






 本文介绍了SQL的基础命令,包括数据表操作、视图创建、DQL查询以及Hadoop的分布式系统概念、HDFS与MapReduce组件的功能和YARN资源调度。涵盖了数据的创建、查询、存储和大规模计算的分布式环境。
本文介绍了SQL的基础命令,包括数据表操作、视图创建、DQL查询以及Hadoop的分布式系统概念、HDFS与MapReduce组件的功能和YARN资源调度。涵盖了数据的创建、查询、存储和大规模计算的分布式环境。
一.回顾sql命令语句
1.常用sql语句
| 关键字 | 功能 | 语法 |
|---|---|---|
| CREATE DATABASE | 创建数据库 | CREATE DATABASE database_name |
| CREATE TABLE | 创建表 | CREATE TABLE student |
| CREATE INDEX | 创建索引 | CREATE INDEX PersonIndex ON Person (LastName, FirstName) |
| DROP | 删除操作 | 删除索引:DROP INDEX index_name 数据库不同则语法存在差异,自行百度 删除表:DROP TABLE 表名称 仅删除表格数据:TRUNCATE TABLE 表名称 删除数据库:DROP DATABASE 数据库名称 |
| ALTER TABLE | 添加、修改、删除列 | 添加列:ALTER TABLE table_name ADD column_name datatype 删除列:ALTER TABLE table_name DROP COLUMN column_name 修改列:ALTER TABLE Persons ALTER COLUMN Birthday year |
| VIEW | 视图 | CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition |
| GROUP BY | 分组查询:主要用于某个重复值,列属性的分开查询操作 | 查询每个客户的总金额:SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer |
| WHERE | 条件查询 | SELECT 列名称 FROM 表名称 WHERE 列 运算符 值运算符(等于=|不等于<>|大于>|小于<|大于等于>=| 小于等于<=| BETWEEN 在某个范围内| LIKE 搜索某种模式) |
| HAVING | 条件查询 | 查找客户 "Bush" 或 "Adams" 拥有超过 1500 的订单总金额:SELECT Customer,SUM(OrderPrice) FROM Orders WHERE Customer='Bush' OR Customer='Adams' GROUP BY Customer HAVING SUM(OrderPrice)>1500 |
| UPDATE SET | 修改表中数据 | UPDATE students SET name = 'Zhongshan' WHERE sno = '1001' |
| AND 和 OR | WHERE 子语句中把两个或多个条件结合起来 | SELECT * FROM Persons WHERE (FirstName='Thomas' OR FirstName='William') AND LastName='Carter' |
| ORDER BY | 默认ASC升序DESC则降序 | SELECT Company, OrderNumber FROM Orders ORDER BY Company DESC, OrderNumber ASC |
