






1. Transformer底层原理解析
1.1 核心架构突破
Transformer是自然语言处理领域的革命性架构,其核心设计思想完全摒弃了循环结构,通过自注意力机制实现全局依赖建模。
整体架构图如下:
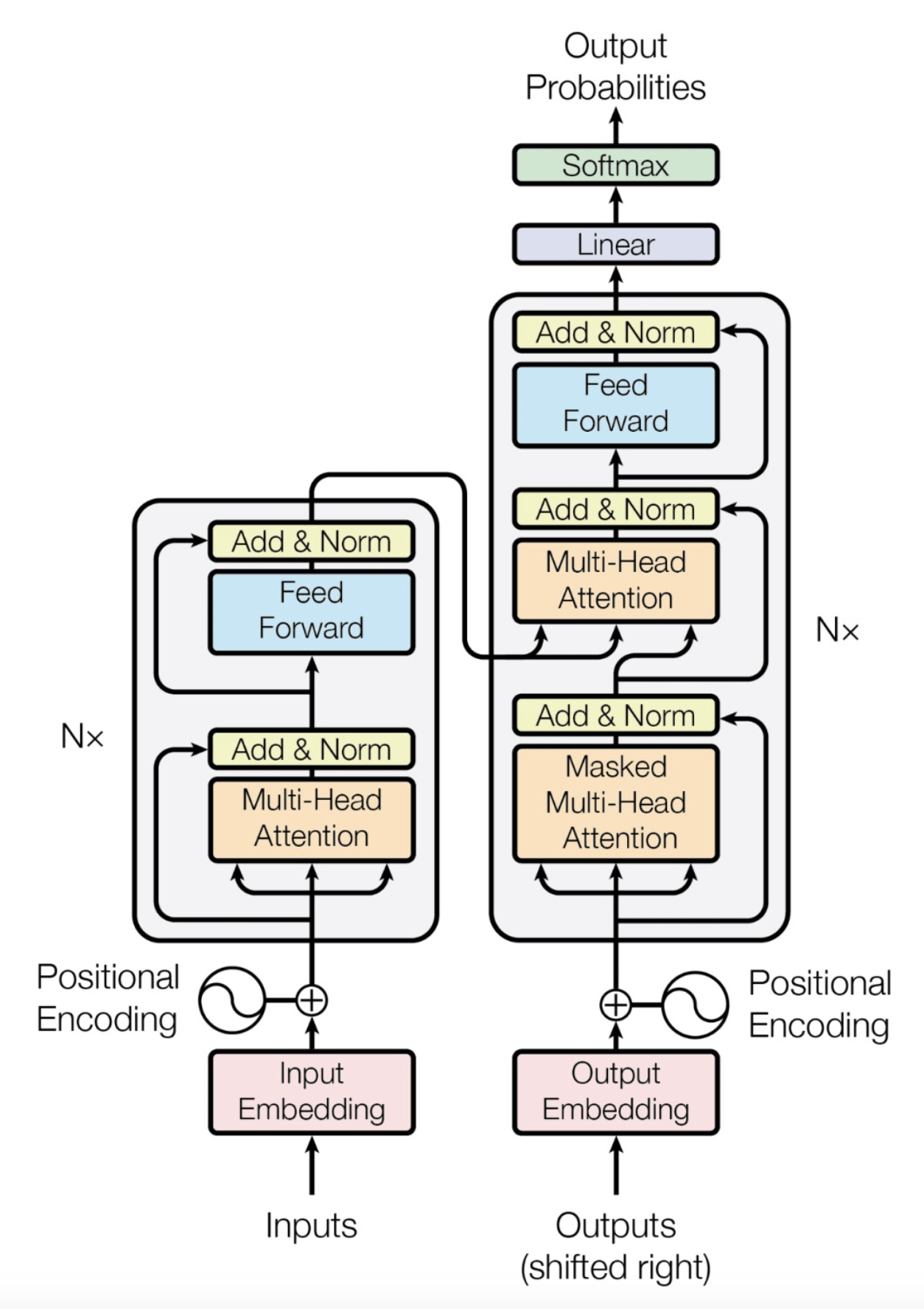
以下是其核心组件:
1)自注意力机制(Self-Attention)
- 输入序列的每个位置都能直接关注所有位置
- 数学公式(缩放点积注意力):
- Q:查询矩阵(当前关注点)
- K:键矩阵(被比较项)
- V:值矩阵(实际内容)
- 缩放因子 防止点积过大导致梯度消失
2)多头注意力(Multi-Head Attention)
- 并行多个注意力头捕获不同子空间信息
- 计算过程:
$$
\text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,...,\text{head}_h)W^O
$$
- 每个头:
3)位置编码(Positional Encoding)
- 引入序列位置信息(因无循环/卷积结构)
- 正弦函数编码(可学习版本也常用):
$$
PE_{(pos,2i)} = \sin(pos/10000^{2i/d_{model}}) \\
PE_{(pos,2i+1)} = \cos(pos/10000^{2i/d_{model}})
$$
- 最新研究:相对位置编码(Relative Position)
4)残差连接与层归一化
- 每个子层后接残差连接:
- 层归一化(LayerNorm)提升训练稳定性
1.2 编码器-解码器架构
| 组件 | 功能描述 |
|---|---|
| 编码器栈 | 由N个相同层堆叠,每层包含自注意力+前馈网络 |
| 解码器栈 | 包含自注意力(带掩码)、编码器-解码器注意力、前馈网络三层结构 |
| 前馈网络 | 位置独立的全连接网络(通常含一个扩展层) |
| 输出层 | 线性层+softmax生成概率分布 |
2. 基于PyTorch实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1)]
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性变换矩阵
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def split_heads(self, x):
batch_size = x.size(0)
return x.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
def forward(self, q, k, v, mask=None):
# 线性变换 + 分头
q = self.split_heads(self.W_q(q)) # (B, h, S, d_k)
k = self.split_heads(self.W_k(k))
v = self.split_heads(self.W_v(v))
# 计算注意力分数
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(scores, dim=-1)
# 注意力加权求和
context = torch.matmul(attn_weights, v) # (B, h, S, d_k)
context = context.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model) # (B, S, d_model)
return self.W_o(context)
class PositionWiseFFN(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
return self.fc2(self.dropout(F.relu(self.fc1(x))))
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.ffn = PositionWiseFFN(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x, mask=None):
# 自注意力子层
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 前馈子层
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout(ffn_output))
return x
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.ffn = PositionWiseFFN(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x, enc_output, src_mask, tgt_mask):
# 自注意力(带掩码)
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 编码器-解码器注意力
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
# 前馈子层
ffn_output = self.ffn(x)
x = self.norm3(x + self.dropout(ffn_output))
return x
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512,
num_heads=8, num_layers=6, d_ff=2048):
super().__init__()
self.encoder_embed = nn.Embedding(src_vocab_size, d_model)
