






使用htmlunit解析蓝奏云直连
前言
最近有个需求,客户端需要更新软件版本,我一直在用蓝奏云,觉得是个非常不错的网盘,可是如果用户自己打开连接选择下载方式很麻烦,用过蓝奏的朋友都知道,打开外链还要选择普通下载-电信下载-联通下载。很麻烦,于是乎,我想到一个办法,把更新的文件上传到网盘,使用java解析出真正的文件地址,让客户端后台创建下载任务,嘿嘿。
分析
我这里放一个jar包测试,外链地址为:https://wwe.lanzous.com/iSb3Deaa3bi
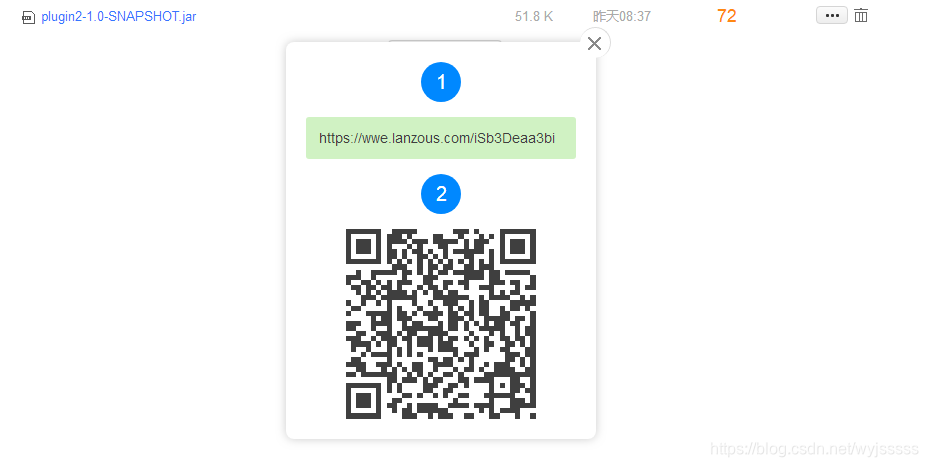
可以看到,这是一个永久下载地址,固定不变的,打开这个链接。

