









目录
前言
PaddleOCR是目前识别精度比较高的开源项目,这篇文章主要介绍如何利用私人数据集训练OCR模型,并部署到本地。
一、环境搭建
1.创建虚拟环境
conda creeate -n paddle_gpu python = 3.82.安装paddlepaddle-gpu版本
激活虚拟环境
activate paddlle_gpu根据paddlepaddle版本要求,安装对应的cuda和cudnn版本。
经过本人测试,安装低于当前电脑cuda版本的paddle,也不影响使用(本人电脑已经安装cuda11.3,没找到对应paddle版本,因此安装的是cuda11.2版本paddle)
conda install paddlepaddle-gpu==2.3.2 cudatoolkit=11.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge验证安装是否成功,终端输入python,然后分别输入以下两行代码
import paddle
paddle.utils.run_check()安装padlleocr,截至2023.06.11,GitHub上最新版本是2.6,因此按照以下命令安装:
pip install "paddleocr>=2.6"验证安装是否成功
from paddleocr import PaddleOCR, draw_ocr
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
img_path = './4.jpg'
result = ocr.ocr(img_path, cls=True)
print(result)
for line in result:
print(len(line))
print(line)
print('图片中的第一个检测结果')
print(result[0][0])
print('图片中的第二个检测结果')
print(result[0][1])
print('图片中的第一个检测结果的框坐标')
print(result[0][0][0])
print('图片中的第一个检测结果的文字')
print(result[0][0][1][0])
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [result[0][i][0] for i in range(len(result[0]))]
print(boxes)
txts = [result[0][i][1][0] for i in range(len(result[0]))]
print(txts)
scores = [result[0][i][1][1] for i in range(len(result[0]))]
