




目录
链表是一个增删快,查询慢的模型(对比数组)链表存储数据的方式
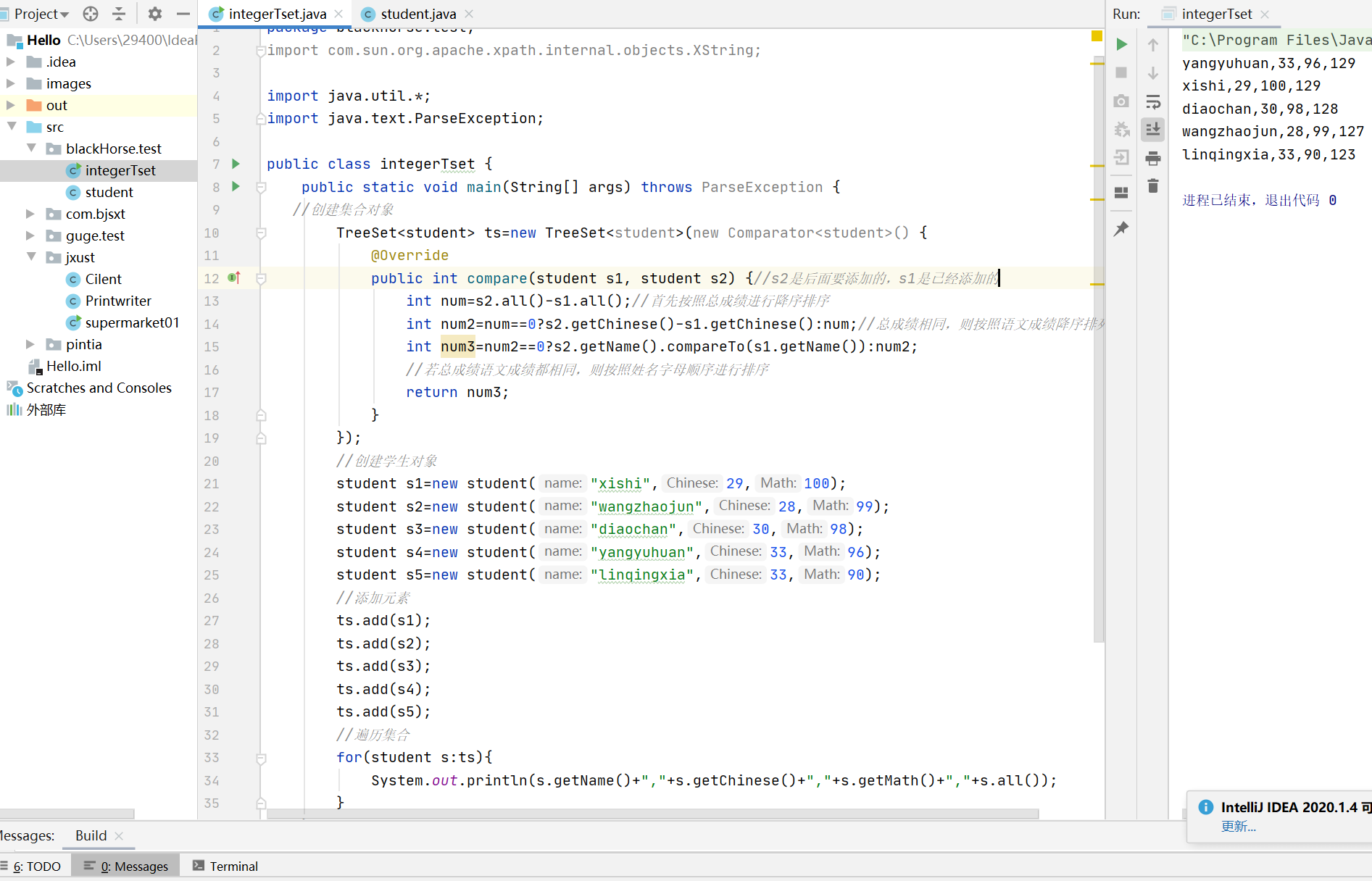
自然排序Comparable的使用
String Integer类都实现了Comparable接口
Comparable接口对实现它的每个类的对象增强一个整体排序,这个排序被称为类的自然排序,类的campareTo方法被称为其自然比较方法
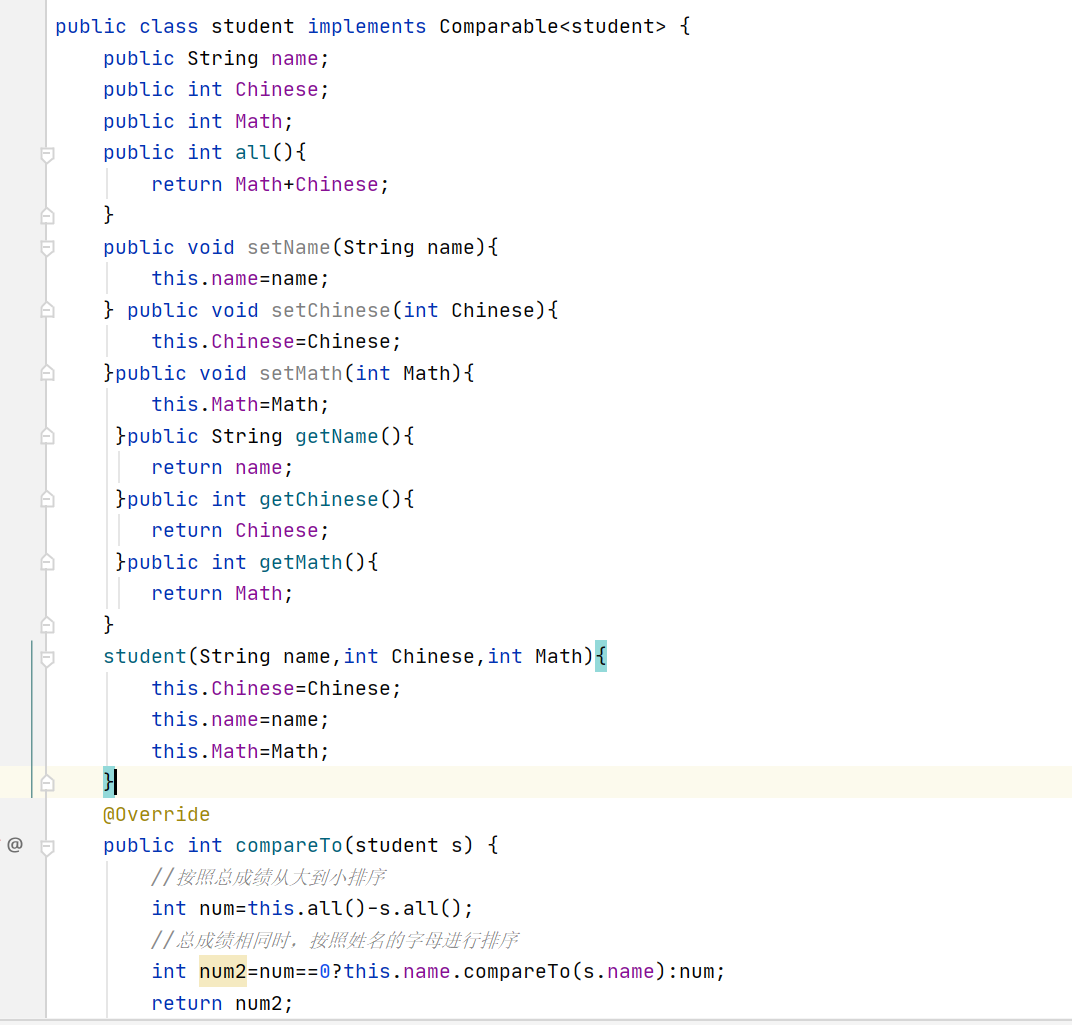
存储学生对象并遍历,创建集合使用无参构造方法
要求:按照年龄从小到大进行排序,年龄相同时,按照姓名的字母进行排序
注:
