






1.导入德国信用卡数据
data = load('german.data-numeric');2.进行数据处理,选取模型数据与测试数据
数据处理
% 最后一列变成0-1
for i = 1:x
data(i,y) = data(i,y)-1;
end选取数据
train_data = data(1:5,[1,2,25])
text_data = data(76,[1,2,25])先选取小样本数据,之后再扩大数据样本,这里选取了1-5行的1,2,25列作为模型数据,第76行的1,2,25列作为测试数据

3.接下来进行贝叶斯模型概率的计算
(1)当贝叶斯概率为0时不进行拉普拉斯平滑(即在当贝叶斯概率为0时不额外增加样本数据)
function [default,nodefault] = beiyesi_function(data,columns,value,index)
[x,y] = size(data);
p_default = 0; % 违约
for i = 1:x
if data(i,index) == 0
p_default = p_default+1;
end
end
p_nodefault = 0; % 未违约
for i = 1:x
if data(i,index) == 1
p_nodefault = p_nodefault+1;
end
end
% columns,value 且 违约
default = 0;
for i = 1:x
if data(i,columns) == value && data(i,index) == 0
default = default+1;
end
end
default = default/p_default;
% columns,value 且 不违约
nodefault = 0;
for i = 1:x
if data(i,columns) == value && data(i,index) == 1
nodefault = nodefault+1;
end
end
nodefault = nodefault/p_nodefault;
function [p0,p1] = beiyesi_train(train_data,text_data)
% 算测试集和模型集的大小
[x_train,y_train] = size(train_data);
[x_text,y_text] = size(text_data);
% 后验0的概率 后验1的概率
p0 = [];
p1 = [];
for i = 1:x_text
for j = 1:y_text-1
[p0(i,j),p1(i,j)] = beiyesi_function_old(train_data,j,text_data(i,j),y_text);
end
end
default = 0; % 违约
for i = 1:x_train
if train_data(i,y_train) == 0
default = default+1;
end
end
default = default/x_train;
nodefault = 0; % 未违约
for i = 1:x_train
if train_data(i,y_train) == 1
nodefault = nodefault+1;
end
end
nodefault = nodefault/x_train;
p0(:,y_text) = 1;
p1(:,y_text) = 1;
for i = 1:x_text
for j = 1:y_text-1
p0(i,y_text) = p0(i,y_text) * p0(i,j);
p1(i,y_text) = p1(i,y_text) * p1(i,j);
end
p0(i,y_text) = p0(i,y_text) * default;
p1(i,y_text) = p1(i,y_text) * nodefault;
end主要算法思想为
先进行计算最后一列0跟1的概率
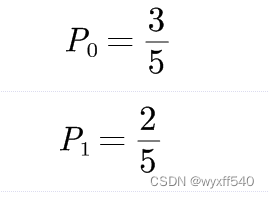
然后计算测试样本(1,12)在概率1跟0时的概率

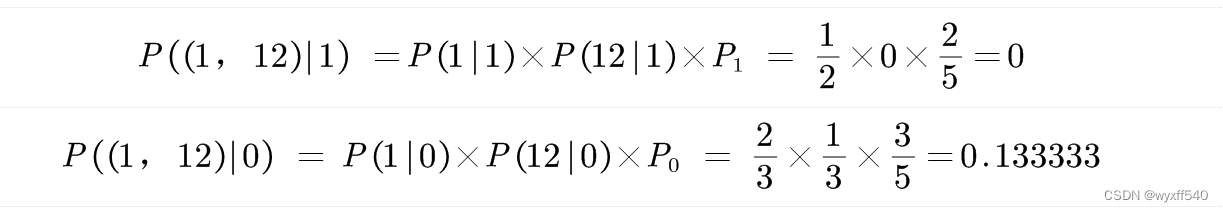

(2) 当贝叶斯概率为0时进行拉普拉斯平滑(即在当贝叶斯概率为0时额外增加一条样本数据)
由上方概率结果可知,此样本只有在P(12|1)时概率为0,导致后面计算P((1,12)|1)时的概率也为0
若在此时进行拉普拉斯平滑后(在样本数据后面自己增加一条当第三列为1时第二列是12的数据),其概率变成


4.接下来计算贝叶斯的正确率
代码参考文章(6条消息) MATLAB朴素贝叶斯(德国信用卡案例)_huaye0101的博客-CSDN博客
(1)当没进行拉普拉斯平滑时小样本正确矩阵及正确率

(2)当进行了拉普拉斯平滑时小样本正确矩阵及正确率

5.接着进行数据量的扩大(更容易比较出两者的区别)
将前800行作为模型数据,后200行作为测试数据
train_data = data(1:800,:)
text_data = data(801:1000,:)
(1)当没进行拉普拉斯平滑时大样本正确矩阵及正确率

(2)当进行了拉普拉斯平滑时大样本正确矩阵及正确率
















 1731
1731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









