






(一)项目特色
(1)AI助力阿尔兹海默症的“老药新用”:“老药新用”目前已成为现在的研究趋势。在我们的项目当中我们使用了LDA文本主题模型的机器学习方法来对相关论文文本数据进行文本挖掘,并使用挖掘结果来构建知识图谱。根据我们的论文文本数据所构建的知识图谱,我们可以很快地发现阿尔兹海默症和一些“老药”的关系,优先验证最有潜力的“老药”,这样就可以有效的降低阿尔兹海默症在药物开发上的成本。
(2)把肠道菌群也考虑进去了:在最新的研究中,肠道菌群也是AD的潜在影响因素。所以,在项目中,我们会同时从大量论文中提取出肠道菌群,药物,基因三者之间的联系。最后,基于AD,药物,基因,肠道菌群的关系,构建知识图谱,
(二)项目流程(我在本项目之中主要负责模型训练)
①数据预处理:从PubMed数据库中提取出有关神经退行性疾病的论文摘要数据,做出一个词频矩阵(分词+词形还原+去掉stopwords)
②模型训练(本人负责):
(1)主题模型训练。通过前面队友的数据预处理之后,我收到了一个统计好的词语出现次数的词频矩阵。并且为了防止常见的单词出现的频率过高,我使用了TF-IDF进行预处理。主题模型是对输入数据进行主题抽取,输出的是一个N*M的矩阵(N是主题个数,M为主题的单词数)。本实验采用LDA模型来进行主题抽取,其中LDA模型采用的是Gibbs Sampling算法实现,具体代码实现方法是采用gensim库中的LDA模型。
(2)词向量训练。在该过程中对每年的数据进行整体的词向量训练,使用的是word2vec中的skip-gram方法,目的是为了把主题里面的单词全部变成向量,便于处理。经过该步骤以后每一个主题都变成了一个矩阵。
(3)聚类模型训练。先把(2)处理过后的所有主题对应的主题矩阵拼接起来,变成一个三维张量。而后采用的是吸引子传播算法(AP聚类算法),并且以主题之间(矩阵之间)的余弦相似度作为聚类算法的相似度度量方法,主题模型的结果进行聚类处理,将主题模型输出类似的主题进行再次聚合。
③命名实体识别、可视化处理、AD知识图谱数据库构建(本人未参与故不做笔记)
(三)一些技术细节
(1)知识图谱
知识图谱是以“实体-关系-实体”的三元组形式在数据库中进行构建,实体有对应的 属性描述其性质,实体之间的联系是通过关系来表示,知识图谱本质是一个含有知识含义 的图,其中图中的节点表示实体,边代表实体之间的关系。
(2)知识抽取
数据获取指的是从海量的数据资源中获取所需格式的数据。目前获取的数据有三种结构,分别是结构化数据、半结构化数据和非结构化数据。知识抽取部分是将研究需要的特定数据从上述获取的资源中进行抽取,具体过程分为 三个部分,分别为实体抽取、关系抽取和属性抽取。
①实体抽取:也就是命名实体识别,包括实体的检测和分类
