







 Transformer-XL通过段级递归机制和相对位置编码解决了传统Transformer模型的上下文长度限制和碎片化问题,实现了更长上下文的学习,并在性能和推理速度上有所提升。此外,文章介绍了缓存机制如何在不回传梯度的情况下扩展上下文长度,以及相对位置编码如何确保时序一致性。
Transformer-XL通过段级递归机制和相对位置编码解决了传统Transformer模型的上下文长度限制和碎片化问题,实现了更长上下文的学习,并在性能和推理速度上有所提升。此外,文章介绍了缓存机制如何在不回传梯度的情况下扩展上下文长度,以及相对位置编码如何确保时序一致性。
- 标题:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- 文章链接:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- 代码:https://github.com/kimiyoung/transformer-xl
- 发表:ACL 2019
- 领域:Transformer (decoder) 改进
- 【本文为速览笔记,仅记录核心思想,具体细节请看原文】
- 摘要:transformer 具有学习长期依赖的潜力,但在语言建模设置中受到固定context length的限制。我们提出了 Transformer XL,可以在不破坏时间一致性的前提下扩展context length。它由一种段级递归机制(segment-level recurrence mechanism)和一种新的位置编码方案组成。我们的方法不仅能够捕获较长期的上下文依赖关系,而且可以解决上下文碎片化问题。Transformer XL 学习的上下文长度比 RNN 长80%,比普通 Transformer 长450%,在短序列和长序列上都取得了更好的性能,而且在评估过程中比普通 Transformer 快1800+倍… (关于性能的部分省略)
注:本文中的 Transformer 其实特指 Transformer-decoder,也就是 GPT 模型
文章目录
1 传统模型的做法 & 问题
- 传统 Transformer 模型能处理的序列长度是固定的,由 attention 层的尺寸决定,必须将序列数据调整为此固定长度才能输入模型。其训练和推断过程一般如下图所示
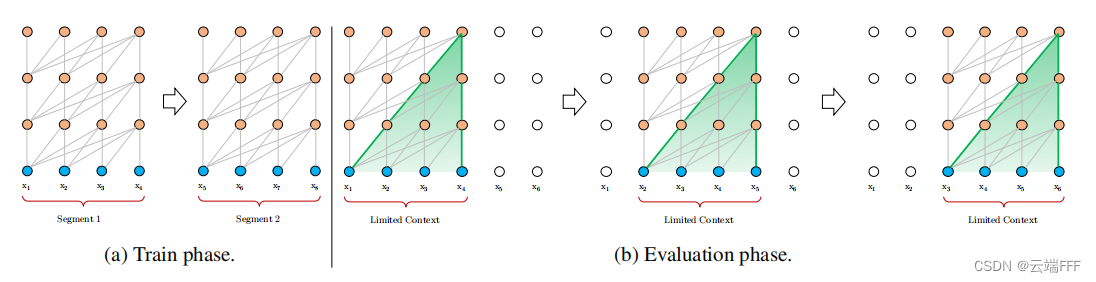
- 训练时,若序列数据长度比固定长度短,则通过 padding 方式补全;若序列数据长度比固定长度长,通常将长序列划分为多个具有固定长度 segments,训练时仅在各个 segment 内部计算 attention,而 segments之间没有联系。
- 推断时,每个 step 对具有固定长度的 segment 进行计算,预测出下一个 token 后,将 segment 范围整体右移进行 AutoRegress
- 传统方法有如下问题
上下文长度受限:模型能够建模的 max context length 被限制为此固定长度,这会影响推理性能上下文碎片问题:出于效率的考虑,划分 segments 时没有考虑句子的自然边界,导致分割出来的 segments 在语义上是不完整的,这在一定程度程度上会误导模型推理速度慢:Transformer decoder 计算的是Masked self attention,也就是每个 token 只以自身产生 query,和自己之前的所有 token 生成的 key 计算 attention value 并汇聚信息,AutoRegress 过程右移 segments 的操作不会影响之前的信息汇聚结果,因此推断 AutoRegress 过程中任意相邻两步重叠的那些 hidden value(重叠的部分黄色点)应当是不需要重新计算的。