







目录

(图片由AI生成)
0.前言
深入理解C语言中函数栈帧的创建与销毁对于掌握程序的执行流程至关重要。函数栈帧存储了函数的参数、局部变量和返回地址等关键信息,每次函数调用时创建,执行完毕后销毁。本篇博客旨在揭开栈帧管理的神秘面纱,通过深入浅出的方式讲解其在程序运行中的角色和影响,帮助读者建立对C语言更深层次的理解,为解决复杂编程问题奠定基础。
1.什么是函数栈帧
函数栈帧是编程中的一个核心概念,特别是在C语言和其他支持函数调用的编程语言中。它是程序运行时在栈内存中为每个函数调用分配的一个内存块,用于存储关于该函数调用的所有必要信息。这包括但不限于函数的局部变量、函数参数、返回地址以及有时的保存寄存器状态等。栈帧的管理是通过栈这种数据结构实现的,遵循后进先出(LIFO)的原则。
1.1栈帧的组成
一个函数栈帧主要包含以下几个部分:
- 局部变量:函数内部定义的变量,其生命周期仅限于函数执行期间。
- 函数参数:传递给函数的参数,使得函数能够接收输入值。
- 返回地址:当函数调用完成后,程序需要知道从哪里继续执行,这就是通过保存调用函数时的位置即返回地址来实现的。
- 保存的寄存器状态:某些寄存器的值可能会在函数调用期间被保存和恢复,以保持调用前后的执行环境不变。
1.2栈帧的作用
栈帧使得函数调用得以实现,支持了诸如递归调用、嵌套调用等复杂的程序结构。每当一个函数被调用时,就会在栈顶创建一个新的栈帧,所有的函数调用信息都将存储在这个栈帧中。当函数执行完毕,相应的栈帧就会被销毁,控制权返回到函数被调用的地方,程序继续执行。
1.3栈帧的管理
栈帧的管理是自动的,由编译器和运行时环境负责。程序员通常不需要直接操作栈帧,但理解其工作原理对于深入理解函数调用机制、调试程序以及优化性能等方面是非常有益的。
2.理解函数栈帧的作用
理解函数栈帧的概念和工作原理能够帮助解决和阐明编程中的许多问题和疑惑。以下是一些通过深入理解函数栈帧可以解决的典型问题:
-
函数调用的工作原理:理解函数栈帧能够帮助开发者明白函数是如何被调用的,包括参数是如何传递的,以及函数是如何返回结果的。
-
局部变量的作用域和生命周期:栈帧为每次函数调用提供了独立的空间,这解释了为什么局部变量只在其定义的函数内部可见,并且为什么它们在函数结束时会消失。
-
递归函数的执行:递归函数的每次调用都会创建一个新的栈帧,这有助于理解递归的工作原理,以及为什么递归过深可能导致栈溢出。
-
程序的执行流:通过栈帧中的返回地址,开发者可以追踪程序的执行流,这对于调试和理解复杂的函数调用链尤其重要。
-
栈溢出和内存管理问题:理解函数栈帧如何在栈上分配和释放有助于识别和避免栈溢出等内存管理问题。
-
调用约定和栈清理:不同的编程语言和编译器可能采用不同的调用约定,理解栈帧有助于明白这些约定是如何影响函数参数的传递、栈帧的清理等。
在“4.函数栈帧相关问题解答”部分,我们将针对上述问题提供更详细的解释和示例,帮助大家更深层次地理解这些概念,从而更有效地编写和调试程序。
3.解析函数栈帧的创建与销毁
3.1栈的介绍
栈是一种特殊的线性数据结构,它遵循后进先出(LIFO, Last In First Out)的原则,即最后存入的数据会被最先取出。在计算机科学中,栈被广泛用于存储程序执行期间的临时数据,如函数调用时的参数、局部变量和返回地址等。
栈的特点:
