






ScholarCopilot 是什么
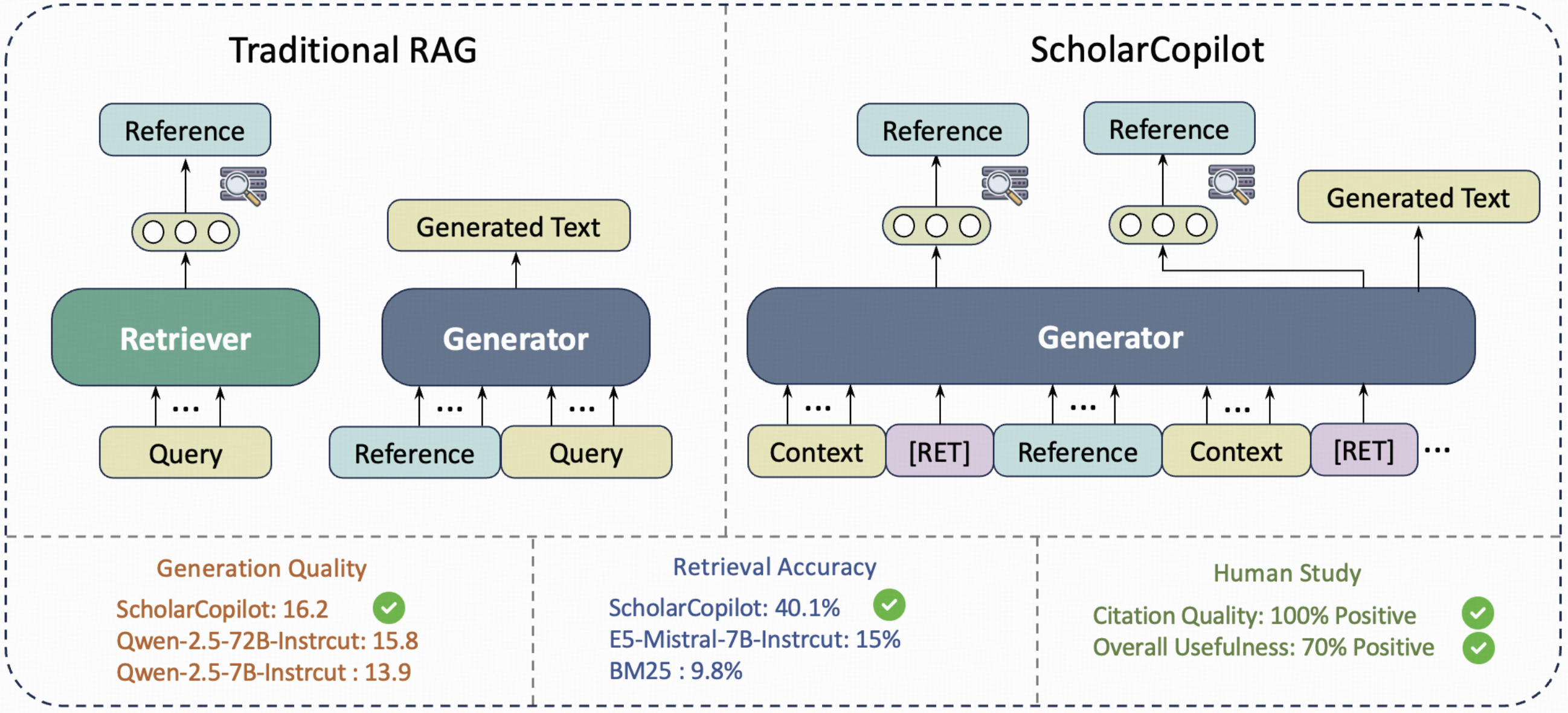
由加拿大滑铁卢大学与卡内基梅隆大学联合研发的 ScholarCopilot,专为解决学术写作中的引用难题而生。该工具通过动态检索标记触发文献搜索,在生成文本时实时插入精准引用,形成完整的学术写作闭环。
其核心技术在于将文本生成与文献检索进行联合优化,使得模型能够自主判断何时需要插入引用。当检测到需要文献支持的内容时,系统会暂停生成过程,从包含 50 万篇 arXiv 论文的数据库中检索相关文献,并将检索结果无缝融入后续文本生成。
ScholarCopilot 的主要功能
- 动态检索增强:通过特殊标记触发实时文献检索,支持模糊查询与精确匹配双模式
- 联合优化生成:将检索到的文献摘要融入生成过程,保证文本与引用的逻辑一致性
- 多格式引用输出:自动生成 APA/MLA 格式引文,支持 BibTeX 条目一键导出
- 错误自检系统:基于置信度分析标记潜在错误引用,提醒人工复核可疑内容
ScholarCopilot 的技术原理
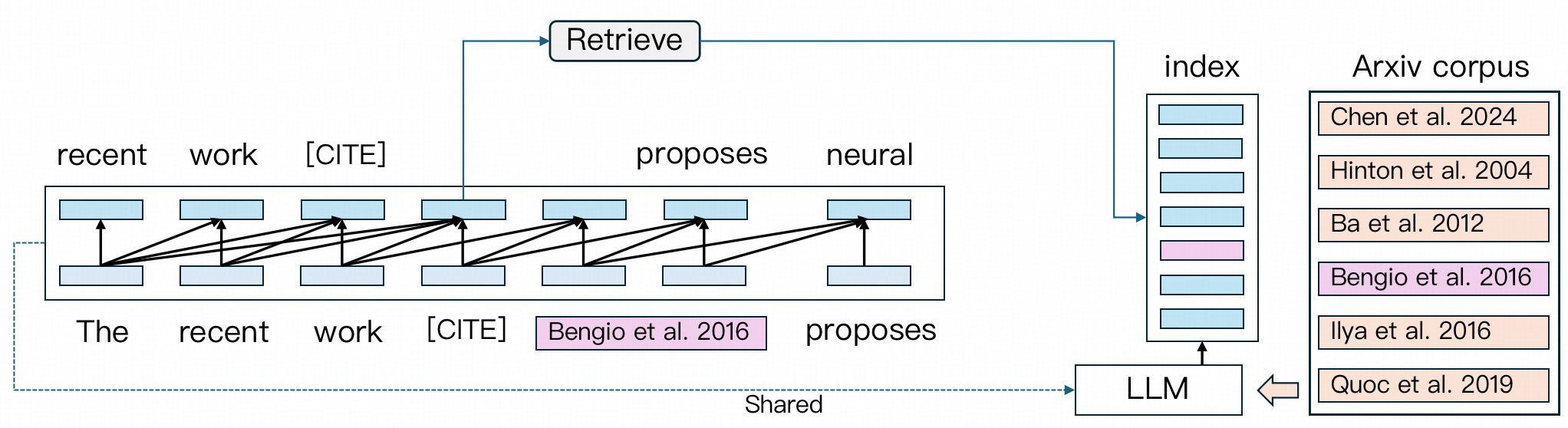
- 动态切换架构:文本生成与文献检索模块通过门控机制实现无缝切换
- 对比学习优化:使用 Triplet Loss 训练检索标记的向量表示,提升检索精度
- 混合索引策略:结合 BM25 与传统嵌入向量,构建分层检索系统
- 联合训练框架:文本生成损失与引用准确率损失共同参与反向传播
如何运行 ScholarCopilot
Scholar Copilot 采用统一的模型架构,通过动态切换机制无缝集成检索和生成。在生成过程中,模型使用学习到的引用模式自主确定适当的引用点。当需要引用时,模型会暂时停止生成,利用引用标记的隐藏状态从语料库中检索相关论文,插入选定的引用,然后恢复连贯的文本生成。
🚀 快速开始
1. 克隆仓库