由于传统模型的固定长度限制,AutoRegress 过程的每次右移都会导致模型忽略最早的一个 token,不得不对整个 segments 的所有 hidden value 进行重新计算。模型支持的 context length 越长,堆叠的 Transformer Block 越多,这种重复计算就越多,这会大大降低测试效率
2 本文方法
2.1 片段递归(Segment-Level Recurrence)
- 为了解决上述问题,Transformer-XL 提出可以在计算当前 segment 时,缓存并利用上一个 segment 中所有 layer 的 hidden state 序列,而且上一个segment的所有隐向量序列只参与前向计算,不再进行反向传播,这就是所谓的segment-level Recurrence。如下图所示
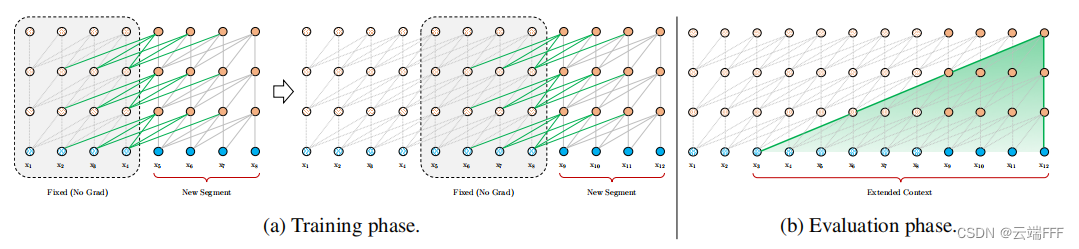
训练阶段:每个 segment 长度保持为固定长度 L L L,但是计算 New segment 时可以通过绿线访问之前缓存的 hidden state value(不回传梯度),这缓解了上下文碎片问题- 注意示意绿线维持了每次输入模型的序列长度为 L L L 不变,这样可以保证 Transformer-XL 模型占用的显存大小和传统模型相同(问题的出发点就是模型能处理的序列长度上限受到显存限制)
- 理论上,需要在每一步计算时仅将相应的 L L L 长度序列放到显存中,但这样就会无法进行 teacher-forcing 并行且难以编码,所以作者开源代码中的做法是直接把完整的上一个 segment 放到显存,在计算 loss 时通过 mask 方法留下所需的部分(详见下文3节)。这种实现方法虽然效果相同,但是没有达成节省显存的效果
- 由于以上原因,有些借用 Transformer-XL 作为 backbone 的方法中训练阶段不进行缓存,仅在测试时缓存(如 gato 和 DB1)以扩展等效上下文长度并加速推断过程
推断阶段:仍然是每个 step 右移一位做 AutoRegress,输入序列长度也仍然是模型的固定长度 L L L,区别在于计算 attention 时仅由上一步 AutoRegress 生成的 token 来产生 query,缓存的前驱 hidden state value 仅生成 key 不产生 query,从而避免了重叠 hidden value 计算。另外缓存机制还变相扩展了有效序列长度,如图所示,最后一个 Transformer Block 对应的 context length 为固定长度 L L L,每往前一个 block 扩展 L − 1 L-1 L−1- 微观上看,提升计算效率的根本原因在于生成 query 的 token 数量减少了,这意味着计算 attention & 汇聚 value 的操作减少了。传统模型的每一层 Transformer Block 有 L L L 个 query,这样才能生成 L L L 个 hidden state 输出供下一层输入用,而 Transformer XL 在推断过程中每次只需要用最近的一个 token 产生 query,其他的 hidden state 都是缓存好的不需计算了
