







SparkSQL 练习项目 - 出租车利用率分析
本项目是 SparkSQL 阶段的练习项目, 主要目的是夯实同学们对于 SparkSQL 的理解和使用
-
数据集
-
2013年纽约市出租车乘车记录
需求
-
统计出租车利用率, 到某个目的地后, 出租车等待下一个客人的间隔
1. 业务
-
数据集介绍
-
业务场景介绍
-
和其它业务的关联
-
通过项目能学到什么
-
数据集结构
- 业务场景
- 技术点和其它技术的关系
- 在这个小节中希望大家掌握的知识
2. 流程分析
-
分析的步骤和角度
-
流程
-
分析的视角
- 步骤分析
3. 数据读取
-
工程搭建
-
数据读取
-
工程搭建
</project>
-
创建 Scala 源码目录
src/main/scala并且设置这个目录为
Source Root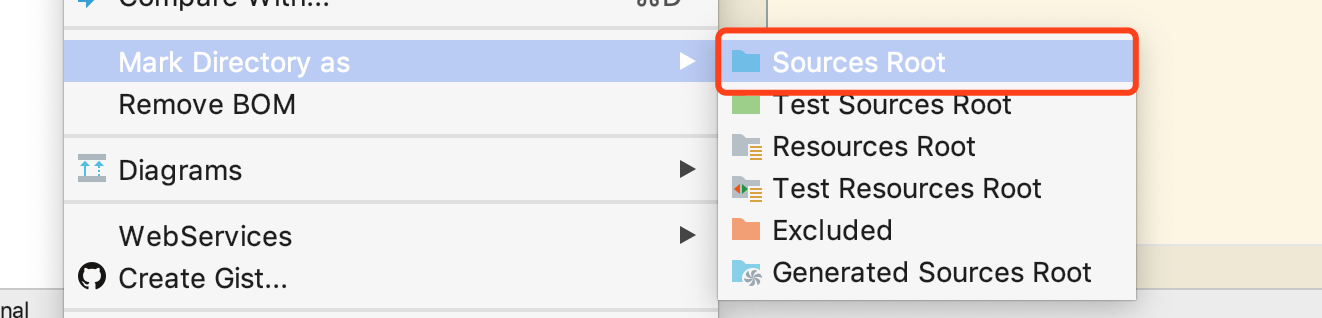
-
创建文件, 数据读取
object TaxiAnalysisRunner {
def main(args: Array[String]): Unit = {
}
}Step 2: 数据读取-
数据读取之前要做两件事
-
-
初始化环境, 导入必备的一些包
-
在工程根目录中创建
dataset文件夹, 并拷贝数据集进去
代码如下
-
-
object TaxiAnalysisRunner {
def main(args: Array[String]): Unit = {
// 1. 创建 SparkSession
val spark = SparkSession.builder()
.master(“local[6]”)
.appName(“taxi”)
.getOrCreate()// 2. 导入函数和隐式转换 import spark.implicits._ import org.apache.spark.sql.functions._ // 3. 读取文件 val taxiRaw = spark.read .option("header", value = true) .csv("dataset/half_trip.csv") taxiRaw.show() taxiRaw.printSchema()}
运行结果如下
}root |-- medallion: string (nullable = true) |-- hack_license: string (nullable = true) |-- vendor_id: string (nullable = true) |-- rate_code: string (nullable = true) |-- store_and_fwd_flag: string (nullable = true) |-- pickup_datetime: string (nullable = true) |-- dropoff_datetime: string (nullable = true) |-- passenger_count: string (nullable = true) |-- trip_time_in_secs: string (nullable = true) |-- trip_distance: string (nullable = true) |-- pickup_longitude: string (nullable = true) |-- pickup_latitude: string (nullable = true) |-- dropoff_longitude: string (nullable = true) |-- dropoff_latitude: string (nullable = true)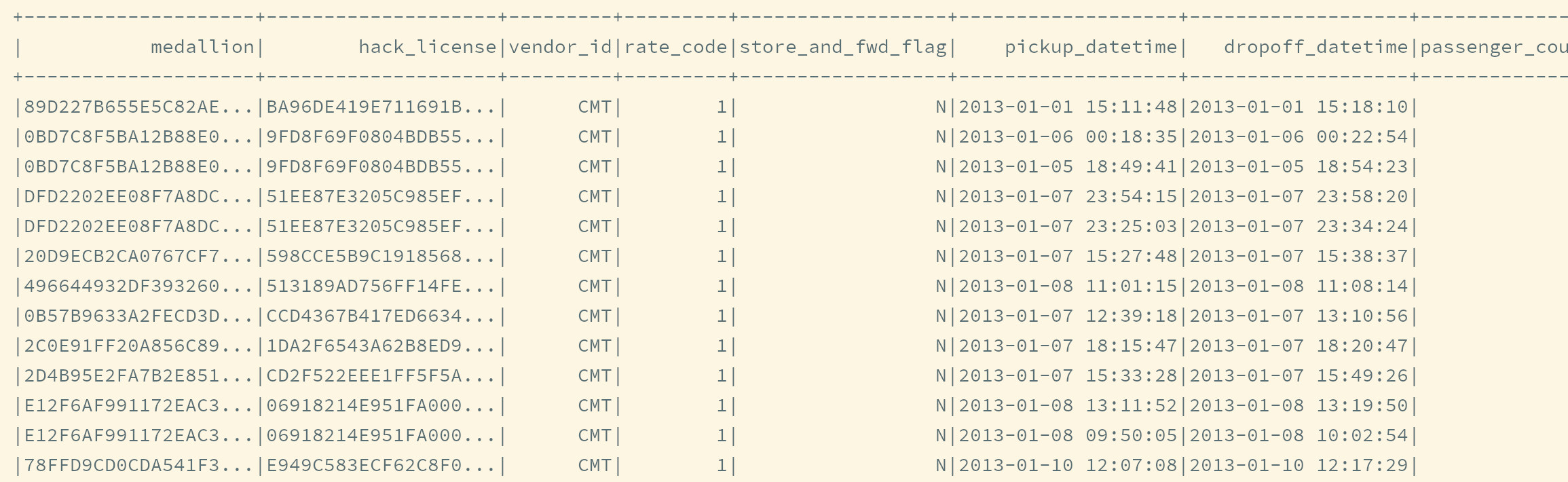
5. 数据清洗
导读-
将
Row对象转为Trip -
处理转换过程中的报错
-
数据转换
def main(args: Array[String]): Unit = {
// 此处省略 Main 方法中内容
}}
/**
- 代表一个行程, 是集合中的一条记录
- @param license 出租车执照号
- @param pickUpTime 上车时间
- @param dropOffTime 下车时间
- @param pickUpX 上车地点的经度
- @param pickUpY 上车地点的纬度
- @param dropOffX 下车地点的经度
- @param dropOffY 下车地点的纬度
*/
case class Trip(
