







文章目录
BFS实际应用题[思维扩展]
BFS,即广度优先搜索(Breadth-First-Search),是一种计算无权最短路径的常见算法。
注:本文的期望读者最好拥有基础的BFS使用能力,了解二叉树层序遍历。
BFS的算法流程通常为:
-
将起始状态存入队列,并利用一个集合存储所有已经遍历到的状态。
-
每一轮都将当前队列中已有的size个状态全部取出,并尝试遍历该状态能够到达的新状态(即没有出现在集合中的状态)。
同时将这些新状态存入队列。
-
如果本轮从队列中取出的状态中存在我们需要的目标状态,那么BFS结束。到目前为止进行的轮数就是最短路径的长度。
如果不存在目标状态,则重复第二步。
能够使用BFS解决的问题,通常意指:计算一个状态到另一个状态的最小转换步数。
LeetCode 127. 单词接龙
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> … -> sk:
每一对相邻的单词只差一个字母。
对于 1 <= i <= k 时,每个 si 都在 wordList 中。注意, beginWord 不需要在 wordList 中。
sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。示例 :
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] 输出:5 解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
常规的BFS思路
- 建立一个队列维护每一步转换可能的单词有哪些
- 每一步取出当前队列所有的单词(记录当前队列的长度sz,循环sz次即可)
- 对于每一个单词,若它是endWord,则返回当前已用的转换步数(即最短序列长度)
- 否则,我们仅修改它的某一个字符,即:遍历该单词长度次,每次用’a’到’z’中的一个代替它
- 将单词转换后,检查转换结果是否是wordList中提供的单词,并且它之前并没有被用过(如果之前出现过,说明能够通过更少的步数到达该状态)
- 若满足条件,则将该单词push到队列,并标记它已被使用
class Solution
{
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList)
{
unordered_set<string> flg; // 用来标记某一单词是否已被使用
unordered_set<string> dic; // 用于快速地查找某一单词是否在wordList中
for (string& e : wordList)
{
dic.insert(e);
}
queue<string> q;
int step = 1;
q.push(beginWord);
while (!q.empty())
{
int sz = q.size();
// 取出当前队列中的所有单词
// 并将所有可能的转换单词push到队列中
while (sz--)
{
string wd = q.front();
if (wd == endWord)
return step;
q.pop();
// 遍历该单词所有可能的转换
for (int i = 0; i < wd.size(); ++i)
{
string tmp = wd;
for (char ch = 'a'; ch <= 'z'; ++ch)
{
tmp[i] = ch;
// 该转换单词存在于字典中,则将它入队
if (dic.find(tmp) != dic.end()
&& flg.find(tmp) == flg.end())
{
q.push(tmp);
flg.insert(tmp);
}
}
}
}
++step;
}
return 0; // 不存在从beginWord到endWord的转换序列
}
};
双向BFS思路
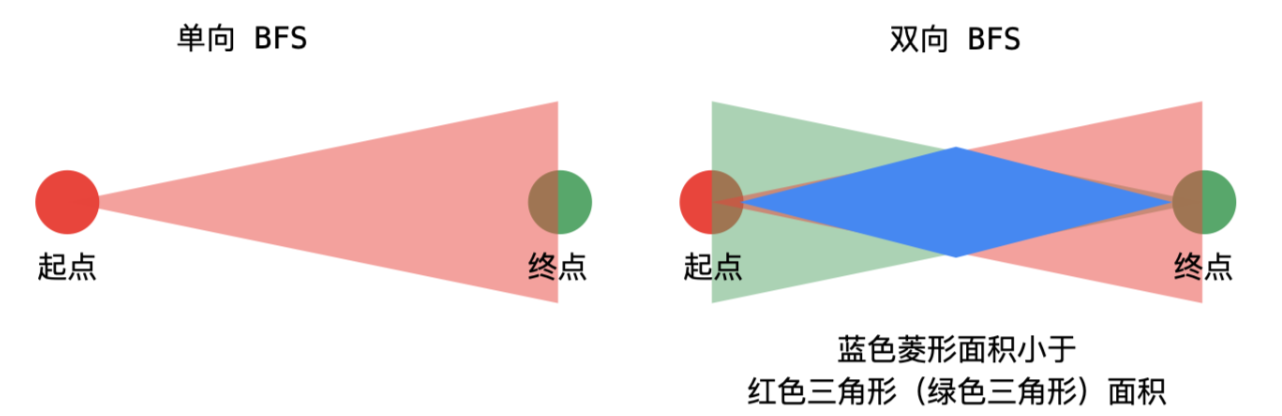
常规BFS都是从起始状态出发,持续搜索,直到目标状态。但是我们分析一下这样的弊端:
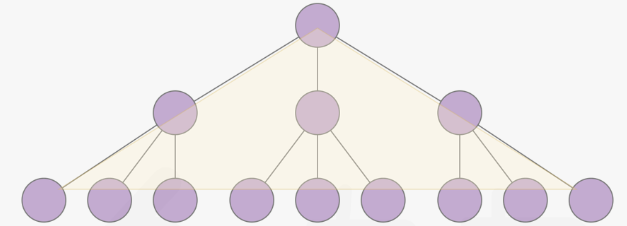
当前层的某一个状态可以衍生出新的状态(假定平均为m个),这就意味着如果多次搜索无果,那么BFS进行step次时,队列中至少会有mstep个状态。
因此,当数据量比较大时,常规的BFS(也可以说是单向BFS)大概率会超时。
双向BFS的不同之处在于:
- 双向BFS尝试从起点走向终点,以及从终点走向起点。
- 简单来说,维护两个队列q1与q2:q1用来存储起点到终点的每一步的可能状态,q2用来存储终点到起点的每一步的可能状态。
- 同时,使用两个集合s1和s2:分别存储q1与q2中出现过的状态。
- 为了减少搜索的次数,我们每次选择较小的那个队列进行BFS。
- 如果在对q1进行BFS的过程中发现,当前的状态出现在s2中,说明我们的双向BFS出现的交汇!对q2进行BFS也是同理。
