







BeautifulSoup学习网址:Beautiful Soup 中文文档
1.下载安装bs4和beautifulsoup4库
pip install bs4
pip install beautifulsoup4
2.豆瓣爬虫---BeautifulSoup
目的:爬取电影名,电影排名和图片,并将图片保存在本地
url地址:https://www.douban.com/doulist/2772079/
import requests
from bs4 import BeautifulSoup
import re
def dianyingming():
'''
爬取电影名
:return:电影名结果列表
'''
count = 1 # 初始化页数
name = [] # 存放最终电影名的列表
print('爬取电影名')
for num in range(0, 351, 25):
print(f'第{count}页开始........................................................................................')
url = 'https://www.douban.com/doulist/2772079/' # 网站url地址
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
xiangying = requests.get(url, params=f'start={num}&sort=seq&playable=0&sub_type=',
headers=headers) # 向url网站发送http请求包
soup = BeautifulSoup(xiangying.text, 'html.parser') # 构建beautifulsoup对象实例
# 找想要捕获的数据规律
name_list = soup.find_all('div', class_='title') # 返回<div class='title'>.....</div>
# 取出标签中的内容
for name_str in name_list:
name_eng = name_str.text.strip() # 电影名中有英文名
name_no_eng = name_eng.split(
maxsplit=1) # split方法:分割字符串,sep参数默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。maxsplit参数表示分割次数,默认分割所有
name.append(f'<<{name_no_eng[0]}>>')
print(f'第{count}页结束......................................................................................')
count += 1
print(f'有两个电影资源被作者删除,下面在列表中添加两个元素')
name.insert(35, f'<<电影被删除>>')
name.insert(275, '<<电影被删除>>')
# 输出最终电影名列表
# for name_result in name:
# print(name_result)
print(len(name)) # 检查爬取电影名的个数
return name
def rank():
'''
爬取评分
:return:rank
'''
print('爬取评分')
rank = []
count = 1
for num in range(0, 351, 25):
print(f'第{count}页开始........................................................................................')
url = 'https://www.douban.com/doulist/2772079/' # 网站url地址
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
xiangying = requests.get(url, params=f'start={num}&sort=seq&playable=0&sub_type=',
headers=headers) # 向url网站发送http请求包
soup = BeautifulSoup(xiangying.text, 'html.parser') # 构建beautifulsoup对象实例
# 总结想要捕获的数据的规律,并爬取数据
rank_list = soup.find_all('span', class_='pos') # 拿到<span class='pos'>....</span>
# 获取标签中的内容
for rank_str in rank_list:
rank_result = rank_str.text # 拿到标签中的内容:排名号
rank.append(rank_result) # 将拿到的内容放到rank结果列表中
print(f'第{count}页结束........................................................................................')
count += 1
for rank_for in rank:
print(rank_for)
print(f'评分表中个数:{len(rank)}')
return rank
def has_src_but_no_style(tag):
'''
判断标签中是否满足,存在src属性、不存在style属性以及不存在alt属性
如果满足,返回True
:param tag: 标签
:return: True/False
'''
return tag.has_attr('src') and not tag.has_attr('style') and not tag.has_attr('alt')
def picture():
'''
爬取网页中电影图片,并保存到本地
:return: 图片网址链接
'''
no_link=[]
link_list=[]
count=1
url = 'https://www.douban.com/doulist/2772079/' # 网站url地址
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
for num in range(0,351,25):
print(f'第{count}页开始........................................................................................')
xiangying = requests.get(url,params=f'start={num}&sort=seq&playable=0&sub_type=',headers=headers) # 向url网站发送http请求包
soup = BeautifulSoup(xiangying.text, 'html.parser') # 构建beautifulsoup对象实例
# 从<img src=>中找出图片链接
img=soup.find_all('img',)
for img_src in img:
if has_src_but_no_style(img_src):
link=img_src.get('src')
# print(type(link))
# print(link[-4:])
no_link_movie=re.findall(r'.*/movie/.*',link)
no_link_sns=re.findall(r'.*/sns/.*',link)
no_link_version=re.findall(r'.*?version=.*',link)
no_link_sum=no_link_version+no_link_sns+no_link_movie
for k in no_link_sum:
no_link.append(k)
if link not in no_link:
link_list.append(link)
print(f'第{count}页结束........................................................................................')
