







前言:wfs 是高性能海量小文件存储系统 ,支持Linux,Windows,Macos,FreeBSD,solaris等系统, 可以高效地进行文件存储和读取。wfs 支持文件压缩归档,并提供简洁的数据读取方式和文件后台管理和 以及归档文件的碎片整理等。
WFS官网
在线测试(用户名admin 密码123)
WFS使用文档
Github源码地址
海量小文件问题(LOSF)是一个在大规模数据存储与管理中广泛存在的挑战,尤其是在互联网、物联网、云计算、大数据等领域的应用场景中尤为突出:
- 系统调用开销:对每个小文件的操作(如打开、关闭、读写等)都需要单独的系统调用,这些调用的开销在小文件数量巨大时累积起来,成为性能瓶颈。
- 元数据管理:每个文件对应一份元数据(如文件名、大小、权限、位置等),海量小文件意味着需要管理大量的元数据。元数据索引、查询和更新的效率直接影响到文件的检索速度和存储系统的整体性能。
- 文件查询效率:在大量小文件中查找特定文件时,遍历和筛选的成本很高,尤其是在缺乏高效索引的情况下。
- 磁盘数据布局:小文件可能导致磁盘空间利用率低(由于文件系统块大小与小文件大小不匹配造成的内部碎片),以及写放大问题(尤其是在写密集型场景中)。
- CPU占用率:处理大量小文件请求时,CPU可能忙于处理I/O调度、元数据操作等,导致CPU资源消耗过大,影响整体系统性能。
wfs针对LOSF问题的实现:
- 高效存储布局与合并技术: WFS将多个小文件聚合成大文件存储,以减少元数据开销和提高存储利用率。同时,通过灵活的索引机制,确保每个小文件都能快速定位和提取。
- 元数据管理优化: 针对大量小文件元数据管理难题,wfs采用高效元数据索引和缓存策略,减少元数据查询时间,并采用层级目录结构或哈希索引等方法,降低元数据存储的复杂度。