- 设 Transformer Block 层数为 N N N,简单 AutoRegress 得到的等价上下文长度可达(图中绘制了 N = 3 , L = 4 N=3,L=4 N=3,L=4 的情况) L c o n t e x t = L + ( N − 1 ) ( L − 1 ) = N ( L − 1 ) + 1 L_{context} = L+(N-1)(L-1) = N(L-1)+1 Lcontext=L+(N−1)(L−1)=N(L−1)+1
- 由于使用了特殊的位置编码(详见下文1.2.2节),在固定长 L L L 序列上训练的模型可以在评估过程中推广到更长的上下文序列上,因此只要显存足够,推断时可以缓存更多的 segment,进一步增加上下文长度
- 下面给出片段递归的形式化表述:设
s
τ
,
s
τ
+
1
s_\tau,s_{\tau+1}
sτ,sτ+1 是相邻的两个 segment,模型输入序列长度为
L
L
L,包含
N
N
N 层 Transformer Block,每个 hidden value 维度为 d,将
s
τ
s_\tau
sτ 中第
n
n
n 层 hidden node value 记为
h
τ
n
∈
R
L
×
d
h_\tau^n\in R^{L\times d}
hτn∈RL×d,则
s
τ
+
1
s_{\tau+1}
sτ+1 中第
n
n
n 层 hidden node value
h
τ
+
1
n
h_{\tau+1}^n
hτ+1n 如下计算
h ~ τ + 1 n − 1 = [ S G ( h τ n − 1 ) ∘ h τ + 1 n − 1 ] , q τ + 1 n , k τ + 1 n , v τ + 1 n = h τ + 1 n − 1 W q ⊤ , h ~ τ + 1 n − 1 W k ⊤ , h ~ τ + 1 n − 1 W v ⊤ , h τ + 1 n = Transformer-Layer ( q τ + 1 n , k τ + 1 n , v τ + 1 n ) . \begin{array}{l} \widetilde{\mathbf{h}}_{\tau+1}^{n-1}=\left[\mathrm{SG}\left(\mathbf{h}_{\tau}^{n-1}\right) \circ \mathbf{h}_{\tau+1}^{n-1}\right], \\ \space\\ \mathbf{q}_{\tau+1}^{n}, \mathbf{k}_{\tau+1}^{n}, \mathbf{v}_{\tau+1}^{n}=\mathbf{h}_{\tau+1}^{n-1} \mathbf{W}_{q}^{\top}, \widetilde{\mathbf{h}}_{\tau+1}^{n-1} \mathbf{W}_{k}^{\top}, \widetilde{\mathbf{h}}_{\tau+1}^{n-1} \mathbf{W}_{v}^{\top}, \\ \space\\ \mathbf{h}_{\tau+1}^{n}=\text { Transformer-Layer }\left(\mathbf{q}_{\tau+1}^{n}, \mathbf{k}_{\tau+1}^{n}, \mathbf{v}_{\tau+1}^{n}\right) . \end{array} h τ+1n−1=[SG(hτn−1)∘hτ+1n−1], qτ+1n,kτ+1n,vτ+1n=hτ+1n−1Wq⊤,h τ+1n−1Wk⊤,h τ+1n−1Wv⊤, hτ+1n= Transformer-Layer (qτ+1n,kτ+1n,vτ+1n). 其中 S G SG SG 是 stop-gradient,表示不再对 s τ s_\tau sτ 的隐向量做梯度回传, ∘ \circ ∘ 是向量拼接符号。- 对 n − 1 n-1 n−1 层的 hidden node,通过拼接前驱 segment 进行扩展得到 h ~ τ + 1 n − 1 \widetilde{\mathbf{h}}_{\tau+1}^{n-1} h τ+1n−1,扩展部分关闭梯度
