







数据集获取:
链接:https://pan.baidu.com/s/1mF7TJzDfdJBzfZW66kxY_Q?pwd=1234
提取码:1234
一、数据整理
#导入库
import numpy as np
from scipy.cluster.vq import *
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import pandas as pd
import numpy as np
from scipy.cluster.vq import *
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from scipy.spatial.distance import cdist
from matplotlib.ticker import MultipleLocator
from matplotlib import style
%matplotlib inline
import numpy as np
import pandas as pd
from scipy import stats, integrate
import seaborn as sns
import matplotlib.pyplot as plt
# seaborn中文乱码解决方案
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf',size=20)
sns.set(font=myfont.get_name(), color_codes=True)
导入NBA数据,我放在我的gitee里面,需要的朋友点击文章最上面的链接自取。
nbadata=pd.read_excel("nbamergeall.xlsx")
NBA数据的属性如下:共27个特征,718条数据。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 718 entries, 0 to 717
Data columns (total 27 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
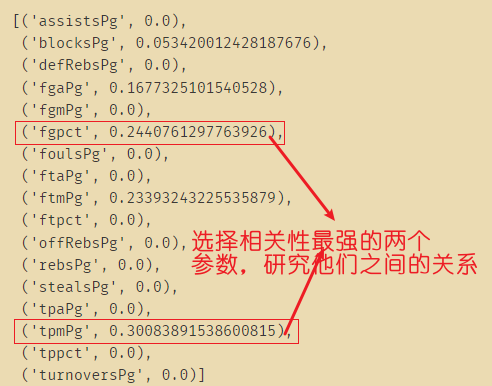
0 assistsPg 718 non-null float64
1 blocksPg 718 non-null float64
2 defRebsPg 718 non-null float64
3 fgaPg 718 non-null float64
4 fgmPg 718 non-null float64
5 fgpct 718 non-null float64
6 foulsPg 718 non-null float64
7 ftaPg 718 non-null float64
8 ftmPg 718 non-null float64
9 ftpct 718 non-null float64
10 games 718 non-null int64 # 一共打了多少场比赛
11 name 718 non-null object
12 offRebsPg 718 non-null float64
13 pointsPg 718 non-null float64
14 rebsPg 718 non-null float64
15 stealsPg 718 non-null float64
16 tpaPg 718 non-null float64 # 每场里面三分球的得分情况
17 tpmPg 718 non-null float64
18 tppct 718 non-null float64
19 turnoversPg 718 non-null float64
20 yearDisplay 718 non-null object
21 nbayear 718 non-null int64
22 y2k 718 non-null bool
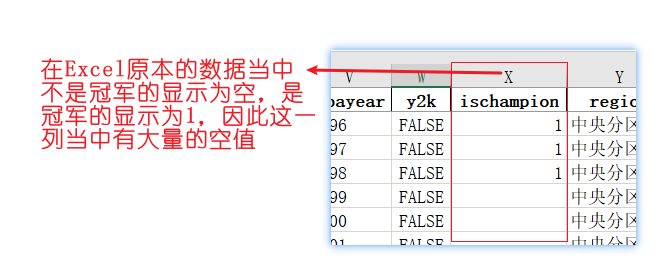
23 ischampion 24 non-null float64 # 标签,最终是否得冠军,可以看到有24个不是空值
24 region 718 non-null object
25 league 718 non-null object
26 ew 718 non-null int64
dtypes: bool(1), float64(19), int64(3), object(4)
memory usage: 146.7+ KB
这27个特征中有一些特征不重要,因此我们只选取一些较为重要的参数。根据这些参数进行分析,然后预测一些球队得冠军的概率有多高。
nbanames定义我们需要的特征:
nbanames=['assistsPg','blocksPg','defRebsPg','fgaPg','fgmPg','fgpct','foulsPg','ftaPg','ftmPg','ftpct','offRebsPg','rebsPg','stealsPg','tpaPg','tpmPg','tppct','turnoversPg','ischampion']
nbadata['ischampion'].isnull().sum()