license: String,
pickUpTime: Long,
dropOffTime: Long,
pickUpX: Double,
pickUpY: Double,
dropOffX: Double,
dropOffY: Double
)
Step 2: 将Row对象转为Trip对象, 从而将DataFrame转为Dataset[Trip]首先应该创建一个新方法来进行这种转换, 毕竟是一个比较复杂的转换操作, 不能怠慢
object TaxiAnalysisRunner {def main(args: Array[String]): Unit = {
// … 省略数据读取// 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(parse)}
/**
* 将 Row 对象转为 Trip 对象, 从而将 DataFrame 转为 Dataset[Trip] 方便后续操作
* @param row DataFrame 中的 Row 对象
* @return 代表数据集中一条记录的 Trip 对象
*/
def parse(row: Row): Trip = {}
}case class Trip(…)
Step 3: 创建Row对象的包装类型因为在针对
Row类型对象进行数据转换时, 需要对一列是否为空进行判断和处理, 在Scala中为空的处理进行一些支持和封装, 叫做Option, 所以在读取Row类型对象的时候, 要返回Option对象, 通过一个包装类, 可以轻松做到这件事创建一个类
RichRow用以包装Row类型对象, 从而实现getAs的时候返回Option对象object TaxiAnalysisRunner {def main(args: Array[String]): Unit = {
// …// 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(parse)}
def parse(row: Row): Trip = {…}
}
case class Trip(…)
class RichRow(row: Row) {
def getAs[T](field: String): Option[T] = {
if (row.isNullAt(row.fieldIndex(field)) || StringUtils.isBlank(row.getAsString)) {
None
} else {
Some(row.getAsT)
}
}
}Step 4: 转换流程已经存在, 并且也已经为空值处理做了支持, 现在就可以进行转换了
首先根据数据集的情况会发现, 有如下几种类型的信息需要处理
-
字符串类型
执照号就是字符串类型, 对于字符串类型, 只需要判断空, 不需要处理, 如果是空字符串, 加入数据集的应该是一个
null -
时间类型
上下车时间就是时间类型, 对于时间类型需要做两个处理
-
转为时间戳, 比较容易处理
-
如果时间非法或者为空, 则返回
0L
-
-
Double类型上下车的位置信息就是
Double类型,Double类型的数据在数据集中以String的形式存在, 所以需要将String类型转为Double类型
总结来看, 有两类数据需要特殊处理, 一类是时间类型, 一类是
Double类型, 所以需要编写两个处理数据的帮助方法, 后在parse方法中收集为Trip类型对象object TaxiAnalysisRunner {def main(args: Array[String]): Unit = {
// …// 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(parse)}
def parse(row: Row): Trip = {
// 通过使用转换方法依次转换各个字段数据
val row = new RichRow(row)
val license = row.getAsString.orNull
val pickUpTime = parseTime(row, “pickup_datetime”)
val dropOffTime = parseTime(row, “dropoff_datetime”)
val pickUpX = parseLocation(row, “pickup_longitude”)
val pickUpY = parseLocation(row, “pickup_latitude”)
val dropOffX = parseLocation(row, “dropoff_longitude”)