- 后进先出:栈的这一特性意味着数据的插入(推入)和删除(弹出)操作都发生在栈的同一端,即栈顶。
- 动态增长和收缩:大多数现代计算机系统中的栈区域会根据需要动态地增长和收缩,但其最大大小通常由系统预设。
- 函数调用的管理:栈在函数调用中扮演着核心角色。每当一个函数被调用时,一个新的栈帧就会被推入栈中;当函数返回时,其栈帧就会从栈中弹出。
3.2寄存器简介
寄存器是计算机处理器内部的非常小但速度极快的存储单元。它们用于存储指令、数据和地址等信息,是处理器执行指令过程中的临时存储地。在函数栈帧的创建和销毁过程中,有两个特别重要的寄存器:
- 堆栈指针(Stack Pointer, SP):它指向当前的栈顶。当向栈中推入数据时,堆栈指针减小;当从栈中弹出数据时,堆栈指针增大。
- 基址指针(Base Pointer, BP):在某些架构中,它用于指向栈帧的开始位置,有助于访问函数的参数和局部变量。
这里,我们将深入讨论几种常见的寄存器,它们在现代计算机体系结构中,特别是在x86和x86-64架构中,扮演着重要的角色:
-
RSP(Stack Pointer Register):在64位x86-64架构中,RSP是栈指针寄存器的扩展版本,用于指向当前的栈顶。它是64位的,可以指向更大的地址空间。
-
RBP(Base Pointer Register):同样在x86-64架构中,RBP是基址指针寄存器的扩展版本。它常用于指向当前函数栈帧的底部,有助于访问函数的参数和局部变量。
-
ESP(Extended Stack Pointer):在32位x86架构中,ESP用作栈指针寄存器,功能与RSP相似,但它是32位的。
-
EBP(Extended Base Pointer):在32位x86架构中,EBP作为基址指针寄存器,功能与RBP相似,但它是32位的。
-
EAX/ RAX:EAX是32位x86架构中的累加器寄存器,而RAX是其在x86-64架构中的64位版本。累加器寄存器常用于存储函数的返回值和进行算术运算。
-
EBX/ RBX:EBX是32位x86架构中的基础寄存器,RBX是其在x86-64架构中的64位版本。这些寄存器通常用于存储数据,供程序后续使用。
-
EIP/ RIP:EIP(Extended Instruction Pointer)是32位x86架构中的指令指针寄存器,RIP(Instruction Pointer Register)是其在x86-64架构中的64位版本。指令指针寄存器存储着下一条将要执行的指令的地址。
-
EDI/ RDI:在32位x86架构中,EDI是目的索引寄存器,而在x86-64架构中,RDI是其64位版本。这些寄存器常用于存储指针或索引,特别是在字符串或数组操作中。
3.3汇编指令简介
汇编语言提供了一组用于直接与计算机硬件交互的指令。这些指令使得程序员能够控制处理器执行的每一步,包括数据的移动、算术运算、控制流程等。以下是一些基本而重要的汇编指令:
-
MOV:
MOV指令用于数据传输,它将数据从一个位置移动到另一个位置,但不进行算术或逻辑运算。格式通常为MOV 目标, 源,表示将源位置的数据复制到目标位置。 -
PUSH:
PUSH指令将一个寄存器或内存位置的内容压入栈顶。这在函数调用时保存寄存器状态或传递参数时非常有用。 -
POP: 与
PUSH相对应,POP指令从栈顶弹出内容并存储到指定的寄存器或内存位置。这常用于恢复之前保存的寄存器状态。 -