self.decoder_embed = nn.Embedding(tgt_vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model)
self.encoder_layers = nn.ModuleList(
[EncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList(
[DecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def encode(self, src, src_mask):
src_emb = self.pos_encoding(self.encoder_embed(src))
for layer in self.encoder_layers:
src_emb = layer(src_emb, src_mask)
return src_emb
def decode(self, tgt, enc_output, src_mask, tgt_mask):
tgt_emb = self.pos_encoding(self.decoder_embed(tgt))
for layer in self.decoder_layers:
tgt_emb = layer(tgt_emb, enc_output, src_mask, tgt_mask)
return tgt_emb
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
enc_output = self.encode(src, src_mask)
dec_output = self.decode(tgt, enc_output, src_mask, tgt_mask)
return self.fc_out(dec_output)
# 示例使用
if __name__ == "__main__":
# 虚拟数据
src_vocab_size = 5000
tgt_vocab_size = 5000
src = torch.randint(0, 5000, (32, 100)) # (batch, seq_len)
tgt = torch.randint(0, 5000, (32, 90))
# 创建模型
model = Transformer(src_vocab_size, tgt_vocab_size)
# 生成掩码(示例)
src_mask = torch.ones(32, 1, 100) # 假设无padding
tgt_mask = torch.tril(torch.ones(90, 90)).expand(32, 1, 90, 90)
# 前向传播
output = model(src, tgt[:, :-1], src_mask, tgt_mask[:, :, :-1, :-1])
print("Output shape:", output.shape) # (batch_size, seq_len, tgt_vocab_size)3. 代码逐行解释
1)位置编码(PositionalEncoding)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))- 计算频率项:![]() ,使用指数和对数简化计算
,使用指数和对数简化计算
- 奇偶位置分别使用sin/cos函数
2)多头注意力(MultiHeadAttention)
def split_heads(self, x):
return x.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)- 将嵌入维度拆分为多个头:`(B, S, d_model)` → `(B, h, S, d_k)`
- `transpose`将头维度提前以实现并行计算
3)前馈网络(PositionWiseFFN)
self.fc1 = nn.Linear(d_model, d_ff) # 扩展维度(通常4倍)
self.fc2 = nn.Linear(d_ff, d_model) # 恢复原始维度- 经典设计:先扩展后压缩,引入非线性
4)解码器层(DecoderLayer)
attn_output = self.self_attn(x, x, x, tgt_mask)- 自注意力使用下三角掩码,防止当前位置关注未来信息
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)- 编码器输出作为K/V,解码器当前状态作为Q
5)Transformer主类
self.pos_encoding = PositionalEncoding(d_model)- 位置编码在嵌入后直接相加
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
enc_output = self.encode(src, src_mask)
dec_output = self.decode(tgt, enc_output, src_mask, tgt_mask)- 经典流程:先编码整个源序列,再自回归生成目标序列
4. 扩展建议
1)性能优化
- 实现Flash Attention(减少显存占用)
- 使用混合精度训练(`torch.cuda.amp`)
2)大模型技巧
- 添加Pre-LayerNorm(训练更稳定)
- 使用SwiGLU或者GELU激活函数替代ReLU
3)高效推理
- 实现KV Cache加速自回归生成
- 集成Beam Search解码策略
4)预训练扩展
- 添加MLM头实现BERT式预训练
- 添加LM头实现GPT式预训练
5)多模态适配
- 替换为Vision Transformer(ViT)的patch嵌入
- 集成Cross-Modal Attention(如CLIP)

















 7965
7965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









