






在前三章中,我们讨论了单变量和多变量时间序列预测的经典方法。现在我们介绍因果关系的概念及其对时间序列分析的一般影响。我们还描述了上一章讨论的线性 VAR 模型的检验。
Notations
如果如果 A t A_t At 是一个静态随机过程,让 A ˉ t \bar A_t Aˉt代表过去值 A t − j , j = 1 , 2 , ⋯ , ∞ A_{t-j}, j=1,2,\cdots,\infty At−j,j=1,2,⋯,∞ 的集合,和 A ‾ ‾ t \overline{\overline{A}}_{t} At代表过去和现在值的集合 A t − j , j = 0 , 1 , … , ∞ . A_{t-j}, j=0,1,\ldots,\infty. At−j,j=0,1,…,∞.. 此外,让 A ‾ ( k ) \overline{A}(k) A(k)表示集合 A t − j , j = k , k + 1 , ⋯ , ∞ A_{t-j}, j=k,k+1,\cdots,\infty At−j,j=k,k+1,⋯,∞。
用 P t ( A ∣ B ) P_{t}(A|B) Pt(A∣B)表示使用 B t B_{t} Bt的值集对 A t A_{t} At进行的最优、无偏、最小二乘预测。 因此,举例来说, P t ( X ∣ X ‾ ) P_t(X|\overline{X}) Pt(X∣X) 将是仅使用过去的 X t X_{t} Xt对 X t X_{t} Xt的最优预测。 预测误差序列将以 ε t ( A ∣ B ) = A t − P t ( A ∣ B ) \varepsilon_t(A|B)=A_t-P_t(A|B) εt(A∣B)=At−Pt(A∣B)表示。 设 σ 2 ( A ∣ B ) \sigma^{2}(A|B) σ2(A∣B)为 ε t ( A ∣ B ) \varepsilon_{t}(A|B) εt(A∣B)的方差。
让 𝑈 𝑡 𝑈_𝑡 Ut 成为全局中自时间 𝑡 − 1 𝑡-1 t−1 起积累的所有信息,让 𝑈 𝑡 − 𝑌 𝑡 𝑈_𝑡-𝑌_𝑡 Ut−Yt 表示除指定序列 𝑌 𝑡 𝑌_𝑡 Yt 之外的所有信息,指定序列 𝑌 𝑡 𝑌_𝑡 Yt 是与 𝑋 𝑡 𝑋_𝑡 Xt 不同的另一个静态时间序列。
Definitions
Causality
如果 σ 2 ( X ∣ U ) < σ 2 ( X ∣ U − Y ‾ ) \sigma^2(X|U)<\sigma^2(X|\overline{U-Y}) σ2(X∣U)<σ2(X∣U−Y),我们说 Y Y Y导致 X X X,表示为 Y t ⟹ X t Y_t\implies X_t Yt⟹Xt,如果我们利用所有可用信息预测 𝑋 𝑡 𝑋_𝑡 Xt,比利用 𝑌 𝑡 𝑌_𝑡 Yt 以外的信息预测 𝑋 𝑡 𝑋_𝑡 Xt 更准确,我们就可以说 𝑌 𝑡 𝑌_𝑡 Yt 导致了 X 𝑡 X_𝑡 Xt。\
Feedback
如果 σ 2 ( X ∣ U ‾ ) < σ 2 ( X ∣ U − Y ‾ ) \sigma^2(X|\overline{U})<\sigma^2(X|\overline{U-Y}) σ2(X∣U)<σ2(X∣U−Y)和 σ 2 ( Y ∣ U ‾ ) < σ 2 ( Y ∣ U − X ‾ ) \sigma^2(Y|\overline{U})<\sigma^2(Y|\overline{U-X}) σ2(Y∣U)<σ2(Y∣U−X),我们说反馈正在发生,用 Y t ⟺ X t Y_t\iff X_t Yt⟺Xt表示,即当 𝑋 𝑡 𝑋_𝑡 Xt 导致 𝑌 t 𝑌_t Yt 并且 𝑌 𝑡 𝑌_𝑡 Yt 也导致 𝑋 𝑡 𝑋_𝑡 Xt 时,反馈就发生了。