count+=1
print('因为有两个资源被作者删除,所以没有显示')
# 访问爬取到的页面,因为图片都是以链接形式存储访问的
count_n=1
for link_tp in link_list:
xiangying_tp=requests.get(link_tp,headers=headers)
# 将爬取到的图片保存到.jpg格式文件中
with open(f'./tmp/{count_n}.jpg','wb+') as f:
f.write(xiangying_tp.content)
count_n+=1
return link_list
name=dianyingming()
rank=rank()
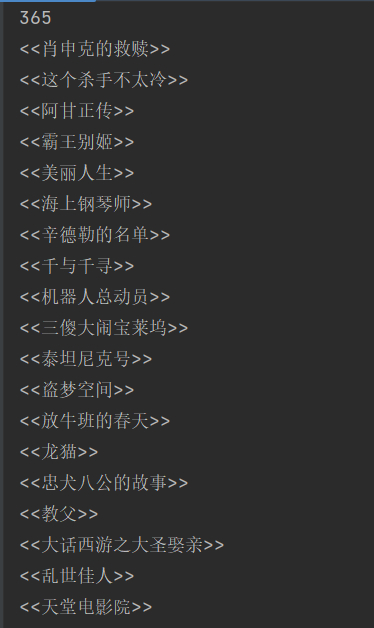
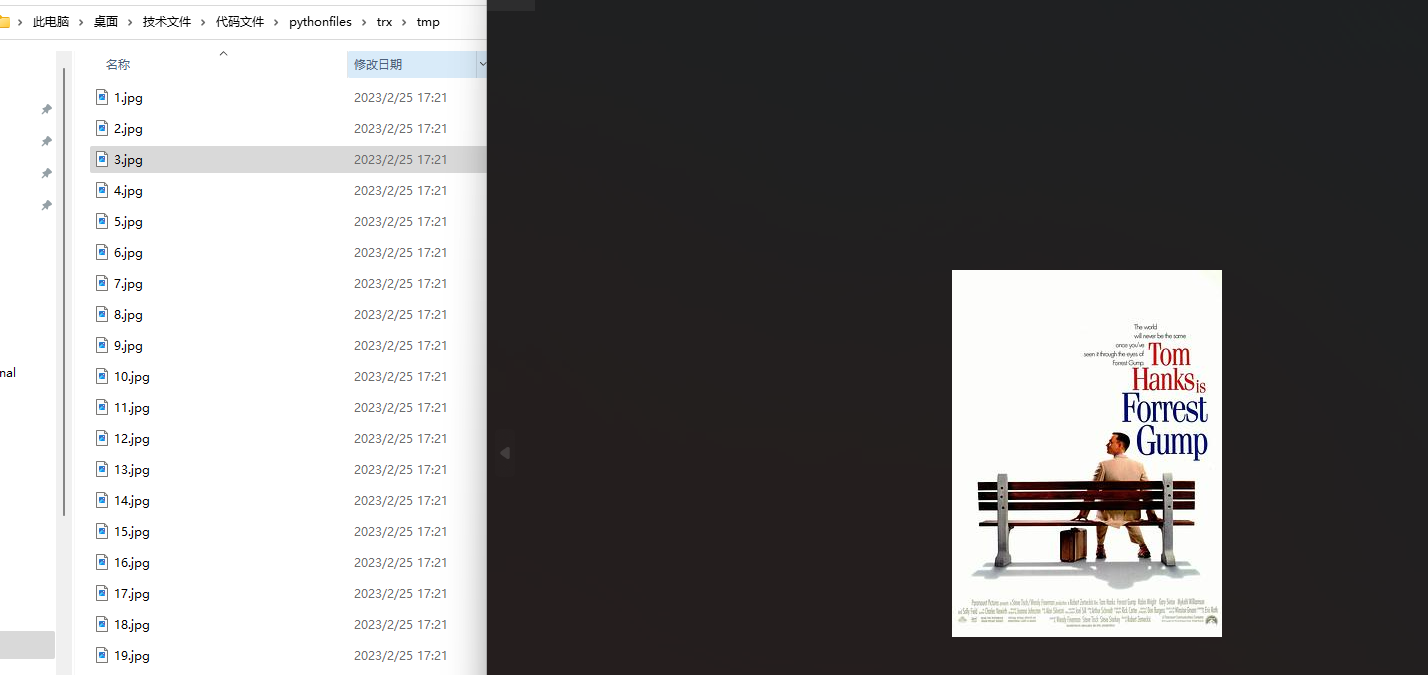
picture=picture()爬取结果:
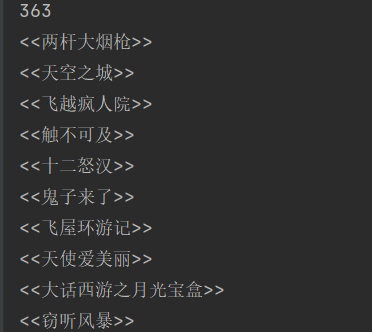
电影名
图片
3.豆瓣爬虫升级---加入多线程
目的:爬取电影名。因为单线程速度过慢,加入多线程
import threading
import requests
from bs4 import BeautifulSoup
from queue import Queue
from threading import Lock
c = Queue() # 实例化队列
l=Lock()# 实例化锁,锁是为了防止数据竞争
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50'
}
name = []
def fang():
global c
for name_url in range(0, 351, 25):
url = f'https://www.douban.com/doulist/2772079/?start={name_url}&sort=seq&playable=0&sub_type='
c.put(url)
def qu():
global c
global headers, name
while True:
url = c.get()
xiangying = requests.get(url, headers=headers) # 向url网站发送http请求包
soup = BeautifulSoup(xiangying.text, 'html.parser') # 构建beautifulsoup对象实例
# 找想要捕获的数据规律
name_list = soup.find_all('div', class_='title') # 返回<div class='title'>.....</div>
# 取出标签中的内容
for name_str in name_list:
name_eng = name_str.text.strip() # 电影名中有英文名
name_no_eng = name_eng.split(
maxsplit=1) # split方法:分割字符串,sep参数默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。maxsplit参数表示分割次数,默认分割所有
l.acquire()
name.append(f'<<{name_no_eng[0]}>>')
l.release()
# 输出最终电影名列表
# for name_result in name:
# print(name_result)
print(len(name)) # 检查爬取电影名的个数
c.task_done() # Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号。每个get()调用得到一个任务,接下来task_done()调用告诉队列该任务已经处理完毕。
gongren_list = []
job1 = threading.Thread(target=fang, daemon=True)
job1.start()
for i in range(5):
job2 = threading.Thread(target=qu, daemon=True)
gongren_list.append(job2)
# print(gongren_list)
for j in gongren_list:
j.start()
c.join() # Queue.join() 实际上意味着等到队列为空,再执行别的操作
for i in name:
print(i)爬取结果:















 1305
1305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