class Solution {
public:
bool bfs(queue<string>& q1, unordered_set<string>& words, unordered_set<string>& s1,
unordered_set<string>& s2)
{
int sz = q1.size();
while (sz--)
{
string str = q1.front();
q1.pop();
for (int i = 0; i < str.size(); ++i)
{
char c = str[i];
for (char j = 'a'; j <= 'z'; ++j)
{
str[i] = j;
if (s1.find(str) == s1.end() && words.find(str) != words.end())
{
if (s2.find(str) != s2.end())
return true;
s1.insert(str);
q1.emplace(str);
}
}
str[i] = c;
}
}
return false;
}
int ladderLength(string beginWord, string endWord, vector<string>& wordList)
{
unordered_set<string> words;
for (auto& word : wordList)
{
words.insert(word);
}
if (words.find(endWord) == words.end())
return 0;
queue<string> q1;
queue<string> q2;
unordered_set<string> s1;
unordered_set<string> s2;
q1.emplace(beginWord);
s1.insert(beginWord);
q2.emplace(endWord);
s2.insert(endWord);
int step = 0;
while (!q1.empty() && !q2.empty())
{
++step;
// 选择较少的那个队列进行BFS
if (q1.size() <= q2.size())
{
if (bfs(q1, words, s1, s2))
return step + 1;
}
else
{
if (bfs(q2, words, s2, s1))
return step + 1;
}
}
return 0;
}
};
LeetCode 854. 相似度为 K 的字符串
对于某些非负整数 k ,如果交换 s1 中两个字母的位置恰好 k 次,能够使结果字符串等于 s2 ,则认为字符串 s1 和 s2 的相似度为k。
给你两个字母异位词 s1 和 s2 ,返回 s1 和 s2 的相似度 k 的最小值。
示例 :
输入:s1 = "ab", s2 = "ba" 输出:1
本题的关键在于如何抽象出状态。
很明显,字符串类型的题目,状态必然与字符串相关。
我们选择从前到后进行s2->s1的转换。如果发现s2[i]!=s1[i],则在s2[i+1...len-1]中选择一个字符与s2[i]交换,使得s2[i]!=s1[i]。
由于s2[i+1...len-1]可能有多个s2[j]满足s2[j]==s1[i],因此状态就会有很多种,毕竟s2[i]通过交换会出现在不同位置,所以每一次交换都会带来新的状态(字符串)。
通过上述描述,可以得知:从一个状态转移到另一个状态时需要找到第一个下标pos,使得对应下标处的字符不相同。为了避免重复的查找,我们额外记录一个pos,使下一次状态转移直接从pos开始向后查找。

常规BFS思路
class Solution {
public:
int kSimilarity(string s1, string s2)
{
int n = s1.size();
queue<pair<string, int>> q; // {上一次交换后所有可能的字符串、上一次交换的位置+1}
unordered_set<string> vis; // 记录已经遍历过的状态
q.emplace(s2, 0);
int k = 0;
while (!q.empty())
{
int sz = q.size();
while (sz--)
{
auto p = q.front();
q.pop();
string cur = p.first;
int pos = p.second;
// 通过k次交换已经完全相同
if (cur == s1)
return k;
while (pos < n && cur[pos] == s1[pos])
{
++pos;
}
// cur的第pos个字符与s1的第pos个不同
for (int i = pos + 1; i < n; ++i)
{
// 避免因为本次交换而破坏了原先相等的两个字符
if (cur[i] != s1[i] && cur[i] == s1[pos])
{