Causality Lag
如果 Y t ⟹ X t Y_{t}\implies X_{t} Yt⟹Xt,我们定义(整数)因果滞后 𝑚 𝑚 m为 𝑘 𝑘 k 的最小值,使得 σ 2 ( X ∣ U − Y ( k ) ) < σ 2 ( X ∣ U − Y ( k + 1 ) ) \sigma^2(X|U-Y(k))<\sigma^2(X|U-Y(k+1)) σ2(X∣U−Y(k))<σ2(X∣U−Y(k+1))。 因此,知道 Y t − j , j = 0 , 1 , … , m − 1 Y_{t-j}, j=0,1,\ldots,m-1 Yt−j,j=0,1,…,m−1的值对于改进 𝑋 𝑡 𝑋_𝑡 Xt的预测毫无帮助。
Assumptions
- X t X_t Xt和 Y t Y_t Yt是平稳的
- P t ( A ∣ B ) P_t(A|B) Pt(A∣B)已经优化
Testing for Granger Causality
在本节中,我们将首先为示例建立 VAR 模型。 除了上一章概述的步骤外,我们还将调用内置的格兰杰因果检验函数并对其进行相应配置。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pandas.plotting import lag_plot
from statsmodels.tsa.vector_ar.var_model import VAR
from statsmodels.tsa.stattools import adfuller, kpss, grangercausalitytests
import warnings
warnings.filterwarnings("ignore")
Example 1: Ipo Dam Dataset
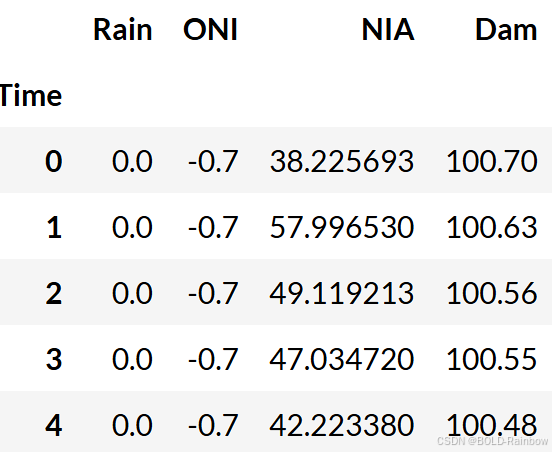
我们将在本例中使用 Ipo 数据集。 该数据集包含以下变量的每日测量值:降雨量(单位:毫米)、海洋尼诺指数(ONI)、NIA 释放流量(单位:立方米/秒)和大坝水位(单位:米)。
ipo_df = pd.read_csv('../data/Ipo_dataset.csv', index_col='Time');
ipo_df = ipo_df.dropna()
ipo_df.head()
ipo_df = pd.read_csv('../data/Ipo_dataset.csv', index_col='Time');
ipo_df = ipo_df.dropna()
ipo_df.head()
Causality between Rainfall and Ipo Dam Water Level
在本例中,我们将重点关注雨量和水坝时间序列。
data_df = ipo_df.drop(['ONI', 'NIA'], axis=1)
data_df.head()
0,0.0,NaN
1,0.0,-0.07
2,0.0,-0.07
3,0.0,-0.01
4,0.0,-0.07
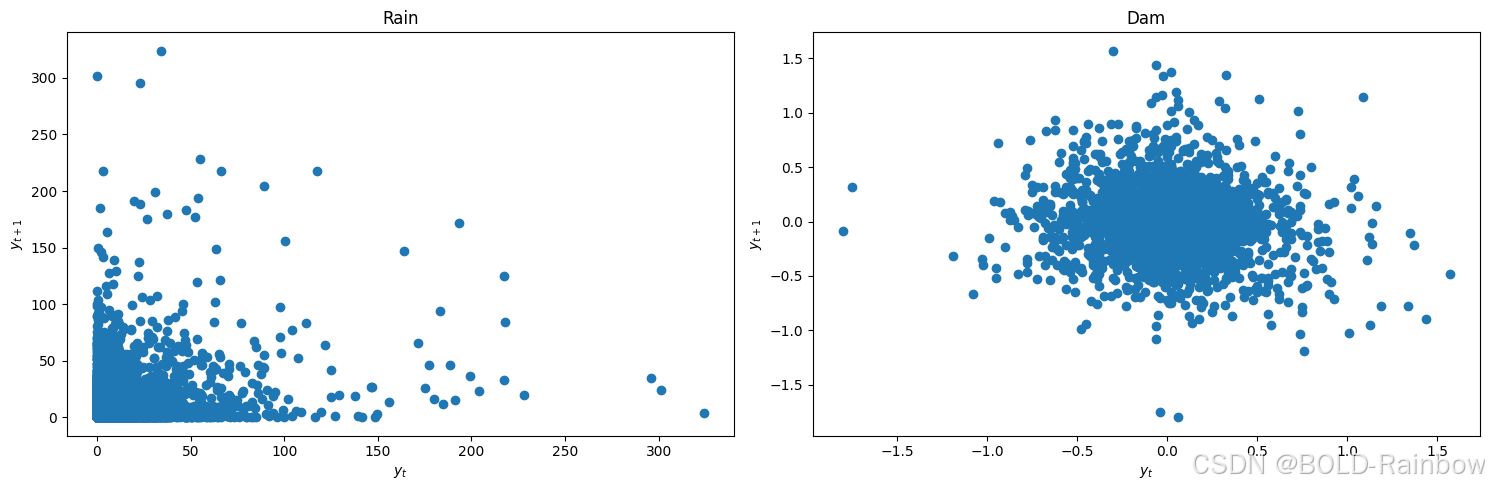
我们可以通过滞后图来快速检查静止性。
def lag_plots(data_df):
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