②关系抽取:自动识别实体之间具有的某种语义关系。根据参与实体的多少可以分为二元关系抽取(两个实体)和多元关系抽取(三个及以上实体)。通过关注两个实体间的语义关系,可以得到(arg1, relation, arg2)三元组,其中arg1和arg2表示两个实体,relation表示实体间的语义关系。
(3)属性抽取
抽取一些数据用来描述实体
(4)知识抽取
本项目当中是从文本数据里面进行知识抽取,本项目采用的是一种常见的方法:主题模型。通过主题模型对文本数据进行主题抽取,进而实现实体概念、实体间关系以及实体的属性等知识的抽取。主题模型是一种基于文本中单词出现频率的一种挖掘算法。 所有主题模型都基于相同的假设:
①每个文档包含多个主题
②每个主题包含多个单词
主题模型(Topic Model)在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。直观来讲,如果一篇文章有一个中心思想,那么一些特定词语会更频繁的出现。一个主题模型试图用数学框架来体现文档的这种特点。主题模型自动分析每个文档,统计文档内的词语,根据统计的信息来断定当前文档含有哪些主题,以及每个主题所占的比例各为多少。本文使用的是LDA主题模型
LDA主题模型
LDA主题模型的图如下
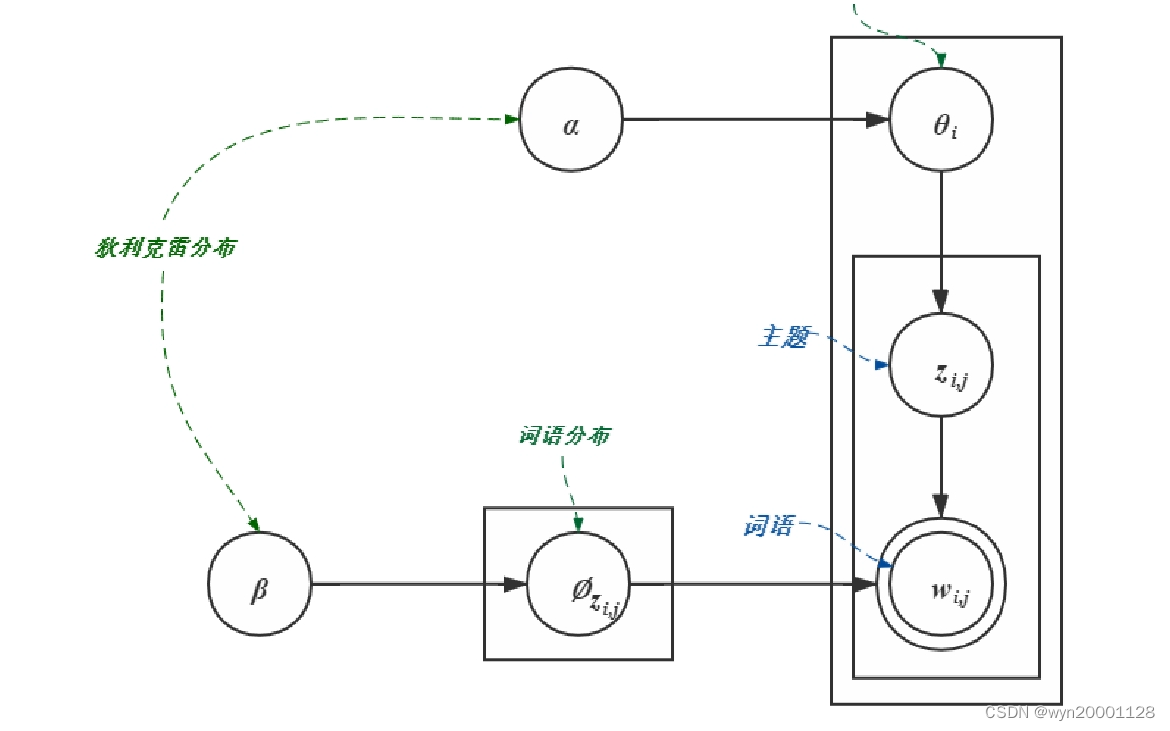
模型解释:LDA模型(隐含狄利克雷分配模型)认为每一篇文本的每一个单词都是经过Topics经过一定概率得到的。上图就是LDA生产单词的过程:
(1)上部分:
α
\alpha
α代表的是文本——话题分布的先验分布(服从狄利克雷分布)。
Θ
i
\Theta_i
Θi表示的是第i个文本的话题分布(多项分布),
Z
i
,
j
Z_{i,j}
Zi,j是第i个文本经过
Θ
i
\Theta_i
Θi选出来的一个话题。
(2)下部分:
β
\beta
β是话题——单词分布的先验分布,
Θ
Z
i
,
j
\Theta_{Z_{i,j}}
ΘZi,j是话题
Z
i
,
j
Z_{i,j}
Zi,j生成一个单词的分布(多项分布)
说通俗点就是:
①LDA模型认为每一篇文本都有一个满足多项分布的文本——话题分布,例如在文档1里面话题1出现的概率,话题2出现的概率,这样可以随机选择一和话题,二会提又满足一个话题—单词分布例如话题1里面单词1出现的概率,单词2出现的概率。这样的话就可以生成一个单词,进而生成多个文档,这个过程可以看成满足一个极其复杂的联合概率分布,接下来只要把这个分布的参数估计出来,就可以提取出文本数据里面的话题特征提取出来。其中文档-话题分布又满足一个参数为
α
\alpha
α的狄利克雷分布,话题-单词分布又满足一个参数为
β
\beta
β的狄利克雷分布。
②LDA在项目当中的作用:
(1)预先设定N个topics,么一个topics都是由得到的数据里面的所有词汇所组成,其中每一个词汇所占的份额不一样的话就说明了topics所讲的侧重点不一样,这也可以理解为抽取出来的知识