SUB:
SUB指令用于算术减法。它从第一个操作数中减去第二个操作数,并将结果存储在第一个操作数中。 -
ADD:
ADD指令执行算术加法。它将两个操作数相加,并将结果存储在第一个操作数中。 -
CALL:
CALL指令执行函数调用。它将返回地址(即CALL指令之后的地址)压入栈中,并将程序控制权转移到指定的函数开始处。 -
JMP (Jump):
JMP指令使程序跳转到指定的地址执行。这在循环、条件执行等情况下非常有用。 -
RET:
RET指令从函数返回。它从栈中弹出返回地址,并将程序控制权转移回该地址。 -
LEA (Load Effective Address):
LEA指令加载有效地址。它计算内存地址表达式的值,但不实际访问内存,而是将地址值存储在寄存器中。这常用于指针运算。 -
CMP (Compare):
CMP指令比较两个操作数。它执行减法操作,但不保存结果,只更新标志寄存器以反映比较的结果,这对于后续的条件分支指令如JE(如果等于则跳转)、JNE(如果不等于则跳转)等非常关键。
这些指令构成了汇编语言编程的基础,理解它们对于深入理解计算机的操作和程序的执行至关重要。通过这些指令,开发者能够精确控制程序的每一步,实现高效和优化的代码。
3.4具体过程解析
3.4.1预备知识
在深入探讨函数栈帧的创建与销毁之前,掌握一些基础的预备知识是非常必要的。这些知识将为我们理解栈帧的管理过程提供坚实的基础:
-
函数调用与栈帧空间:每次函数被调用时,系统都会为该次调用在栈上分配一个新的内存区域,这个区域称为函数栈帧。栈帧中包含了函数的局部变量、参数、返回地址等信息。
-
栈帧的寄存器管理:函数栈帧的管理依赖于两个关键的寄存器——ESP(Stack Pointer)和EBP(Base Pointer)。在32位架构中,ESP寄存器用于追踪栈顶的位置,即最新压入栈的元素位置;EBP寄存器则用于标记当前函数栈帧的底部,使得函数内部及其调用者能够有效地访问栈帧中的数据。
-
跨编译器的实现:虽然不同的编译器和不同的环境(如x86与x86-64)可能在细节上有所差异,但函数栈帧的创建与销毁的基本原理和过程在本质上是相似的。本次演示将基于Visual Studio 2022的x86环境,这是一个常见的开发环境,其对栈帧的处理方式能够很好地代表大多数现代编译器的行为。
一张插图可以较好地反映运行时堆栈的使用:(图源网络,侵删)
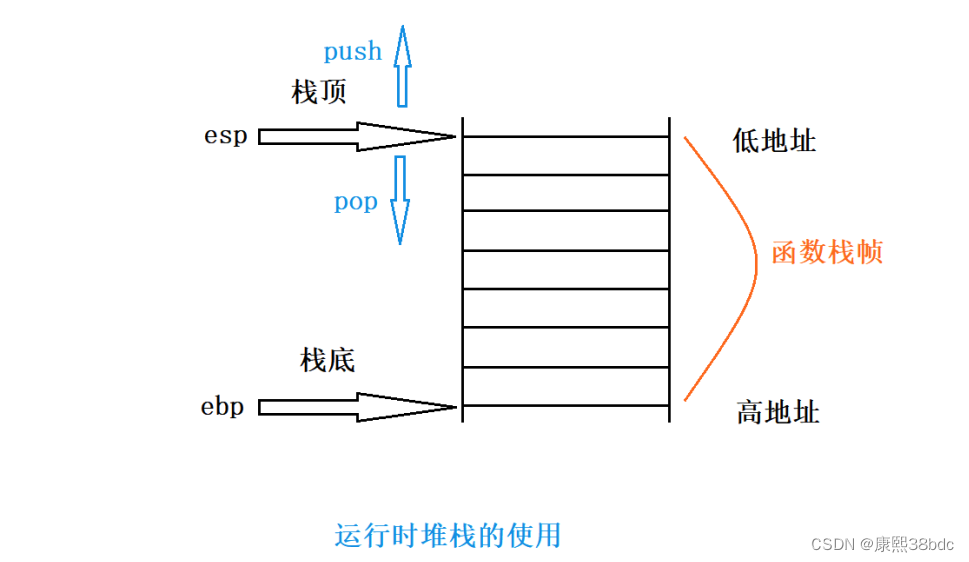
3.4.2函数的调用堆栈
为方便起见,我们的测试代码如下:
#include <stdio.h>
int Add(int x, int y)
{
int z = 0;
z = x + y;
return z;
}
int main()
{
int a = 10;
int b = 20;
int c = 0;
c = Add(a, b);
printf("%d\n", c);
return 0;
}在VS2022中,我们进入调试状态后,点击“调试->窗口->调用堆栈”:

在“调用堆栈”栏中,我们再点击“显示外部代码”:
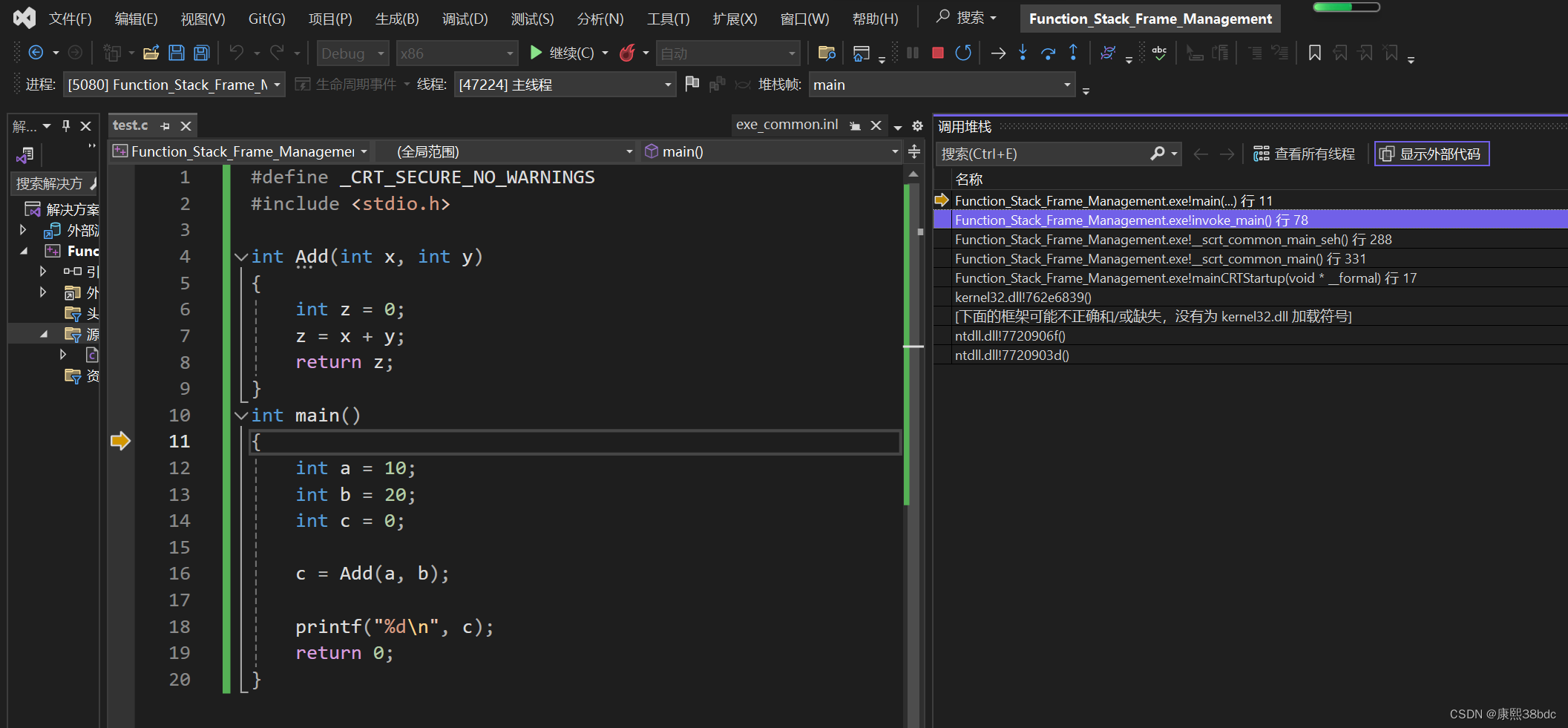
在这里,我们可以观察到,main函数被调用前,由invoke_main 函数来调用main函数。为简化起见,在invoke_main函数之前的函数调用我们就暂时不考虑了。