lag_plot(data_df[data_df.columns[0]], ax=ax1)
ax1.set_title(data_df.columns[0]);
lag_plot(data_df[data_df.columns[1]], ax=ax2)
ax2.set_title(data_df.columns[1]);
ax1.set_ylabel('$y_{t+1}$');
ax1.set_xlabel('$y_t$');
ax2.set_ylabel('$y_{t+1}$');
ax2.set_xlabel('$y_t$');
plt.tight_layout()
lag_plots(data_df)
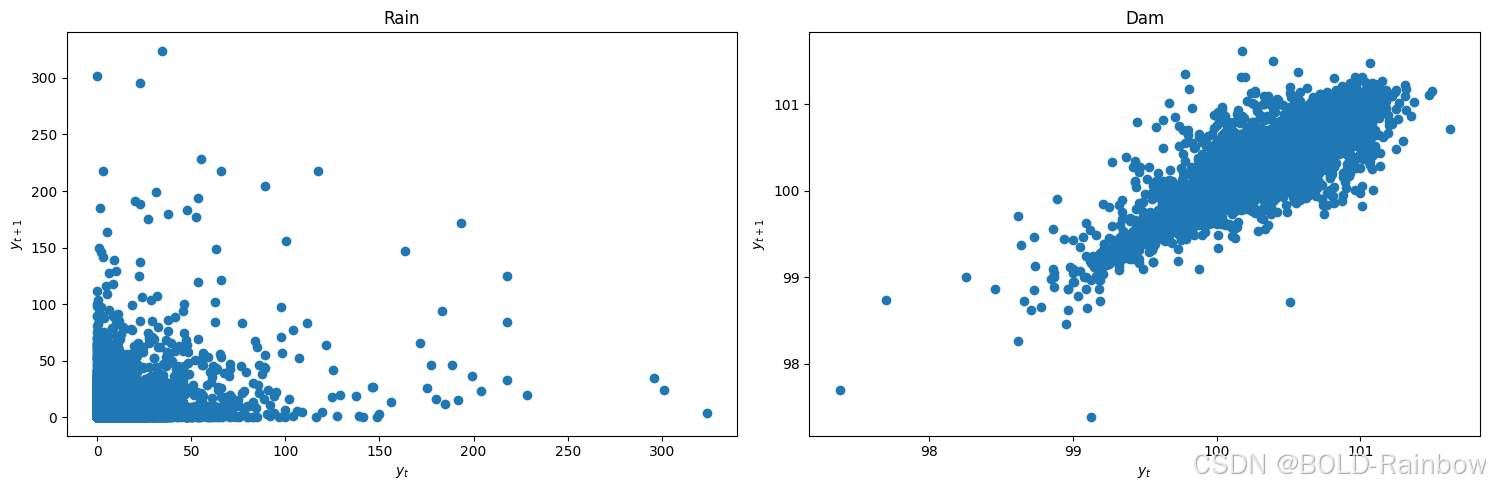
Result:Dam 数据看上去不是平稳的. Rainfall滞后图没有定论。
我们使用上一章讨论过的 KPSS 和 ADF 检验来最终检验是否存在静止性。
def kpss_test(data_df):
test_stat, p_val = [], []
cv_1pct, cv_2p5pct, cv_5pct, cv_10pct = [], [], [], []
for c in data_df.columns:
kpss_res = kpss(data_df[c].dropna(), regression='ct')
test_stat.append(kpss_res[0])
p_val.append(kpss_res[1])
cv_1pct.append(kpss_res[3]['1%'])
cv_2p5pct.append(kpss_res[3]['2.5%'])
cv_5pct.append(kpss_res[3]['5%'])
cv_10pct.append(kpss_res[3]['10%'])
kpss_res_df = pd.DataFrame({'Test statistic': test_stat,
'p-value': p_val,
'Critical value - 1%': cv_1pct,
'Critical value - 2.5%': cv_2p5pct,
'Critical value - 5%': cv_5pct,
'Critical value - 10%': cv_10pct},
index=data_df.columns).T
kpss_res_df = kpss_res_df.round(4)
return kpss_res_df
kpss_test(data_df)
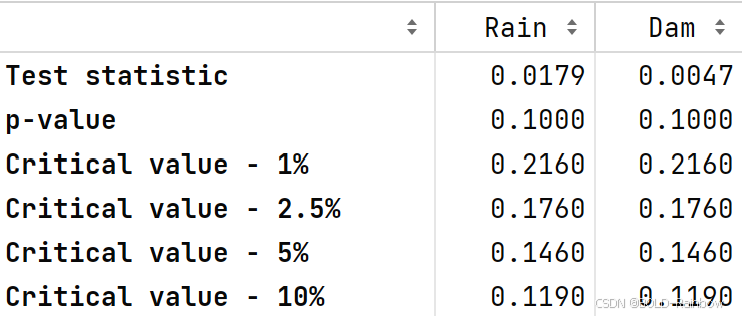
结果 Rain数据是平稳的,而水坝不是。
def adf_test(data_df):
test_stat, p_val = [], []
cv_1pct, cv_5pct, cv_10pct = [], [], []
for c in data_df.columns:
adf_res = adfuller(data_df[c].dropna())
test_stat.append(adf_res[0])
p_val.append(adf_res[1])
cv_1pct.append(adf_res[4]['1%'])
cv_5pct.append(adf_res[4]['5%'])
cv_10pct.append(adf_res[4]['10%'])