swap(cur[i], cur[pos]); // 交换
// 如果cur已经在之前的遍历中出现,那么说明可以通过更少的步数将s2转成cur
// 因此本轮无需将cur插入
if (vis.find(cur) == vis.end())
{
q.emplace(cur, pos + 1);
vis.insert(cur);
}
swap(cur[i], cur[pos]); // 恢复,向后寻找新的可能性
}
}
}
++k;
}
return -1;
}
};
A*启发式搜索
读作A-star启发式搜索,是一种基于贪心的BFS算法。
算法思路:
-
使用优先级队列取代BFS的普通队列,其队首保存:到目标状态"代价"最小的某个中间状态。
同样地,使用一个集合记录已经遍历到的状态,以及到达这个状态所需的步数。
-
所谓代价f(x),由两部分组成:
- g(x):表示从起始状态到当前中间状态的最小转移步数。
- h(x):启发函数,表示从当前中间状态到目标状态的可能转移步数。比如说,从(x1, y1)到(x2, y2)的转移步数为|x1-x2|+|y1-y2|(曼哈顿距离),或者取欧几里得距离sqrt((x1-x2)2+(y1-y2)2)。
f(x)=g(x)+h(x),优先队列根据*f(x)*的值进行从小到大的排序。
-
每次从优先队列的队首取出一个点,由于该点的代价f(x)最小,因此它是当前最有可能以最少的步数到达目标状态的中间状态。根据该状态更新它可能到达的状态,并插入到优先队列中。
可以看出,A-star启发式搜索的过程与dijkstra算法的过程十分相似,实际上dijkstra只是启发搜索中h(x)=0的一个特殊情况!
struct Node
{
Node(int _cost, int _pos, int _step, const string& _cur)
: cost(_cost), pos(_pos), step(_step), cur(_cur)
{
}
int cost; // 代价
int pos; // 上一次交换的位置+1
int step; // 转移到当前状态所需的步数
string cur; // 中间状态
};
struct Cmp
{
bool operator()(const Node* n1, const Node* n2)
{
return n1->cost > n2->cost;
}
};
class Solution
{
// 计算s2与s1有cnt个不同的字符,那么将s2转移至s1至少交换(cnt + 1) / 2次
int getH(const string& s1, const string& s2, int pos)
{
int cnt = 0;
for (int i = pos; i < s1.size(); ++i)
{
if (s1[i] != s2[i])
++cnt;
}
return (cnt + 1) / 2;
}
public:
int kSimilarity(string s1, string s2)
{
int n = s1.size();
priority_queue<Node*, vector<Node*>, Cmp> pq;
unordered_map<string, int> vis;
pq.push(new Node(0, 0, 0, s2));
vis[s2] = 0;
int k = 0;
while (!pq.empty())
{
Node* node = pq.top();
pq.pop();
string cur = node->cur;
int pos = node->pos;
int step = node->step;
// 通过k次交换已经完全相同
if (cur == s1)
return step;
while (pos < n && cur[pos] == s1[pos])
{
++pos;
}
// cur的第pos个字符与s1的第pos个不同
for (int i = pos + 1; i < n; ++i)
{
if (cur[i] != s1[i] && cur[i] == s1[pos])
{
swap(cur[i], cur[pos]); // 交换
// 如果cur在之前的遍历中没有出现,或者本次转换到cur,比之前使用的步数更少,则更新
if (vis.find(cur) == vis.end() || step + 1 < vis[cur])
{
pq.emplace(new Node(step + 1 + getH(s1, cur, pos + 1), pos + 1, step + 1, cur));
vis[cur] = step + 1;
}
swap(cur[i], cur[pos]); // 恢复,向后寻找新的可能性
}
}
}
return -1;
}
};















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











