







图,也就是tensorflow计算图。tensorflow程序需要先构图,再运行图。图由结点和边组成。
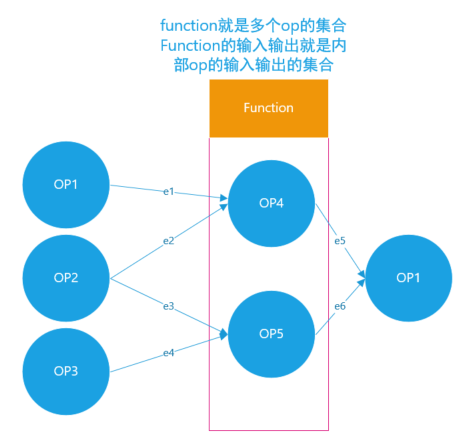
图的结点就是OP。而边连接OP的输出与另一个OP的输入。如下图,e1表示把OP1的输出连接到OP4的输入。 一个OP可以接受多个OP的输出作为输入。一个OP的输出也可以连接到多个OP的输入上。

分析图
- 需要保存图中有哪些结点(op)
- 结点之间如何连接(edge)
- 图需要序列化反序列化,以保存到磁盘上或者从磁盘加载
- 图就是模式,也就是机器学习,深度学习中说的模型
tensorflow 图的proto表示
GraphDef
// Represents the graph of operations
message GraphDef {
repeated NodeDef node = 1; //保存图中的结点
VersionDef versions = 4;
int32 version = 3 [deprecated = true];
// node[i].op的名字如果是library里的一个函数的名字,则这个Node认为是函数调用
//函数调用者保证函数输入同时满足,用Tuple机制
//函数输入都ready后函数就立即启动运算
//函数输出的消费者也通过Tuple机制所有输出Ready才开始使用
FunctionDefLibrary library = 2;
}
NodeDef
- 在tesnsorflow/core/framework/node_def.proto中定义了Node中的表示。
- NodeDef中的Input字符,实际上保存了图中的边。
- Node的输出实际上就是OP的输出。
- tensorflow/core/framework/node_def_utils.h中有操作Node中attr, 输入输出的函数
- 同样提供了NodeDefBuilder来创建Node: tensorflow/core/framework/node_def_builder.h
message NodeDef {
string name = 1;
//实际OP
string op = 2;
//这里通过node_name:src_output来标识需要哪个Node的哪个输出作为当前Node的输入
repeated string input = 3;
//指定设备名:"/job:worker/replica:0/task:1/device:GPU:3" 不指定会在运行时分配
string device = 4;
//op在构图时的配置,也就是OpDef里的属性,保存了属性名和值
map<string, AttrValue> attr = 5;
message ExperimentalDebugInfo {
repeated string original_node_names = 1;
repeated string original_func_names = 2;
}
ExperimentalDebugInfo experimental_debug_info = 6;
FullTypeDef experimental_type = 7;
}Function
- Function可以看作是把多个Node打包起来当前一个结点,这多个Node的输入就是OpDef signature,其中就是每个Node的输入集合起来。函数就是个子图,因此可以把图转成函数,tensorflow提供了函数:tensorflow/core/framework/graph_to_function.h中
- repeated NodeDef node_def就是持有了函数的所有node.
- ret字段则是函数的输出,实际就是多个OP的输出
- 函数还需要求梯度,因此需要再保存个梯度函数:在机器学习中要用梯度下降法,因此需要梯度函数
- function定义也提供了类似Builder的Helper
// A library is a set of named functions.
message FunctionDefLibrary {
repeated FunctionDef function = 1;
repeated GradientDef gradient = 2;
repeated RegisteredGradient registered_gradients = 3;
}
message FunctionDef {
// The definition of the function's name, arguments, return values,
// attrs etc.
OpDef signature = 1;
// Attributes specific to this function definition.
map<string, AttrValue> attr = 5;
// Attributes for function arguments. These attributes are the same set of
// valid attributes as to _Arg nodes.
message ArgAttrs {
map<string, AttrValue> attr = 1;
}
map<uint32, ArgAttrs> arg_attr = 7;
// Unique IDs for each resource argument, used to track aliasing resources. If
// Argument A and Argument B alias each other, then
// resource_arg_unique_ids[A.index] == resource_arg_unique_ids[B.index].
l be attached to the _Arg nodes'
// "_resource_arg_unique_id" attribute.
map<uint32, uint32> resource_arg_unique_id = 8;
// NOTE: field id 2 deleted on Jan 11, 2017, GraphDef version 21.
reserved 2;
repeated NodeDef node_def = 3;
// A mapping from the output arg names from `signature` to the
// outputs from `node_def` that should be returned by the function.
map<string, string> ret = 4;
// A mapping from control output names from `signature` to node names in
// `node_def` which should be control outputs of this function.
map<string, string> control_ret = 6;
}
message GradientDef {
string function_name = 1; // The function name.
string gradient_func = 2; // The gradient function's name.
}
message RegisteredGradient {
