







- 本文介绍如何在 gym 套件中使用自己创建的环境,改编自官方文档 Make your own custom environment
- 关于 gym 套件的基础介绍参考:RL gym 环境(1)—— 安装和基础使用
文章目录
1. 悬崖漫步环境
1.1 环境定义
-
本文通过构造经典的悬崖漫步(Cliff Walking)环境,来说明 gym 环境的自定义和使用方法
-
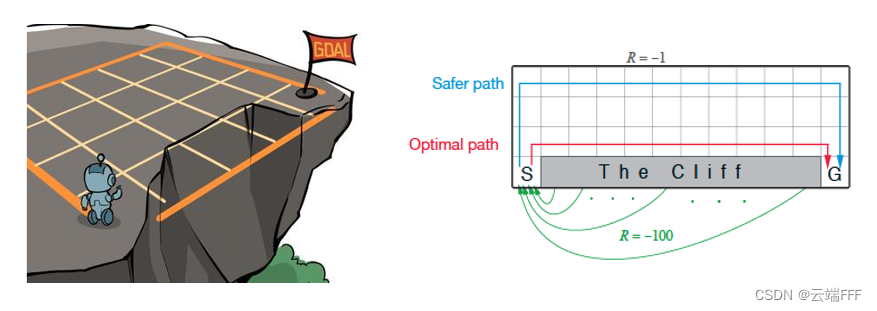
首先简单介绍悬崖漫步环境,本段引用自 《动手学强化学习》第4章
这是一个 4 x 12 的网格世界,每一个网格表示一个状态。智能体的起点是左下角的状态,目标是右下角的状态,智能体在每一个状态都可以采取 4 种动作:上、下、左、右。如果智能体采取动作后触碰到边界墙壁则状态不发生改变,否则就会相应到达下一个状态。环境中有一段悬崖,智能体掉入悬崖或到达目标状态都会结束动作并回到起点,也就是说掉入悬崖或者达到目标状态是终止状态。智能体每走一步的奖励是 −1,掉入悬崖的奖励是 −100
-
下面给出在我利用 gym 实现的 Cliff Walking 环境中运行 Q-Learning 的效果(8倍快放)

- 蓝色圆圈代表 agent,因为我这里仅在轨迹开始时刷新渲染,所以 agent 看起来一直在起点没动
- 左下角黑色方格,右下角绿色方格,二者间的黑色方格分别代表起点、目标点和悬崖
- 通过颜色实时渲染相对 V ( s ) V(s) V(s) 价值(根据 reward 设置, V ( s ) V(s) V(s) 一定都是负数,渲染逻辑是以 V ( s ) V(s) V(s) 的最大绝对值为基准, 价值越接近基准就越红)
- 通过渐变颜色直线实时渲染策略,指向是从绿色端指向黑色端
- 我这里对动作空间增加了 noop 操作,即原地不动,从渲染的策略也可以看出,如果有些方格没有出射直线,就是说当前该位置 policy 为 noop
- 如图可见,Q-Learning 最终收敛到 Optimal path
1.2 实现效果
- 本文仅说明如何构造这个可视化环境,不涉及 RL 算法,目标是实现如下效果


- 上侧 gif 是
render_mode='rgb_array'情况下,通过键盘手动控制 agent 运动的情况(手动交互渲染模式必须设为 rgb_array),可见agent 移动到悬崖或目标点会自动复位到起点。注意到这里没有渲染价值颜色和策略,这是因为渲染模式设置为rgb_array时,每次调用渲染方法render()会将游戏画面会转像素 ndarray 形式返回,常用于借助 CNN 进行状态观测的情况,为避免影响观测不应渲染额外内容 - 下侧 gif 是
render_mode='human'情况下,随机采样 action 运行的情况,这时状态价值 V V V 和 policy 都是随机设置的,所以图像在闪烁
- 上侧 gif 是
2. 环境实现
2.1 文件组织
- 新建 python 工程,如下组织项目文件

2.2 编写环境类
- 这节说明 2.1 节中 GridWorld.py 文件的写法,这是自定义环境的重点
- 为了符合 gym 规范,自定义环境的工作大体包括
- 继承抽象类
gym.Env - 添加
metadata属性,指定环境支持的渲染模式和渲染帧率 - 定义环境观测空间属性
observation_space和动作空间属性action_space,必须是gym.spaces某个子类的实例 - 实现
reset(),step(),render(),close()四个类方法作为环境对外交互的窗口,其他类方法应设置为_开头的内部方法
- 继承抽象类
2.2.1 定义和初始化
-
遵循以下要点
- 继承抽象类
gym.Env - 按规范添加
metadata属性,从中指定环境支持的渲染模式(如"human", "rgb_array", "ansi"等)和渲染帧率。所有环境都支持渲染模式None,应该将其设置为__init__方法的缺省形参 - 在类初始化方法
__init__中定义环境的观测空间observation_space和动作空间action_space,它们必须是gym.spaces某个子类的实例。我这里将观测定义为 agent 当前位置和目标位置的二维坐标,因此观测空间可以设为元素为gym.spaces.MultiDiscrete的gym.spaces.Dict类实例 - 完成环境所需的其他初始化工作
- 继承抽象类
-
代码如下
class CliffWalkingEnv(gym.Env): def __init__(self, render_mode=None, map_size=(4,12), pix_square_size=20): self.pix_square_size = pix_square_size self.nrow = map_size[0] self.ncol = map_size[1] self.start_location = np.array([0, self.nrow-1], dtype=int) self.target_location = np.array([self.ncol-1, self.nrow-1], dtype=int) # 观测空间 self.observation_space = spaces.Dict( { "agent": spaces.MultiDiscrete([self.ncol, self.nrow]), "target": spaces.MultiDiscrete([self.ncol, self.nrow]), } ) # 动作空间:上下左右+noop self.action_space = spaces.Discrete(5) # 每个动作对应 agent 位置的变化 self._action_to_direction = { 0: np.array([0, 0]), # noop 1: np.array([1, 0]), # right 2: np.array([0, 1]), # down 3: np.array([-1, 0]), # left 4: np.array([0, -1]), # up } # 渲染模式支持 'human' 或 'rgb_array' assert render_mode is None or render_mode in self.metadata["render_modes"] self.render_mode = render_mode # 渲染模式为 render_mode == 'human' 时用于渲染窗口的组件 self.window = None self.clock = None