- 用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自然排序,就是让元素所属的类实现Compareble接口,重写CompareTo(To)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件写
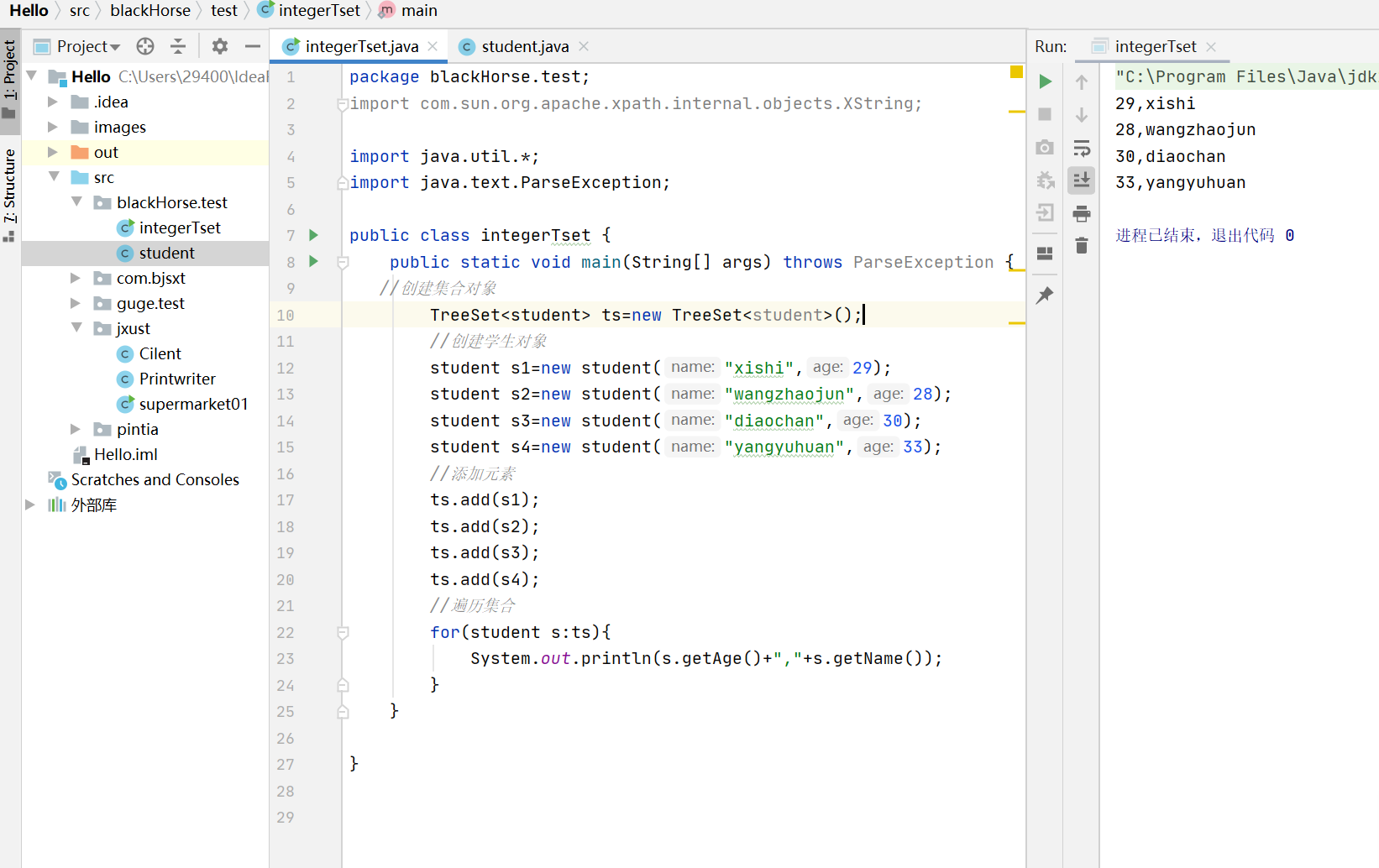
红色圈出来的两步是必须要操作的,要不然无法将数据存储在集合里面,但是现在这样却只能保存一个数据,具体原因在compareTo的return值

但此时运行时,却只能存储一个数据

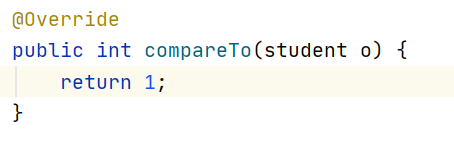