adf_res_df = pd.DataFrame({'Test statistic': test_stat,
'p-value': p_val,
'Critical value - 1%': cv_1pct,
'Critical value - 5%': cv_5pct,
'Critical value - 10%': cv_10pct},
index=data_df.columns).T
adf_res_df = adf_res_df.round(4)
return adf_res_df
adf_test(data_df)
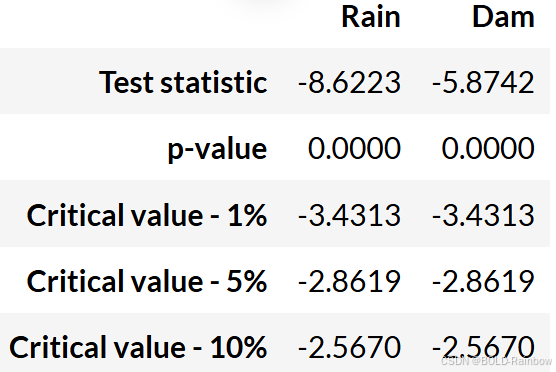
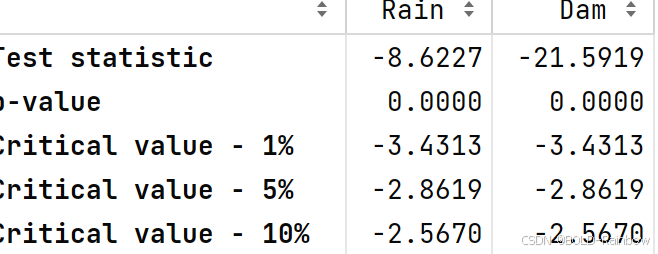
结果 两个数据都是静态的。
由于滞后图和 KPSS 检验都表明 Dam 不是静态的,因此我们在建立 VAR 模型之前首先采用差分法。
data_df['Dam'] = data_df['Dam'] - data_df['Dam'].shift(1)
data_df = data_df.dropna()
我们再次查看滞后图,并应用 KPSS 和 ADF 检验。
lag_plots(data_df)
kpss_test(data_df)
adf_test(data_df)
Result: 三者都确凿无疑地表明,这两个数据都不是静止的。
接下来,我们将数据分成 VAR 模型的训练集和测试集。
def splitter(data_df):
end = round(len(data_df)*.8)
train_df = data_df[:end]
test_df = data_df[end:]
return train_df, test_df
train_df, test_df = splitter(data_df)
然后,我们通过计算不同的多元信息标准(AIC、BIC、HQIC)和 FPE 来选择 VAR 序列 𝑝 𝑝 p。
def select_p(train_df):
aic, bic, fpe, hqic = [], [], [], []
model = VAR(train_df)
p = np.arange(1,60)
for i in p:
result = model.fit(i)
aic.append(result.aic)
bic.append(result.bic)
fpe.append(result.fpe)
hqic.append(result.hqic)
lags_metrics_df = pd.DataFrame({'AIC': aic,
'BIC': bic,
'HQIC': hqic,
'FPE': fpe},
index=p)
fig, ax = plt.subplots(1, 4, figsize=(15, 3), sharex=True)
lags_metrics_df.plot(subplots=True, ax=ax, marker='o')
plt.tight_layout()
print(lags_metrics_df.idxmin(axis=0))
train_df, test_df = splitter(data_df)
AIC 21
BIC 8
HQIC 11
FPE 21
dtype: int64

Result: 我们看到,BIC 在
𝑝
=
8
𝑝=8
p=8 时的值最低,而 HQIC 在
𝑝
=
11
𝑝=11
p=11 时的值最低。 虽然 AIC 和 FPE 在
𝑝
=
21
𝑝=21