- query 仅在当前 segment 上计算得到,长度为 L L L;key、value 在扩展段上计算得到,长度 2 L 2L 2L
- Transformer-Layer 输出长度由 key 长度决定,长度 L L L
2.2 相对位置编码(Relative Positional Encodings)
- 仍考虑上面图中绘制的模型输入长度
L
=
4
L=4
L=4 的情景,传统方法中相邻两个 segment 的绝对位置编码为 0 1 2 3 0 1 2 3
- 如果维持位置编码不变,当通过绿线(缓存)构造跨 segment 序列时会出现重复的绝对位置编码,误导模型
- 如果每次构造好长 L L L 的序列再按顺序编码 0 1 2 3,会导致生成之前缓存的 hidden state value 的位置编码和当前所需的不同,就没法使用缓存了
- 为了构造一致的位置编码,作者提出以 “当前要预测的 token(即生成 query 的 token)位置” 为原点构造相对位置编码,这种情况下无论哪个长为
L
=
4
L=4
L=4 的序列的位置编码都是 3 2 1 0,代表与 “当前要预测的 token 位置” 的相对距离。这种编码方案可以自然地不断向前扩展,保证时序一致性。具体的,这种位置编码具有以下特点
- 任意 attention head,无论 token 处于什么位置,生成的 query 向量都应该一致
- 任意两个 token 之间,只要间距相同,则相对位置信息相同
- 作者将 token 的内容信息和位置信息拆分,即 key/query 的内容信息/位置信息是在四个不同的空间中产生的,这有助于学习更好的特征
- relative pos embedding 是由正余弦公式生成的(类似BERT),这样模型就能学到关于位置嵌入的归纳偏差,结合 3 可以实现序列长度泛化
- 下面给出相对位置编码的形式化描述。先看传统模型的绝对位置编码是如何在 attention 计算时发挥作用的

A i , j a b s = ( E x i + U i ) ⊤ W q ⊤ W k ( E x j + U j ) = E x i ⊤ W q ⊤ W k E x j + E x i ⊤ W q ⊤ W k U j + U i ⊤ W q ⊤ W k E x j + U i ⊤ W q ⊤ W k U j \begin{aligned} \mathbf{A}_{i, j}^{\mathrm{abs}}&=\left(\mathbf{E}_{x_{i}}+\mathbf{U}_{i}\right)^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k}\left(\mathbf{E}_{x_{j}}+\mathbf{U}_{j}\right) \\ &=\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{E}_{x_{j}}+\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{U}_{j}+\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{E}_{x_{j}}+\mathbf{U}_{i}^{\top} \mathbf{W}_{q}^{\top} \mathbf{W}_{k} \mathbf{U}_{j} \end{aligned} Ai,jabs=(Exi+Ui)⊤Wq⊤Wk(Exj+Uj)=Exi⊤Wq⊤WkExj+Exi⊤Wq⊤WkUj+Ui⊤Wq⊤WkExj+Ui⊤Wq⊤WkUj 其中 i > j i>j i>j 是要计算 attention 的两个 token 的位置索引, E , U E,U E,U 分别代表 token content embedding 和 absolute pos embedding,二者相加得到 token embedding,再分别由投影矩阵 W q , W k W_q, W_k Wq,Wk 生成 query vector 和 key vector,最后做向量内积得到 attention score α i , j \alpha_{i,j} αi,j,注意其中 U U U 通常是可学习的。这个计算过程可以展开为四个部分,接下来下面我们按以上四点对展开式进行处理

- 第一步把 learnable absolute pos embedding U j U_j Uj 换成 unlearnable relative pos embedding R i − j R_{i-j} Ri−j,注意这是正余弦公式生成的,不可学习
- 第二步正常展开
- 第三步区分 token content embedding 和 relative pos embedding 的 key 投影矩阵,得到 W k , E W_{k,E} Wk,E 和 W k , R W_{k,R} Wk,R
- 第四步将所有 query 统一为同一个可学习向量,并对 key 的 content 和 position 加以区分,得到可学习的 u , v u, v u,v
- 最后我们还可以整理一下得到
A i , j r e l = ( E x i ⊤ W q ⊤ + u ⊤ ) W k , E E x j + ( E x i ⊤ W q ⊤ + v ⊤ ) W k , R R i − j = ( query i + query_bias c o n t e n t i ) key c o n t e n t j + ( query i + query_bias p o s i t i o n i ) key p o s i t i o n i − j \begin{aligned} \mathbf{A}_{i, j}^{\mathrm{rel}} &=(\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top} + u^\top) \mathbf{W}_{k, E} \mathbf{E}_{x_{j}}+(\mathbf{E}_{x_{i}}^{\top} \mathbf{W}_{q}^{\top}+v^\top) \mathbf{W}_{k, R} \mathbf{R}_{i-j} \\ &=(\text{query}^i + \text{query\_bias}^i_{content})\text{key}^j_{content} + (\text{query}^i + \text{query\_bias}^i_{position})\text{key}^{i-j}_{position} \end{aligned} Ai,jrel=(Exi⊤Wq⊤+u⊤)Wk,EExj+(Exi⊤Wq⊤+v⊤)Wk,RRi−j=(queryi+query_biascontenti)keycontentj+(queryi+query_biaspositioni)keypositioni−j 这样式子中各项都很直观了