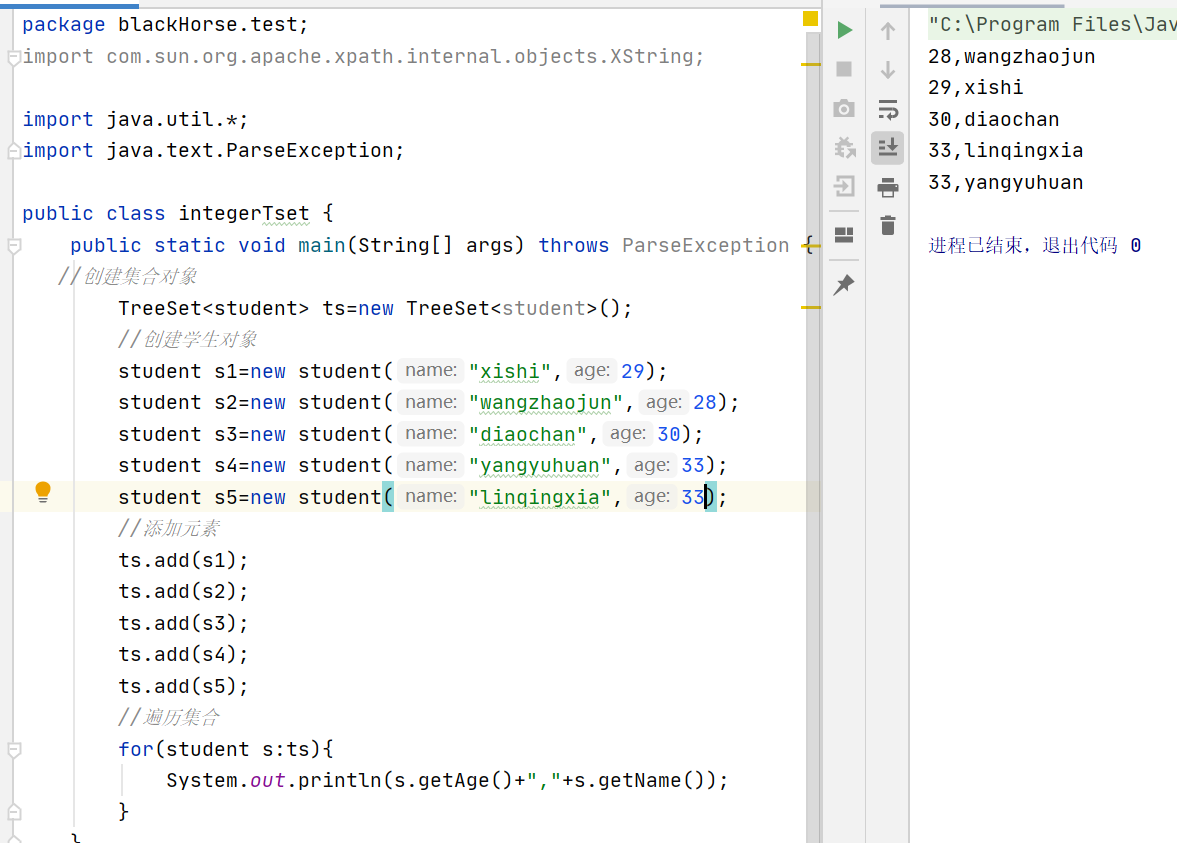
当我把compareTo的return值改成1之后,就能将所有的数据保存在集合里面了,遍历时是正序输出(遍历输出顺序与存储输入的顺序一致)
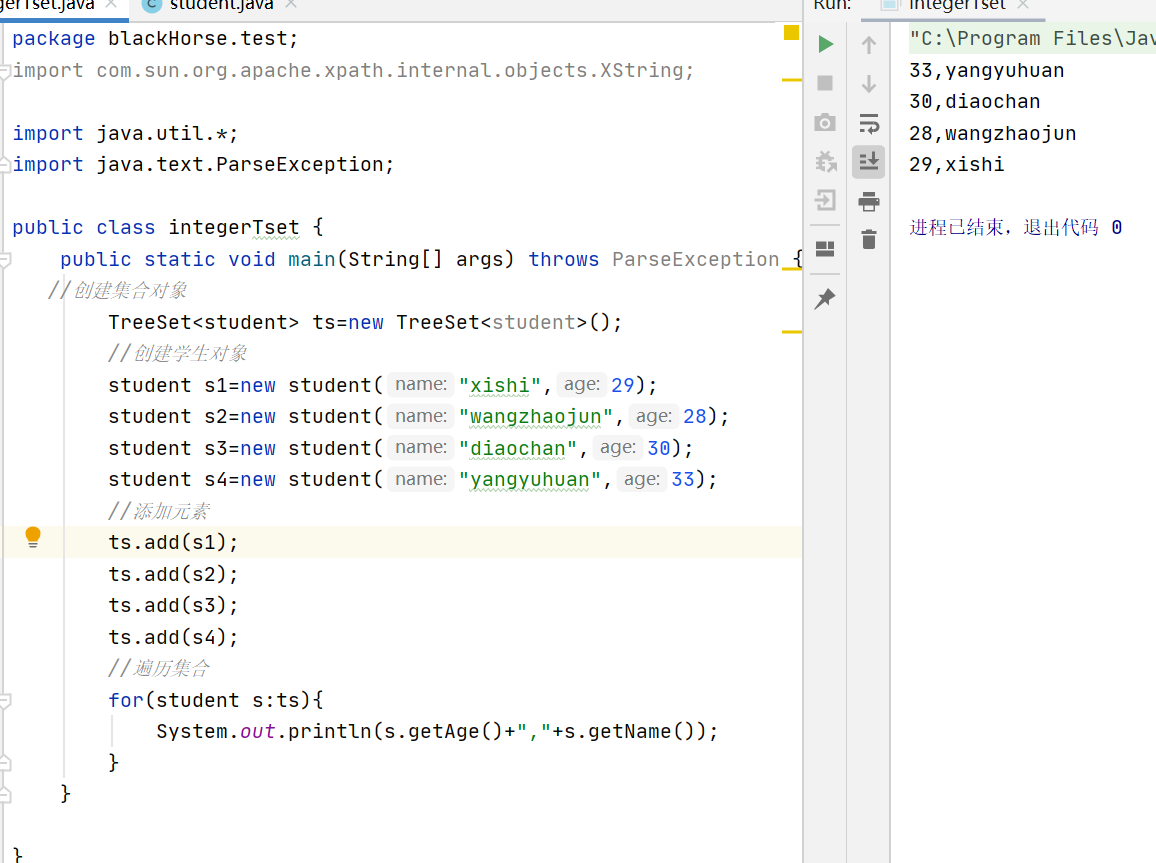
将return值改为-1后,就会进行倒序输出(遍历输出顺序与存储输入的顺序相反)

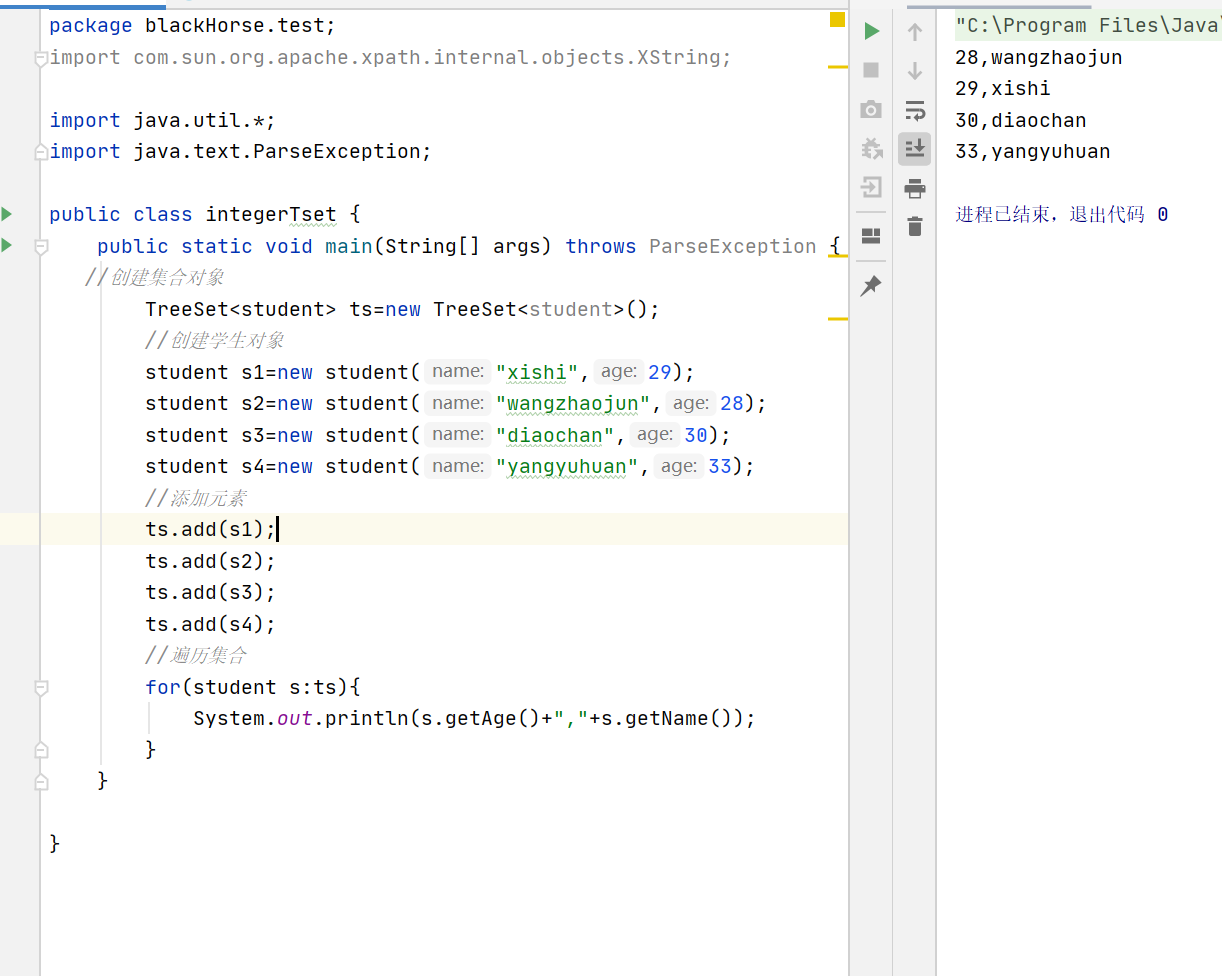
把compareTo的return值进行修改,实现按照年龄从小到大遍历输出

把compareTo方法的返回值进行修改,实现按照年龄从大到小进行排序

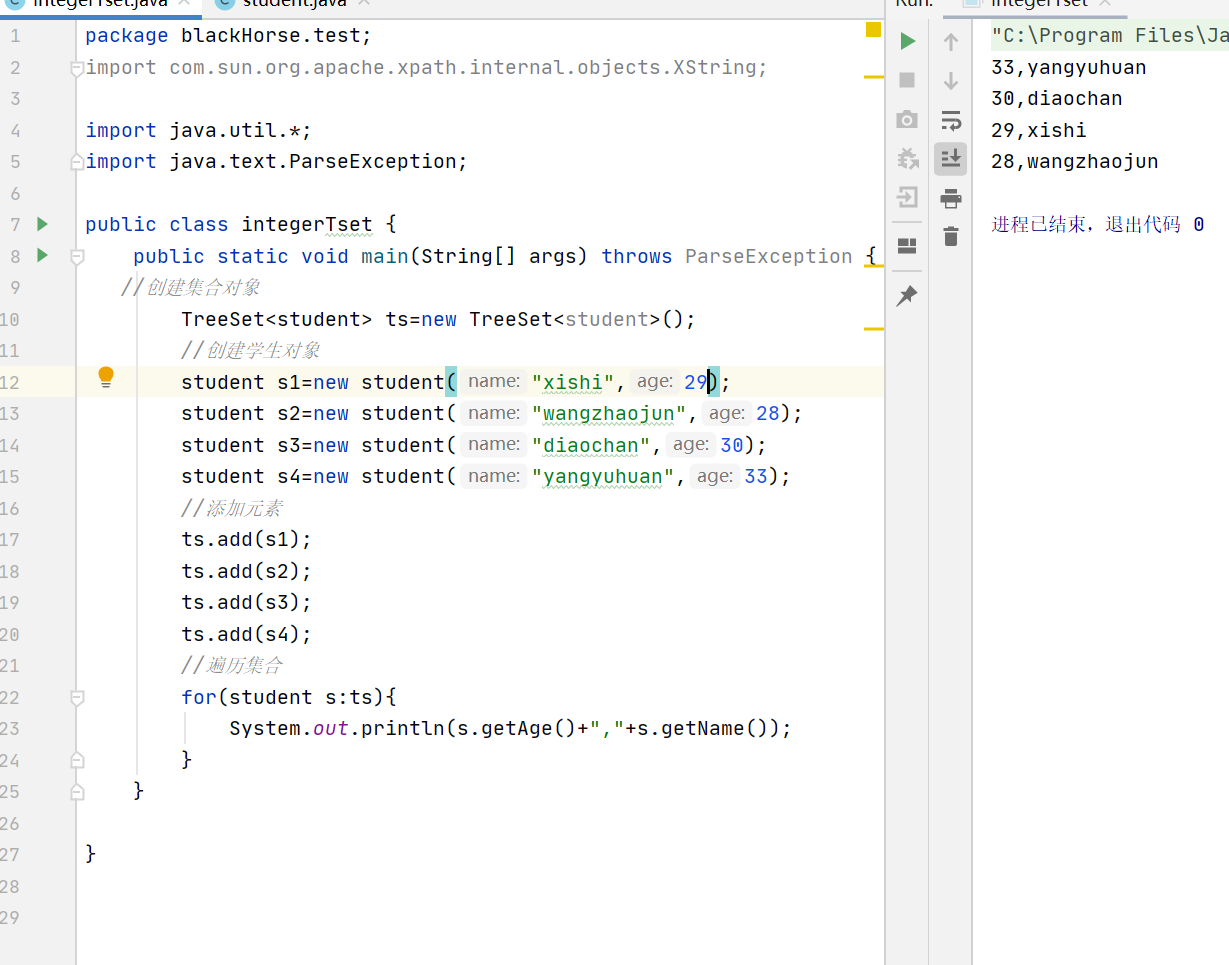