2.2.2 从状态构造观测
- 因为在
env.reset()和env.step()方法中都要返回observation,可以设置一个内部方法进行 state 到 observation 的转换。另外,这里将二者返回的附加信息info定义为 agent 当前状态距离目标位置的曼哈顿距离def _get_obs(self): return {"agent": self._agent_location, "target": self._target_location} def _get_info(self): return {"distance": np.linalg.norm(self._agent_location - self._target_location, ord=1)} # 附加信息定义为 agent 当前位置到 target 的曼哈顿距离
2.2.3 reset 方法
reset方法用于启动一个新轨迹的交互过程,可以假定在调用reset()之前不会调用step()方法,同时,当step()方法发出terminated或truncated信号时应该调用reset()- 环境基类
gym.Env内置一个随机数生成器,一般通过形参seed,在reset()方法中,通过super().reset(seed=seed)实现该随机数生成器的初始化。seed形参应该有缺省值None,按使用规范,创建环境实例后应立即带seed值调用reset()方法,之后reset()时不要再带seed。另外,如果第一次调用reset()时没有指定seed,会利用某个熵源(如时间戳)随机设置随机数生成器 reset()方法应该返回初始 observation 和一些辅助 info,可以使用之前实现的_get_obs和_get_info方法def reset(self, seed=None, options=None): '''step 方法给出 terminated 或 truncated 信号后,调用 reset 启动新轨迹''' # 通过 super 初始化并使用基类的 self.np_random 随机数生成器 super().reset(seed=seed) # agent 置于起点,设置终点位置 self._agent_location = self.start_location.copy() self._target_location = self.target_location.copy() # 获取当前状态观测和附加信息 observation = self._get_obs() info = self._get_info() # 可以在此刷新渲染,但本例需要渲染最新策略,所以在测试时更新策略后再手动调用 render 方法 #if self.render_mode == "human": # self._render_frame() return observation, info
2.2.4 step 方法
step()方法通常包含环境的大部分逻辑。它接受一个 action,计算应用该 action 后的环境 state,并返回元组 (observation, reward, terminated, truncated, info)- 对于 observation 和 info 直接使用之前实现的
_get_obs和_get_info方法得到,reward 根据环境定义设置、terminated信号设为 “达到目标位置”,truncated信号设为 “落下悬崖”def step(self, action): '''环境一步转移''' # agent 转移到执行 action 后的新位置 self._agent_location = self._state_transition(self._agent_location, action) # 判断标识 terminated & truncated 并给出 reward terminated = np.array_equal(self._agent_location, self._target_location) truncated = self._agent_location[1].item() == self.nrow - 1 and self._agent_location[0].item() not in [0, self.ncol-1] reward = -1 if terminated: reward = 0 if truncated: reward = -100 # 获取当前状态观测和附加信息 observation = self._get_obs() info = self._get_info() # 可以在这里刷新渲染,但我这里需要渲染最新策略,所以在测试时再手动调用 render 方法 #if self.render_mode == "human": # self._render_frame() return observation, reward, terminated, truncated, info
2.2.5 render 方法
- 这里我们使用 PyGame 进行渲染,许多 Gym 官方环境都使用了 PyGame 库
- 本例中渲染工作比较复杂,注意根据