git clone git@github.com:TIGER-AI-Lab/ScholarCopilot.git
cd ScholarCopilot/run_demo
2. 设置环境
pip install -r requirements.txt
3. 下载所需的模型和数据
bash download.sh
4. 启动演示
bash run_demo.sh
更新语料库中的最新论文
若要将最新的论文更新到你的语料库中,请按照以下步骤操作:
1. 下载元数据
从 Kaggle 下载最新的 arXiv 元数据并保存到你选择的 ARXIV_META_DATA_PATH
2. 运行数据处理脚本
cd utils/
python process_arxiv_meta_data.py ARXIV_META_DATA_PATH ../data/corpus_data_arxiv_1215.jsonl
3. 生成语料库的嵌入
bash encode_corpus.sh
4. 将嵌入转换为 HNSW 索引以提高搜索效率
python build_hnsw_index.py --input_dir <embedding dir> --output_dir <hnsw index dir>
训练你自己的模型
1. 下载训练数据
cd train/
bash download.sh
2. 配置并运行训练脚本
要重现我们的结果,你可以使用脚本中的超参数,并使用 4 台机器,每台机器 8 个 GPU(总共 32 个 GPU):
cd src/
bash start_train.sh
资源
- 项目主页:ScholarCopilot
- GitHub 仓库:https://github.com/TIGER-AI-Lab/ScholarCopilot


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