实现如果年龄相同则按照姓名的字母顺序排列
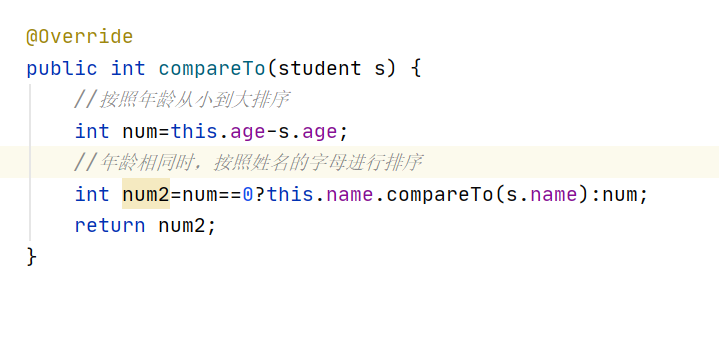
对于CompareTo方法
升序时 this在前面,降序时 this在后面
这里TreeSet用的无参构造,自动从小到大排序,判断大小的标准是compareTo的返回值,如果返回值是1就放在后面,返回值是-1就放在前面。只说1是正序是不对的
比较器排序Comparator的使用
创建一个集合,对学生的进行遍历,学生类的属性有姓名,数学成绩,语文成绩。
按照总成绩从大到小的顺序进行排列,如果总成绩相同则按照语文成绩进行排列,如果语文成绩还相同,则按照姓名的字母顺序进行排列。