render_mode判断是否渲染价值颜色和策略,另外,由于提供 V value 和 policy 的 RL 算法对环境状态观测进行了HashPosition包装(见下文 2.3 节),将原始观测中 keyagent对应的二维位置坐标拉平成一维,所以渲染时要手动处理一下改回来def render(self, state_values=None, policy=None): if self.render_mode == "rgb_array": return self._render_frame() # 'rgb_array' 渲染模式下画面会转换为像素 ndarray 形式返回,通常用于借助 CNN 从游戏画面提取观测向量的情况,为避免影响观测不要渲染价值颜色和策略 elif self.render_mode == "human": self._render_frame(state_values, policy) # 'human' 渲染模式下会弹出窗口,如果不直接通过游戏画面提取状态观测,可以渲染价值颜色和策略,以便人员观察收敛情况 else: raise False # 不支持其他渲染模式,报错 def _state_transition(self, state, action): '''返回 agent 在 state 出执行 action 后转移到的新位置''' direction = self._action_to_direction[action] state += direction state[0] = np.clip(state[0], 0, self.ncol-1).item() state[1] = np.clip(state[1], 0, self.nrow-1).item() return state def _render_frame(self, state_values=None, policy=None): pix_square_size = self.pix_square_size canvas = pygame.Surface((self.ncol*pix_square_size, self.nrow*pix_square_size)) canvas.fill((255, 255, 255)) if self.window is None and self.render_mode == "human": pygame.init() pygame.display.init() self.window = pygame.display.set_mode((self.ncol*pix_square_size, self.nrow*pix_square_size)) if self.clock is None and self.render_mode == "human": self.clock = pygame.time.Clock() # 背景白色 pygame.draw.rect( canvas, (255, 255, 255), pygame.Rect( (0, 0), (pix_square_size*self.ncol, pix_square_size*self.nrow), ), ) # 绘制远离悬崖的方格 if self.render_mode == "human" and isinstance(state_values, np.ndarray): # human 模式下渲染状态颜色 for col in range(self.ncol): for row in range(self.nrow-1): state_value = state_values[row][col].item() max_value = 1 if np.abs(state_values).max() == 0 else np.abs(state_values).max() pygame.draw.rect( canvas, (abs(state_value)/max_value*255, 20, 20), # 通过颜色反映 state value pygame.Rect( (col*pix_square_size, row*pix_square_size), (pix_square_size-1, pix_square_size-1), # 每个状态格边长减小1,这样自动出现缝线 ), ) else: # rgb_array 模式下不渲染状态颜色 for col in range(self.ncol): for row in range(self.nrow-1): pygame.draw.rect( canvas, (150, 150, 150), pygame.Rect( (col*pix_square_size, row*pix_square_size), (pix_square_size-1, pix_square_size-1), ), ) # 绘制悬崖边最后一行方格 for col in range(self.ncol): if col == 0: color = (100, 100, 100) # 起点 elif col == self.ncol-1: color = (100, 150, 100) # 终点 else: color = (0, 0, 0) # 悬崖 pygame.draw.rect( canvas, color, pygame.Rect( (col*pix_square_size, (self.nrow-1)*pix_square_size), (pix_square_size-1, pix_square_size-1), # 每个状态格边长减小1,这样自动出现缝线 ), ) # 绘制 agent pygame.draw.circle( canvas, (0, 0, 255), (self._agent_location + 0.5) * pix_square_size, pix_square_size / 3, ) # human 模式下渲染基于 Q value 的贪心策略 if self.render_mode == "human" and