







 本文介绍了如何利用rvest包爬取猎聘网的招聘信息,包括职位、链接、薪水、工作地点、教育背景和工作经验等信息,并对提取的数据进行合并,最终保存为CSV文件,为后续的数据分析做好准备。
本文介绍了如何利用rvest包爬取猎聘网的招聘信息,包括职位、链接、薪水、工作地点、教育背景和工作经验等信息,并对提取的数据进行合并,最终保存为CSV文件,为后续的数据分析做好准备。
前言
前不久,我用rvest包爬取了政府工作报告,通过jiebaR分词,并用wordcloud2进行了词云分析。点击查看 http://blog.csdn.net/wzgl__wh/article/details/72804687
今天,我们来用rvest包爬取猎聘网上的招聘信息。
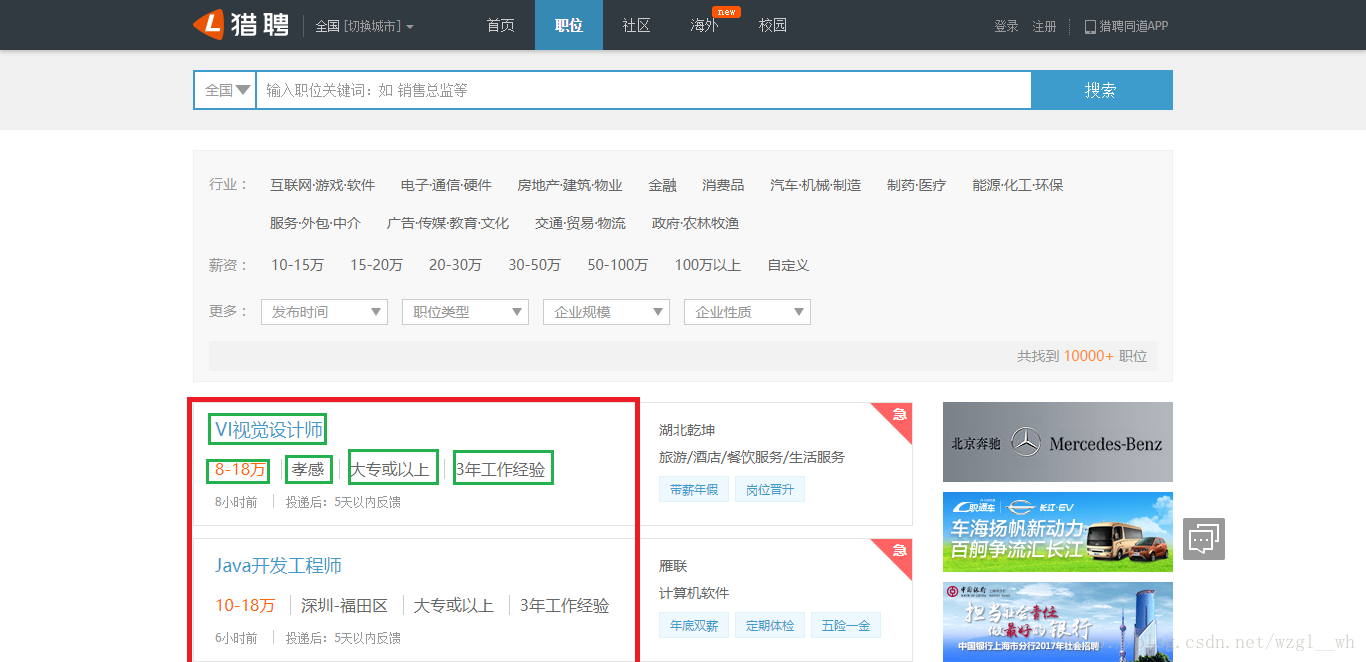
链接为 https://www.liepin.com/zhaopin/?init=1 。 打开的页面如上图,今天任务要爬取红色区域里面用绿色标记的那些信息,爬取完之后保存下来。
在开始之前,我先简单的介绍一下下面几个函数:
函数 |
作用 |
read_html() |
读取html文档 |
html_nodes() |
获得指定名称的网页元素、节点 |
html_text() |
获得指定名称的网页元素、节点文本 |
html_attrs() |
提取所有的属性名称及其内容 |
html_attr() |
提取指定的属性名称及其内容 |
html_tag() |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