- 用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
- 自然排序,就是让集合构造方法接受Comparator的实现类对象,重写Compare(To 1,To 2)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件写
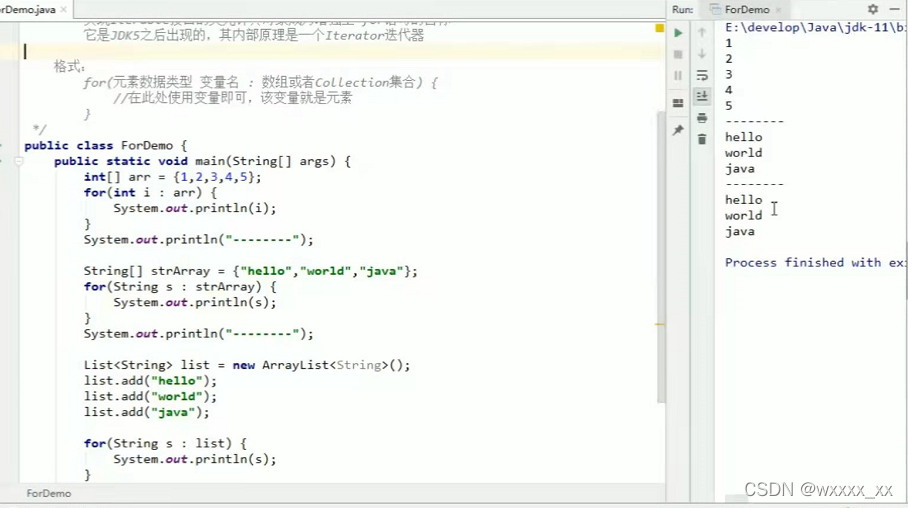
增强for循环
简化数组和Collection集合的遍历
- 实现Iterable接口的类允许其对象成为增强for语句的目标
- 它是JDK5之后出现的,其内部原理是一个Iterator迭代器
增强for的格式
for(元素数据类型 变量名:数组或者Collection集合){
