







这篇文章其实是对MoreWindows文章中 [1] 的一个问题的思考。
下面是他文章的源码
#include <stdio.h>
#include <windows.h>
volatile long g_nLoginCount; //登录次数
unsigned int __stdcall Fun(void *pPM); //线程函数
const DWORD THREAD_NUM = 50;//启动线程数
DWORD WINAPI ThreadFun(void *pPM)
{
Sleep(100);//some work should to do
//g_nLoginCount++;
InterlockedIncrement((LPLONG)&g_nLoginCount);
Sleep(50);
return 0;
}
int main()
{
printf(" 原子操作 Interlocked系列函数的使用\n");
printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
//重复20次以便观察多线程访问同一资源时导致的冲突
int num= 20;
while (num--)
{
g_nLoginCount = 0;
int i;
HANDLE handle[THREAD_NUM];
for (i = 0; i < THREAD_NUM; i++)
handle[i] = CreateThread(NULL, 0, ThreadFun, NULL, 0, NULL);
WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
printf("有%d个用户登录后记录结果是%d\n", THREAD_NUM, g_nLoginCount);
}
return 0;
}
我代码中进程数改为100,后发现输出全为零,后用二分法找到64这个分界点。
刚开始觉得应该分配给进程的资源不够导致因线程过多产生的栈空间超过了进程的内存。
我开始尝试改一下代码
#include <stdio.h>
#include <windows.h>
volatile long g_nLoginCount; //登录次数
unsigned int __stdcall Fun(void *pPM); //线程函数
const DWORD THREAD_NUM = 100;//启动线程数
DWORD WINAPI ThreadFun(void *pPM)
{
Sleep(100); //some work should to do
//g_nLoginCount++;
InterlockedIncrement((LPLONG)&g_nLoginCount);
Sleep(50);
return 0;
}
int main()
{
printf(" 原子操作 Interlocked系列函数的使用\n");
printf(" -- by MoreWindows( http://blog.csdn.net/MoreWindows ) --\n\n");
//重复20次以便观察多线程访问同一资源时导致的冲突
int num= 20;
while (num--)
{
g_nLoginCount = 0;
int i;
HANDLE handle[THREAD_NUM];
for (i = 0; i < THREAD_NUM; i++){
handle[i] = CreateThread(NULL, 0, ThreadFun, NULL, 0, NULL);
WaitForSingleObject(handle[i],INFINITE);//原来只能到64
CloseHandle(handle[i]);
}
WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE);
printf("有%d个用户登录后记录结果是%d\n", THREAD_NUM, g_nLoginCount);
}
return 0;
}
这个有点慢可以了。
这时候,还是认为是资源问题。
但是,Google一下,发现一片文章 [2] ,中间说道:
默认情况下,一个线程的栈要预留1M的内存空间,而一个进程中可用的内存空间只有2G,所以理论上一个进程中最多可以开2048个线程。
我发现我的两个错误,一是,进程空间可以占据OS分给用户态的全部内存。二是,内存足够用,不止64。
再回去看博文,发现博主给的答案。MSDN上对WaitForMultipleObjects()函数第一个参数作了说明:The maximum number of object handles is MAXIMUM_WAIT_OBJECTS(64)。
求心理阴影~~我实在没考虑过那个函数!
我在 头文件winnt.h 发现这个定义:
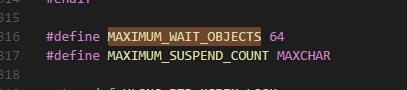
原来是这个原因。
另外还有一点,
评论:“这样由于线程执行的并发性,很可能线程A执行到第二句时,线程B开始执行,线程B将原来的值又写入寄存器eax中,这样线程A所主要计算的值就被线程B修改了。这样执行下来,结果是不可预知的——可能会出现50,可能小于50。”
“这样线程A所所主要计算的值就被线程B修改了”这句话应该是不对的
引起问题的原因应该是:A执行到第二句,执行B,假设B执行结束后,继续执行A,其实寄存器eax是会恢复到A最后的值,这样导致的结果是线程B的执行结果被A覆盖,相当于B没有执行
回答:每个线程的寄存器是私有的,切换线程时会保存各寄存器中的值。
[1] . http://blog.csdn.net/morewindows/article/details/7429155
[2] . http://jackyhongvip.iteye.com/blog/1339768















 6328
6328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