| BETWEEN | 范围取值 | 范围查询年龄:SELECT column_name(s) FROM table_name WHERE age BETWEEN 30 AND 40 |
| AS | 别名 | SELECT sname AS na FROM student |
| DISTINCT | 去重复值 | SELECT DISTINCT 列名称 FROM 表名称 |
INSERT INTO | 向表格中插入新的行 | INSERT INTO 表名称 VALUES (值1, 值2,....)INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....) |
| LIKE | 操作符 | %:代表零个或多个字符 _ :仅替代一个字符 [!charlist]:不在字符列中的任何单一字符 查N开头:SELECT * FROM Persons WHERE City LIKE 'N%' 查G结尾:SELECT * FROM Persons WHERE City LIKE '%G' |
| IN | 操作符允许我们在 WHERE 子句中规定多个值 | 选取姓氏为 王 和 李 的人: SELECT * FROM Persons WHERE LastName IN ('王','李') |
2.sql练习题
创建数据表
CREATE TABLE employee
(
id INT,
NAME VARCHAR(20), -- 姓名
sex VARCHAR(10), -- 性别
salary FLOAT -- 收入
);
INSERT INTO employee VALUES(1,'zhangsan','male',2000),(2,'lisi','male',1000),(3,'xiaohong','female',4000);
CREATE TABLE student(
id INT,
NAME VARCHAR(20),
chinese INT, -- 中文成绩
english INT, -- 英文成绩
math INT -- 数学成绩
);
INSERT INTO student(id, NAME, chinese, english, math)
VALUES (1, '张小明', 89, 78, 90),(2, '李进', 67, 53, 95),(3, '王五', 87, 78, 77),(4, '李一', 88, 98, 92),(5, '李来财', 82, 84, 67),(6, '张进宝', 55, 85, 45),(7, '黄蓉', 75, 65, 30),(7, '黄蓉', 75, 65, 30);
DQL数据查询
-- 1.查询表中所有学生的信息。
SELECT *
FROM student
-- 2.查询表中所有学生的姓名和对应的英语成绩。
SELECT NAME,english
FROM student
-- 3.过滤表中重复数据。
SELECT DISTINCT *
FROM student
-- 4.统计每个学生的总分。
SELECT id,NAME,score
FROM student
WHERE score = chinese + english + math
-- 5.在所有学生总分数上加10分特长分。
UPDATE student SET score = score + 10
-- 6.使用别名表示学生分数。
SELECT chinese AS ch,english AS en,math AS ma
FROM student
-- 7.查询英语成绩大于90分的同学