(2)LDA的调参过程
N:对于不同Topic所训练出来的模型,计算它的困惑度。最小困惑度所对应的Topic就是最优的主题数
topN:设置为30
α
\alpha
α和
β
\beta
β:
α
=
1
/
N
,
β
=
200
/
每一个主题的词项数量
\alpha=1/N,\beta=200/每一个主题的词项数量
α=1/N,β=200/每一个主题的词项数量
下面是本人对LDA学习的详细博客:LDA学习笔记
(5)知识融合
知识融合过程主要是对知识抽取过程抽取的知识进行清洗整理,因为上一步骤抽取的 知识中存在着与实验无关的冗余信息或者是错误信息。我主要负责实体对齐这一部分。
实体对齐(实体消歧+共指消歧)
实体消歧主要是用来解决同名实体产生歧义等相关问题,主要采用聚类算法来实现。这里使用的是空间向量模型,同样称为词袋模型,是根据当前预料中的实体附近的单词去构造特征向量,一般处理数据为文本数据,因此多利用余弦相似度计算向量之间的相似度,从而将该实体聚类到与此最相近的实体集合中。共指消歧是解决多个实体对应于同一实体对象的问题,目前多采用机器学习中的决策树算法以及聚类算法来实现。本项目当中采用Word2vec与聚类算法结合。
Word2vec
Word2vec模型是一个基于三层神经网络的词向量模型,是由Mikolov于2013年提出的, 通过非监督训练将文本中的每个单词映射到一个k维向量空间,并把每个单词在这个k维 空间的表示组合在一起作为该单词的向量表示,其中词向量的含义是语义越相近在向量维 度上的距离越相近。 改进方法就是:Hierarchical Softmax+神经网络语料模型,让语义越相近在向量维度上的距离越相近,具体如下:
(1)CBOW模型是一个基于上下文预测当前的目标单词向量模型。输入就是与一个特定词上下文相关的词所对应的词向量,而输出就是这个特定词的词向量。原理如下
①根据语料库词频构造一颗哈夫曼树,每一颗非叶节点都有一个参数向量
θ
\theta
θ
②把这个特定词的周围的2c个词向量求和取平均值
③从哈夫曼树的根节点开始,进行多次逻辑斯特二分到达那个特定词上面去,并通过梯度上升反向传播
(2)Skip-gram模型是已经知道当前词语对上下文进行预测,该模型的输入为当前单词的词向量,即w(t),输出 的是上下文单词的向量表示,就是输入是当前特定单词,而后进行定位到上下文的多个单词上面去,每个单词都是和CBOW模型一样的方法。
本项目当中词向量的维度是200
本人学习Word2vec的具体帖子如下:Word2vec模型学习笔记


















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









