






Langchain-Chatchat源码模型加载中、可分为在线模型和离线模型的加载。
本次源码解读主要针对在线模型的、离线模型部署加载后续工作中使用到了再更新
Langchain-chatchat源码解读:将模型启动、聊天对话和知识库对话做了较为详细的源码解读。
在你看过一次后相信会有一个整体的理解。
但是 Langchain-Chatchat整个项目会涉及到跟多的知识点、如 Langchain-Chatchat、FastApi、Fastchat、甚至一些比较高级的python语法、因此需要所有的知识点面面俱到是不现实的。
但为了方便能对项目的源码解读、我会对使用到的关键知识进行补充、虽然不多、但都是一些使用频率高且核心的知识。
来看一下大致的框架:
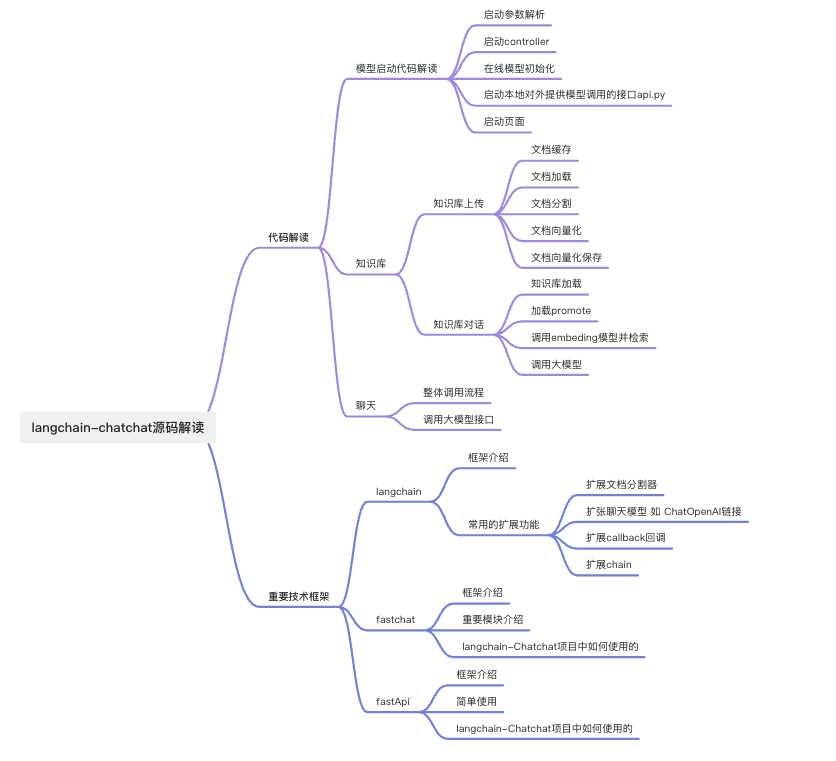
1. 模型启动
注:由于没有本地大模型、因此启动的配置都是选择在线模型(大语言模型和Embedding)
- 将
config目录下的配置复制一份、去掉后缀example - 修改
model_config.py配置
API是智谱AI API、具体注册及api key获取请前往 http://open.bigmodel.cn
LLM_MODELS = ["qwen-api","zhipu-api", "openai-api"]
ONLINE_LLM_MODEL = {
"openai-api": {
"model_name": "gpt-3.5-turbo",
"api_base_url": "https://api.openai.com/v1",
"api_key": "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",
"openai_proxy": "",
},
"zhipu-api": {
"api_key": "db3865ed46f05c5d2e92abc7dbe65d0d.yeGFgIna6alvZrpS",
"version": "glm-4",
"provider": "ChatGLMWorker",
},
"qwen-api": {
"version": "qwen-max",
"api_key": "sk",
"provider": "QwenWorker",
"embed_model": "text-embedding-v1"
}
}
选用的 Embedding 名称
embedding 模型名称
embed_model = "qwen-api"
安装依赖
pip install -r requirements.txt
启动
python startup.py -a --lite
2.模型启动脚本
langchain-chatchat 启动脚本为:startup.py
2.1 启动入口
if __name__ == "__main__":
create_tables()
if sys.version_info < (3, 10):
loop = asyncio.get_event_loop()
else:
try:
loop = asyncio.get_running_loop()
except RuntimeError:
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(start_main_server())
事件循环(Event Loop)是异步编程的核心概念、它允许程序在等待异步操作(如 I/O、网络请求等)的结果时继续执行其他任务。
在 Python 的 asyncio 库中、事件循环负责管理和执行异步任务、确保程序的高效运行。
具体来说,事件循环做以下几件事情:
- 维护一个或多个任务队列。
- 执行当前队列中的任务。
- 在任务等待外部事件(如数据到达)时暂停执行。
- 当外部事件触发(如数据到达)时、将相关任务放回队列继续执行。
在asyncio中、事件循环是通过 loop 对象来实现的。
你可以创建事件循环、运行和停止它、以及管理其内部的异步任务。这使得你可以在单个线程内并发地执行多个任务、而不需要多线程、这在 I/O 密集型应用中非常有用
补充一下操作系统IO密集型的知识及面试题:
1. 谈谈你对 I/O 多路复用的理解(重要)
分析
要说出没有 I/O 多路复用时、如果服务端要支持多个客户端 I/O 存在什么问题、然后再说出 I/O 多路复用是怎么解决的。
参考面试回答
I/O 多路复用是一种允许单个线程(或进程)同时监听多个文件描述符(通常是 socket)的技术。 它解决了传统阻塞 I/O 模型中、单个线程只能处理一个连接的瓶颈问题、从而提高了服务器的并发处理能力。
- 如果不使用 I/O 多路复用、服务端要并发处理多个客户端的 I/O
事件的话、需要通过创建子进程或者线程的方式来实现、也就是针对每一个连接的 I/O
事件要需要一个子进程或者线程来处理、但是随着客户端越来越多、意味着服务端需要创建更多的子进程或者线、这样对系统的开销太大了。