我们可以确定,invoke_main 函数有自己的栈帧,main函数和Add函数也会维护自己的栈帧,而每个函数栈帧都有自己的 ebp 和 esp 来维护栈帧空间。
下面,我们从main函数的栈帧创建开始讲解。
3.4.3转到反汇编
在开始调试后,点击“调试->窗口->反汇编”,我们即可看到C语言代码以及后附的汇编指令。
反汇编截图如下(部分):
 以下是反汇编的代码:(main部分及Add部分)
以下是反汇编的代码:(main部分及Add部分)
//main函数部分
int main()
{
00CA18D0 push ebp
00CA18D1 mov ebp,esp
00CA18D3 sub esp,0E4h
00CA18D9 push ebx
00CA18DA push esi
00CA18DB push edi
00CA18DC lea edi,[ebp-24h]
00CA18DF mov ecx,9
00CA18E4 mov eax,0CCCCCCCCh
00CA18E9 rep stos dword ptr es:[edi]
00CA18EB mov ecx,0CAC008h
00CA18F0 call 00CA132F
int a = 10;
00CA18F5 mov dword ptr [ebp-8],0Ah
int b = 20;
00CA18FC mov dword ptr [ebp-14h],14h
int c = 0;
00CA1903 mov dword ptr [ebp-20h],0
c = Add(a, b);
00CA190A mov eax,dword ptr [ebp-14h]
00CA190D push eax
00CA190E mov ecx,dword ptr [ebp-8]
00CA1911 push ecx
00CA1912 call 00CA10B9
00CA1917 add esp,8
00CA191A mov dword ptr [ebp-20h],eax
printf("%d\n", c);
00CA191D mov eax,dword ptr [ebp-20h]
00CA1920 push eax
00CA1921 push 0CA7B30h
00CA1926 call 00CA10D7
00CA192B add esp,8
return 0;
00CA192E xor eax,eax
}
00CA1930 pop edi
00CA1931 pop esi
00CA1932 pop ebx
00CA1933 add esp,0E4h
00CA1939 cmp ebp,esp
00CA193B call 00CA1253
00CA1940 mov esp,ebp
00CA1942 pop ebp
00CA1943 ret
//Add函数部分
int Add(int x, int y)
{
00CA1790 push ebp
00CA1791 mov ebp,esp
00CA1793 sub esp,0CCh
00CA1799 push ebx
00CA179A push esi
00CA179B push edi
00CA179C lea edi,[ebp-0Ch]
00CA179F mov ecx,3
00CA17A4 mov eax,0CCCCCCCCh