string gradient_func = 1; // The gradient function's name.
string registered_op_type = 2; // The gradient function's registered op type.
}
Model
// Class of a node in the performance model.
enum NodeClass {
UNKNOWN = 0;
INTERLEAVE_MANY = 1;
ASYNC_INTERLEAVE_MANY = 2;
KNOWN_RATIO = 3;
ASYNC_KNOWN_RATIO = 4;
UNKNOWN_RATIO = 5;
ASYNC_UNKNOWN_RATIO = 6;
}
// Algorithm used for model autotuning optimization.
enum AutotuneAlgorithm {
DEFAULT = 0;
HILL_CLIMB = 1;
GRADIENT_DESCENT = 2;
MAX_PARALLELISM = 3;
}
// Protocol buffer representing the data used by the autotuning modeling
// framework.
message ModelProto {
// General representation of a node in the model.
message Node {
// Unique node ID.
int64 id = 1;
// Human-readable name of the node.
string name = 2;
// An indication whether autotuning is enabled for this node.
bool autotune = 3;
// The number of bytes stored in this node's buffer.
int64 buffered_bytes = 4;
// The number of elements stored in this node's buffer.
int64 buffered_elements = 5;
// The number of bytes consumed by the node.
int64 bytes_consumed = 6;
// The number of bytes produced by the node.
int64 bytes_produced = 7;
// The number of elements produced by the node.
int64 num_elements = 8;
// The aggregate processing time spent in this node in nanoseconds.
int64 processing_time = 9;
// An indication whether this node records metrics about produced and
// consumed elements.
bool record_metrics = 10;
// Represents a node parameter.
message Parameter {
// Human-readable name of the parameter.
string name = 1;
// Identifies the model value of the parameter. This can be different from
// the actual value (e.g. during optimization search).
double value = 2;
// The actual value of the parameter.
double state_value = 3;
// Minimum value of the parameter.
double min = 4;
// Maximum value of the parameter.
double max = 5;
// Identifies whether the parameter should participate in autotuning.
bool tunable = 6;
}
// Parameters of this node.
repeated Parameter parameters = 11;
// Statistic of inputs processing time history.
double input_processing_time_sum = 12;
int64 input_processing_time_count = 13;
// IDs of inputs of this node.
repeated int64 inputs = 14;
// Class of this node.
NodeClass node_class = 15;
// Ratio of input to output elements. This is only used by KNOWN_RATIO and
// ASYNC_KNOWN_RATIO nodes.
double ratio = 16;
// Ratio identifies how many parallelism calls are introduced by one
// buffered element. This is only used by ASYNC_KNOWN_RATIO nodes.
double memory_ratio = 17;
}
// Map of node IDs to nodes of this model.
map<int64, Node> nodes = 1;
// ID of the output node of this model.
int64 output = 2;
// Counter for node IDs of this model.
int64 id_counter = 3;
reserved 4;
// Contains parameters of the model autotuning optimization.
message OptimizationParams {
// Algorithm used for autotuning optimization.
AutotuneAlgorithm algorithm = 1;
// Number of available logical threads.
int64 cpu_budget = 2;
// Amount of available memory in bytes.
int64 ram_budget = 3;
// Time between two consecutive `GetNext` calls to the iterator represented
// by the output node.
double model_input_time = 4;
}
OptimizationParams optimization_params = 5;
}














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