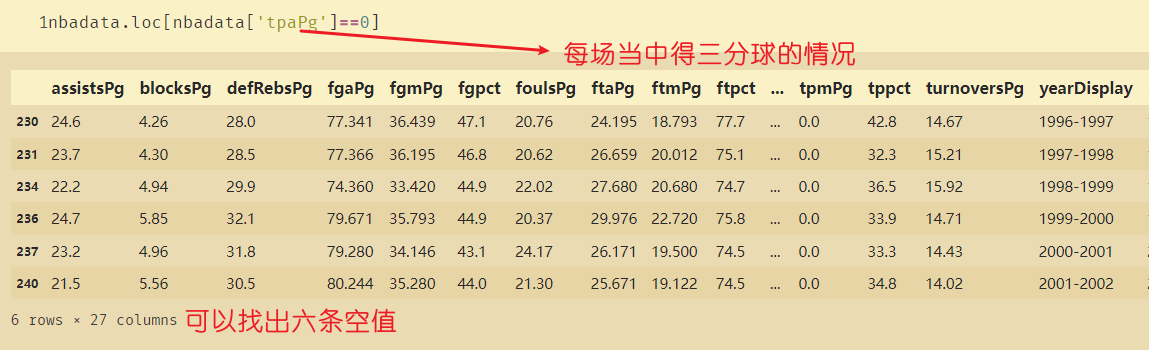
nbadata.loc[nbadata['tpaPg']==0]
有六条数据中三分球的得分为0,这可能会对最终的数据造成影响。
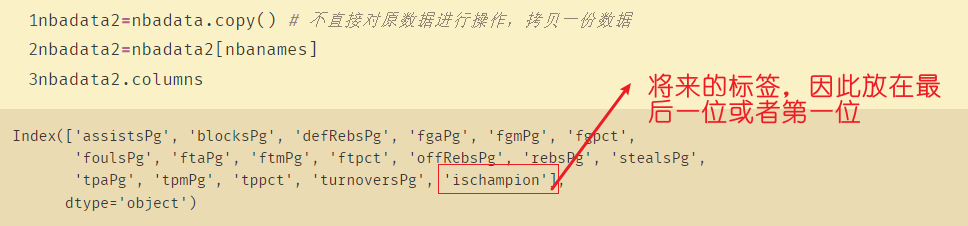
nbadata2=nbadata.copy() # 不直接对原数据进行操作,拷贝一份数据
nbadata2=nbadata2[nbanames]
nbadata2.columns
二、缺失值处理
由于'ischampion'含有694个空值,因此我们需要将空值变成0
nbadata2.loc[nbadata2['ischampion'].isnull(),'ischampion']='no'
# 将空值替换为字符‘no’
nbadata2.loc[nbadata2['ischampion']==1,'ischampion']='yes'
# 将原本数据为1的地方改成字符‘yes’
nbadata2

在对数据有了大概的处理之后,就要对数据进行无量纲化处理了。
这里不过多演示,即不对此数据进行量纲化处理。
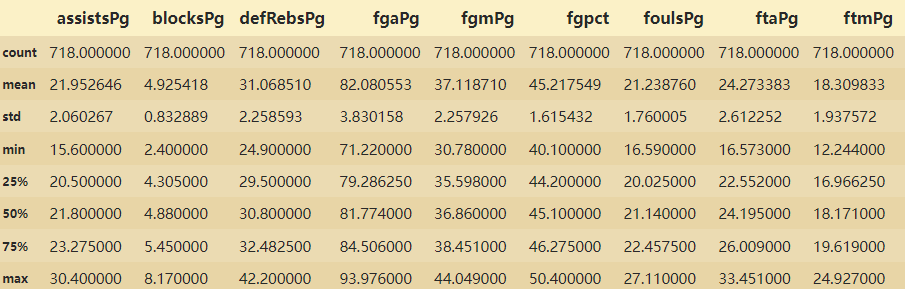
nbadata2.describe()
三、创建训练集和测试集
创建训练集和测试集(70%和30%)
# 创建训练集和测试集(70%和30%)
from sklearn.model_selection import train_test_split
x=nbadata2.iloc[:,:-1] # 这里取的没有包括第18列
x
y=nbadata2.iloc[:,-1] # 取出是否是冠军这列
y
Xtrain,Xtest,Ytrain,Ytest=train_test_split(x,y,test_size=0.3)
from sklearn.tree import DecisionTreeClassifier #导入决策树
nba_tree=DecisionTreeClassifier(criterion='entropy') # 评判标准使用信息熵
nba_tree.fit(Xtrain,Ytrain) # 拟合
answer=nba_tree.predict(x) # 进行预测
answer_array=np.array([y,answer])
answer_mat=np.matrix(answer_array).T
result=pd.DataFrame(answer_mat)
result.columns=['实际类别','预测类别']
result
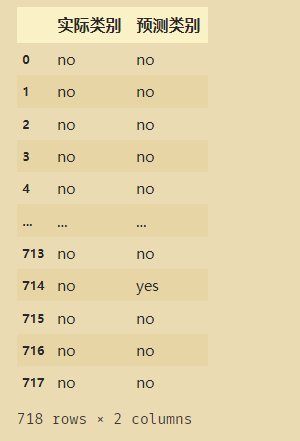
增加一列,来对比实际类别和预测类别是否相同:
result['YN']=(result['实际类别']==result['预测类别']) # 得到的结果是布尔值