00CA17A9 rep stos dword ptr es:[edi]
00CA17AB mov ecx,0CAC008h
00CA17B0 call 00CA132F
int z = 0;
00CA17B5 mov dword ptr [ebp-8],0
z = x + y;
00CA17BC mov eax,dword ptr [ebp+8]
00CA17BF add eax,dword ptr [ebp+0Ch]
00CA17C2 mov dword ptr [ebp-8],eax
return z;
00CA17C5 mov eax,dword ptr [ebp-8]
}
00CA17C8 pop edi
00CA17C9 pop esi
00CA17CA pop ebx
00CA17CB add esp,0CCh
00CA17D1 cmp ebp,esp
00CA17D3 call 00CA1253
00CA17D8 mov esp,ebp
00CA17DA pop ebp
00CA17DB ret 3.4.4函数栈帧的创建
为了深入理解函数栈帧的创建和销毁过程,我们将结合main函数和Add函数的反汇编代码进行逐行解析。这将帮助我们明白在实际函数调用和返回时栈帧是如何被操作的。
main函数中栈帧的创建
00CA18D0 push ebp- 将当前的基址指针(
ebp)的值压入栈中。这是为了保存上一个函数栈帧的基址指针。
00CA18D1 mov ebp,esp- 将栈顶指针(
esp)的值复制到基址指针(ebp)。这样做是为了设置当前函数栈帧的基点,即将ebp指向当前栈帧的底部。
00CA18D3 sub esp,0E4h- 通过将
esp减去一个固定值(在这个例子中是0E4h),为局部变量和可能的其他数据(如调用者保存的寄存器)分配空间。
00CA18D9 push ebx
00CA18DA push esi
00CA18DB push edi- 将
ebx、esi和edi寄存器的值压入栈中。这是因为这些寄存器可能会在函数内部被使用,按照约定,当前函数需要在修改前保存这些值,并在函数返回前恢复它们。
main函数调用Add函数
当main函数准备调用Add函数时,它需要传递参数并准备好新的栈帧:
00CA190A mov eax, dword ptr [ebp-14h]
00CA190D push eax
00CA190E mov ecx, dword ptr [ebp-8]
00CA1911 push ecx
- 将
Add函数的参数a和b推入栈中。首先推入的是b,然后是a,因为C语言默认使用从右到左的参数推送顺序。
00CA1912 call 00CA10B9- 调用
Add函数。call指令自动将返回地址(即下一条指令的地址)压入栈中,并跳转到Add函数的起始地址。
Add函数中栈帧的创建
00CA1790 push ebp
00CA1791 mov ebp, esp
00CA1793 sub esp, 0CCh
Add函数的开始部分与main函数类似:保存上一个栈帧的ebp,设置新的栈帧基点,为局部变量分配空间。
3.4.5函数栈帧的销毁
Add函数返回
00CA17C5 mov eax, dword ptr [ebp-8]
- 将返回值(
z的值)存入eax,因为按照约定,函数的返回值通常存放在eax寄存器中。
00CA17CB add esp, 0CCh
