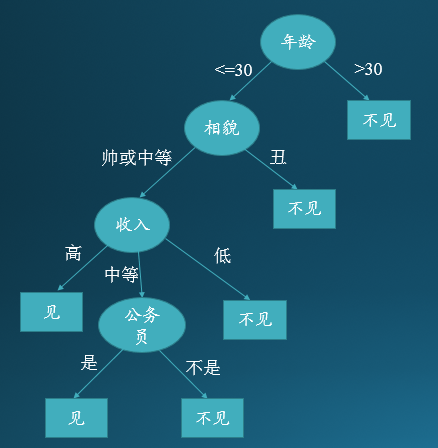
从上图可以看出该女士首先选择年龄这个属性作为分类依据,年龄大于30岁的直接不见,不超过30岁的再看相貌这个属性,如果丑就不见,如果帅或中等的话再看收入…… 直到最终可以判定所有实例的类别。
建立决策树的关键就是在当前状态下选择哪个属性作为分类依据,因此要选择适当的目标函数。目标函数可以选择信息增益、信息增益率和基尼系数,分别对应ID3、C4.5和CART这三种决策树学习算法。下面分别介绍:
1. ID3:
ID3算法是以信息增益作为其特征选择的目标函数的。当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵和条件熵分别称为经验熵和经验条件熵。特征A对训练数据D的信息增益g(D,A)定义为:数据集D的经验熵H(D)与特征A给定条件下数据集D的经验条件熵H(D|A)之差,即g(D,A) = H(D) - H(D|A)。信息增益表示得知特征A的信息而使得数据集D的分类的不确定性减少的程度。
下面详述信息增益的计算方法:
设训练数据集为D,|D|表示其样本个数。设有K个类
Ck
,
k=1,2,3,...,K
,
|Ck|
为属于类
Ck
的样本个数,显然有
∑Kk=1|Ck|=|D|
。设特征A有
n
个不同的取值{
(1)计算数据集D的经验熵:
(2)计算特征A对数据集D的经验条件熵:
(3)计算信息增益:
根据信息增益的特征选择方法是对训练数据集(或子集)D,计算每个特征的信息增益,选择信息增益最大的特征做为当前状态下的分类依据。
ID3算法的过程如下:
输入:训练数据集
D
,特征集
输出:决策树
T
① 若
② 若
③ 否则,计算各特征
④ 如果
Am
的信息增益小于阈值
ϵ
,则置
T
为单节点树,并将
⑤ 否则,对
⑥ 对第
i
个子结点,以
2. C4.5:
在使用信息增益 g(D,A) 进行特征选择时,取值多的属性更容易使数据更纯,其信息增益更大,训练得到的是一棵庞大且深度浅的数,这样是不合理的。因此用信息增益率对这一问题进行校正。C4.5算法正是以信息增益率作为其特征选择的目标函数的。
信息增益比为:
其中, g(D,A) 为信息增益, HA(D) 为训练数据集D关于特征A的值的熵,
C4.5算法和ID3算法类似,只是把特征选择目标函数换成信息增益率,其算法过程参照ID3。
3. CART:
CART算法是以基尼系数作为其特征选择的目标函数的。
在分类问题中,假设由K个类,样本点属于第















 2270
2270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