print(scores)
im_show = draw_ocr(image, boxes, txts, scores)
im_show = Image.fromarray(im_show)
im_show.save('./result.jpg')运行结果如下:

克隆paddleocr库并解压https://github.com/PaddlePaddle/PaddleOCR/archive/refs/heads/release/2.6.zip
接着:
cd PaddleOCR-release-2.6/PPOCRLabelPPOCRLabel文件夹如下图所示:
安装PPOCRLabel,为标注数据作准备,运行以下代码:
python setup.py bdist_wheel该目录下dist文件夹中会生成一个wheel文件
接着运行:
pip3 install dist/PPOCRLabel-2.1.3-py2.py3-none-any.whl安装完成后,启动PPOCRLabel:
PPOCRLabel --lang ch如果提示缺少包,用pip install “packname” 即可,
注意,安装Ploygon时,用pip install Ploygon3命令安装。
二、准备数据
1.使用PPOCRLabel标注数据
运行以下代码:
PPOCRLabel --lang ch 
提前将数据划分为训练集和测试集,再分别进行标注。
点击左上角文件按钮,加载数据集目录,点击左下角自动标注,然后一幅一幅检查并修改检测框和标签,标注结束以后,点击左上角文件导出标记结果和识别结果。
注意,多点标注时,点击最后一个点使其和第一个点重合(这时鼠标会变成小手),即视为画完整个框,然后点击右上角重新识别按钮(多点检测框也会自动变成带角度的矩形框),检查并修改识别结果。
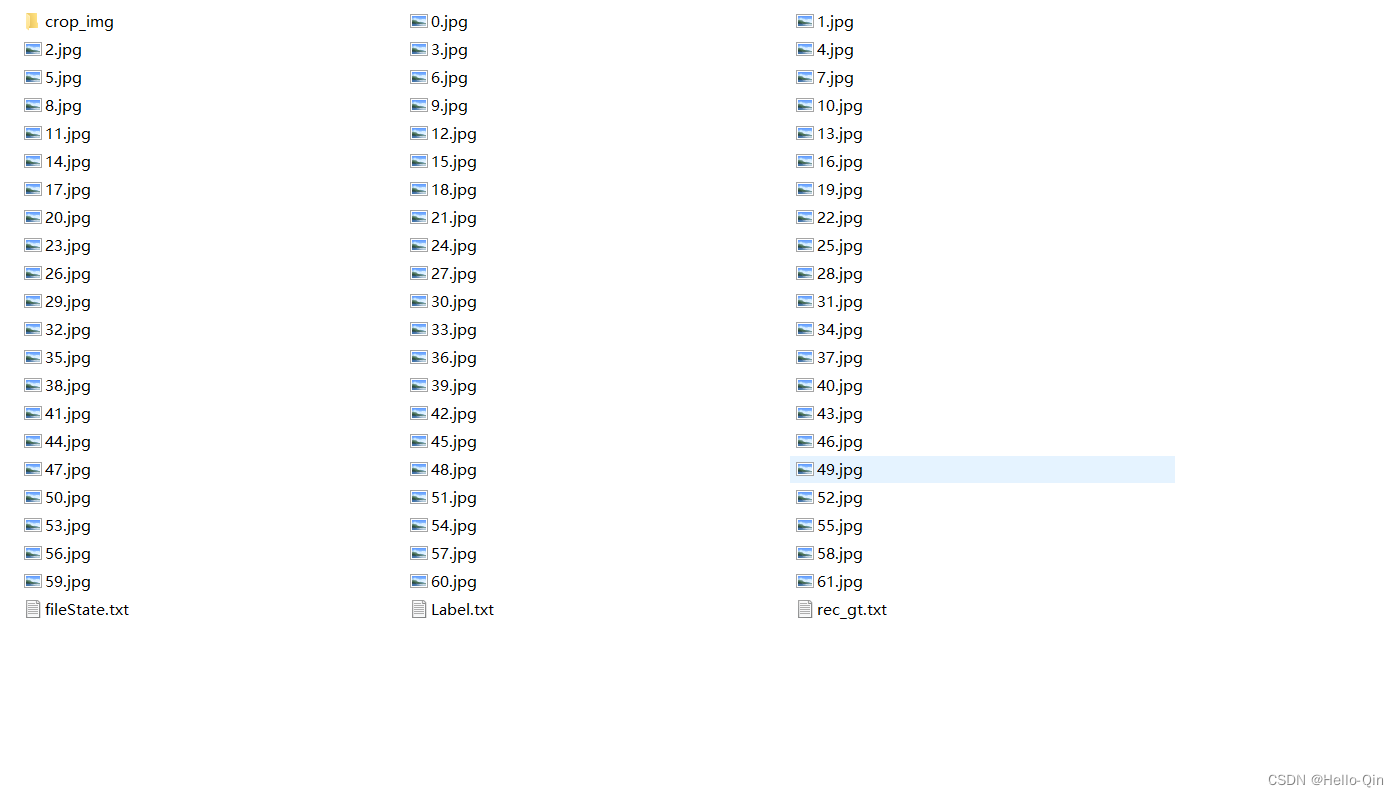
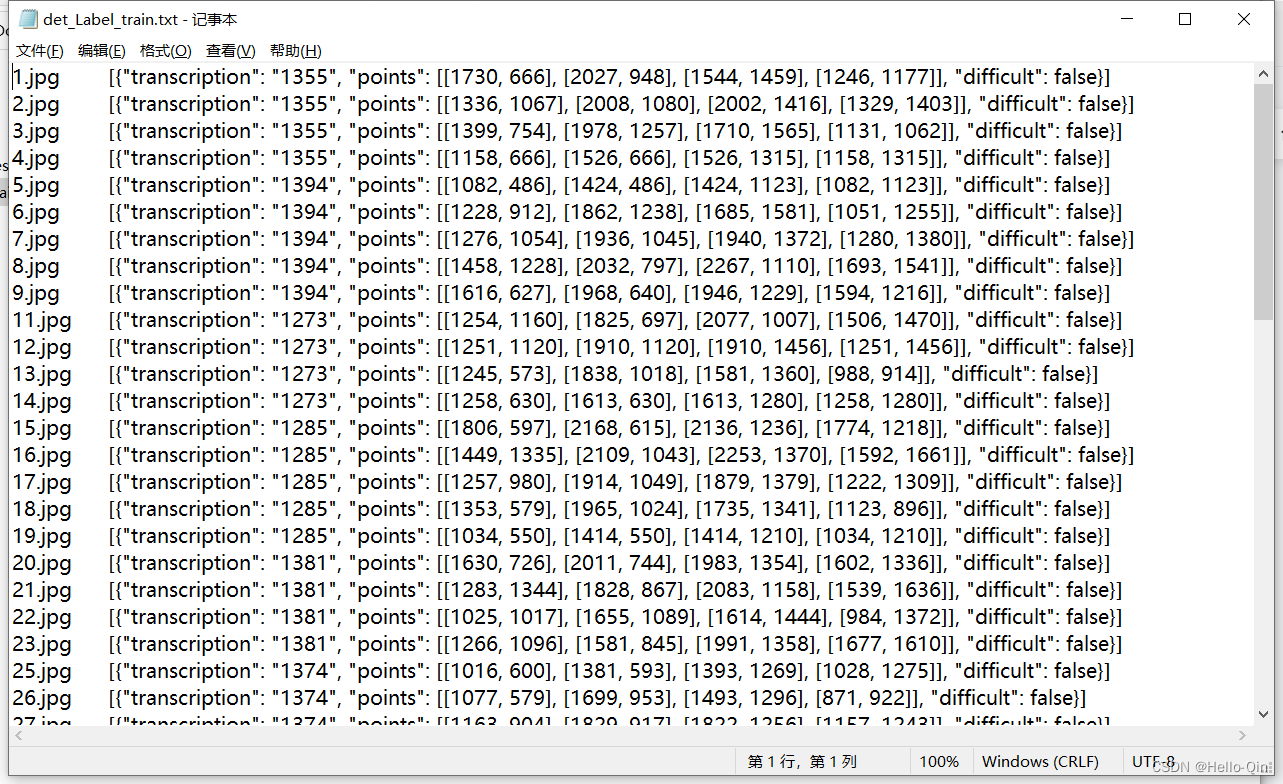
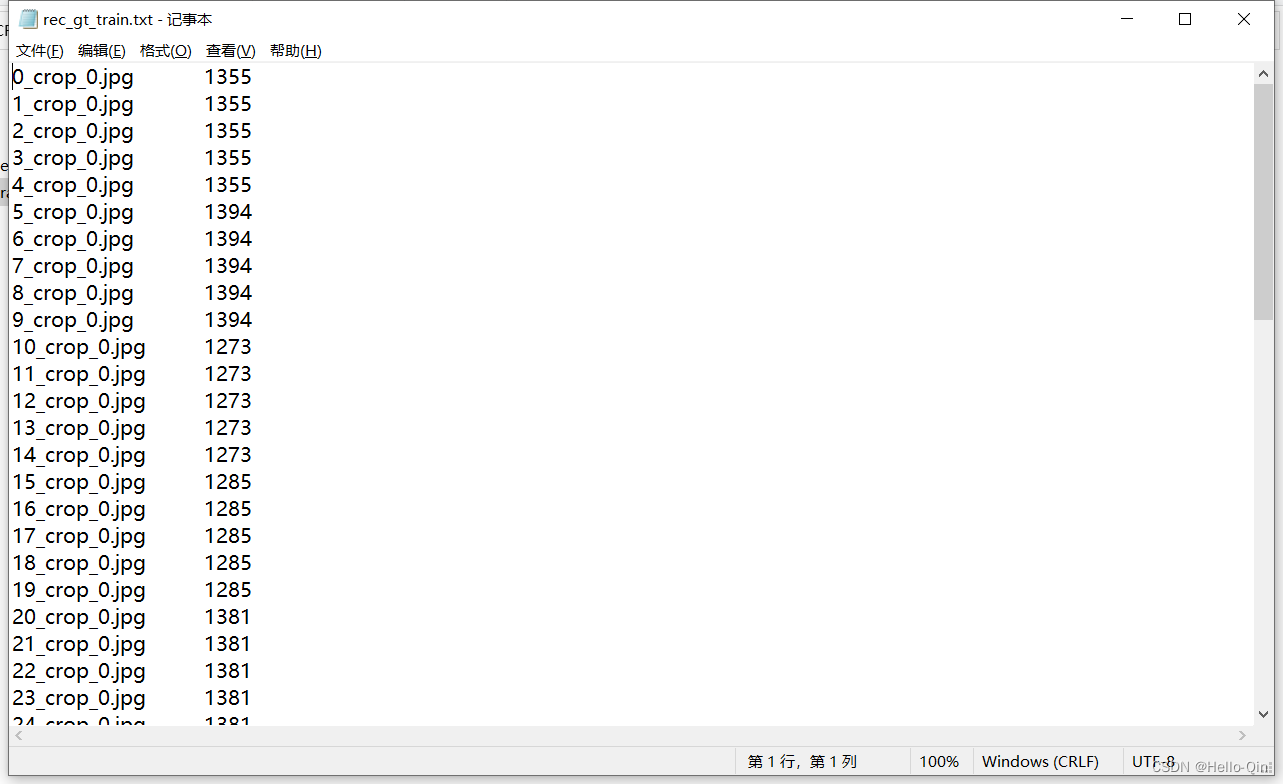
其中,crop_img是从整张图中裁剪的文字区域,Label.txt中每行保存的是原始图片名以及对应文字检测框的四个点坐标(文字检测模型的标签),rec_gt.txt中每行保存的是crop_img文件夹下的图片名和对应文字识别结果(文字识别模型的标签)。
2.构建数据集
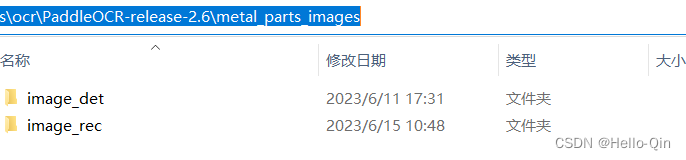
在PaddleOCR-release-2.6文件夹下新建一个存放metal_parts_images(根据自己数据集命名)文件夹,目录下新建image_det和image_rec文件夹,每个文件夹下分别新建train和test文件夹。
