







python爬虫学习笔记3.2-urllib和request练习
一、urllib练习
1.百度贴吧案例
需求
输入贴吧名字,下载查询到的html页面。
分析
手动测试查询流程
进入百度贴吧,输入海贼王查询,点击一个页面右键下载即可。
用代码的方式编写此过程即是找到这个页面的url,请求这个url,获取内容,并保存。因此关键就在于如何找到这个url
观察页面
查询关键字海贼王,结果页面显示如下,观察当前页面,发现有2个地方比较特殊,url部分和分页部分。
分析特殊部分
https://tieba.baidu.com/f?
url中的固定部分
kw
根据前面的知识,kw=%???是’海贼王’的十六进制编码,此处的’海贼王’可以用一个变量表示
pn
分别点击第2,3页,发现url有下列变化,pn在以(n-1)*50递增,按照规律第一页应该pn=0,查询一下和最初显示的页面相同。
https://tieba.baidu.com/f?ie=utf-8&kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&fr=search
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=50
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=100
# 猜测第一页pn=0
https://tieba.baidu.com/f?kw=%E6%B5%B7%E8%B4%BC%E7%8E%8B&ie=utf-8&pn=0
# 总结规律url的拼接
pn = (n-1)*50
baseurl = 'https://tieba.baidu.com/f?'
url = baseurl + kw + '&pn=' + str(pn)
步骤
- 主体架构
- 拼接url发起请求,获取响应
- 写入文件
代码
import urllib.request
import urllib.parse
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36','Cookie':'BIDUPSID=23F0C104655E78ACD11DB1E20FA56630; PSTM=1592045183; TIEBA_USERTYPE=45a1bae36dc6696040e230ee; BAIDUID=23F0C104655E78AC9F0FB18960BCA3D3:SL=0:NR=10:FG=1; BDUSS=ldxR1FyQ2FEaVZ5UWFjTDlRbThVZHJUQTY1S09PSU81SXlHaUpubVpEY0FMakZmRVFBQUFBJCQAAAAAAAAAAAEAAADzvSajSjdnaGgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAChCV8AoQlfb; TIEBAUID=524dbb48e125ba59527aac97; BDUSS_BFESS=ldxR1FyQ2FEaVZ5UWFjTDlRbThVZHJUQTY1S09PSU81SXlHaUpubVpEY0FMakZmRVFBQUFBJCQAAAAAAAAAAAEAAADzvSajSjdnaGgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAChCV8AoQlfb; bdshare_firstime=1598269131458; Hm_lvt_287705c8d9e2073d13275b18dbd746dc=1598269132; MCITY=-158%3A; STOKEN=cbc451dc794ed6487c35c551af2ca5d54091f34c2442a1c32fde578f244fb763; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=7; BCLID=9680358736405562036; BDSFRCVID=YCIOJeCin4S2BnTr7aHqhLyxn2KX8jRTH6eCU5vSD8fFhSugyYuoEG0PVf8g0KubhN5xogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF=tJPH_IIKfII3fP36qRbBb-JH-fTB-4n-HD7yWCvw0hTcOR5JMtIM0TDYhROHt-o7-CbrX4n8tqvibbc-3MA-bftAjqjg0Tvh3DbgLR3Xy45osq0x0hjte-bQypoaaUCtMIOMahv1al7xO-JoQlPK5JkgMx6MqpQJQeQ-5KQN3KJmfbL9bT3tjjISKx-_t6DOJbnP; H_PS_PSSID=32757_32617_1428_32844_7544_31660_32723_32230_7517_32116_32718; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1600675770,1600675812,1600872339,1602504063; st_key_id=17; 2737225203_FRSVideoUploadTip=1; Hm_lpvt_98b9d8c2fd6608d564bf2ac2ae642948=1602505620; st_data=2b0ded14593ade58fc1a8d50a2f8ad7928c0bef12b48ebbd60bb645cad4e10201acccc373eb356fdb56f6b0ab617ed5e9d082b71565c956d9457486ef5e25c9a41e1b40af6e8a9d866b3c7a8d4d97dc777b505aa5d3d8bb075e6c986c224472b12b37c80b76e6e1a7db114cfa47189ff53f19ad35b79cc1a1bc8ecc582d370da86edef6d209dfe8a4ba628a4880dd0fd; st_sign=7d6a3224'
}
# 主体架构
name = input('请输入贴吧的名字:')
begin = int(input('请输入起始页:'))
end = int(input('请输入结束页:'))
kw = {'kw':name}
kw = urllib.parse.urlencode(kw)
# 拼接url 发请求,获响应
for i in range(begin,end+1):
pn = (i-1)*50
# print(pn) https://tieba.baidu.com/f?kw=%???&pn=0
baseurl = 'https://tieba.baidu.com/f?'