val dropOffY = parseLocation(row, “dropoff_latitude”)// 创建 Trip 对象返回 Trip(license, pickUpTime, dropOffTime, pickUpX, pickUpY, dropOffX, dropOffY)}
/**
* 将时间类型数据转为时间戳, 方便后续的处理
* @param row 行数据, 类型为 RichRow, 以便于处理空值
* @param field 要处理的时间字段所在的位置
* @return 返回 Long 型的时间戳
*/
def parseTime(row: RichRow, field: String): Long = {
val pattern = “yyyy-MM-dd HH:mm:ss”
val formatter = new SimpleDateFormat(pattern, Locale.ENGLISH)val timeOption = row.getAs[String](field) timeOption.map( time => formatter.parse(time).getTime ) .getOrElse(0L)}
/**
* 将字符串标识的 Double 数据转为 Double 类型对象
* @param row 行数据, 类型为 RichRow, 以便于处理空值
* @param field 要处理的 Double 字段所在的位置
* @return 返回 Double 型的时间戳
*/
def parseLocation(row: RichRow, field: String): Double = {
row.getAsString.map( loc => loc.toDouble ).getOrElse(0.0D)
}
}case class Trip(…)
class RichRow(row: Row) {…}
-
异常处理
-
在进行类型转换的时候, 是一个非常容易错误的点, 需要进行单独的处理
-
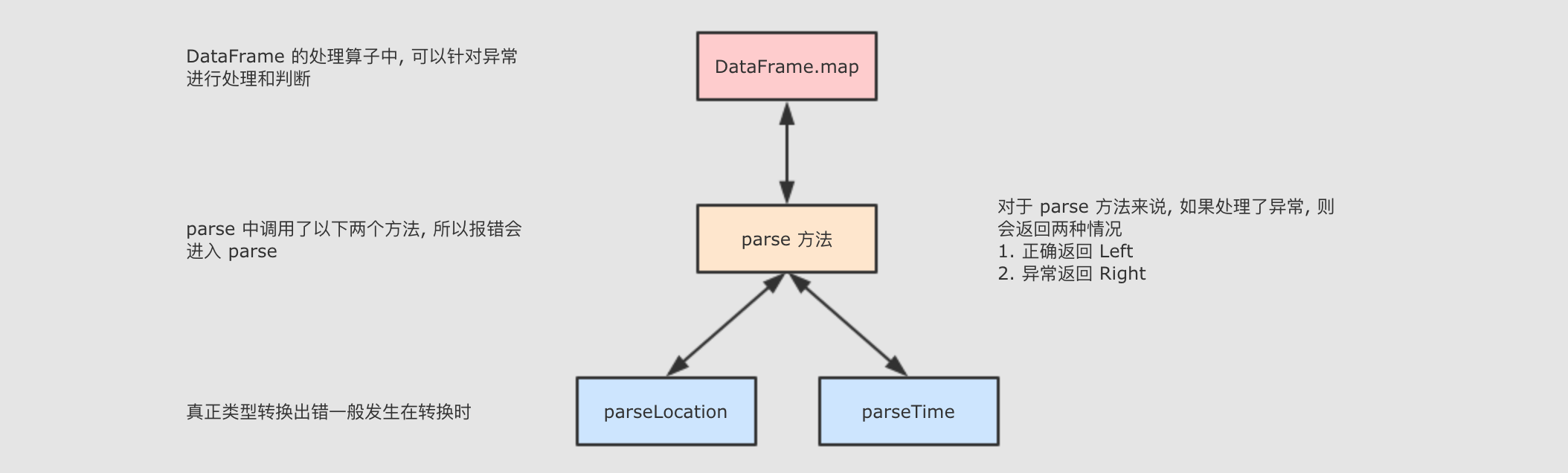
parse方法应该做的事情应该有两件-
捕获异常
异常一定是要捕获的, 无论是否要抛给
DataFrame, 都要先捕获一下, 获知异常信息捕获要使用
try … catch …代码块 -
返回结果
返回结果应该分为两部分来进行说明
-
正确, 正确则返回数据
-
错误, 则应该返回两类信息, 一 告知外面哪个数据出了错, 二 告知错误是什么
-
对于这种情况, 可以使用
Scala中提供的一个类似于其它语言中多返回值的Either.Either分为两个情况, 一个是Left, 一个是Right, 左右两个结果所代表的意思可有由用户来指定val process = (b: Double) => { (1) val a = 10.0 a / b } -
Step 1: 思路 -
def safe(function: Double => Double, b: Double): Either[Double, (Double, Exception)] = { (2)
try {
val result = function(b) (3)
Left(result)
} catch {
case e: Exception => Right(b, e) (4)
}
}val result = safe(process, 0) (5)
result match { (6)
case Left® => println®
case Right((b, e)) => println(b, e)
}1 一个函数, 接收一个参数, 根据参数进行除法运算 2 一个方法, 作用是让 process函数调用起来更安全, 在其中catch错误, 报错后返回足够的信息 (报错时的参数和报错信息)3 正常时返回 Left, 放入正确结果4 异常时返回 Right, 放入报错时的参数, 和报错信息5 外部调用 6 处理调用结果, 如果是 Right 的话, 则可以进行响应的异常处理和弥补 Either和Option比较像, 都是返回不同的情况, 但是Either的Right可以返回多个值, 而None不行如果一个
Either有两个结果的可能性, 一个是Left[L], 一个是Right[R], 则Either的范型是Either[L, R]Step 2: 完成代码逻辑加入一个 Safe 方法, 更安全