isinstance(policy, np.ndarray): # 前几行正常行走区域 for col in range(self.ncol): for row in range(self.nrow-1): hash_position = col*self.nrow + row actions = policy[hash_position] for a in actions: s_ = self._state_transition(np.array([col,row]), a) if (s_ != np.array([col,row])).sum() != 0: start = np.array([col*pix_square_size+0.5*pix_square_size,row*pix_square_size+0.5*pix_square_size]) end = s_*pix_square_size+0.5*pix_square_size dot_num = 15 for i in range(dot_num): pygame.draw.rect( canvas, (10, 255-i*175/dot_num, 10), pygame.Rect( start + (end-start) * i/dot_num, (2,2) ), ) # 最后一行只绘制起点策略 col, row = 0, self.nrow-1 hash_position = col*self.nrow + row actions = policy[hash_position] for a in actions: s_ = self._state_transition(np.array([col,row]), a) if (s_ != np.array([col,row])).sum() != 0: start = np.array([col*pix_square_size+0.5*pix_square_size,row*pix_square_size+0.5*pix_square_size]) end = s_*pix_square_size+0.5*pix_square_size dot_num = 15 for i in range(dot_num): pygame.draw.rect( canvas, (10, 255-i*175/dot_num, 10), pygame.Rect( start + (end-start) * i/dot_num, (2,2) ), ) # 'human' 渲染模式下会弹出窗口 if self.render_mode == "human": # The following line copies our drawings from `canvas` to the visible window self.window.blit(canvas, canvas.get_rect()) pygame.event.pump() pygame.display.update() # We need to ensure that human-rendering occurs at the predefined framerate. # The following line will automatically add a delay to keep the framerate stable. self.clock.tick(self.metadata["render_fps"]) # 'rgb_array' 渲染模式下画面会转换为像素 ndarray 形式返回,适用于用 CNN 进行状态观测的情况,为避免影响观测不要渲染价值颜色和策略 else: return np.transpose(np.array(pygame.surfarray.pixels3d(canvas)), axes=(1, 0, 2))
2.2.6 close 方法
close()方法应该关闭环境所有使用的开放资源,本例中render_mode可能是"human",所以关闭可能打开了的窗口def close(self): if self.window is not None: pygame.display.quit() pygame.quit()
2.3 编写包装类
- 在 wrappers 目录中可以针对自定义环境编写一些所需的包装类,这里简单写一个将原始观测中
env.observation_space['agent']元素拉平成一维的包装,供后续 RL 算法使用 - 自定义包装需要继承
gym.ObservationWrapper类,然后重写observation()方法import gym # 观测包装,把环境的原生二维观测转为一维的 class HashPosition(gym.ObservationWrapper): def __init__(self, env): super().__init__(env) self.env = env map_size = env.observation_space['agent'].nvec self.observation_space = gym.spaces.Discrete(map_size[0]*map_size[1]) # 新的观测空间 def observation(self, obs): return obs["agent"][0] * self.env.nrow + obs["agent"][1]
2.4 测试环境
- 至此,我们的自定义环境和包装其实已经可以使用了,虽然这种用法不符合最佳实践,还是可以先进行测试
- 本节末尾会指出当前用法的问题,然后在 3、4 节说明使用自定义环境的最佳实践方案
2.4.1 将环境目录转换为包
- 向 MyGymExamples 目录、envs 目录、wrappers 目录分别添加