url = baseurl + kw + '&pn=' + str(pn)
# print(url)
# 发起请求
req = urllib.request.Request(url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
# print(html)
# 写入文件
filename = '第'+ str(i) + '页.html'
with open(filename,'w',encoding='utf-8') as f:
# print('正在爬取第%d页'%i)
f.write(html)
总结
- 测试流程
- 观察页面
- 总结规律
- 编写代码
2.百度贴吧其他实现方式
需求
对百度贴吧案例进行重构
分析
观察代码发现读取页面和写入文件部分是可以复用的,不需要重复性编写细节部分调用一个读取和写入文件的端口即可。
有2种方式,分别是函数和类的方式。
代码
函数
import urllib.request
import urllib.parse
# 读取页面
def readPage(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
# 发起请求
req = urllib.request.Request(url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
return html
# 写入文件
def writePage(filename,html):
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
print('写入成功')
# 主函数
def main():
name = input('请输入贴吧的名字:')
begin = int(input('请输入起始页:'))
end = int(input('请输入结束页:'))
kw = {'kw': name}
kw = urllib.parse.urlencode(kw)
for i in range(begin, end + 1):
pn = (i - 1) * 50
baseurl = 'https://tieba.baidu.com/f?'
url = baseurl + kw + '&pn=' + str(pn)
# 调用函数
html = readPage(url)
filename = '第' + str(i) + '页.html'
writePage(filename,html)
if __name__ == '__main__':
main()
类
import urllib.request
import urllib.parse
class BaiduSpider():
# 把常用的不变的放到init方法里面
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
self.baseurl = 'https://tieba.baidu.com/f?'
def readPage(self,url):
req = urllib.request.Request(url, headers=self.headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
return html
def writePage(self,filename,html):
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
print('写入成功')
def main(self):
name = input('请输入贴吧的名字:')
begin = int(input('请输入起始页:'))
end = int(input('请输入结束页:'))
kw = {'kw': name}
kw = urllib.parse.urlencode(kw)
for i in range(begin, end + 1):
pn = (i - 1) * 50
# baseurl = 'https://tieba.baidu.com/f?'
url = self.baseurl + kw + '&pn=' + str(pn)
# 调用函数
html = self.readPage(url)
filename = '第' + str(i) + '页.html'
self.writePage(filename, html)
if __name__ == '__main__':
# 我们要调用main()方法 就需要实例化类
spider = BaiduSpider()
spider.main()
3.post请求实现有道翻译
需求
本地输入单词获取有道翻译
前提知识
数据提取
从相应url等获取我们想要的数据的过程
数据分类
- 非结构化数据:HTML
- 正则表达式、xpath
- 结构化数据:json、xml
- 处理方法:转化为python数据类型
数据提取之json
使用json库可以轻松将json数据转化为python内建数据类型。
JSON是一种轻量级的数据交换格式,方便程序员阅读和编写同时也方便机器的解析和生成。适用于数据交互,eg:网站前台和后台的数据交互。
JSON中的字符串都是双引号,eg:{"type":"EN2ZH_CN","errorCode":0,"elapsedTime":1,"translateResult":[[{"src":"nih","tgt":"国家卫生研究院"}]]}
JSON —json.loads()–> python
字符串 <–json.dumps()— 数据类型
包含JSON —json.load()—> python
类文件对象 <–json.dump()---- 数据类型
分析
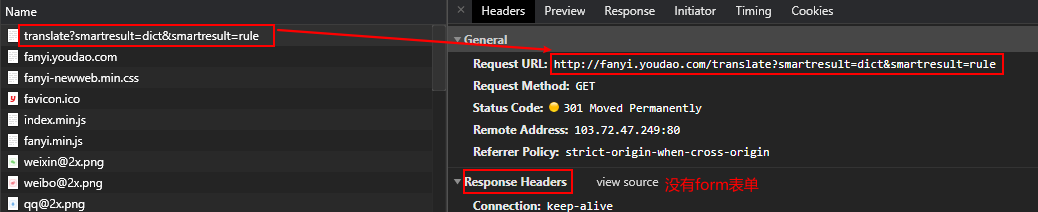
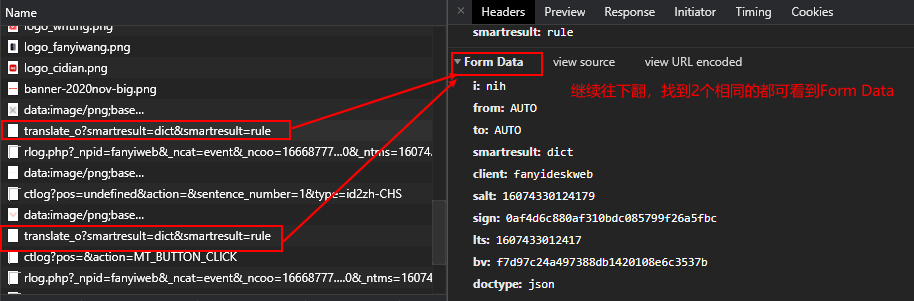
POST请求需要获取Form Data。
获取Form Data
点击有道翻译,右键检查,找到下列图片,看到是POST请求,有Form Data。

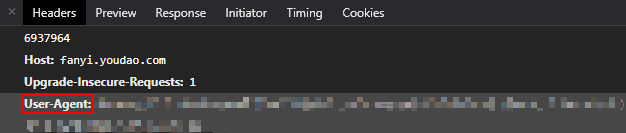
获取User-Agent