将PPOCRLabel标注数据放到对应目录下,train和test文件夹放置图片,label文件也放到该目录下(注意,标注软件自动保存的图片路径需要修改)。
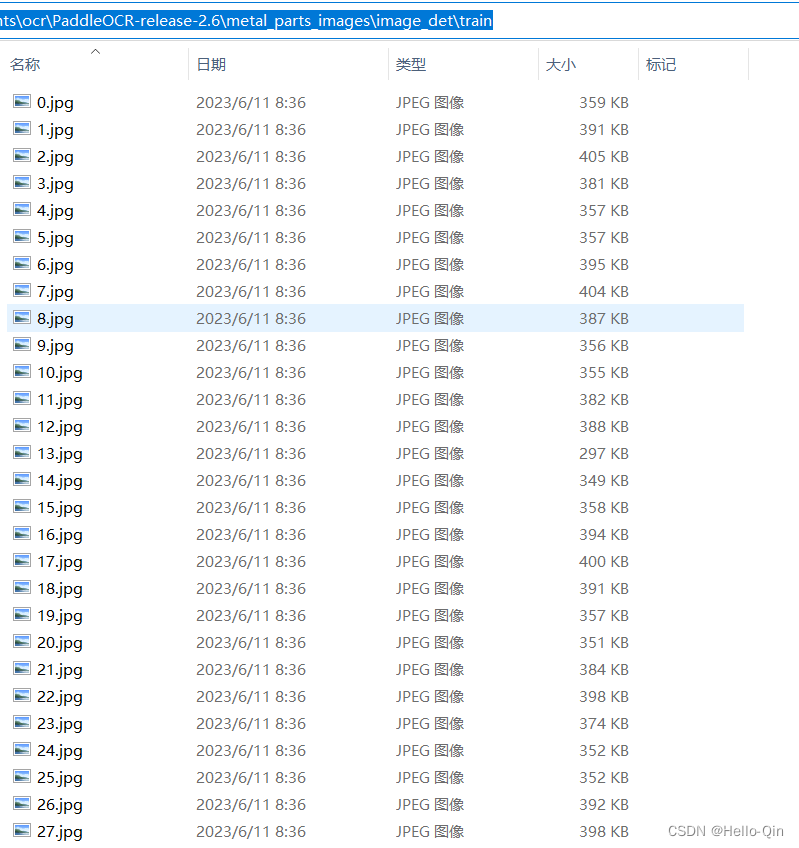
检测模型对应的训练和测试数据文件结构:
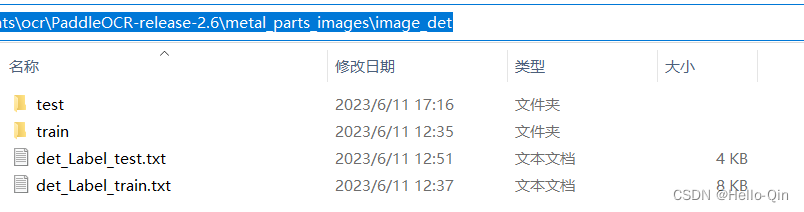
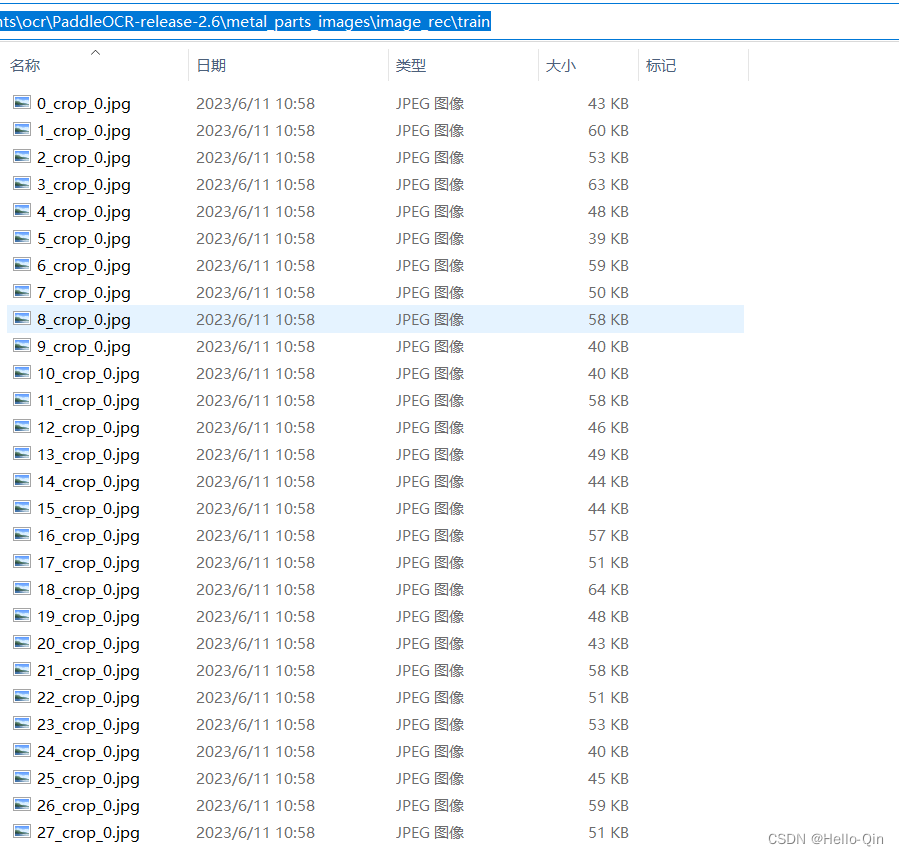
识别模型对应的训练和测试数据文件结构:

注意,label文件对应图片路径不要搞错。
三、训练文字检测模型
1.下载预训练文字检测模型
PaddleOCR-release-2.6目录下,新建pretrain_models文件夹。
下载预训练模型,解压到./pretrain_models文件夹。https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams
2.修改参数配置文件
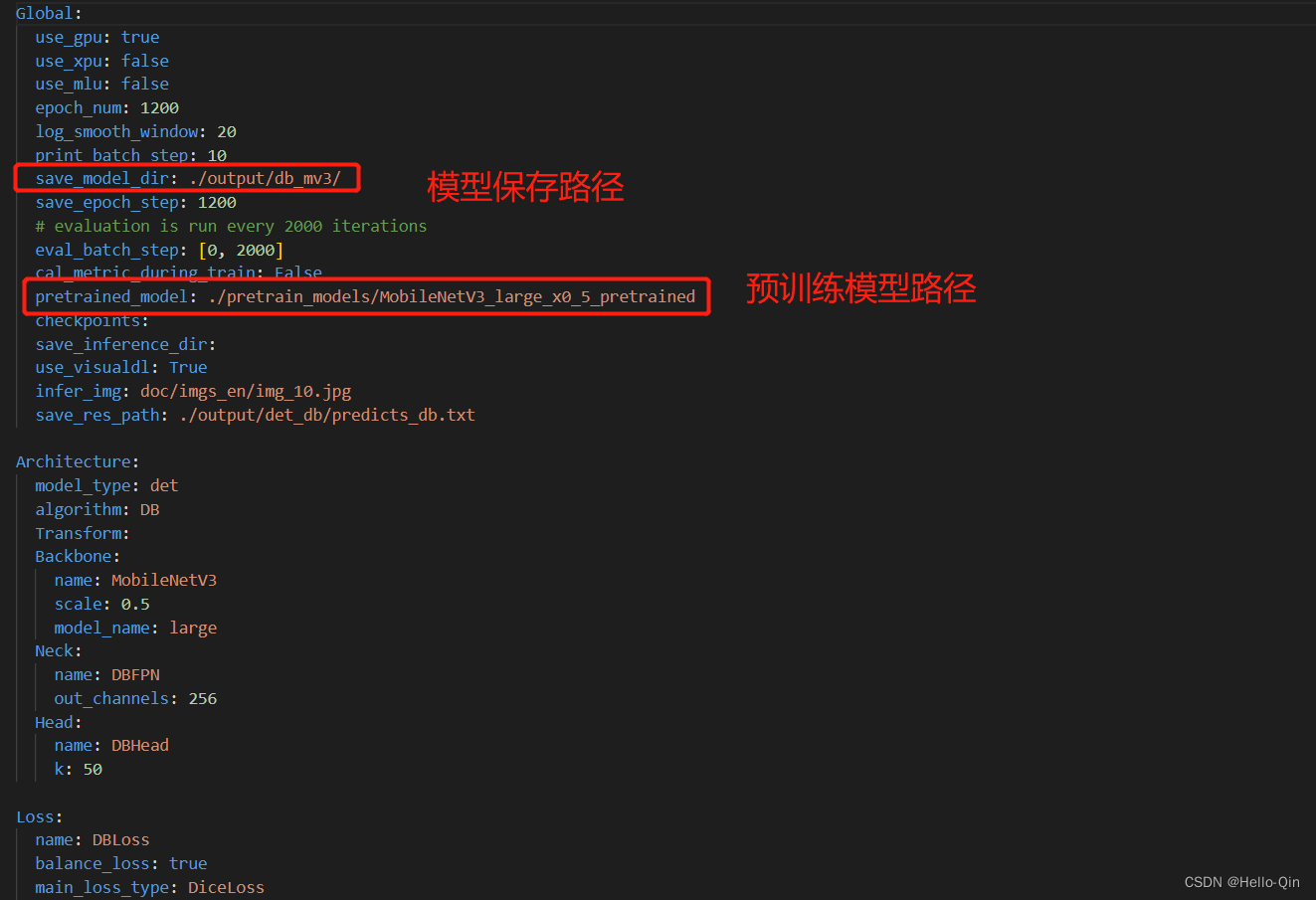
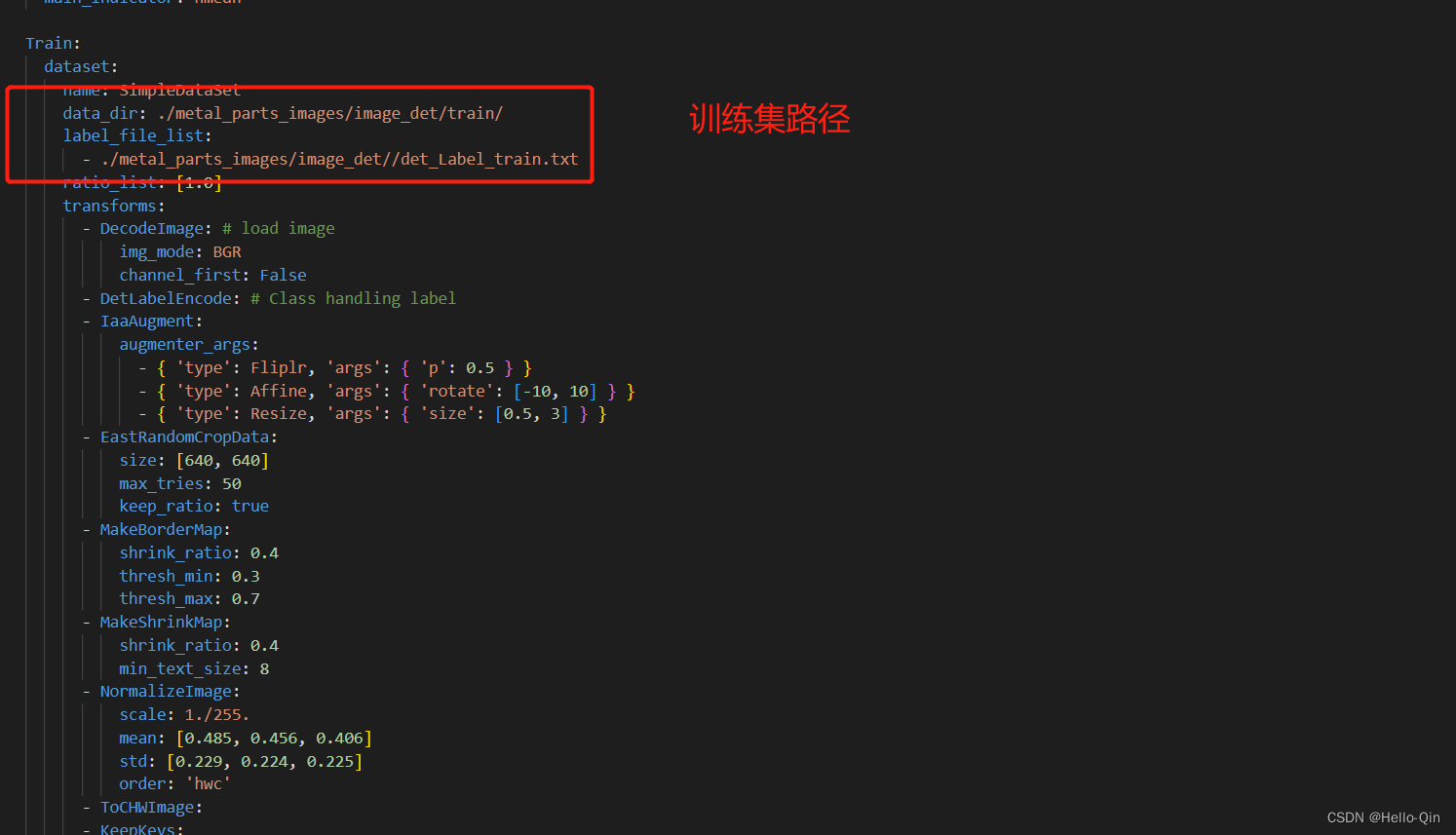
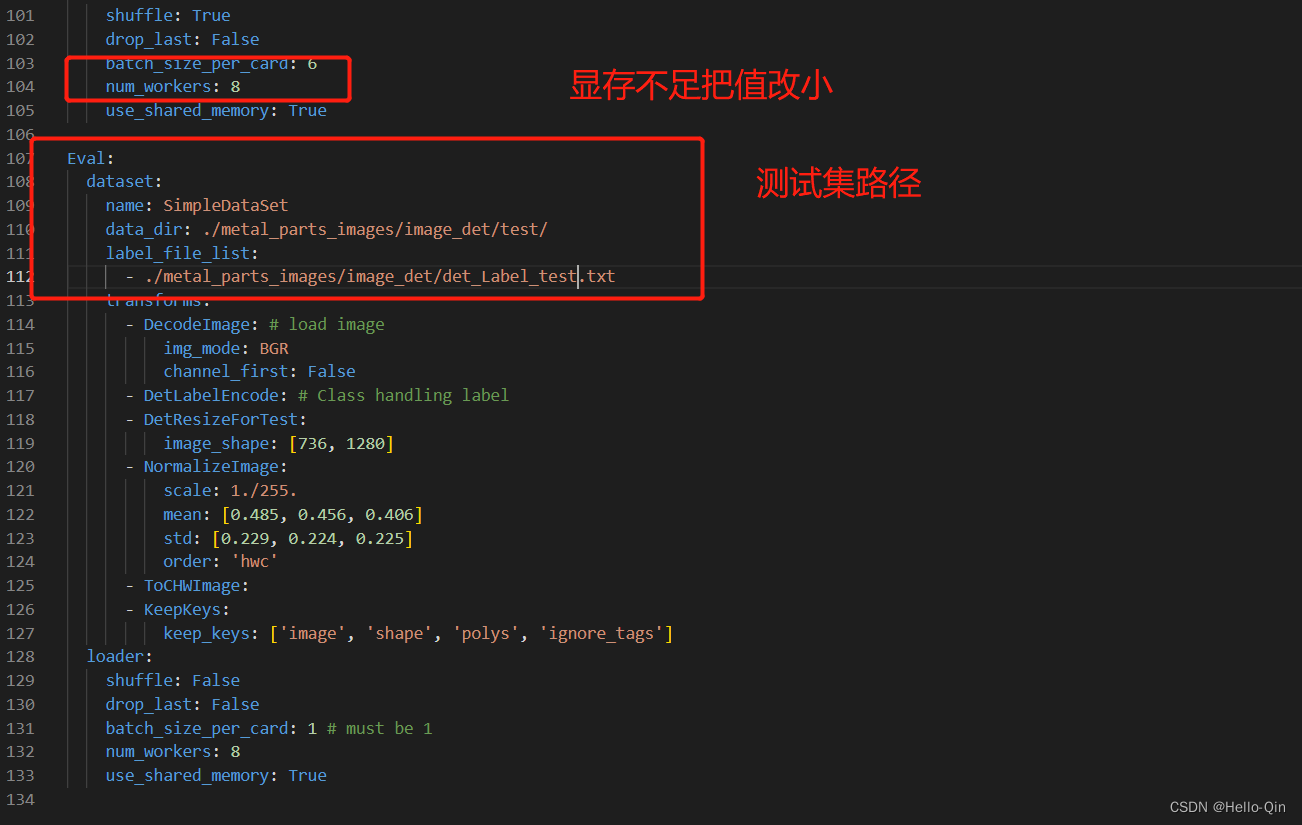
修改\PaddleOCR-release-2.6\configs\det目录下的det_mv3_db.yml,也可以复制一份,重新命名。