__init__.py文件,这样 python 就会把这个目录识别为一个包,从而可以在根目录通过import MyGymExamples,import MyGymExamples.envs这样的代码引入这些目录转成的包 - 在执行这种 import 时,比如
import MyGymExamples.envs时,会按从深到浅的顺序依次执行各个目录下的__init__.py进行初始化。为了能从任意一层包(目录)处直接 import 其下所有子包(子目录)内定义的类,应该在各层__init__.py文件中 import 其所有子目录中的类。本例中三个__init__.py的内容如下# envs 目录下的 __init__.py from MyGymExamples.envs.GridWorld import CliffWalkingEnv# wrappers 目录下的 __init__.py from MyGymExamples.wrappers.HashPosition import HashPosition# MyGymExamples 目录下的 __init__.py from MyGymExamples.envs.GridWorld import CliffWalkingEnv from MyGymExamples.wrappers.HashPosition import HashPosition
2.4.2 测试代码
- 本节给出实现 1.2 节实验效果的测试代码
- 在根目录创建 EnvTest_ManualControl.py,手动交互测试代码编写如下
from MyGymExamples import CliffWalkingEnv from gym.utils.play import play from gym.utils.env_checker import check_env import pygame map_size = (4,12) env = CliffWalkingEnv(render_mode='rgb_array', map_size=map_size, pix_square_size=30) # 手动交互时渲染模式必须设置为 rgb_array print(check_env(env.unwrapped)) # 检查 base 环境是否符合 gym 规范 env.action_space.seed(42) # 设置所有随机种子 observation, info = env.reset(seed=42) # env.step() 后,env.render() 前的回调函数,可用来处理刚刚 timestep 中的运行信息 def palyCallback(obs_t, obs_tp1, action, rew, terminated, truncated, info): # 非 noop 动作,打印 reward 和附加 info if action != 0: print(rew, info) # key-action 映射关系 mapping = {(pygame.K_UP,): 4, (pygame.K_DOWN,): 2, (pygame.K_LEFT,): 3, (pygame.K_RIGHT,): 1} # 开始手动交互 play(env, keys_to_action=mapping, callback=palyCallback, fps=15, noop=0) env.close() - 在根目录创建 EnvTest_RandomAction.py,自动运行测试代码编写如下
from MyGymExamples import CliffWalkingEnv from gym.utils.env_checker import check_env import numpy as np import random map_size = (4,12) env = CliffWalkingEnv(render_mode='human', map_size=map_size, pix_square_size=30) # render_mode 设置为 'human' 以渲染价值颜色和贪心策略 print(check_env(env.unwrapped)) # 检查 base 环境是否符合 gym 规范 env.action_space.seed(42) # 设置所有随机种子 observation, info = env.reset(seed=42) for _ in range(10000): # 随机采样 action 执行一个 timestep observation, reward, terminated, truncated, info = env.step(env.action_space.sample()) # 随机产生状态价值和策略进行渲染 env.render(state_values=np.random.randint(0, 10, map_size), policy=np.array([np.array(random.sample(list(range(5)), random.randint(1, 5))) for _ in range(map_size[0]*map_size[1])], dtype=object)) # 任务完成或失败,重置环境 if terminated or truncated: print(reward, info) observation, info = env.reset() env.close()
- 在根目录创建 EnvTest_ManualControl.py,手动交互测试代码编写如下
2.4.3 最佳实践
- 虽然自定义环境已经可以使用,但上述用法并不是最好的,有两个问题
- gym 库无法检测到自定义的
CliffWalkingEnv环境,因此无法像原生环境那样通过gym.make()方法定义环境实例。 此问题在第 3 节解决 - 为了使用自定义环境和包装,必须在项目中包含完整的 MyGymExamples 目录(包),也就是要包含所有源码,我们希望能将它搞成一个可以用 pip 安装的包,直接将其安装到虚拟环境中,这样就不必在工程中包含自定义环境和包装的源码了。此问题在第 4 节解决