//在此处使用变量即可,该变量就是元素
}
int [] arr={1,2,3,4,5}
for(int i:arr){
System.out.println(i);
}
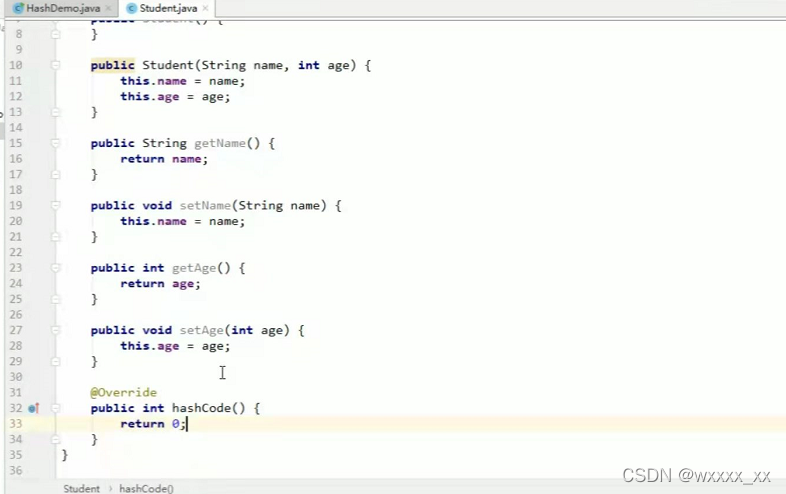
哈希值
哈希值是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
Object类中有一个方法可以获取对象的哈希值
- public int hashCode():返回对象的哈希值码
对象的哈希值特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
