






distinct
语法:select distinct 字段1,字段2,...from tab
① 用在所有字段前,对所有字段起作用;
② 对所用字段起作用的意思是只有distinct后面跟的所有字段都相同时才会去重;
③ 当distinct后跟多字段时,无法对单一字段进行去重。
group by
语法:select * from tab group by 字段
① group by去重是针对select后跟的所有字段,而不是针对group by后跟的字段进行去重(MySQL5.7以后如果select后的字段没在group by中出现会报错,也可以修改全局系统变量sql_mode去掉only_full_group_by)。
count()
① count(*),查询整行,不关心某行中有的字段值为null,
② count(1),与count(*)相同,
③ count(字段1),如果字段1为null则不会计数,
③ count(distinct 字段1),统计不重复不为null的字段1行数。
举例
表emp如下:

SELECT DAY
,NAME
FROM emp
GROUP BY DAY,NAME运行结果如下:
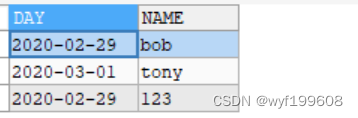
以上结果可以发现2020-02-29 bob这条语句被过滤了。
SELECT DAY
,NAME
,COUNT(1)
FROM emp
GROUP BY DAY,NAME结果如下:
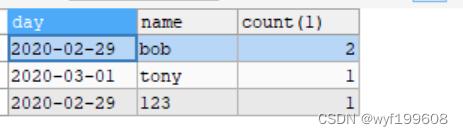
这个语句执行出来更能明确的看到确实有一条数据被去重了。
以下几个语句证明了count(distinct 字段1)的作用:
SELECT DAY
,COUNT(DISTINCT DAY)
FROM emp
GROUP BY DAY
SELECT DAY
,COUNT(DISTINCT NAME)
FROM emp
GROUP BY DAY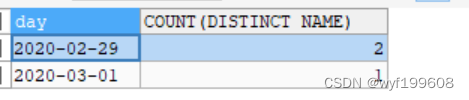
将表emp改成如下:
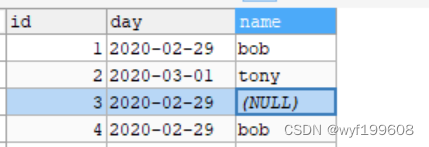
SELECT day
,COUNT(DISTINCT NAME)
FROM emp
GROUP BY DAY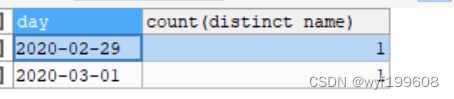















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









