






前言:
上一篇中我们通过官方所给的yolov11n.pt模型和自己的数据集来训练自己的模型,这次我们来学习如何继续训练自己的模型来提高识别精度。
1.上一篇中我们通过通过官方所给的模型训练完以后会生成以下文件,如图: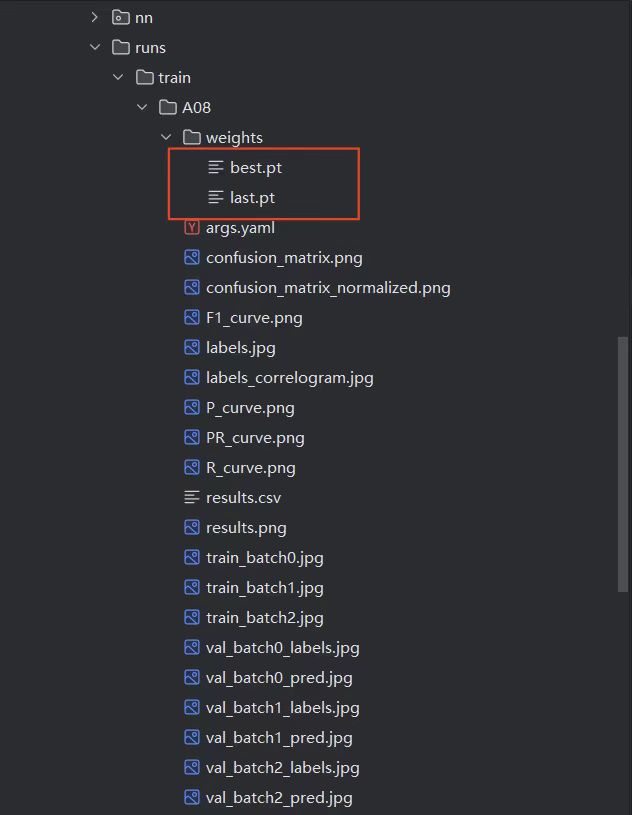
其中,best.pt 文件是当前训练结束后所生成的“最优模型”,last.pt是用于“继续训练”的模型。
2.打开我们的train.py文件,然后将里面的模型路径换成last.pt文件的路径,如图: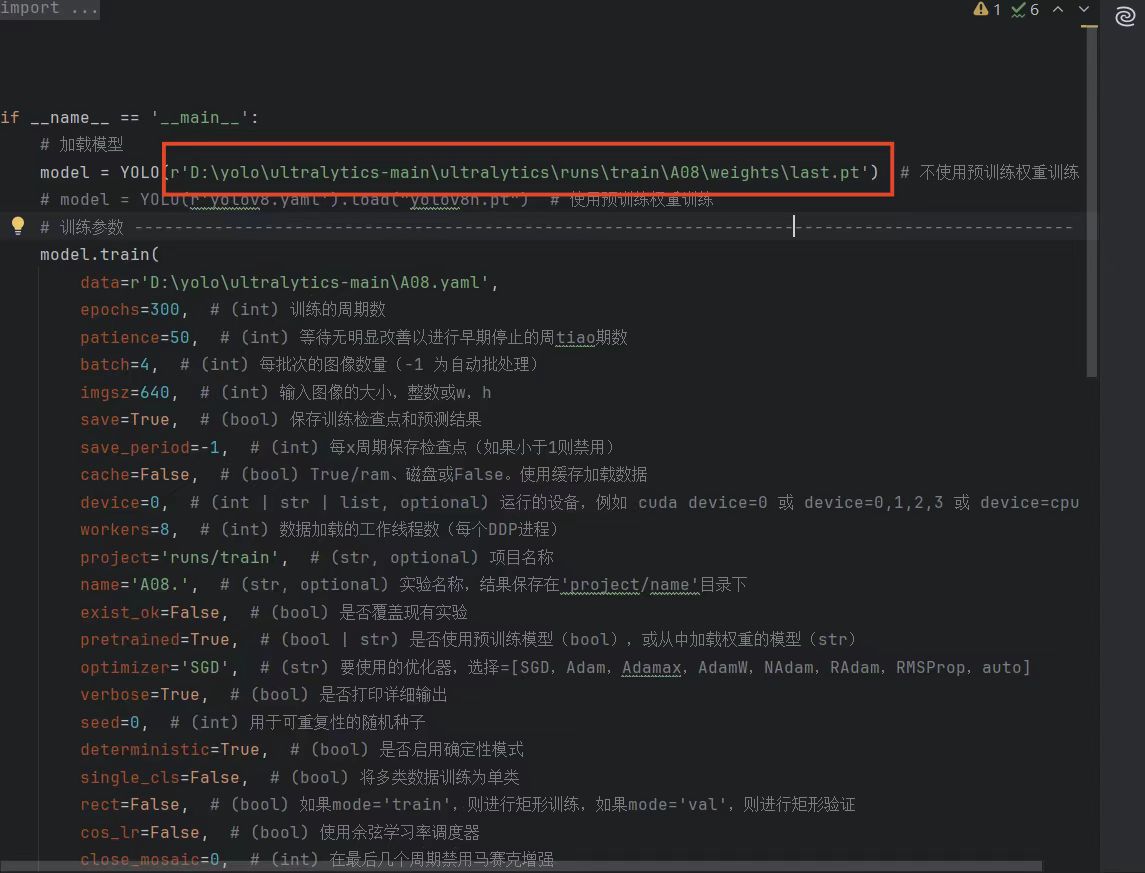
3.再继续训练时我们的数据集也是需要更换的,数据集的格式和之前的一样,只需要更改一下.yaml文件中的路径,如图: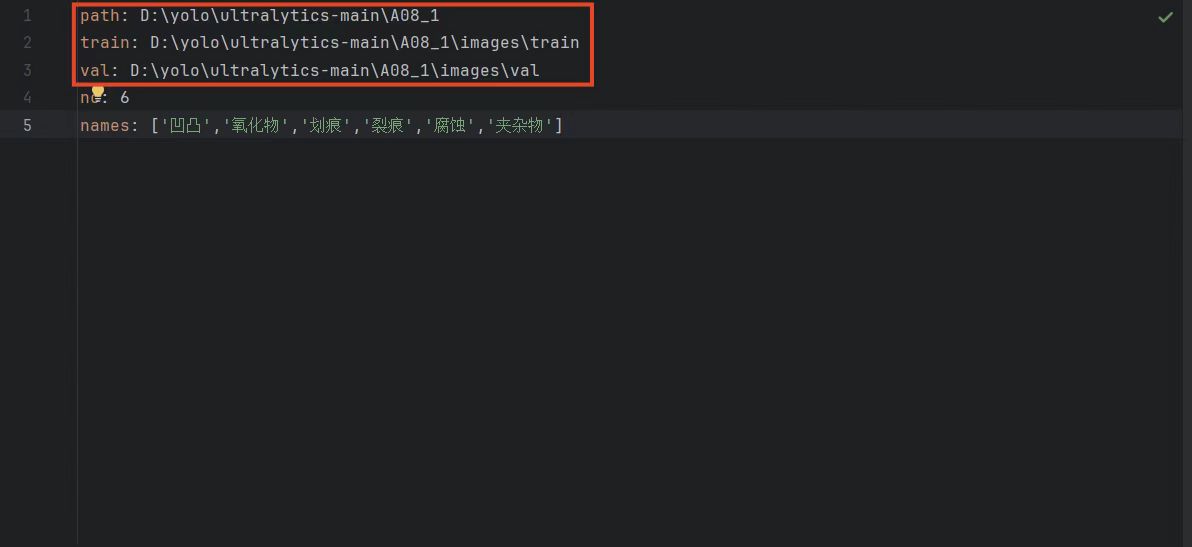 比如我上次的数据集文件夹是“A08”,这次的数据集文件夹呢就叫“A08_1”,这样我们修改路径时方便一点。
比如我上次的数据集文件夹是“A08”,这次的数据集文件夹呢就叫“A08_1”,这样我们修改路径时方便一点。
4.这样配置完成后我就可以重新运行train.py文件,等它训练完成后会继续生成best.pt和last.pt文件,以此往复就可以不断提高我们的模型精度。
总结:
通过以上方法,我们就可以不断训练我们自己的模型了,训练集的图片数我建议一次标注200~400张;因为这样我们可以一次性标注完不会遗漏和出错,同时这样操作会使训练时间短一点(因为我觉得大多数小伙伴用的应该都是笔记本电脑吧!),这样做的弊端就是我们的训练次数需要多一点来达到我们所需要的识别精度。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