p=21 时的值都最低,但它们的曲线图也呈现出一个弯头。 因此,我们可以选择 8 个滞后期(也是为了提高计算效率)。
现在,我们用选定的阶次拟合 VAR 模型。
p = 8
model = VAR(train_df)
var_model = model.fit(p)
最后,我们可以检验变量的格兰杰因果关系
def granger_causation_matrix(data, variables, p, test = 'ssr_chi2test', verbose=False):
"""Check Granger Causality of all possible combinations of the time series.
The rows are the response variables, columns are predictors. The values in the table
are the P-Values. P-Values lesser than the significance level (0.05), implies
the Null Hypothesis that the coefficients of the corresponding past values is
zero, that is, the X does not cause Y can be rejected.
data : pandas dataframe containing the time series variables
variables : list containing names of the time series variables.
"""
df = pd.DataFrame(np.zeros((len(variables), len(variables))), columns=variables, index=variables)
for c in df.columns:
for r in df.index:
test_result = grangercausalitytests(data[[r, c]], p, verbose=False)
p_values = [round(test_result[i+1][0][test][1],4) for i in range(p)]
if verbose: print(f'Y = {r}, X = {c}, P Values = {p_values}')
min_p_value = np.min(p_values)
df.loc[r, c] = min_p_value
df.columns = [var + '_x' for var in variables]
df.index = [var + '_y' for var in variables]
return df
granger_causation_matrix(train_df, train_df.columns, p)
Rain_x Dam_x
Rain_y 1.0 0.2169
Dam_y 0.0 1.0000
召回: 如果给定的 p 值小于显著性水平 (0.05),则相应的 X 序列(column)会导致 Y(row)。
结果: 在这个特定的例子中,我们可以说降雨格兰杰效应导致了大坝水位的变化。 这意味着降雨数据会改善大坝水位预测性能的变化。
另一方面,大坝水位的变化并不格兰杰引起降雨。 这意味着大坝水位数据的变化并不能提高降雨预测性能。