00CA17D1 cmp ebp, esp
00CA17D3 call 00CA1253
00CA17D8 mov esp, ebp
00CA17DA pop ebp
00CA17DB ret
- 销毁
Add函数的栈帧:释放局部变量空间,恢复ebp的值,然后通过ret指令返回到调用点(main函数中call之后的地址)。
main函数继续执行并返回
00CA1917 add esp, 8
main函数从Add函数返回后,清理传递给Add函数的参数所占用的栈空间。
最后,main函数完成其余操作后,会通过与函数开始时相反的操作销毁自己的栈帧并返回:
00CA1930 pop edi
00CA1931 pop esi
00CA1932 pop ebx
00CA1933 add esp, 0E4h
00CA1939 cmp ebp, esp
00CA193B call 00CA1253
00CA1940 mov esp, ebp
00CA1942 pop ebp
00
- 恢复寄存器值,释放局部变量空间,恢复
ebp的值,最后通过ret指令结束函数,返回到操作系统。
4.函数栈帧相关问题解答
在理解了函数栈帧的概念和操作之后,我们现在可以解答一些常见的与函数栈帧相关的问题,这些问题通常在深入学习编程时出现。
1. 函数调用的工作原理
函数调用的工作原理基于栈帧的创建和销毁。当一个函数被调用时,为它创建一个新的栈帧,其中包含了函数的参数、局部变量和返回地址。函数执行完成后,栈帧被销毁,控制权返回到调用者,这个过程通过call和ret汇编指令以及栈操作实现。
2. 局部变量的作用域和生命周期
局部变量存储在函数的栈帧中,它们的作用域限定在函数内部。当函数调用结束,栈帧被销毁,其中的局部变量也随之被销毁。这解释了局部变量为什么不能在函数外部访问,以及为什么它们在每次函数调用时都是“新的”。
3. 递归函数的执行
递归函数的每次调用都会创建一个新的栈帧,为每个调用实例提供独立的局部变量和参数空间。这使得递归函数能够实现复杂的算法,如快速排序、树的遍历等。但是,过深的递归可能导致栈溢出,因为每个栈帧都占用一定的内存空间。
4. 程序的执行流
通过栈帧中的返回地址,可以追踪程序的执行流。调试器就是利用这一点来帮助开发者理解程序的执行路径,尤其是在复杂的函数调用和递归调用中。
5. 栈溢出和内存管理问题
栈溢出通常是由于无限递归或过大的局部变量分配导致的。理解栈帧的创建和销毁机制可以帮助开发者设计更高效的函数,避免不必要的内存占用,从而减少栈溢出的风险。
6. 调用约定和栈清理
不同的编程语言和编译器可能使用不同的调用约定,这影响了参数如何传递、栈帧如何设置和清理等。理解函数栈帧的操作有助于理解这些约定的差异,以及如何在不同的编程环境中编写兼容的代码。
5.小结
本篇博客深入探讨了函数栈帧的创建与销毁过程,揭示了C语言中函数调用的底层工作原理。通过逐行解析反汇编代码,我们了解到每次函数调用时栈帧的形成、局部变量和参数的处理方式,以及函数返回时栈帧的销毁。这些知识不仅对于理解函数调用的工作原理至关重要,也为深入掌握编程语言的内存管理、递归调用、程序执行流跟踪等高级概念提供了坚实的基础。














 6955
6955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