result.loc[result['YN']==False]
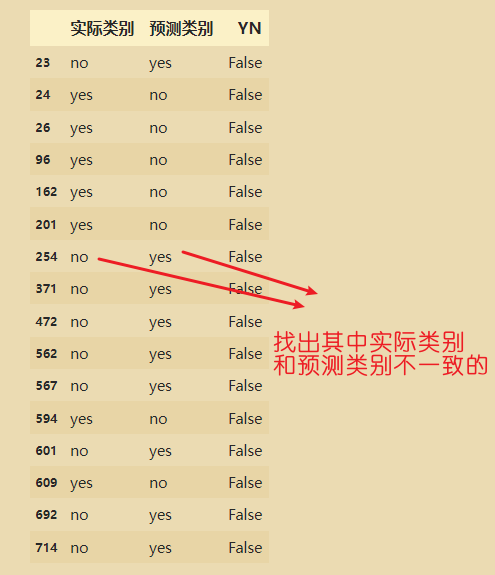
建模
# 建模
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
clf = tree.DecisionTreeClassifier(criterion="entropy") #默认是基尼系数,实例化
clf = clf.fit(Xtrain, Ytrain) #训练模型
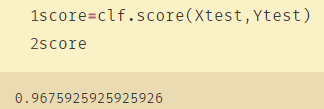
score = clf.score(Xtest, Ytest) #返回预测的准确度accuracy
score
得到的准确率:

四、绘制决策树
# 画树 NBA
nbafeatures=['assistsPg','blocksPg','defRebsPg','fgaPg','fgmPg','fgpct','foulsPg','ftaPg','ftmPg','ftpct','offRebsPg','rebsPg','stealsPg','tpaPg','tpmPg','tppct','turnoversPg']
import graphviz
dot_data=tree.export_graphviz(clf
,out_file="NBATree.dot"
,feature_names=nbafeatures
,class_names=["yes","no"]
,filled=True
,rounded=True)
graph=graphviz.Source(dot_data)
graph

这里出现None是因为之前在是否投中三分球那列有几条是0值的数据没有处理。
并且如果有一些数据类型不同的话也没法组合在一起。
解决方法:去除 ,out_file="NBATree.dot"这行代码
# 画树 NBA
nbafeatures=['assistsPg','blocksPg','defRebsPg','fgaPg','fgmPg','fgpct','foulsPg','ftaPg','ftmPg','ftpct','offRebsPg','rebsPg','stealsPg','tpaPg','tpmPg','tppct','turnoversPg']
import graphviz
dot_data=tree.export_graphviz(clf
# ,out_file="NBATree.dot"
,feature_names=nbafeatures
,class_names=["yes","no"]
,filled=True
,rounded=True)
graph=graphviz.Source(dot_data)
graph