那么有了 I/O 多路复用就可以解决这个问题:
-
I/O 多路复用可以实现是多个 I/O 复用一个进程、也就是只需要一个进程就能监听多个文件描述符、并发处理多个客户端的 I/O 事件
进程可以通过通过操作系统提供的系统调用来实现 例如select、poll、epoll 这类 I/O
多路复用系统调用接口从内核中获取有事件发生的 socket 集合、当任何一个被监听的文件描述符准备好进行 I/O
操作(例如有数据可读、可以写入数据)时、I/O 多路复用机制会通知应用程序、对每一个 socket
事件进行处理。避免了为每个连接创建线程/进程的开销。 -
总结: I/O 多路复用的核心思想是将多个 I/O操作的阻塞等待交给操作系统内核来处理。 应用程序只需要关注哪些 socket 连接上有事件发生、而不需要阻塞等待每个连接。Redis 单线程也能做到高性能的原因、也跟 I/O 多路复用有关系。
2. select、poll、epoll 有什么区别?(重要)
分析
select:调用开销大(需要复制集合)、集合大小有限制、需要遍历整个集合找到就绪的描述符poll:poll 采用数组的方式存储文件描述符、没有最大存储数量的限制、其他方面和 select 没有区别、调用开销大(也需要复制集合)去epoll:调用开销小(不需要复制)、集合大小无限制、采用回调机制、不需要遍历整个集合
select、poll都是在用户态维护文件描述符集合、因此每次需要将完整集合传给内核
epoll由操作系统在内核态中维护文件描述符集合、因此只需要在创建的时候传入文件描述符。
回答
select 和 poll 内部都使用线性结构(例如数组或链表)来存储进程所关注的 Socket 集合。首先需要把关注的 Socket 集合通过 select/poll 系统调用从用户态拷贝到内核态。 内核会遍历这个 Socket 集合、检查每个 Socket 上是否有事件发生。 如果某个 Socket 上有事件(例如可读或可写)、内核会标记该 Socket 的状态。 最后内核会将整个 Socket 集合从内核态拷贝回用户态、应用程序需要再次遍历这个集合、找到被标记为可读或可写的 Socket、并进行相应的处理。
很明显发现select 和 poll的缺陷在于、当客户端越多、也就是 Socket 集合越大、Socket 集合的遍历和拷贝会带来很大的开销、epoll 通过两个方面解决了 select/poll 的问题。
- epoll 在内核里使用
【红黑树】来关注进程所有待检测的 Socket、红黑树是个高效的数据结构、增删改一般时间复杂度是 O(logn)、通过对这棵黑红树的管理、不需要像 select/poll 在每次操作时都传入整个 Socket 集合、只需要在添加或删除 Socket 时更新红黑树、避免了重复的数据拷贝。减少了内核和用户空间大量的数据拷贝和内存分配。 - epoll 采用事件驱动的方式。 内核维护一个就绪链表、只记录发生事件(例如可读或可写)的 Socket。 当有事件发生时、内核会将相应的 Socket 添加到就绪链表中。 应用程序只需要从就绪链表中获取事件,而无需像
select 和 poll那样遍历整个Socket集合。 这大大提高了检测效率,尤其是在只有少数 Socket 准备就绪的情况下。
ok让我们继续分析源码:
loop.run_until_complete(main()) 和 asyncio.run(main()) 都用于运行协程,但它们之间有一些区别:
loop.run_until_complete(main()):
○ 这是一个低级别的 API,通常用于需要更精细控制事件循环行为的情况。
○ 它会阻塞当前线程,直到传递给它的协程完成。
○ 你可以多次调用run_until_complete来运行不同的协程、但它们会共享同一个事件循环。asyncio.run(main()):
○ 这是一个高级别的 API,从 Python 3.7 开始引入。
○ 它会自动创建一个新的事件循环,并在协程完成后关闭它。
○ 你不需要显式地管理事件循环,因此更易于使用。
○ 这是大多数应用程序开发者的首选方式。
总之,如果你只需要运行一个协程并且不需要更多的控制,那么使用 asyncio.run(main()) 是最好的选择。如果你需要更细粒度的控制,可以使用 loop.run_until_complete(main())
让我们通过一个复杂的案例来对比 loop.run_until_complete(main()) 和 asyncio.run(main()) 的使用。了解loop.run_until_complete(main())为什么能更精准的控制。
假设我们有一个网络应用、需要启动一个服务器、同时还要定期检查服务器的状态。我们希望在启动服务器后立即开始状态检查、并且在服务器运行期间定期进行检查

















 1592
1592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









