






2020年魔幻开局,上半年疫情肆虐,逼自己学完了这套Kafka 源码深度剖析课程视频,通过对Kafka高性能的消息封装流程源码剖析,服务端高性能架构设计源码剖析等,看完彻底掌握了Kafka底层原理,顺利拿到了心心念念的字节Offer,这套大数据干货资料,原价 2699 元,现在限时免费送,希望你和我一样过五关斩六将,下半年直奔大厂!
视频目录
1. Kafka高性能的消息封装流程架构设计源码剖析
(1)Kafka概述
(2)生产者初始化流程
(3)生产者分区选择
(4)生产者消息封装流程深度剖析
(5)生产者内存池设计
2. Kafka客户端容错体系源码剖析
(6)Sender线程初始化流程
(7)Kafka网络架构设计
(8)生产者请求发送流程剖析
(9)生产者相应消息处理流程剖析
(10)生产者内存回收处理流程详解
(11)生产者消息异常处理流程剖析
(12)生产者消息超时处理流程剖析
(13)生产者流程总结
3. Kafka服务端高性能架构设计源码剖析
(14)Acceptor线程核心启动流程剖析
(15)Processor线程核心原理剖析
(16)服务端如何接收请求
(17)服务端如何发送响应给客户端
(18)支持超高并发的Kafka网络架构设计
(19)Kafka核心对象关系梳理
(20)ReplicaManager写数据流程深度剖析
(21)稀松索引生成流程深度剖析
(22)服务端消息flush流程深度剖析
4. Kafka数据管理源码剖析
(23)副本同步流程深度剖析
(24)Follower拉取数据请求流程剖析
(25)Leader处理数据请求流程剖析
(26)LEO,HW更新流程深度剖析
(27)ISR定时检查线程原理剖析
(28)Controller选举流程剖析
(29)Broker注册流程剖析
(30)Topic创建流程 元数据管理流程剖析
(31)元数据管理流程剖析
添加课程小助手
免费领取全套视频网盘链接

人数较多,请大家耐心等待
添加都会一一通过
有什么办法可以真正帮助大家成为一名优秀的大数据架构师?
据预测,未来5年,中国大数据产业规模年均增长率将超过30%,大数据行业应用场景广泛,与大数据相关的岗位多达几十种,电子商务、政府数据中心、医药、金融、互联网企业等都在抢夺大数据人才。
据媒体报道,在国内顶尖互联网公司,大数据行业的薪酬要比同一个级别的其他职位高20%至30%,且颇受企业重视。所以学习大数据专业知识,不仅“前(钱)”途无量 ,也是进入大公司的捷径。
基于这样的状况,奈学教育创始人孙玄联合多位业内资深架构专家共同打磨一门《大数据架构师》课程,希望能够帮助一批想要在大数据行业有所建树的人。

现在扫码,有小福利 ↓↓↓
免费领取课程大纲
给自己一个升职、加薪的机会
课程深度剖析了各个基础技术的源码,对这些基础技术知识动态的排列组合,形成大数据全局架构观,并深入讲述大数据全局架构设计的方方面面,打造真正满足企业万亿级海量数据规模的数据中台,真正赋能前台业务。
Part 1:课程由谁主讲?
《大数据架构师》在线大课,是由孙玄(前58技术委员会主席 & 现奈学CEO )、沈剑(前百度资深研发工程师 & 现 58CTO )、李希沅(前转转资深架构师 & Hadoop平台负责人 )、马中华 (前 Oracle 数据开发负责人 & 阿里第一位认证金牌讲师 )几位资深技术大咖联合设计。