2.3 一个 trick
- GLU Variants Improve Transformer 这篇 2020 年的文章分析了对 transformer 模型中 FFD 层的诸多改进,在后续 Transformer-based 模型中得到的广泛使用,这里也提一嘴。
- 标准的 FFD 层是一个两层 MLP
O = ϕ ( X W u ) W o O = \phi(XW_u)W_o O=ϕ(XWu)Wo 其中 X ∈ R n × d , W u ∈ R d × e , W o ∈ R e × d X\in\R^{n\times d}, W_u\in\R^{d\times e}, W_o\in\R^{e\times d} X∈Rn×d,Wu∈Rd×e,Wo∈Re×d, ϕ \phi ϕ 为激活函数,通常是 ReLU。GLU 这篇文章研究了此两层 MLP 的诸多变体,基本思想是把隐空间投影矩阵 W u W_u Wu 变成两个,再把两个隐变量分别激活后复合得到输出,提升 FFD 层的容量。形式化表示如下
U = ϕ u ( X W u ) V = ϕ v ( X W v ) O = ( U ⊙ V ) W o \begin{array}{l} U=\phi_{u}\left(X W_{u}\right) \\ V=\phi_{v}\left(X W_{v}\right) \\ O=(U \odot V) W_{o} \end{array} U=ϕu(XWu)V=ϕv(XWv)O=(U⊙V)Wo 其中 W u , W v ∈ R d × e W_u,W_v\in\R^{d\times e} Wu,Wv∈Rd×e, ⊙ \odot ⊙ 表示按对应位置元素相乘, ϕ u , ϕ v \phi_{u},\phi_{v} ϕu,ϕv 是两个激活函数 - 下图整理了各种变体的形式和性能表现

可见其中 GEGLU 和 SwiGLU 是表现比较好的
3. 补充
- 性能分析请参考原文,在性能和推理速度方面均有提升
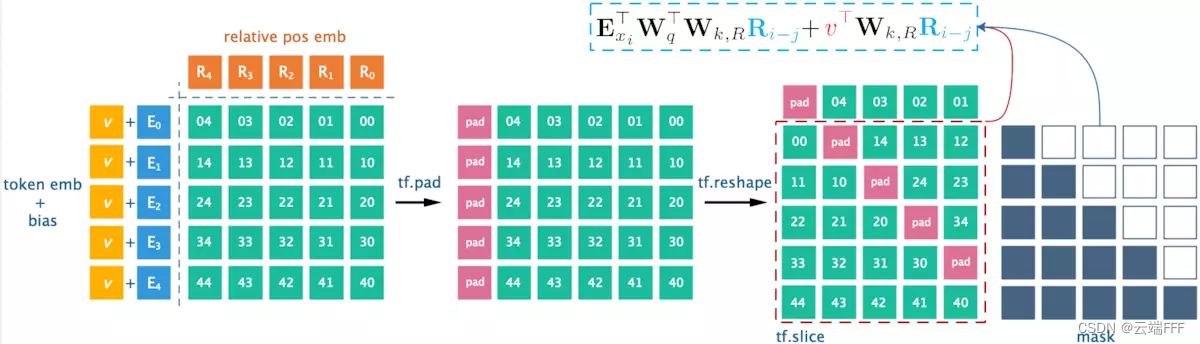
- 代码实现比较麻烦,可参考[NLP] Relative location encoding (2) Relative Positional EncoDings - Transformer-XL。贴一下核心图示
- 不使用 memory 缓存时的位置编码和 loss mask 构造过程如下。处理结果还要对应位置加上一个相同尺寸的 content 相关性成分,最后 mask 得到下三角矩阵,注意相对位置信息的对应关系
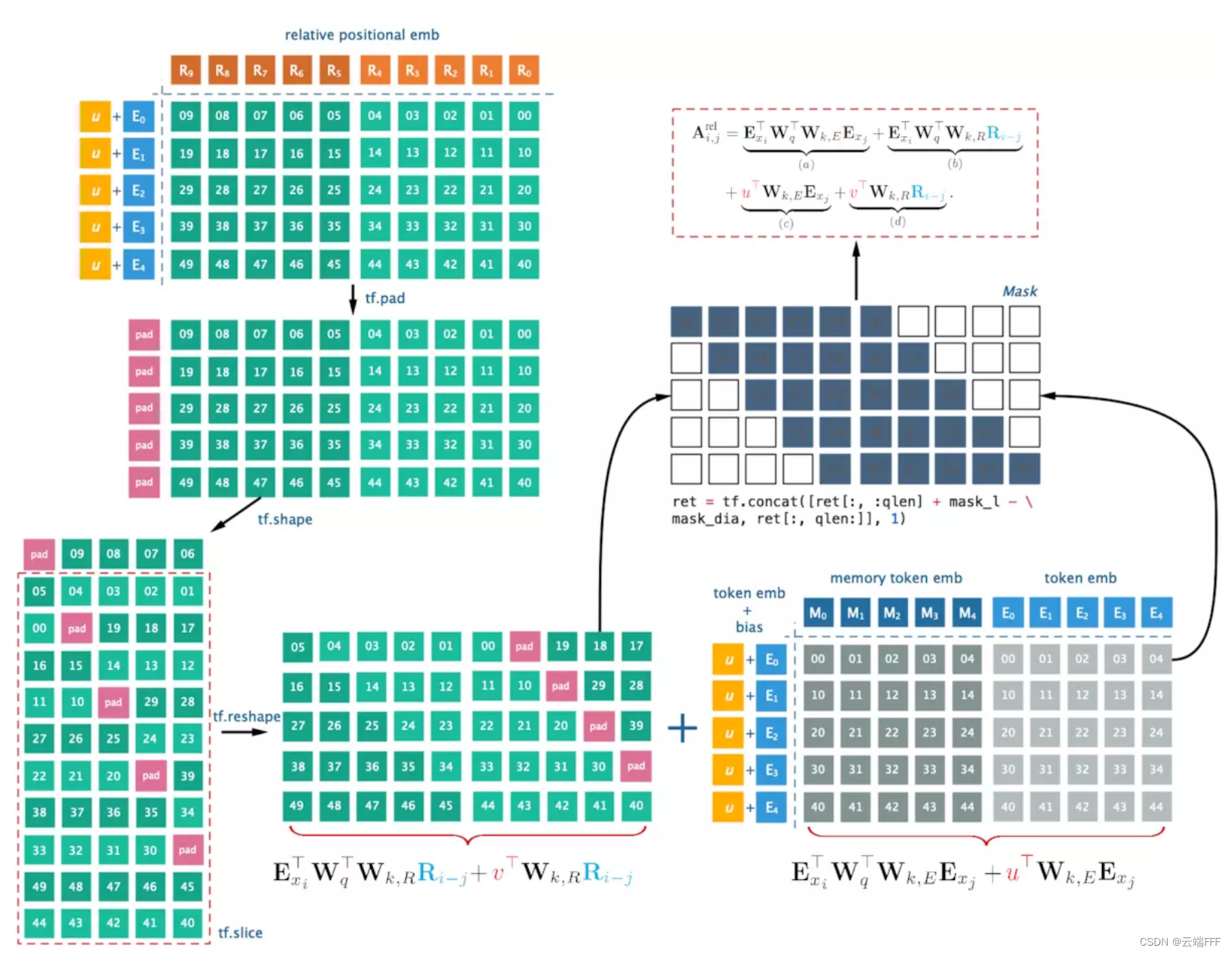
- 使用 memory 缓存时的 attention score 计算过程如下,最后 mask 得到中间的灰色部分(图中最左边画错了多了一斜列),注意相对位置信息的对应关系
- 不使用 memory 缓存时的位置编码和 loss mask 构造过程如下。处理结果还要对应位置加上一个相同尺寸的 content 相关性成分,最后 mask 得到下三角矩阵,注意相对位置信息的对应关系
- 参考:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