SELECT NAME
FROM student
WHERE english > 90
-- 8.查询总分大于200分的所有同学
SELECT NAME
FROM student
WHERE score = chinese + english + math AND score > 200
-- 9.查询英语分数在 80-90之间的同学。
SELECT NAME
FROM student
WHERE english NETWEEN 80 AND 90
-- 10.查询英语分数不在 80-90之间的同学。
SELECT NAME
FROM student
WHERE english NOT BETWEEN 80 AND 90
-- 11.查询数学分数为89,90,91的同学。
SELECT NAME
FROM student
WHERE math IN(89,90,91)
-- 12.查询所有姓李的学生英语成绩。
SELECT NAME,english
FROM student
WHERE NAME LIKE '李%'
-- 13.查询数学分80并且语文分80的同学。
SELECT NAME
FROM student
WHERE math = 80 AND chinese = 80
-- 14.查询英语80或者总分200的同学
SELECT NAME
FROM student
WHERE english = 80 AND score = chinese + math + english AND score =200
二.初步了解hadoop
1.分布式系统和集群
(1)分布式与集群
分布式:指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。
集群:指一组独立的计算机系统构成的一多处理器系统,它们之间通过网络实现进程间的通信,让若干台计算机 联合起来工作(服务),可以是并行的,也可以是做备份。
(2)分布式的基本架构
分布式的调度主要有2类架构模式: • 去中心化模式 • 中心化模式
2.hadoop框架概论
(1)hadoop功能
HDFS组件 HDFS是Hadoop内的分布式存储组件 可以构建分布式文件系统用于数据存储
MapReduce组件 MapReduce是Hadoop内分布式计算 组件。提供编程接口供用户开发分布式 计算程序
YARN组件 YARN是Hadoop内分布式资源调度组件。 可供用户整体调度大规模集群的资源使用。
(2)hadoop架构
HDFS和Yarn
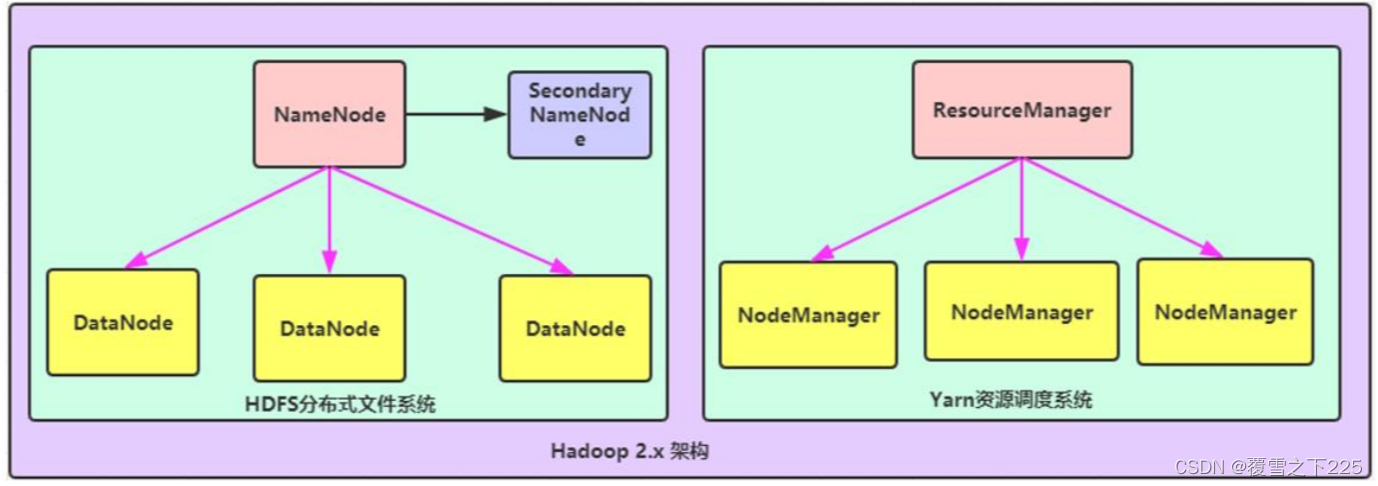
➢ HDFS模块: NameNode:集群当中的主节点,主要用于管理集群当中的各种数据 SecondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理 DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
➢ 数据计算核心模块: ResourceManager:接收用户的计算请求任务, 并负责集群的资源分配 NodeManager: 负责执行主节点分配的任务
MapReduce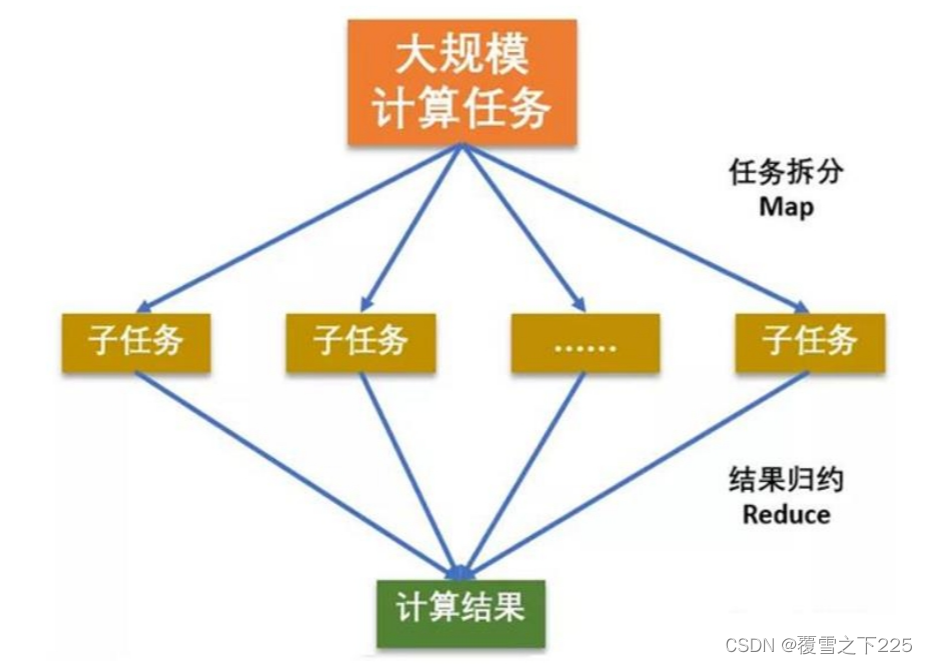
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储
MapReduce的运行需要由Yarn集群来提供资源调度。















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