五、探索决策树
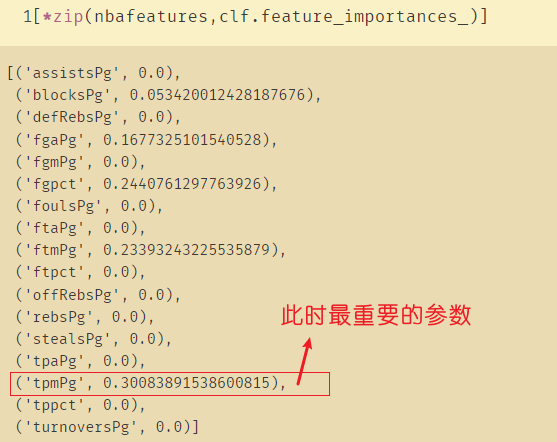
clf.feature_importances_
[*zip(nbafeatures,clf.feature_importances_)]
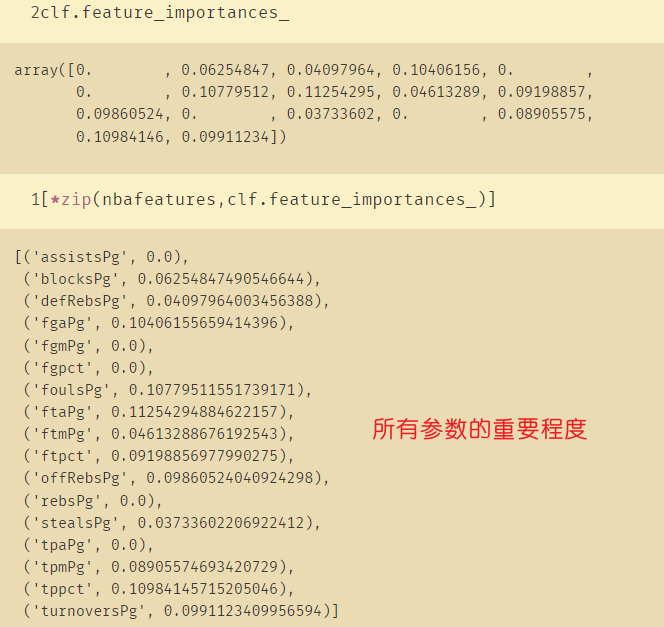
六、调参
调参即对之前的决策树进行减枝等操作:
clf=tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
,max_depth=5 # 树只留5层
)
clf=clf.fit(Xtrain,Ytrain)
dot_data=tree.export_graphviz(clf
,feature_names=nbafeatures
,class_names=["yes","no"]
,filled=True
,rounded=True)
graph=graphviz.Source(dot_data)
graph
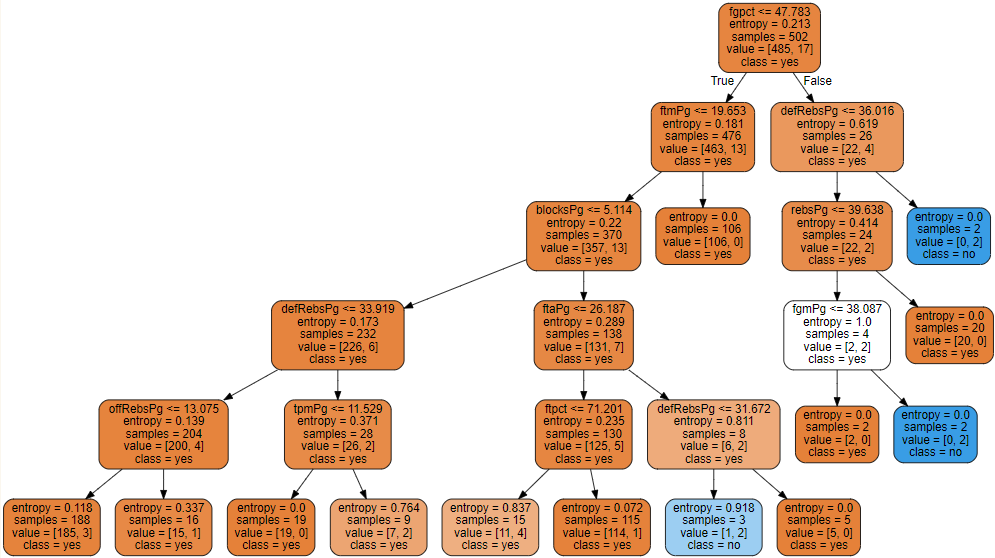
score=clf.score(Xtest,Ytest)
score
可以看到调参之后的正确率有所提高:
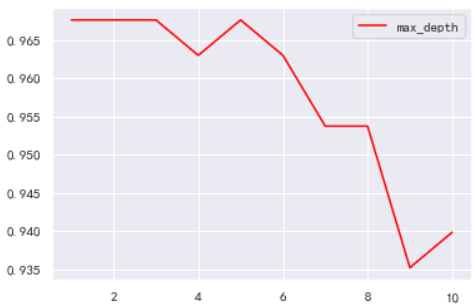
利用学习曲线观察深度是多少的时候能得到最好的
import matplotlib.pyplot as plt
test=[]
for i in range(10):
clf=tree.DecisionTreeClassifier(max_depth=i+1 # 1-10层
,criterion="entropy"
,random_state=30
,splitter="random"
)
clf=clf.fit(Xtrain,Ytrain)
score=clf.score(Xtest,Ytest) # 分别计算测试集上面的表现
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
可以看出在深度为3或者5的时候,正确率最高
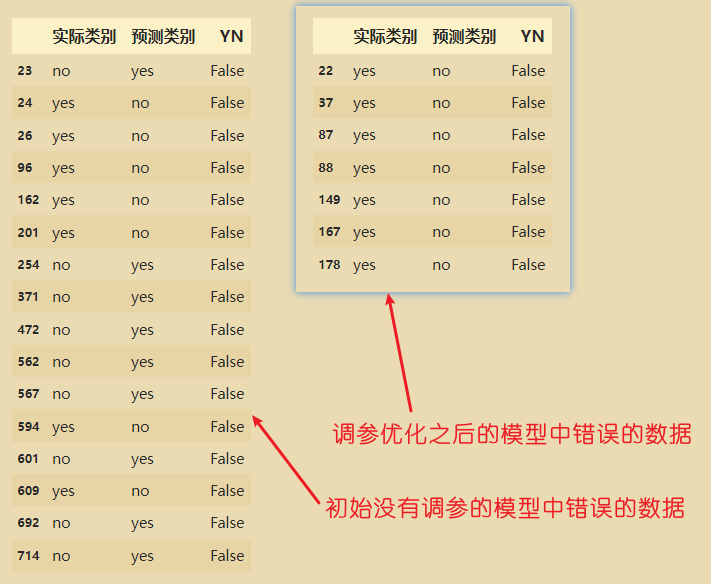
用这个调参过的模型做预测:
answer=clf.predict(Xtest)
answer_array=np.array([Ytest,answer])
answer_mat=np.matrix(answer_array).T
result2=pd.DataFrame(answer_mat)
result2.columns=['实际类别','预测类别']
result2