重写hashCode()方法
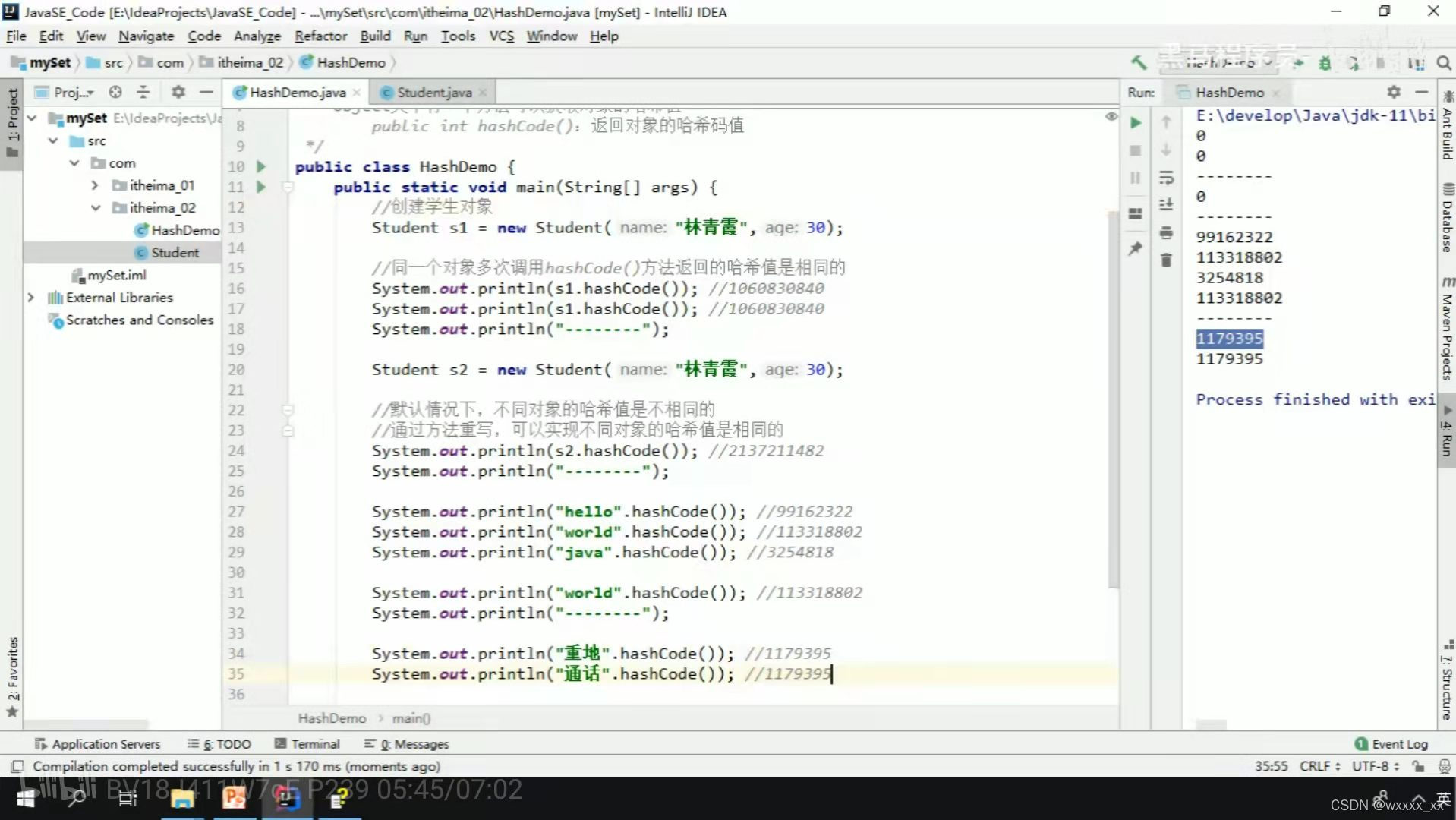
重写后的运行结果(注释后面写的是未重写hashCode()方法的运行结果)
常见数据结构——栈
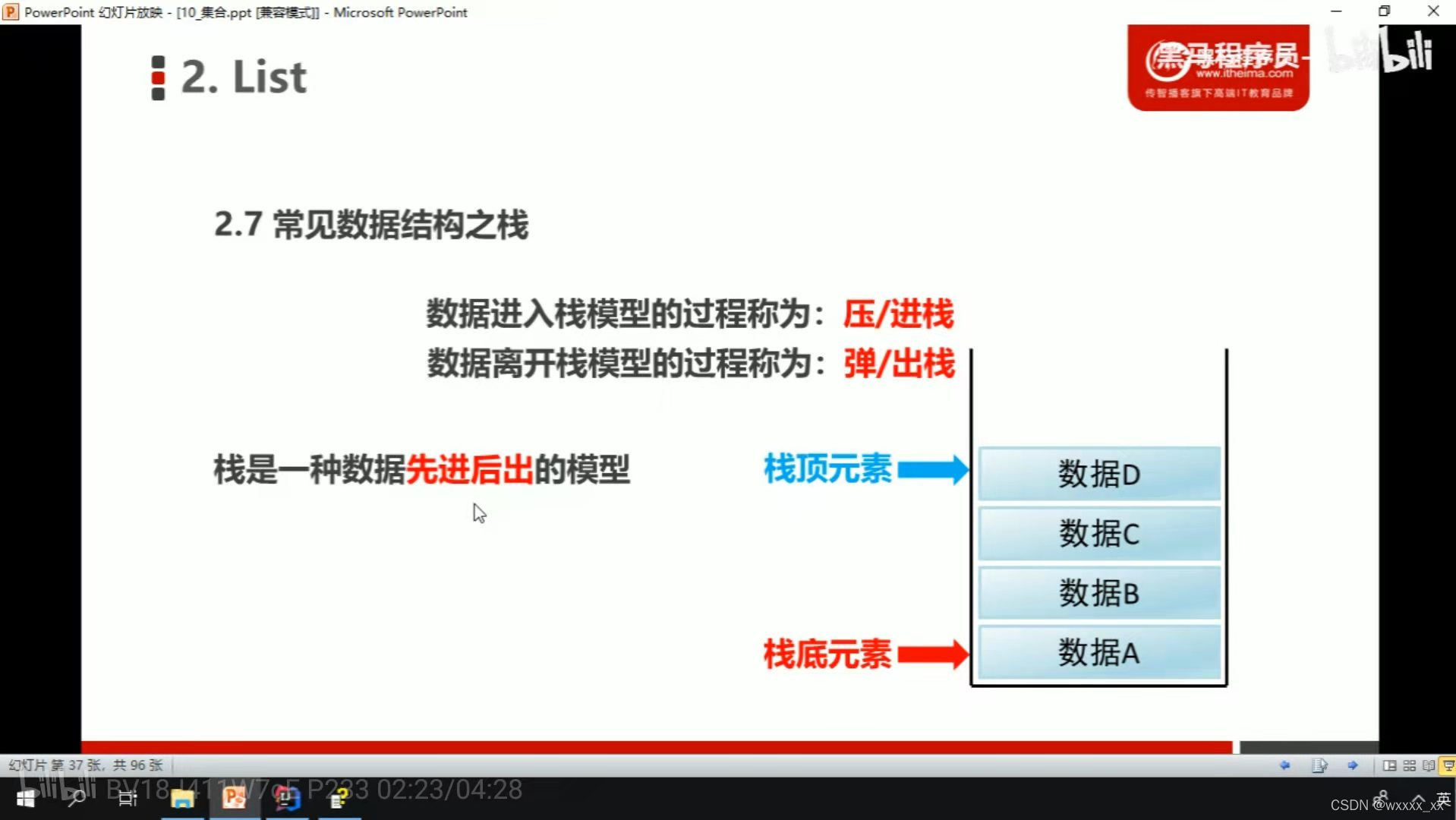
常见数据结构——队列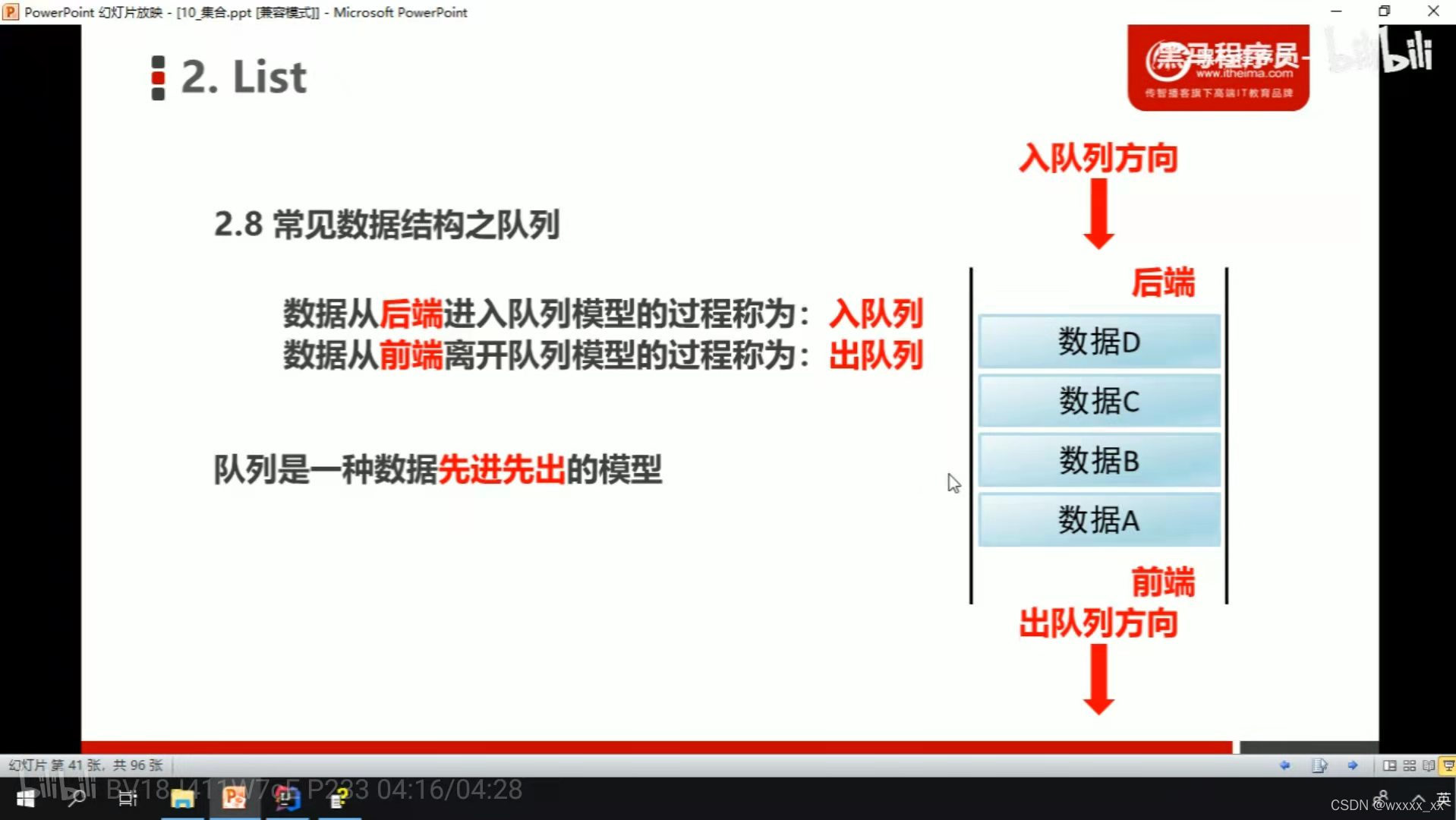
常见数据结构——数组
数组是一种查询快,增删慢的模型
查询数据通过索引定位,查询任意数据耗时相同,查询效率高
删除数据时,要将原始数据删除,同时后面每个数据前移,删除效率低
添加数据时,添加位置后的每个数据后移,再添加元素,添加效率极低