如果要可视化训练过程,把use_visualdl 改为True。
3.执行训练
开始训练,输入以下命令:
python tools/train.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained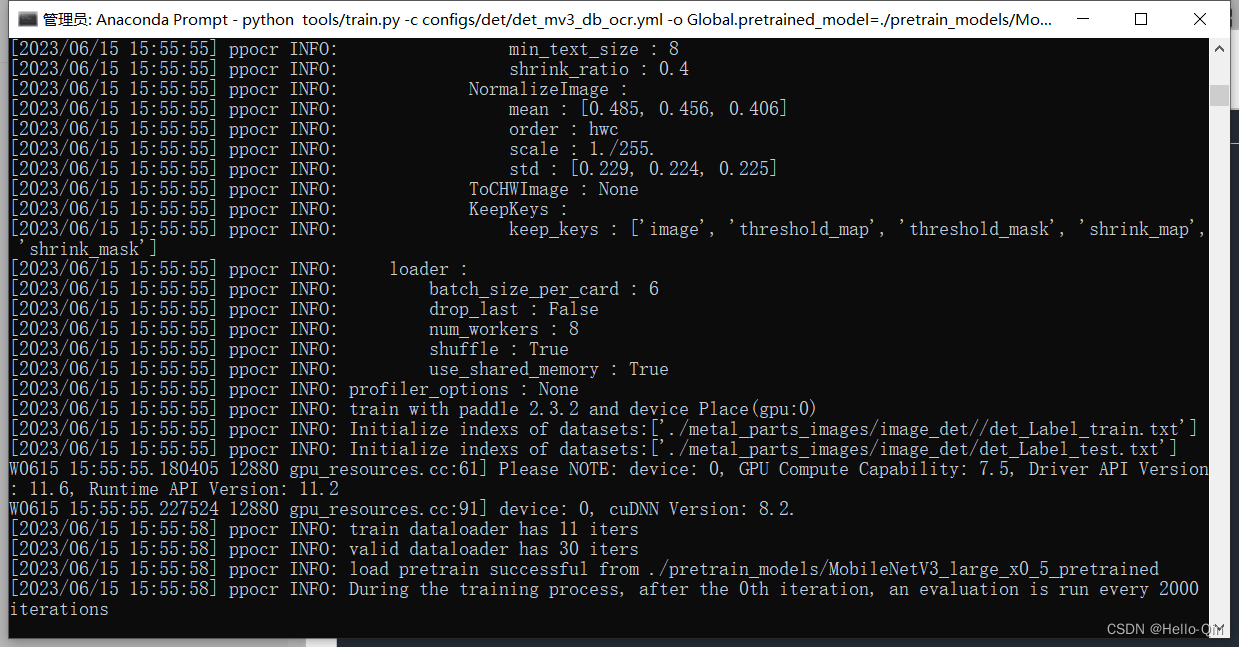
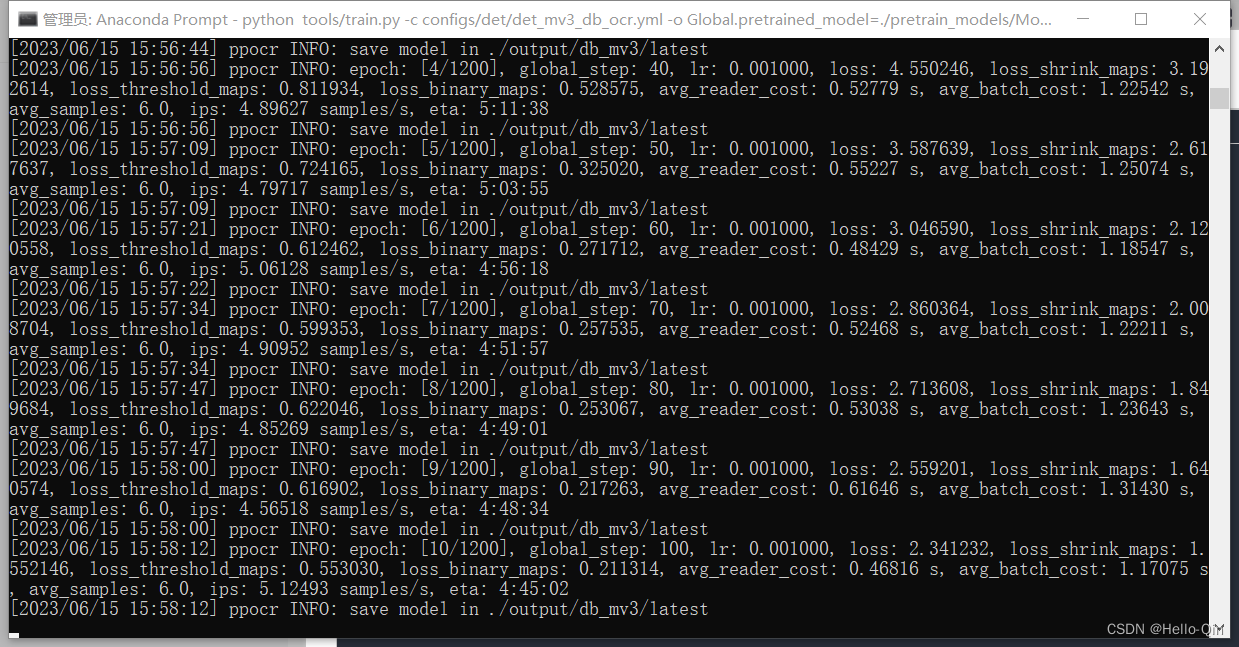
4.可视化训练过程
训练过程中,再开一个终端,输入以下命令可视化训练过程:
visualdl --logdir "./output/db_mv3" 
打开浏览器,输入http://localhost:8040/
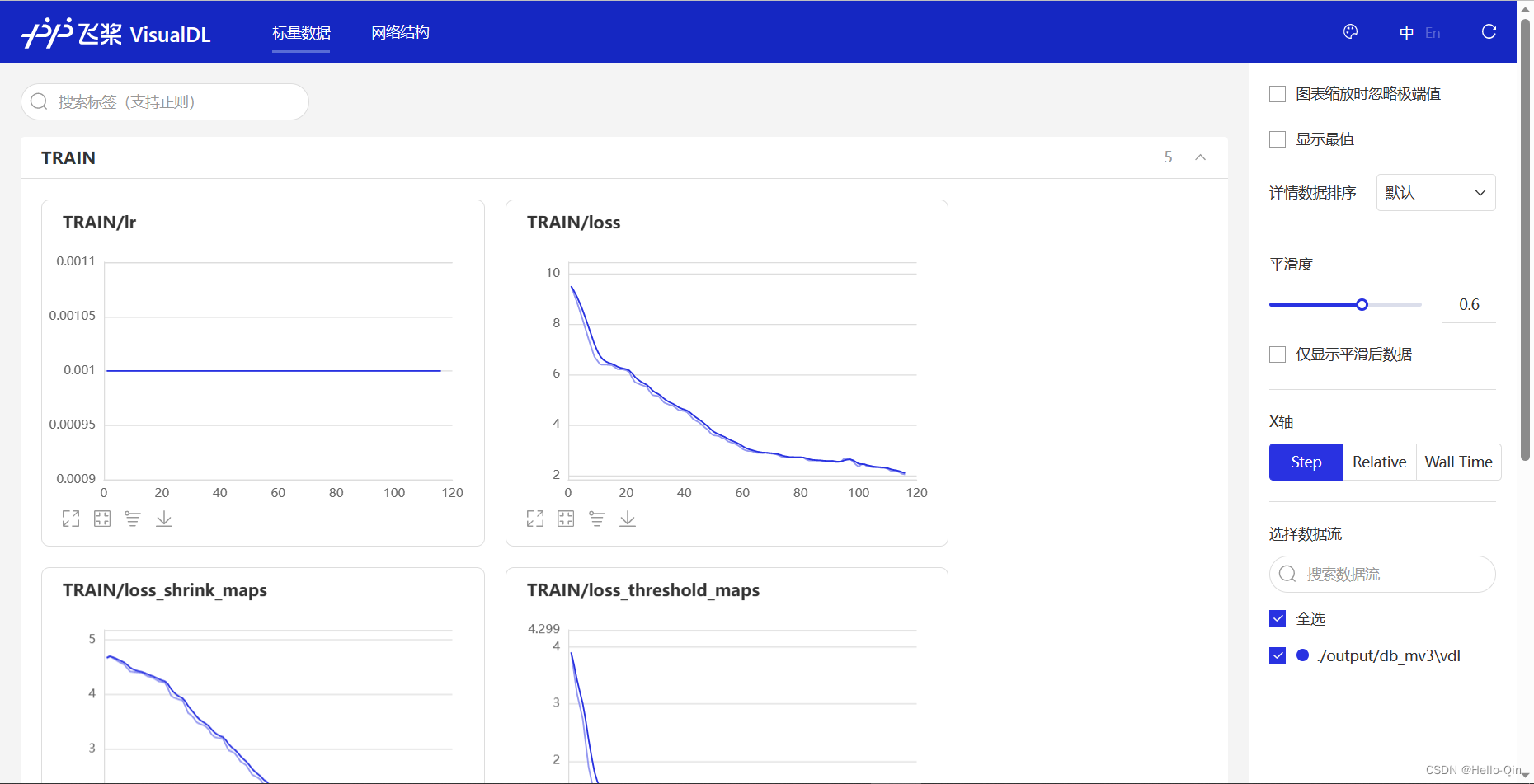
5.执行评估
评估模型,输入以下命令:
python tools/eval.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./output/db_mv3/best_accuracy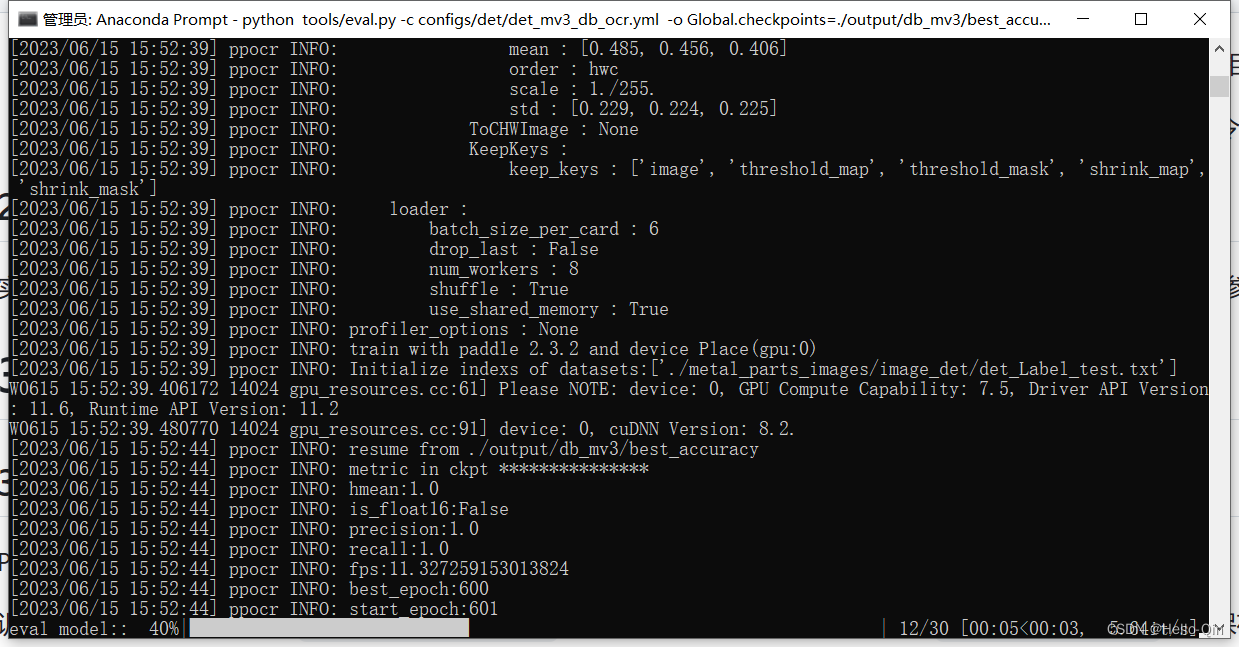
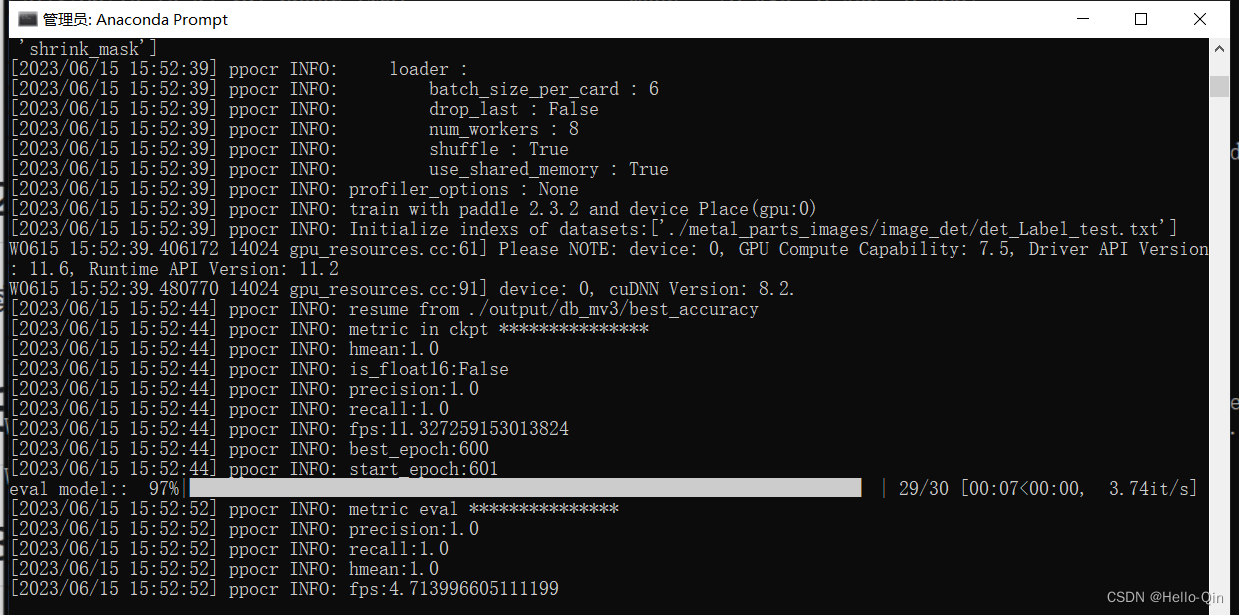
6.模型导出
输入以下命令