object TaxiAnalysisRunner {def main(args: Array[String]): Unit = {
// …// 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(safe(parse))}
/**
* 包裹转换逻辑, 并返回 Either
*/
def safe[P, R](f: P => R): P => Either[R, (P, Exception)] = {
new Function[P, Either[R, (P, Exception)]] with Serializable {
override def apply(param: P): Either[R, (P, Exception)] = {
try {
Left(f(param))
} catch {
case e: Exception => Right((param, e))
}
}
}
}def parse(row: Row): Trip = {…}
def parseTime(row: RichRow, field: String): Long = {…}
def parseLocation(row: RichRow, field: String): Double = {…}
}case class Trip(…)
class RichRow(row: Row) {…}
Step 3: 针对转换异常进行处理对于
Either来说, 可以获取Left中的数据, 也可以获取Right中的数据, 只不过如果当Either是一个 Right 实例时候, 获取Left的值会报错所以, 针对于
Dataset[Either]可以有如下步骤-
试运行, 观察是否报错
-
如果报错, 则打印信息解决报错
-
如果解决不了, 则通过
filter过滤掉Right -
如果没有报错, 则继续向下运行
object TaxiAnalysisRunner {def main(args: Array[String]): Unit = {
…// 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(safe(parse)) val taxiGood = taxiParsed.map( either => either.left.get ).toDS()}
…
}…
很幸运, 在运行上面的代码时, 没有报错, 如果报错的话, 可以使用如下代码进行过滤
object TaxiAnalysisRunner {def main(args: Array[String]): Unit = {
…// 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(safe(parse)) val taxiGood = taxiParsed.filter( either => either.isLeft ) .map( either => either.left.get ) .toDS()}
…
}…
观察数据集的时间分布观察数据分布常用手段是直方图, 直方图反应的是数据的
"数量"分布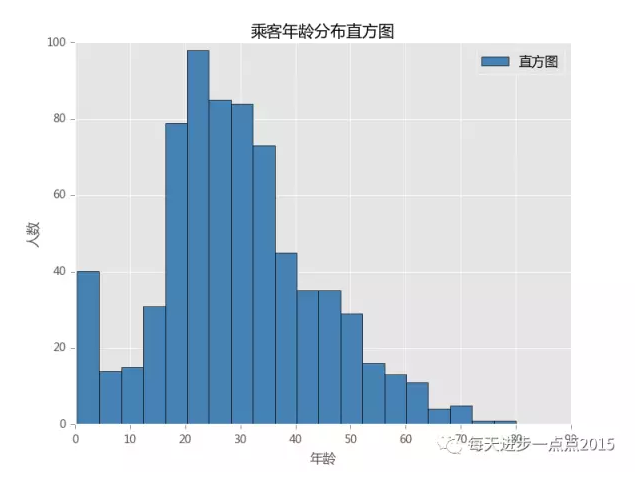
通过这个图可以看到其实就是乘客年龄的分布, 横轴是乘客的年龄, 纵轴是乘客年龄的频数分布
因为我们这个项目中要对出租车利用率进行统计, 所以需要先看一看单次行程的时间分布情况, 从而去掉一些异常数据, 保证数据是准确的
绘制直方图的 "图" 留在后续的
DMP项目中再次介绍, 现在先准备好直方图所需要的数据集, 通过数据集来观察即可, 直方图需要的是两个部分的内容, 一个是数据本身, 另外一个是数据的分布, 也就是频数的分布, 步骤如下-
计算每条数据的时长, 但是单位要有变化, 按照分钟, 或者小时来作为时长单位
-
统计每个时长的数据量, 例如有
500个行程是一小时内完成的, 有300个行程是1 - 2小时内完成
def main(args: Array[String]): Unit = {
…// 5. 过滤行程无效的数据 val hours = (pickUp: Long, dropOff: Long) => { val duration = dropOff - pickUp TimeUnit.HOURS.convert(, TimeUnit.MILLISECONDS) } val hoursUDF = udf(hours)}
…
}Step 2:统计时长分布-
第一步应该按照行程时长进行分组
-
求得每个分组的个数
-
最后按照时长排序并输出结果