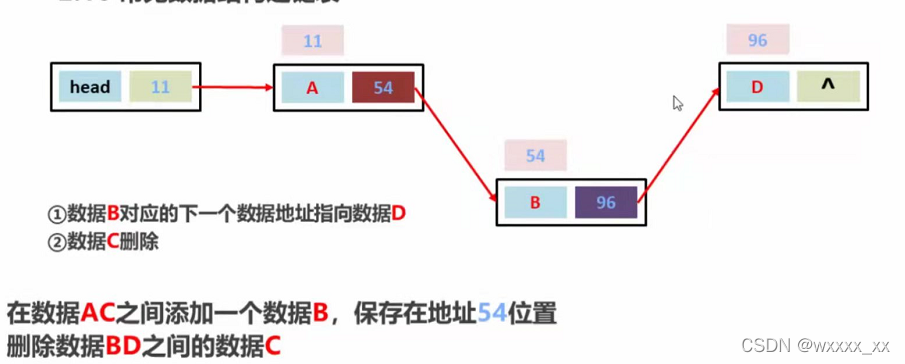
常见数据结构——链表
链表是一个增删快,查询慢的模型(对比数组)
链表存储数据的方式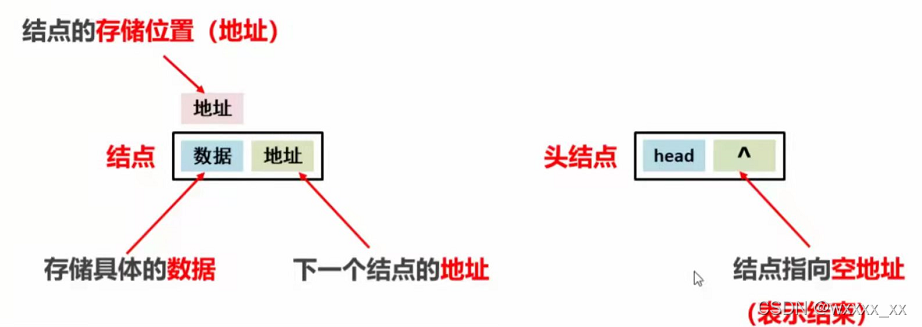
链表的大致结构
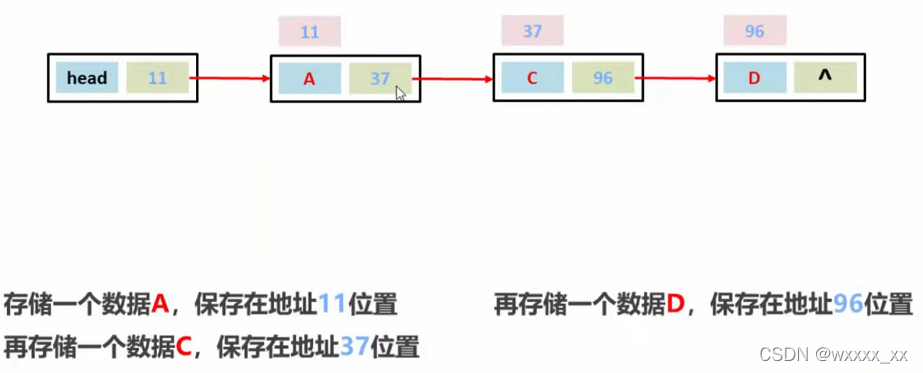
链表增删数据的步骤
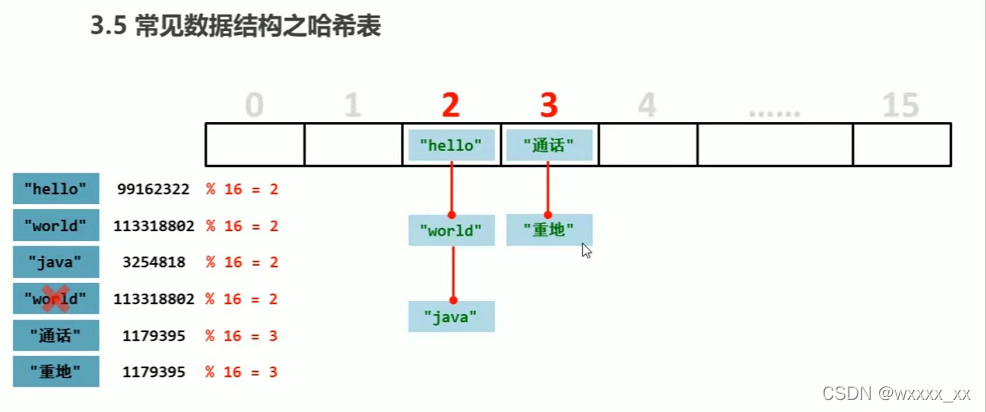
常见数据结构——哈希表
哈希表底层使用的是数组与单向链



















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