Part 2:这门课程有什么亮点?
首先,围绕源码级核心技术讲解
课程针对Hadoop,Hive,Spark,Fink,Zookeeper,Kafka等核心技术进行源码深度剖析,夯实大数据技术功底。
第二,提供PB级大数据中台落地实践
构建大数据中台的lass层、到Pass层,企业级大数据平台落地实操,体验企业级大数据中台从0到1的构建过程。
第三,课程采用千亿级真实案例驱动
基于一线大厂的真实需求,实际落地案例进行剖析。项目需求真实,项目背景真实,项目架构真实,让你具备一线大厂研发经验。
第四,多维度企业级项目实践
从不同角度培养合格的企业级大数据研发工程师,包含源码二次开发实践,企业级数据中台落地实践,数仓实践,离线项目实践,实时项目实践,分布式数据中心实践等。
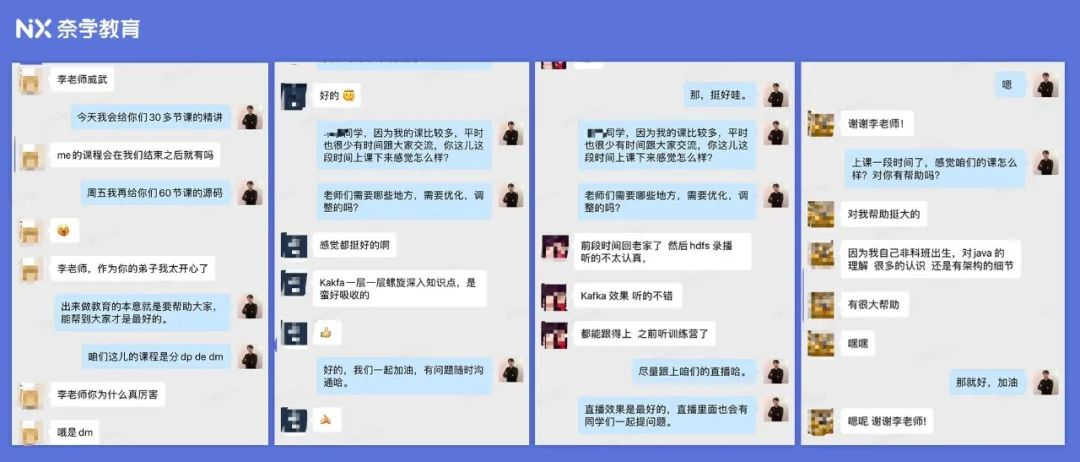
Part 3:师兄师姐们都说好!!
还有,往期的师兄师姐们,都猝不及防地爱上了我们的企业级干货。
你们自己看 ↓↓↓
Part 4:学习课程,你将获得
01
大数据技术生态源码阅读能力
1、针对HDFS/MapReduce/Spark/Kafka/Flink等大数据核心技术、业内首次深入源码级别讲解,并全程画图辅助理解
2、直击核心技术,针对源码二次开发
3、提升源码阅读能力
02
架构设计企业级数据中台能力
1、打破数据孤岛,将数据用起来
2、独立落地数据中台lass层/Pass层
3、基于数据中台打造企业级项目
03
架构设计千亿级数仓能力
1、掌握数仓核心知识
2、掌握企业级数仓建模方法论
3、掌握数据治理
04
架构设计PB级大数据项目能力
1、全面掌握数据采集、数据存储、数据处理等各环节
2、掌握企业离线开发/实时开发常用技术
3、掌握大数据常见场景的架构设计方案
Part 5:配套的课程服务有哪些?
为全方位保障学习权益,奈学教育推出付费学员十大保护权益,全程为你的学习之旅保驾护航!
1. 建立学员VIP学习群,不解散,持续为您提供技术答疑服务
2. 每个班级会配备专属助教+班主任,全程督促学员完成课程学习
3. 每章一次测试题,助你查漏补缺
4. 每节课会布置课程作业,巩固课程
5. 老师随时随地技术答疑,让你的问题不在过夜
6. 模拟面试、简历修改、背景提升
7. 不定期线下交流会,面对面交流收获多
8. 录播永久有效,课上文件笔记都会同步
9. 高端岗位内推
10. 前两次课程不满意全额退款
最新一期《大数据架构师》课程开课在即,现在报名优惠多多,可添加课程小助手详细咨询~
再贵的东西除以365天都会变得很便宜,再小的努力乘以365天都会变得很伟大。
你想要做的很多事情,不是没结果,而是没有坚持下去;那就从今天起,给自己一个重新出发的机会吧。
现在扫码,有小福利 ↓↓↓
免费领取授课视频
给自己一个升职、加薪的机会
点击“阅读原文”领取更多干货学习资料!

















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