Causality between NIA Release Flow and Ipo Dam Water Level
在下一个示例中,我们将重点关注 NIA 和 Dam 时间序列。
data_df = ipo_df.drop(['ONI', 'Rain'], axis=1)
data_df.head()
NIA Dam
Time
0 38.225693 100.70
1 57.996530 100.63
2 49.119213 100.56
3 47.034720 100.55
4 42.223380 100.48
我们首先通过观察滞后图并应用 KPSS 和 ADF 检验来检查是否存在静止性。
lag_plots(data_df)
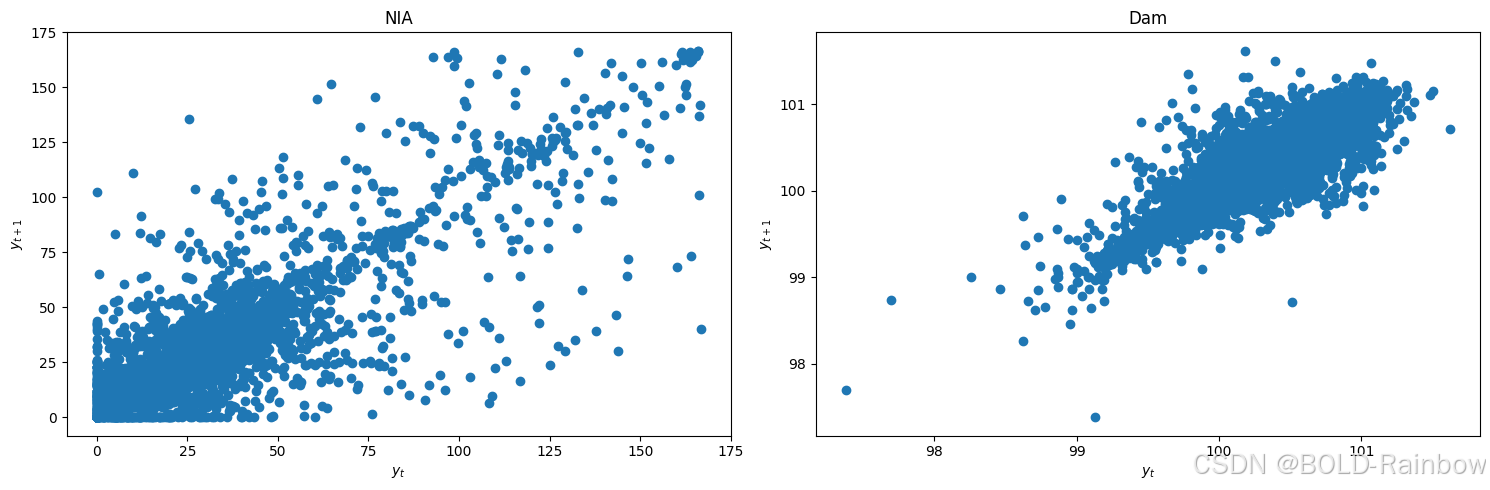
kpss_test(data_df)
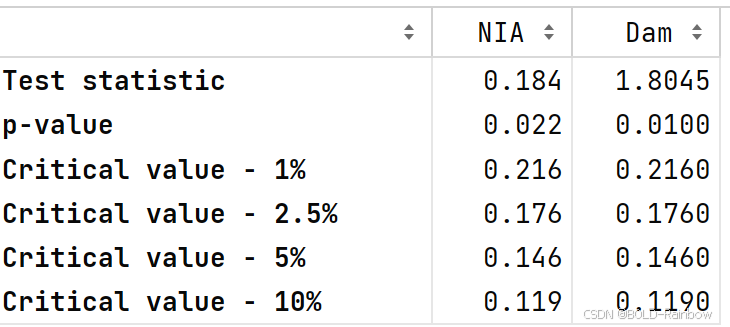
adf_test(data_df)
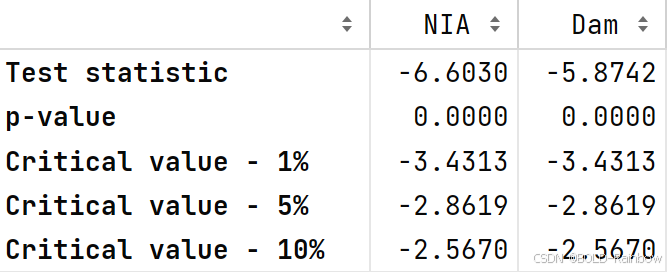
结果 这三个结果都确凿地表明,这两个数据都不是静止的。
我们采用差分法并重新检查静态性。
data_df['NIA'] = data_df['NIA'] - data_df['NIA'].shift(1)
data_df['Dam'] = data_df['Dam'] - data_df['Dam'].shift(1)
data_df = data_df.dropna()
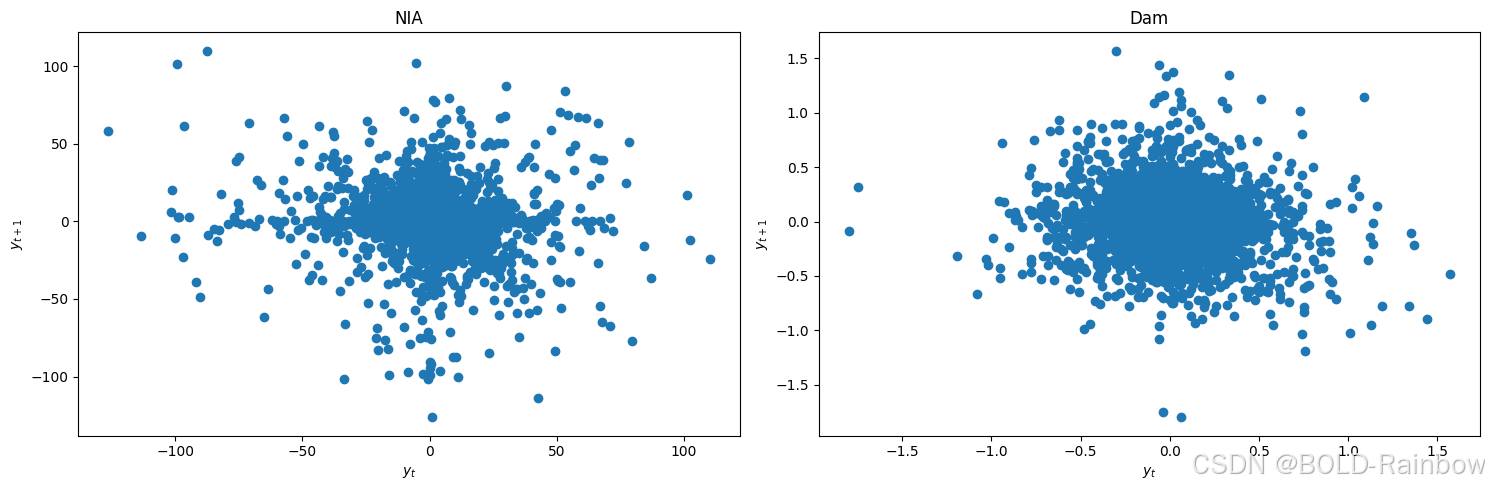
lag_plots(data_df)
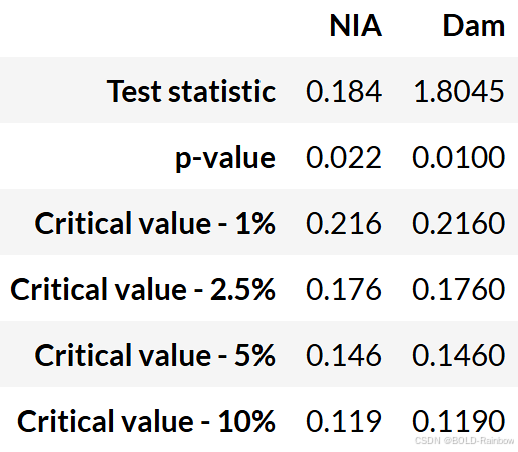
kpss_test(data_df)
adf_test(data_df)
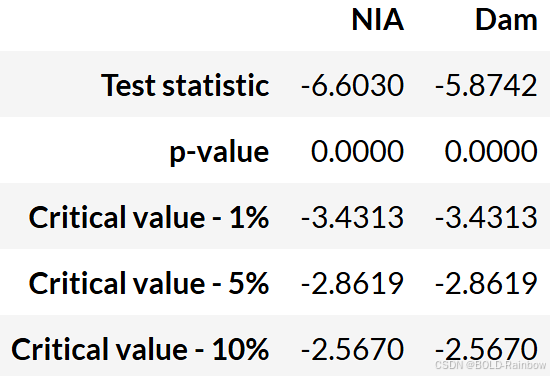
结果 三个结论都一致认为两个数据都是平稳的
接下来,我们分割数据并选择滞后阶数
𝑝
𝑝
p。
train_df, test_df = splitter(data_df)
select_p(train_df)
AIC 27
BIC 8
HQIC 13
FPE 27
dtype: int64

我们选择
𝑝
=
8
𝑝=8
p=8,理由与前述相同。 最后,我们拟合 VAR 模型并检验格兰杰因果关系。
p = 8
model = VAR(train_df)
var_model = model.fit(p)
granger_causation_matrix(train_df, train_df.columns, p)
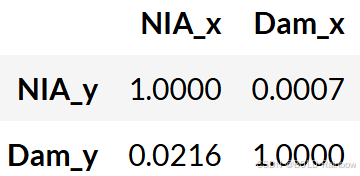
Recall 如果给定的 p 值小于显著性水平 (0.05),则相应的 X 序列(column)会导致 Y(row)。
结果 在这个特定的例子中,我们可以说 NIA 释放流量的变化会格兰杰作用于大坝水位的变化。 反之,大坝水位的变化也会格兰杰作用于 NIA 下泄流量的变化。 这就是上文提到的反馈的一个例子。 这意味着 NIA 释放流量数据可改善大坝水位预测性能的变化,而大坝水位数据也可改善 NIA 释放流量预测性能的变化。
Example 2: Causality for La Mesa Dam
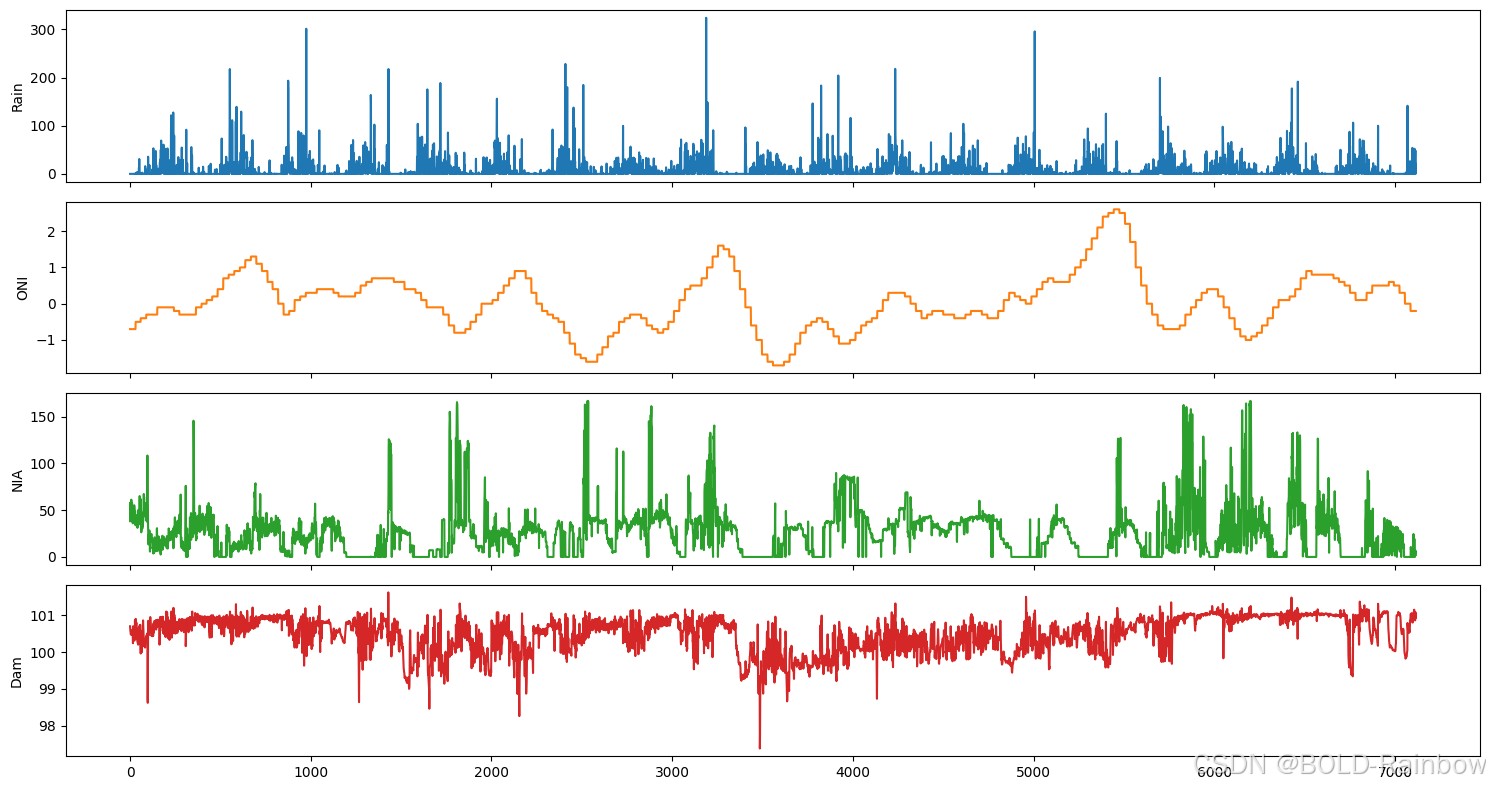
现在,我们对拉梅萨数据集采取同样的步骤。