- 缓存与预读策略: lru缓存机制,对访问频繁的数据进行缓存,降低I/O操作次数,提高读取速度。
- 数据去重与压缩技术: 实现数据去重和数据压缩,去除重复内容,减小存储空间占用,并通过多级压缩算法优化存储效率。
wfs 的应用场景
- 海量非结构化数据存储:适用于存储大量的非结构化数据,如图片、视频、日志文件、 备份数据、静态资源文件等。
- 高效文件数据读取:wfs存储引擎可以达到100万/每秒 以上的数据读取效率,特别适合文件读取密集型的业务。
- 多种图片处理需求:wfs内置图片基础处理,适合对图片处理多种要求的业务,如图片适应多个尺寸,自定义裁剪等。
V1.0.7更新内容
- 修复bug
- 优化性能
- 优化后台管理界面
- 更新docker镜像: docker pull donnie4w/wfs
说明:
wfs的图片处理,有较多url参数,使用图片处理,可以方便显示图片处理的正确参数用法,更多具体的图片处理方式可以参考 使用文档
新增后台图片处理界面:
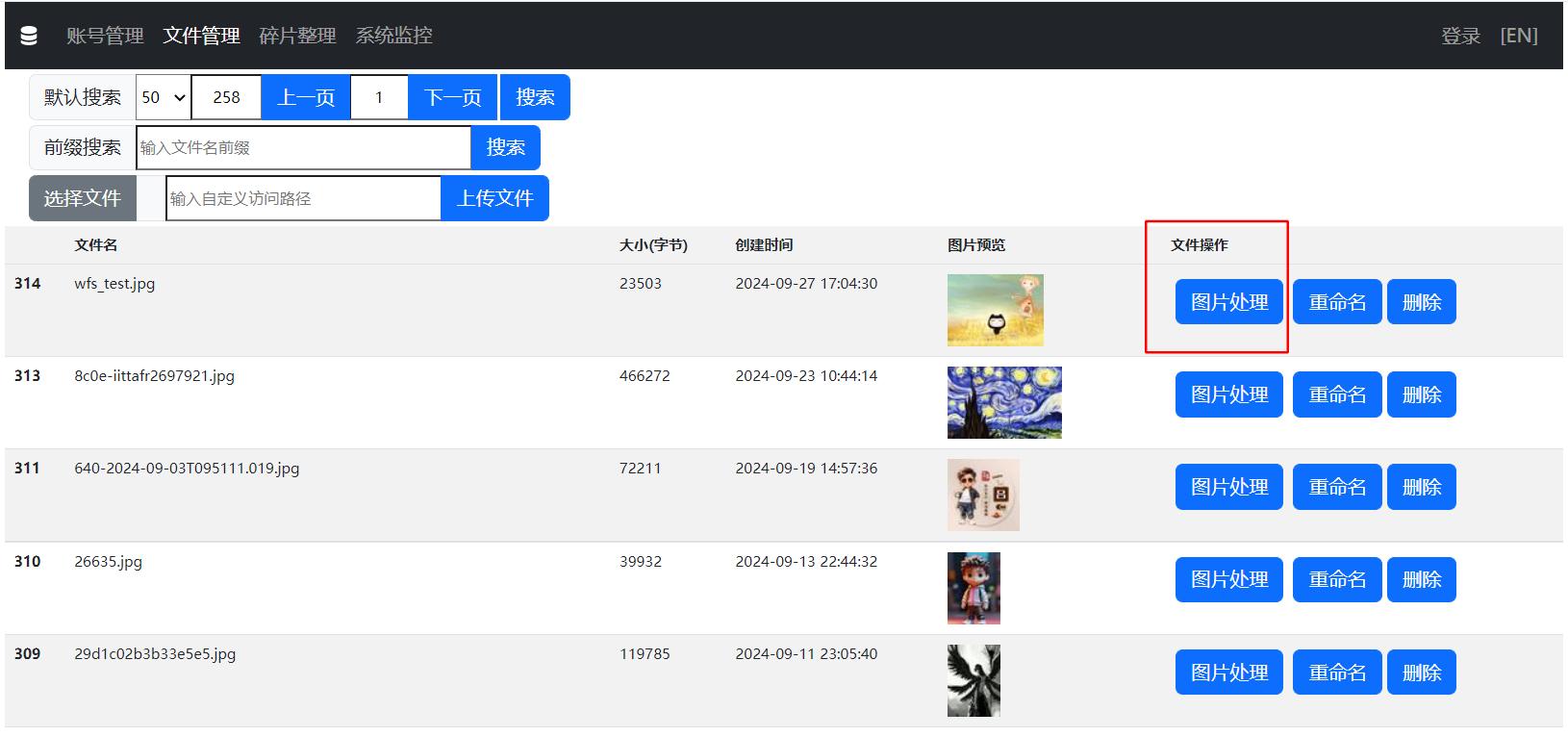
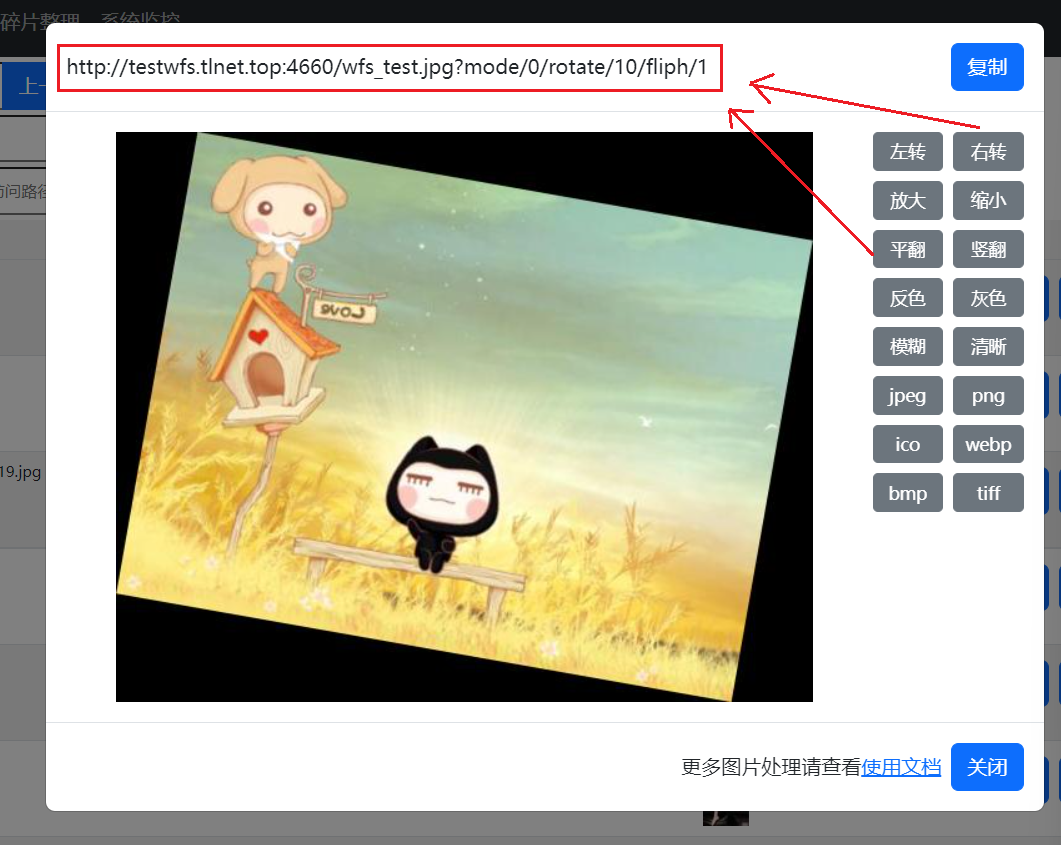
通过图片处理,界面将显示图片处理参数的正确拼接方式。
说明:后台界面管理只是一种辅助模式,应用到项目中时,高效对图片进行增删改查,建议使用wfs客户端,客户端使用tcp与压缩协议,可以有效提高文件操作效率。















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