python tools/export_model.py -c configs/det/det_mv3_db_ocr.yml -o Global.pretrained_model=./output/db_mv3/best_accuracy Global.save_inference_dir=./inference/det_db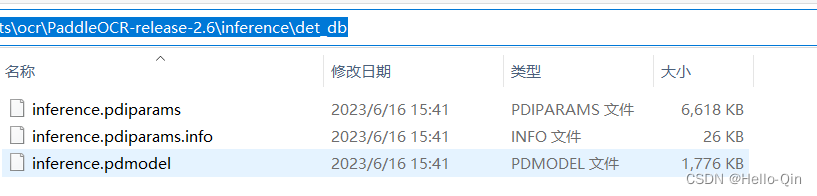
7.测试检测结果
输入以下命令:
python tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./inference/det_db/" --image_dir="./5.jpg" --use_gpu=True 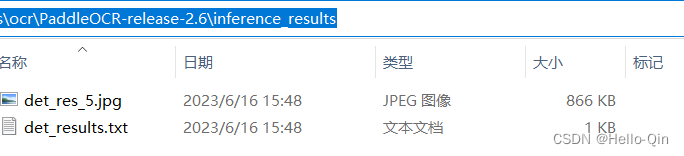
也可以把单张图片的路径改成文件夹路径,这样能够检测文件夹下所有图片。
四、训练文字识别模型
1.下载预训练文字识别模型
https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar
解压到pretrain_models文件夹
2.修改参数配置文件
.\configs\rec\PP-OCRv3\en_PP-OCRv3_rec.yml
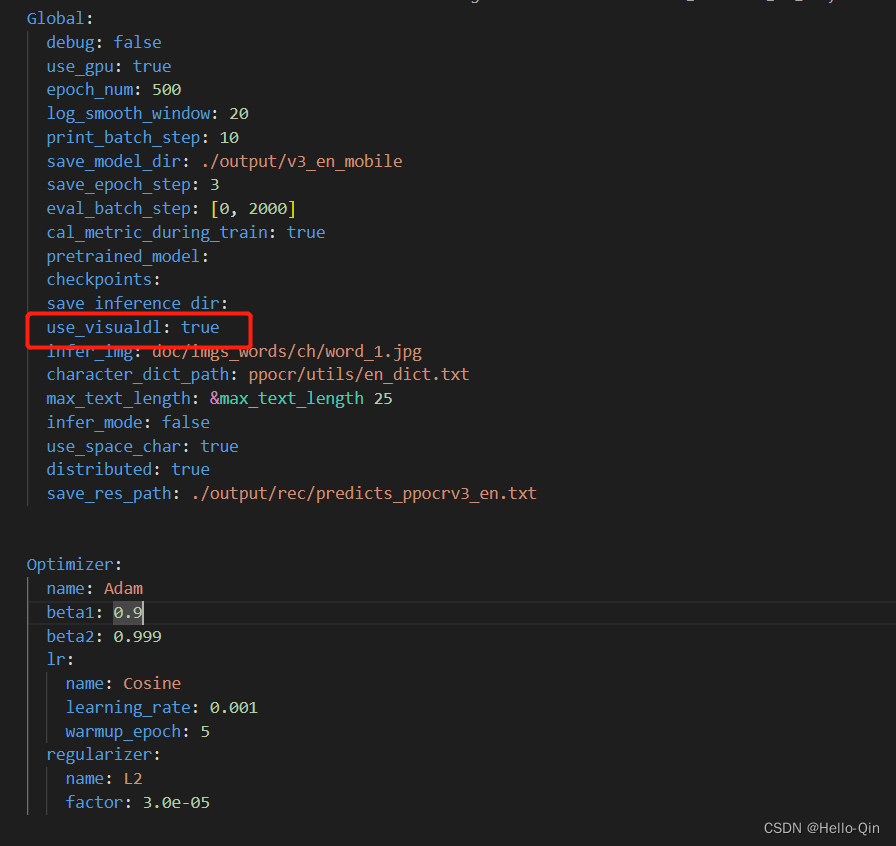
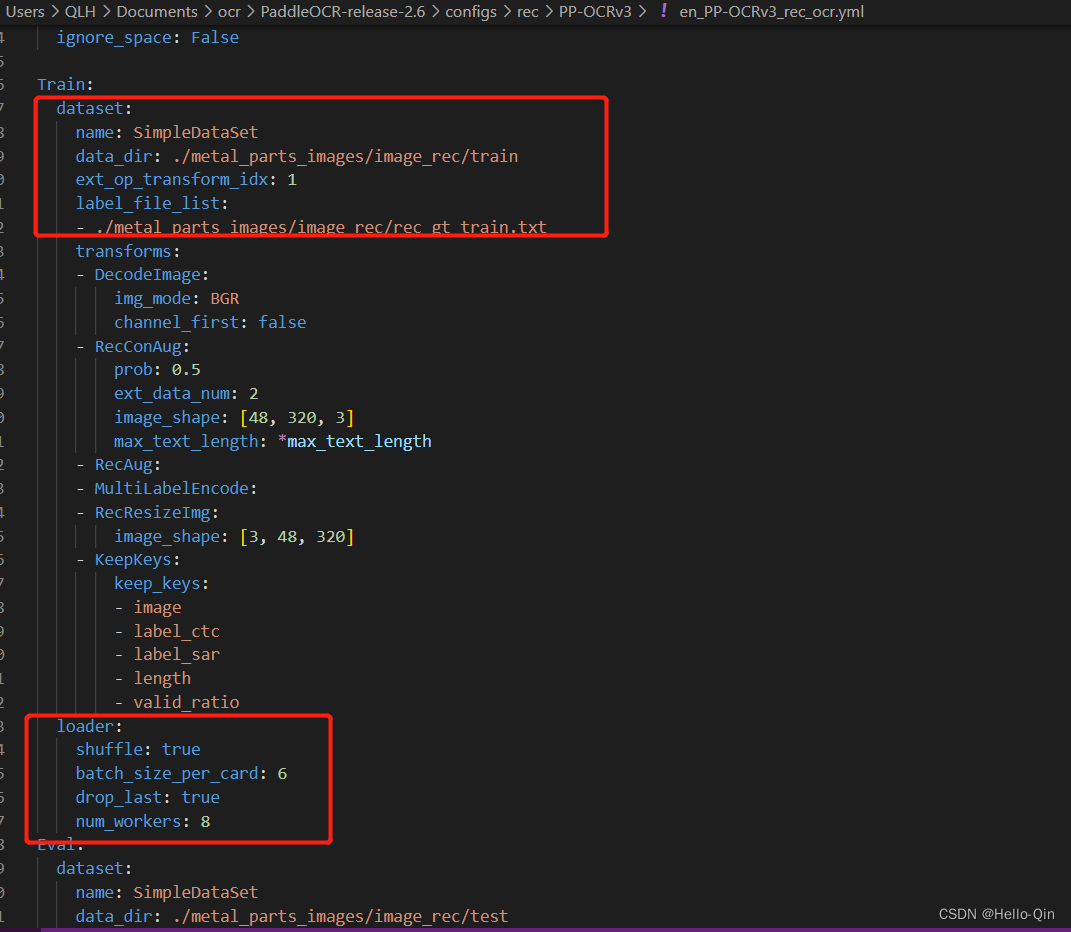
3.执行训练
python tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec_ocr.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy4.可视化训练过程
visualdl --logdir ./output/v3_en_mobile5.执行评估
python tools/eval.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec_ocr.yml -o Global.checkpoints=./output/v3_en_mobile/latest 6.测试识别结果
python tools/infer_rec.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec_ocr.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy Global.infer_img=./metal_parts_images/image_rec/test/0_crop_0.jpg














 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