lamesa_df = pd.read_csv('../data/La Mesa_dataset.csv', index_col='Time');
lamesa_df = lamesa_df.dropna()
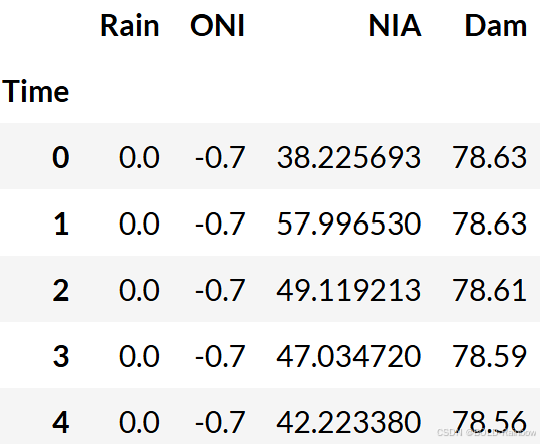
lamesa_df.head()
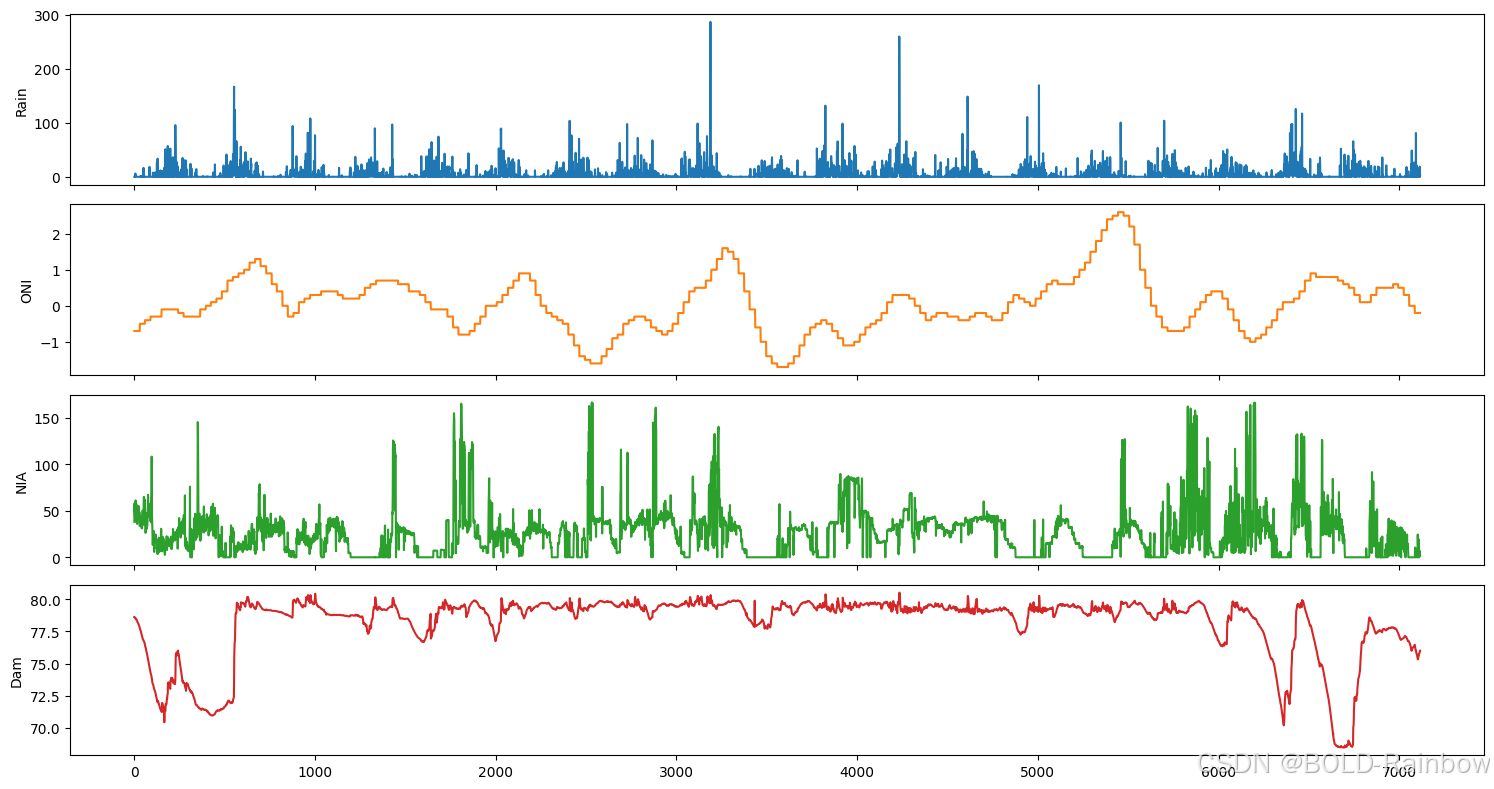
fig,ax = plt.subplots(4, figsize=(15,8), sharex=True)
plot_cols = ['Rain', 'ONI', 'NIA', 'Dam']
lamesa_df[plot_cols].plot(subplots=True, legend=False, ax=ax)
for a in range(len(ax)):
ax[a].set_ylabel(plot_cols[a])
ax[-1].set_xlabel('')
plt.tight_layout()
plt.show()
Causlity between Rainfall and La Mesa Dam Water Level
在下一个示例中,我们首先考虑雨水和水坝时间序列。
data_df = lamesa_df.drop(['ONI', 'NIA'], axis=1)
data_df.head()
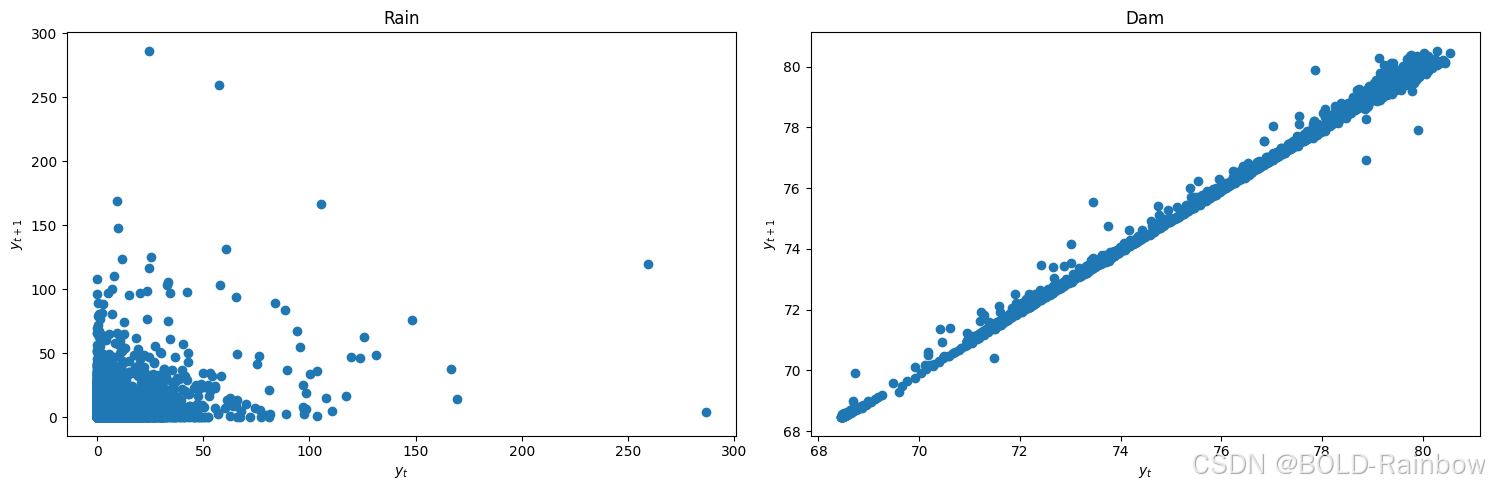
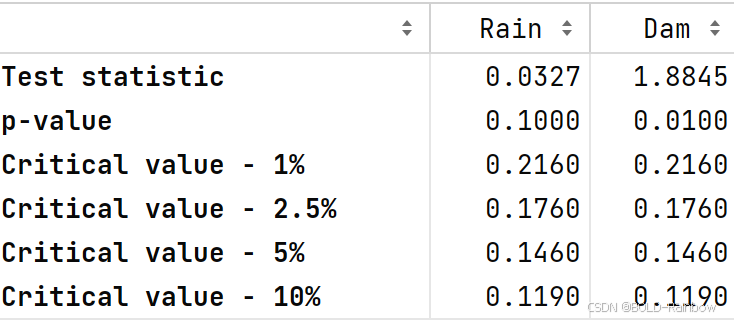
我们首先通过观察滞后图并应用 KPSS 和 ADF 检验来检查是否存在平稳性。
lag_plots(data_df)
kpss_test(data_df)
adf_test(data_df)
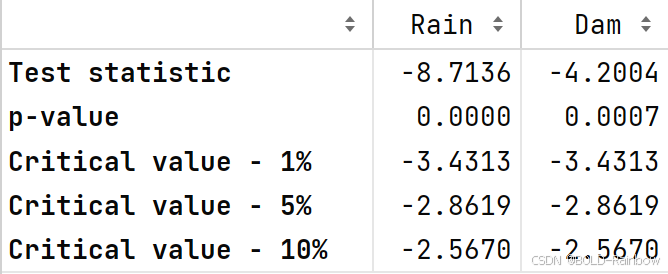
结果: 三项检验结果表明Rain是平稳的,然而Dam不是
我们采用差分法并重新检查静态性。
data_df['Dam'] = data_df['Dam'] - data_df['Dam'].shift(1)
data_df = data_df.dropna()
lag_plots(data_df)
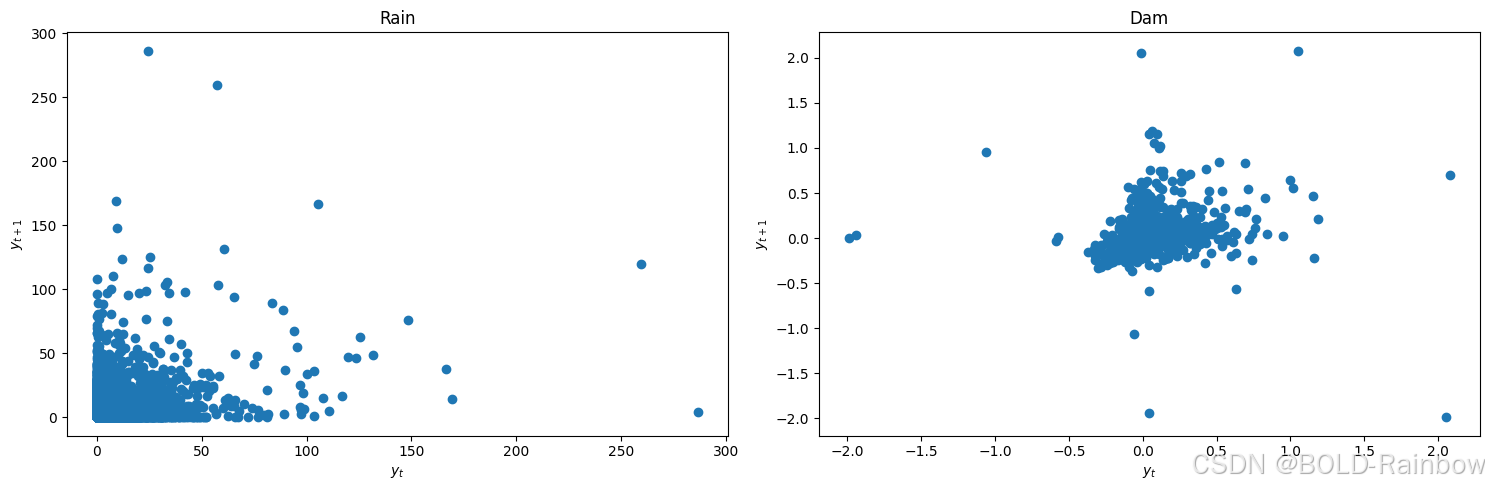
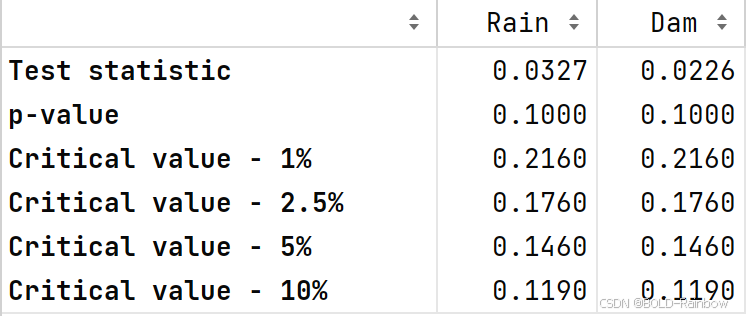
kpss_test(data_df)
adf_test(data_df)
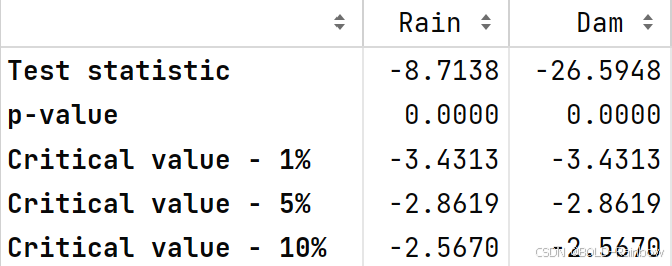
结果 三项检验一致认为现在处于平稳状态
我们接下来选择延迟阶数
p
p
p
train_df, test_df = splitter(data_df)
select_p(train_df)
AIC 7
BIC 6
HQIC 7
FPE 7
dtype: int64

我们选择
𝑝
=
7
𝑝=7
p=7。 最后,我们拟合 VAR 模型并检验格兰杰因果关系。
p = 7
model = VAR(train_df)
var_model = model.fit(p)
granger_causation_matrix(train_df, train_df.columns, p)
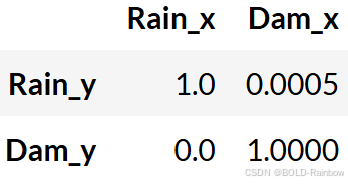
Recall: 如果给定的 p 值小于显著性水平 (0.05),则相应的 X 序列(列)会导致 Y(行)。