点击下载会发现,下载地址固定时间会变化一次,现在按F12进入浏览器调试,选择Network,会发现一个ajaxm.php,点击它,进入Response,会发现一窜json数据,没错,这就是我们我们想要的,复制到浏览器打开会创建一个下载任务。
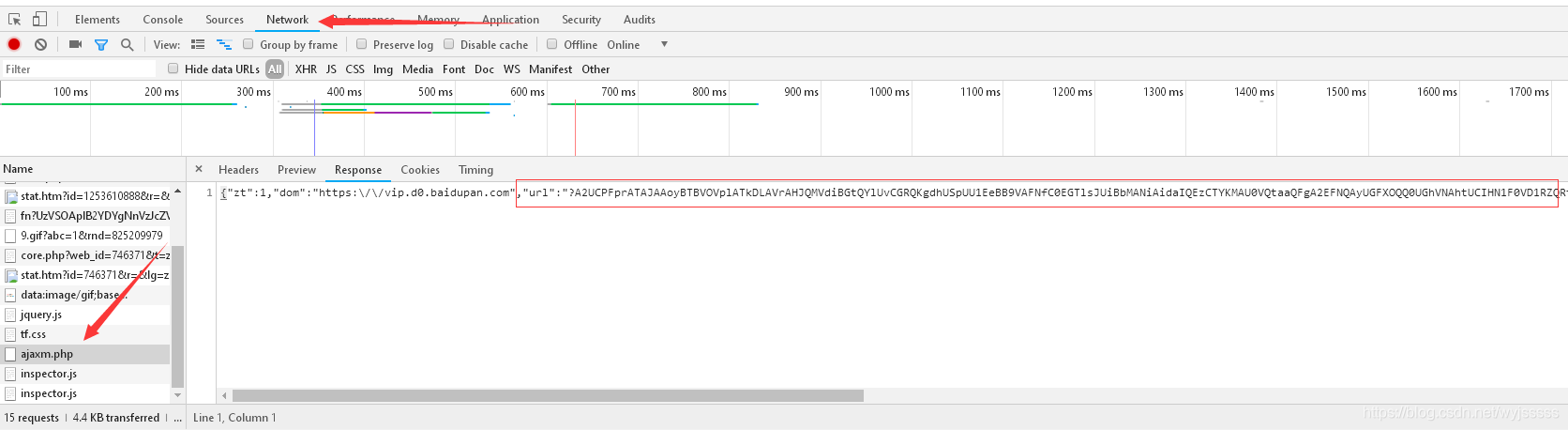
现在需要做的就是通过java解析拿到这个json数据。
=======废话不多说,直接上代码
使用框架(htmlunit)
maven地址
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.41.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.71</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
先创建一个浏览器
public class Browser {
private static volatile WebClient webClient=null;
private Browser(){
WebClient webClient=new WebClient();
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setActiveXNative(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
}
public static WebClient getWebClient(){
if(webClient==null){
synchronized (Browser.class){
if(webClient==null){
webClient=new WebClient();
}
}
}
return webClient;
}
}
Resolve.java
public class Resolve {
private WebClient webClient;
//蓝奏云外链地址
private String path;
public Resolve(){}
public Resolve(String path) {
this.path = path;
}
public void setPath(String path) {
this.path = path;
}
public void init() throws IOException {
webClient=Browser.getWebClient();
//监听资源加载,这里的WebConnectionWrapper会监听所有资源加载
webClient.setWebConnection(new WebConnectionWrapper(webClient){
@Override
public WebResponse getResponse(WebRequest request) throws IOException {
WebResponse response = super.getResponse(request);
String data=response.getContentAsString();
//过滤得到下载链接,也就之前那窜json数据(涂个方便,就没写正则)
if(data.contains("{\"zt\":1,\"dom\":\"https")) {
JSONObject jsonObject= (JSONObject) JSON.parse(data);
System.out.println("下载地址");
//解析得到下载链接
String url = "https://vip.d0.baidupan.com/file/" + jsonObject.get("url");
System.out.println(url);
}
return response;
}
});
//
webClient.getPage(path);
}
}
最后,来一个测试类
public class Test {
public static void main(String[] args) throws IOException {
Resolve resolve = new Resolve("https://wwe.lanzous.com/iSb3Deaa3bi");
resolve.init();
}
}
嗯,运行得到了一个连接,复制到浏览器会发现会创建一个下载任务。

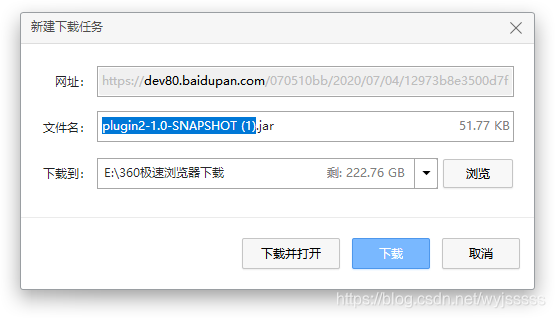
等等--------------
拿到的这个地址你会发现,,有个问题,打开浏览器输入地址,会创建个下载任务,其实这个不是真正的文件地址,打开下载工具下载下来是个html页面,在这里着实被坑了一把,真正的文件地址是302重定向后;
获取真正的文件地址
使用json获取重定向后的连接
添加一个方法
/**
*
* @param url 重定向之前的url
* @throws IOException
*/
private void redirect(String url) throws IOException {
Connection connect = Jsoup.connect(url);
//这里必须要加请求头,不然无法跳转,着实被坑了一把,找了好久才知道原因
connect.header("Accept-Language","zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
Connection.Response response = connect.followRedirects(false).execute();
System.out.println("Is URL going to redirect : " + response.hasHeader("Location"));
System.out.println("Target : " + response.header("Location"));
}
最后response.header("Location")拿到的就是重定向后的地址,也就是真正的文件地址,复制到下载工具就可以下载啦。

















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