object TaxiAnalysisRunner {def main(args: Array[String]): Unit = {
…// 5. 过滤行程无效的数据 val hours = (pickUp: Long, dropOff: Long) => { val duration = dropOff - pickUp TimeUnit.MINUTES.convert(, TimeUnit.MILLISECONDS) } val hoursUDF = udf(hours) taxiGood.groupBy(hoursUDF($"pickUpTime", $"dropOffTime").as("duration")) .count() .sort("duration") .show()}
…
}会发现, 大部分时长都集中在
1 - 19分钟内+--------+-----+ |duration|count| +--------+-----+ | 0| 86| | 1| 140| | 2| 383| | 3| 636| | 4| 759| | 5| 838| | 6| 791| | 7| 761| | 8| 688| | 9| 625| | 10| 537| | 11| 499| | 12| 395| | 13| 357| | 14| 353| | 15| 264| | 16| 252| | 17| 197| | 18| 181| | 19| 136| +--------+-----+Step 3:注册函数, 在 SQL 表达式中过滤数据大部分时长都集中在
1 - 19分钟内, 所以这个范围外的数据就可以去掉了, 如果同学使用完整的数据集, 会发现还有一些负的时长, 好像是回到未来的场景一样, 对于这种非法的数据, 也要过滤掉, 并且还要分析原因object TaxiAnalysisRunner {def main(args: Array[String]): Unit = {
…// 5. 过滤行程无效的数据 val hours = (pickUp: Long, dropOff: Long) => { val duration = dropOff - pickUp TimeUnit.MINUTES.convert(, TimeUnit.MILLISECONDS) } val hoursUDF = udf(hours) taxiGood.groupBy(hoursUDF($"pickUpTime", $"dropOffTime").as("duration")) .count() .sort("duration") .show() spark.udf.register("hours", hours) val taxiClean = taxiGood.where("hours(pickUpTime, dropOffTime) BETWEEN 0 AND 3") taxiClean.show()}
…
}6. 行政区信息
-
目标和步骤
- 总结
6.1. 需求介绍
-
目标和步骤
- 思路整理
-
-
需求
项目的任务是统计出租车在不同行政区的平均等待时间, 所以源数据集和经过计算希望得到的新数据集大致如下
-
源数据集
-
目标数据集

-
-
目标数据集分析
目标数据集中有三列,
borough,avg(seconds),stddev_samp(seconds)-
borough表示目的地行政区的名称 -
avg(seconds)和stddev_samp(seconds)是seconds的聚合,seconds是下车时间和下一次上车时间之间的差值, 代表等待时间
所以有两列数据是现在数据集中没有
-
borough要根据数据集中的经纬度, 求出其行政区的名字 -
seconds要根据数据集中上下车时间, 求出差值
-
-
步骤
-
求出
borough-
读取行政区位置信息
-
搜索每一条数据的下车经纬度所在的行政区
-
在数据集中添加行政区列
-
-
求出
seconds -
根据
borough计算平均等待时间, 是一个聚合操作
-
GeoJSON 是什么
-
-
-
定义
-
GeoJSON是一种基于JSON的开源标准格式, 用来表示地理位置信息 -
其中定了很多对象, 表示不同的地址位置单位
-
-
如何表示地理位置
类型 例子 点

{ "type": "Point", "coordinates": [30, 10] }线段

{ "type": "Point", "coordinates": [30, 10] }多边形
{ "type": "Point", "coordinates": [30, 10] }