结果 在这个例子中,我们可以说降雨量格兰杰效应会导致大坝水位的变化。 反之,大坝水位的变化也会导致降雨量的变化。 这又是一个反馈的例子。 这意味着降雨量数据提高了大坝水位变化的预测性能,而大坝水位数据也提高了降雨量预测性能。
Causality between NIA Release Flow and La Mesa Dam Water Level
在下一个示例中,我们将重点关注 NIA 和 Dam 时间序列。
data_df = lamesa_df.drop(['ONI', 'Rain'], axis=1)
data_df.head()
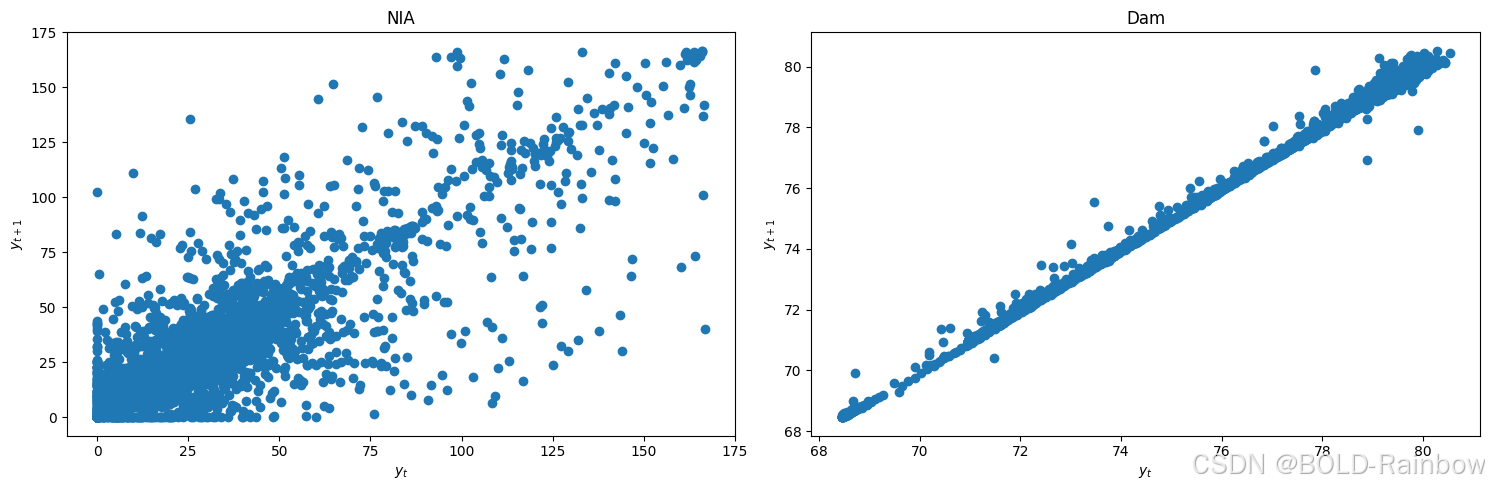
我们首先通过观察滞后图并应用 KPSS 和 ADF 检验来检查是否存在静止性。
lag_plots(data_df)
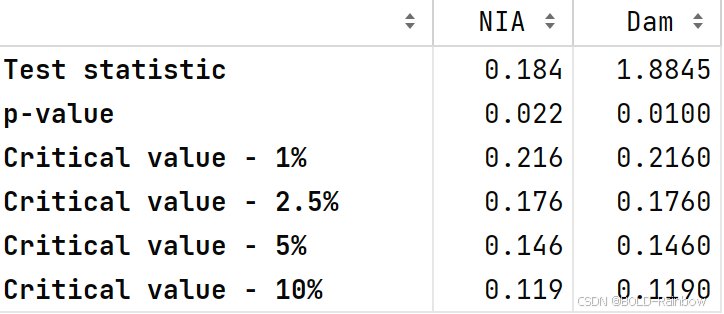
kpss_test(data_df)
adf_test(data_df)
结果: 这三个结果都确凿地表明,这两个数据都不是静止的。
我们采用差分法并重新检查静态性。
data_df['NIA'] = data_df['NIA'] - data_df['NIA'].shift(1)
data_df['Dam'] = data_df['Dam'] - data_df['Dam'].shift(1)
data_df = data_df.dropna()
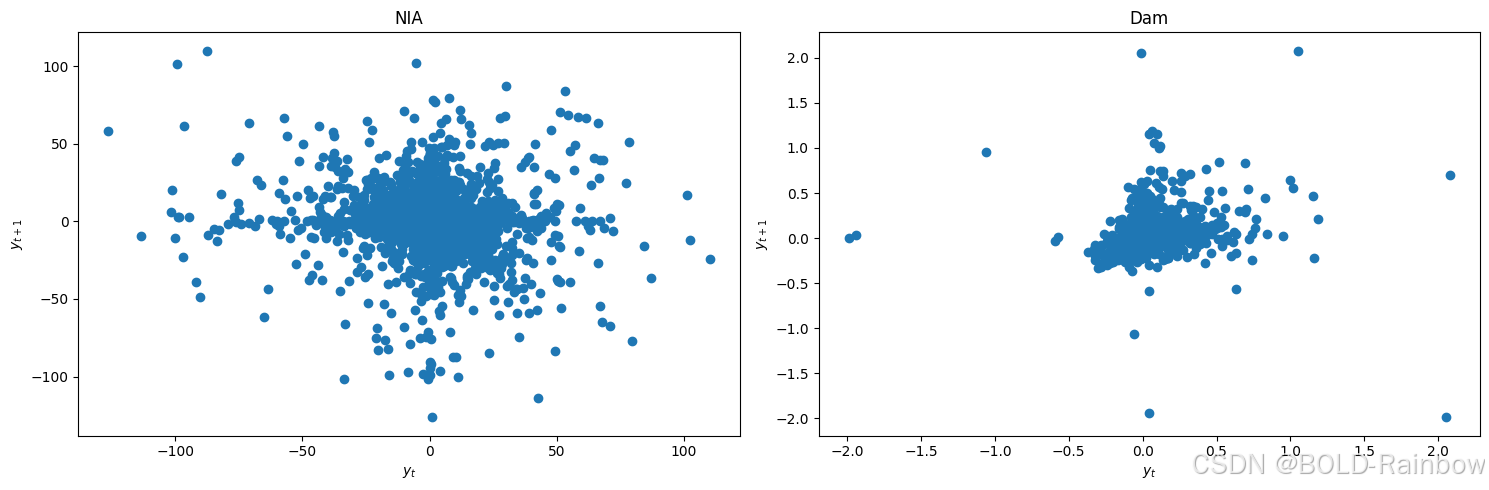
lag_plots(data_df)
kpss_test(data_df)
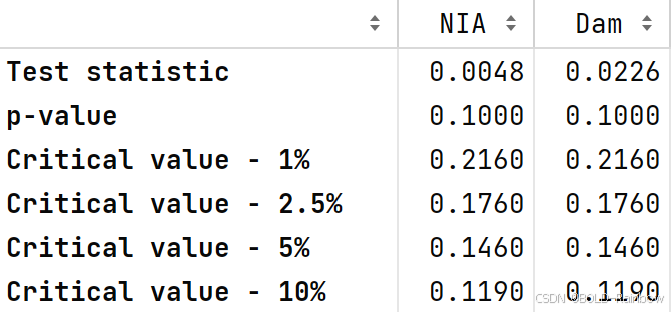
adf_test(data_df)
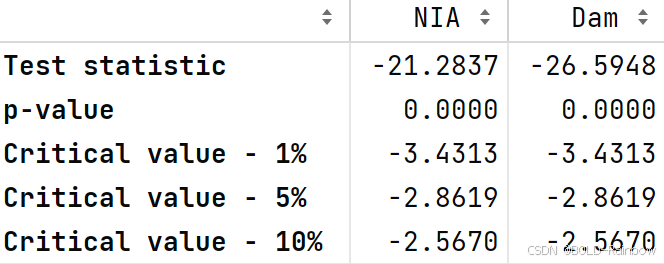
结果: 三j结果最终一致认为,两个数据现在都处于静止状态。
接下来,我们对数据进行拆分,并选择滞后阶数𝑝。
train_df, test_df = splitter(data_df)
select_p(train_df)
AIC 14
BIC 2
HQIC 8
FPE 14
dtype: int64

我们选择𝑝=14。 最后,我们拟合 VAR 模型并检验格兰杰因果关系。
p = 14
model = VAR(train_df)
var_model = model.fit(p)
granger_causation_matrix(train_df, train_df.columns, p)
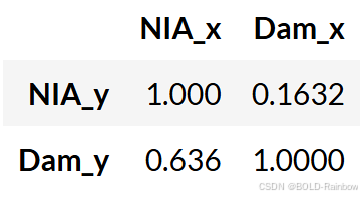
Recall: 如果给定的 p 值小于显著性水平 (0.05),则相应的 X 序列(列)会导致 Y(行)。
结果 我们可以看到,与 Ipo 大坝不同,对于 La Mesa 大坝而言,NIA 下泄流量的变化与大坝水位的变化并不互为格兰杰原因。 这意味着 NIA 下泄流量数据不会改善大坝水位预测性能的变化,而大坝水位数据也不会改善 NIA 下泄流量预测性能的变化。
Summary
我们在本章中介绍了因果关系的概念,并讨论了它对时间序列分析的影响。 我们还对几个数据集的线性 VAR 模型进行了格兰杰因果检验,看到了所探讨变量之间因果关系的不同实例。
因果关系将在后一章中再次讨论,特别是本章讨论的方法的局限性,以及非线性模型的因果关系。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