- gym 库无法检测到自定义的
3. 将自定义环境注册到 gym
- 使用执行如下代码即可把自定义环境注册到 gym 中,我们将这一段添加到 MyGymExamples 目录下的
__init__.py文件中,这样在import MyGymExamples时就会自动注册from gym.envs.registration import register register( id='MyGymExample/CliffWalkingEnv-v0', entry_point='MyGymExamples.envs:CliffWalkingEnv', max_episode_steps=300, )id由三部分组成,可选的 namespace (这里是 MyGymExample)、必选的 name(这里是CliffWalkingEnv)和一个可选的 version(这里是v0)。id 用于在创建环境时指定环境,这里是gym.make('my_gym_examples/CliffWalkingEnv-v0', render_mode='human', ...)entry_point指定环境类在源码中的路径max_episode_steps指定创建环境时增加一个TimeLimitwrapper,轨迹超长就会触发truncated标志,可以通过info["TimeLimit.truncated"]区分truncated和terminated。类似地,还可以设置其他自带 wrapper,包括

- 除了上面的方法以外,注册代码其实可以随便放到一个
module包里,然后通过形如env = gym.make('module:Env-v0')的代码创建环境。从这个角度看,上面的代码其实相当于把注册代码放到了MyGymExample包里,所以创建环境时也可以不写import MyGymExample,而是在创建环境时写env = gym.make('MyGymExamples:MyGymExample/CliffWalkingEnv-v0',...)。有时某些第三方代码库(比如RL算法库)只允许传入环境 id,这种方法就非常有用了,可以在不改动代码库的情况下注册环境 - 总之,把注册代码加到 MyGymExamples 目录下的
__init__.py文件中后,有以下三种创建环境的等价方式- 不注册,直接调用源码定义的类,同第 2 节
from MyGymExamples import HashPosition, CliffWalkingEnv env = CliffWalkingEnv( render_mode='rgb_array', map_size=map_size, pix_square_size=30) - 通过
import MyGymExamples自动执行 MyGymExamples 目录中的__init__.py文件,从而执行到注册代码import MyGymExamples env = gym.make('MyGymExamples/CliffWalkingEnv-v0', render_mode='rgb_array', map_size=map_size, pix_square_size=30) - 看做注册代码在 MyGymExamples 模块中,使用前缀形式
env = gym.make('MyGymExamples:MyGymExamples/CliffWalkingEnv-v0', render_mode='rgb_array', map_size=map_size, pix_square_size=30)
- 不注册,直接调用源码定义的类,同第 2 节
4. 自定义环境的打包分发
- 最后,我们利用 setuptools 库把 MyGymExample 打包成一个源码包,然后使用 pip 将其安装到虚拟环境,这样就可以在工程中省略自定义环境和包装类的所有源码了。这里只使用 setuptools 的一小部分基础功能,关于该库的详细介绍请参考:python打包分发工具:setuptools
- 打源码包以及 pip 安装流程如下
- 在根目录编写如下 setup.py 文件
from setuptools import setup, find_packages setup( name="MyGymExamples", version="0.0.1", install_requires=["gym==0.26.2", "pygame==2.1.0"], packages=find_packages() ) - 在根目录命令行窗口执行
python setup.py sdist,这会在根目录生成dist文件夹(包含压缩源码的分发包)和.egg-info文件夹(中间临时配置信息) - 切换目录到 dist 文件夹,执行
pip install MyGymExamples-0.0.1.tar.gz直接 pip 安装源码包,这会使 conda 虚拟环境的 site-packages 文件夹中出现自定义 MyGymExamples 包的全部源码和 MyGymExamples-0.0.1.dist-info 配置信息。在命令行输入conda list也能看到自定义包的安装信息... mygymexamples 0.0.1 pypi_0 pypi ... - 使用时直接和平时一样
from MyGymExamples import HashPosition, CliffWalkingEnv或者import MyGymExamples就好
- 在根目录编写如下 setup.py 文件
5. 完整代码下载
- 自定义环境源码、环境测试代码以及 RL 训练代码已全部上传至 github:RL_task_practice/4,欢迎 star
- 关于利用自定义环境进行 RL 训练的内容,将在下一篇文章详细说明
















 73
73











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