User-Agent的参数一般是用于模拟浏览器,欺骗服务器,获取和浏览器一致的内容。
转换数据类型
有了Form Data和headers就可以发起请求,获取数据,当打印获取的内容却发现不是我们想要的结果,为什么会这样?打印一下html的类型
<class 'str'> {"type":"EN2ZH_CN","errorCode":0,"elapsedTime":1,"translateResult":[[{"src":"nih","tgt":"国家卫生研究院"}]]}
这是json类型的字符串,是不是有点眼熟,像python中的字典,使用json把json类型的字符串转换成Python数据类型的字典,就可以使用字典得到我们想要的’国家卫生研究院’.
步骤
- 获取Form Data和headers
- 请求url
- 转换数据类型
- 输出结果
代码
import urllib.request
import urllib.parse
import json
# 请输入你要翻译的内容
key = input('请输入你要翻译的内容:')
# 拿到form表单的数据
data = {
'i': key,
'from': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15880623642174',
'sign': 'c6c2e897040e6cbde00cd04589e71d4e',
'ts': '1588062364217',
'bv': '42160534cfa82a6884077598362bbc9d',
'doctype': 'json',
'version': '2.1',
'keyfrom':'fanyi.web',
'action': 'FY_BY_CLICKBUTTION'
}
data = urllib.parse.urlencode(data)
data = bytes(data,'utf-8')
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
req = urllib.request.Request(url,data=data,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
# print(type(html),html)
# print(html)
'''
{"type":"ZH_CN2EN","errorCode":0,"elapsedTime":1,"translateResult":[[{"src":"你好","tgt":"hello"}]]}
'''
# 把json类型的字符串转换成Python数据类型的字典
r_dict = json.loads(html)
# print(type(r_dict),r_dict)
# [[{"src":"你好","tgt":"hello"}]]
# [{"src":"你好","tgt":"hello"}]
# {"src":"你好","tgt":"hello"}
# 'hello'
r = r_dict['translateResult'][0][0]['tgt']
print(r)
总结
- POST请求找Form Data
- 尽量找到返回json数据的URL
二、requests练习
1.requests实现有道翻译
需求
requests实现有道翻译
分析
- post请求查找form data
- 使用User-Agent
- 解码
步骤
- 搭建主框架
- 分别获取data,url和headers
- 请求url,打印数据
代码
import requests
import json
key = input('请输入您要翻译的内容:')
data = {
'i': key,
'from': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '15880623642174',
'sign': 'c6c2e897040e6cbde00cd04589e71d4e',
'ts': '1588062364217',
'bv': '42160534cfa82a6884077598362bbc9d',
'doctype': 'json',
'version': '2.1',
'keyfrom':'fanyi.web',
'action': 'FY_BY_CLICKBUTTION'
}
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
res = requests.post(url,data=data,headers=headers)
res.encoding = 'utf-8'
html = res.text
print(html)
总结
代码框架
import requests
import json
url = ''
data = ''
headers = {'User-Agent':''}
res = requests.post(url,data=data,headers=headers)
res.encoding = 'utf-8'
html = res.text
#print(html)
2.处理不信任证书的网站
需求
什么是SSL证书?
SSL证书是数字证书的⼀种,类似于驾驶证、护照和营业执照的电子副本。
因为配置在服务器上,也称为SSL服务器证书。SSL 证书就是遵守 SSL协
议,由受信任的数字证书颁发机构CA,在验证服务器身份后颁发,具有服务
器身份验证和数据传输加密功能
测试网站 https://inv-veri.chinatax.gov.cn/
分析
因为需要对网站的SSL证书进行验证,所以verify这个参数默认值为true,所以在处理不信任证书的网站,将这个参数=false即可。
代码
import requests
url = 'https://inv-veri.chinatax.gov.cn/'
res = requests.get(url,verify=False)
print(res.text)
总结
verify=False














 2562
2562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