result2['YN']=(result2['实际类别']==result2['预测类别'])
result2.loc[result2['YN']==False]
七、决策树回归
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
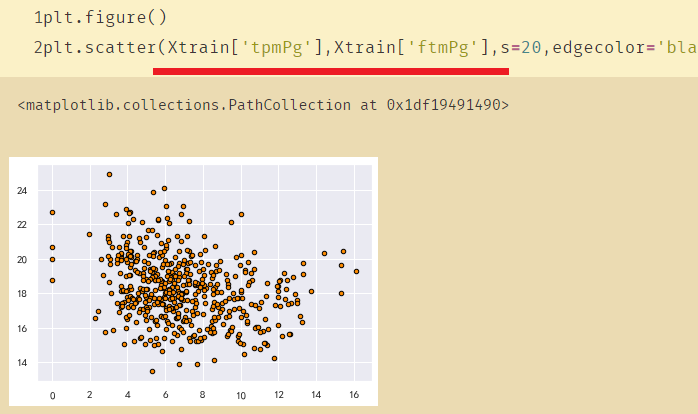
plt.figure()
plt.scatter(Xtrain['tpmPg'],Xtrain['ftmPg'],s=20,edgecolor='black',c='darkorange',label='data')
from sklearn.model_selection import train_test_split
x=nbadata2.iloc[:,:-1] # 这里取的没有包括第18列
x
y=nbadata2.iloc[:,-1] # 取出是否是冠军这列
y
Xtrain,Xtest,Ytrain,Ytest=train_test_split(x,y,test_size=0.3)
regr_1=DecisionTreeClassifier(max_depth=2)
regr_2=DecisionTreeClassifier(max_depth=5)
regr_1.fit(x[["tpmPg"]],y)
regr_2.fit(x[["tpmPg"]],y)
y_1=regr_1.predict(Xtest[["tpmPg"]])
y_2=regr_2.predict(Xtest[["tpmPg"]])
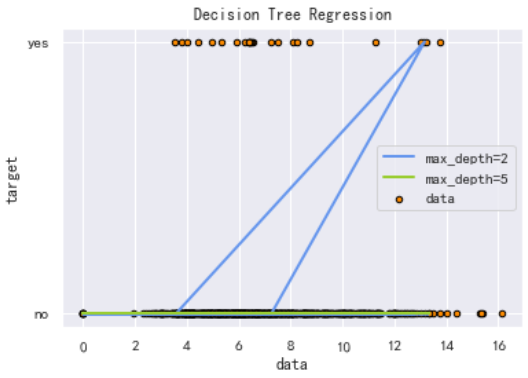
plt.figure()
plt.scatter(x[["tpmPg"]],y,s=20,edgecolor="black",c="darkorange",label="data")
plt.plot(Xtest[["tpmPg"]],y_1,color="cornflowerblue",label="max_depth=2",linewidth=2)
plt.plot(Xtest[["tpmPg"]],y_2,color="yellowgreen",label="max_depth=5",linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()















 5533
5533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