{ "type": "Polygon", "coordinates": [ [[35, 10], [45, 45], [15, 40], [10, 20], [35, 10]], [[20, 30], [35, 35], [30, 20], [20, 30]] ] } -
数据集
-
行政区范围可以使用
GeoJSON中的多边形来表示 -
课程中为大家提供了一份表示了纽约的各个行政区范围的数据集, 叫做
nyc-borough-boundaries-polygon.geojson
-
-
使用步骤
-
创建一个类型
Feature, 对应JSON文件中的格式 -
通过解析
JSON, 创建Feature对象 -
通过
Feature对象创建GeoJSON表示一个地理位置的Geometry对象 -
通过
Geometry对象判断一个经纬度是否在其范围内
-
总结
-
6.2. 工具介绍
-
目标和步骤
- JSON4S 介绍
-
-
介绍
一般在
Java中, 常使用如下三个工具解析JSON-
GsonGoogle开源的JSON解析工具, 比较人性化, 易于使用, 但是性能不如Jackson, 也不如Jackson有积淀 -
JacksonJackson是功能最完整的JSON解析工具, 也是最老牌的JSON解析工具, 性能也足够好, 但是API在一开始支持的比较少, 用起来稍微有点繁琐 -
FastJson阿里巴巴的
JSON开源解析工具, 以快著称, 但是某些方面用起来稍微有点反直觉
-
-
什么是
JSON解析
-
读取
JSON数据的时候, 读出来的是一个有格式的字符串, 将这个字符串转换为对象的过程就叫做解析 -
可以使用
JSON4S来解析JSON,JSON4S是一个其它解析工具的Scala封装以适应Scala的对象转换 -
JSON4S支持Jackson作为底层的解析工具
-
-
Step 1: 导入
Maven依赖<!-- JSON4S --> <dependency> <groupId>org.json4s</groupId> <artifactId>json4s-native_2.11</artifactId> <version>${json4s.version}</version> </dependency> <!-- JSON4S 的 Jackson 集成库 --> <dependency> <groupId>org.json4s</groupId> <artifactId>json4s-jackson_2.11</artifactId> <version>${json4s.version}</version> </dependency> -
Step 2: 解析
JSON-
步骤
-
-
解析
JSON对象 -
序列化
JSON对象 -
使用
Jackson反序列化Scala对象 -
使用
Jackson序列化Scala对象
代码
-
-
import org.json4s._ import org.json4s.jackson.JsonMethods._ import org.json4s.jackson.Serialization.{read, write}
-
-
case class Product(name: String, price: Double)
val product =
“”"
|{“name”:“Toy”,“price”:35.35}
“”".stripMargin// 可以解析 JSON 为对象
val obj: Product = parse(product).extra[Product]// 可以将对象序列化为 JSON
val str: String = compact(render(Product(“电视”, 10.5)))// 使用序列化 API 之前, 要先导入代表转换规则的 formats 对象隐式转换
implicit val formats = Serialization.formats(NoTypeHints)// 可以使用序列化的方式来将 JSON 字符串反序列化为对象
val obj1 = readPerson// 可以使用序列化的方式将对象序列化为 JSON 字符串
GeoJSON 读取工具的介绍
val str1 = write(Product(“电视”, 10.5))GeometryEngine.contains(geometry, other, csr) (3)
总结1 读取 JSON生成Geometry对象2 重点: 一个 Geometry对象就表示一个GeoJSON支持的对象, 可能是一个点, 也可能是一个多边形3 判断一个 Geometry中是否包含另外一个Geometry6.3. 具体实现
-
目标和步骤
- 解析 JSON
case class Feature(
id: Int,
properties: Map[String, String],
geometry: JObject
)case class FeatureProperties(boroughCode: Int, borough: String)
-
Step 2: 将
JSON字符串解析为目标类对象创建工具类实现功能
object FeatureExtraction { def parseJson(json: String): FeatureCollection = {
implicit val format: AnyRef with Formats = Serialization.formats(NoTypeHints)
val featureCollection = readFeatureCollection
featureCollection
}
}-
Step 3: 读取数据集, 转换数据
val geoJson = Source.fromFile("dataset/nyc-borough-boundaries-polygon.geojson").mkString val features = FeatureExtraction.parseJson(geoJson) -
解析 GeoJSON
def getGeometry: Geometry = { (2)
GeometryEngine.geoJsonToGeometry(compact(render(geometry)), 0, Geometry.Type.Unknown).getGeometry
}
}在出租车 DataFrame 中增加行政区信息1 geometry对象需要使用ESRI解析并生成, 所以此处并没有使用具体的对象类型, 而是使用JObject表示一个JsonObject, 并没有具体的解析为某个对象, 节省资源2 将 JSON转为Geometry对象val boroughUDF = udf(boroughLookUp)
-
Step 4: 测试转换结果, 统计每个行政区的出租车数据数量
-
动机: 写完功能最好先看看, 运行一下
taxiClean.groupBy(boroughUDF('dropOffX, 'dropOffY)) .count() .show() -
-
总结
7. 会话统计
-
目标和步骤
- 会话统计的概念
-
-
需求分析
-
需求
统计每个行政区的平均等客时间
-
需求可以拆分为如下几个步骤
-
按照行政区分组
-
在每一个行政区中, 找到同一个出租车司机的先后两次订单, 本质就是再次针对司机的证件号再次分组
-
求出这两次订单的下车时间和上车时间只差, 便是等待客人的时间
-
针对一个行政区, 求得这个时间的平均数
-
-
问题: 分组效率太低
分组的效率相对较低
-
分组是
Shuffle -
两次分组, 包括后续的计算, 相对比较复杂
-
-
解决方案: 分区后在分区中排序
-
按照
License重新分区, 如此一来, 所有相同的司机的数据就会在同一个分区中 -
计算分区中连续两条数据的时间差

上述的计算存在一个问题, 一个分组会有多个司机的数据, 如何划分每个司机的数据边界? 其实可以先过滤一下, 计算时只保留同一个司机的数据 -
-
无论是刚才的多次分组, 还是后续的分区, 都是要找到每个司机的会话, 通过会话来完成功能, 也叫做会话分析
-
功能实现
-
val boroughDurations = sessions.mapPartitions(trips => {
val viter = trips.sliding(2)
.filter(_.size == 2)
.filter(p => p.head.license == p.last.license)
viter.map(p => boroughDuration(p.head, p.last))
}).toDF(“borough”, “seconds”) -
Step 4: 统计数据
boroughDurations.where("seconds > 0") .groupBy("borough") .agg(avg("seconds"), stddev("seconds")) .show() -
总结















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









