






一、问题的分析
在对352个城市进行综合评价以选出“最令外国游客向往的50个城市”时,需要考虑多个关键因素,以确保评选结果符合外国游客的游览偏好。
-
评估指标定义
在评选“最令外国游客向往的城市”时,我们需要综合考虑城市规模、环境保护、人文底蕴、交通便利、气候条件和地方美食。城市规模影响旅游设施和服务的丰富性,环境保护水平决定城市的清洁度和环保措施,人文底蕴提供独特的文化体验。交通便利性确保游客能轻松访问景点,适宜的气候提升游客舒适度,而丰富的地方美食则增加对城市的吸引力。 -
数据收集与准备
在对城市进行综合评价时,需要收集以下信息:城市规模的数据,包括人口和区域面积,以了解基础设施和服务水平;环境保护方面的数据,如空气质量和水质监测,以评估环保措施;人文底蕴,如历史遗迹、博物馆和图书馆,以展示文化丰富性;交通便利性,包括公共交通网络和主要交通枢纽,以评估景点的可达性;气候条件,如年均气温和降水量,以判断舒适度;以及餐饮业状况,包括特色餐厅和美食节,了解地方美食的吸引力。 -
综合评分模型
将上述因素的相关数据标准化,采用层次分析方法来计算每个城市的综合得分。各因素的权重可以根据外国游客的偏好进行调整。 -
排名与选择
根据综合得分对352个城市进行排序,选择得分最高的50个城市。
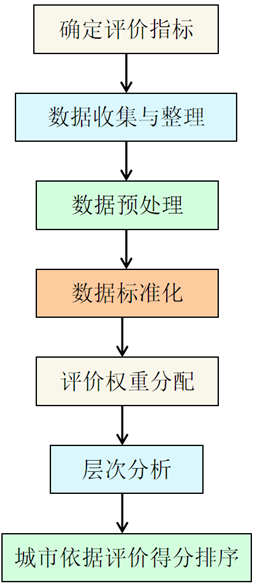
问题2的研究思路如图5-1所示:
二、数据收集
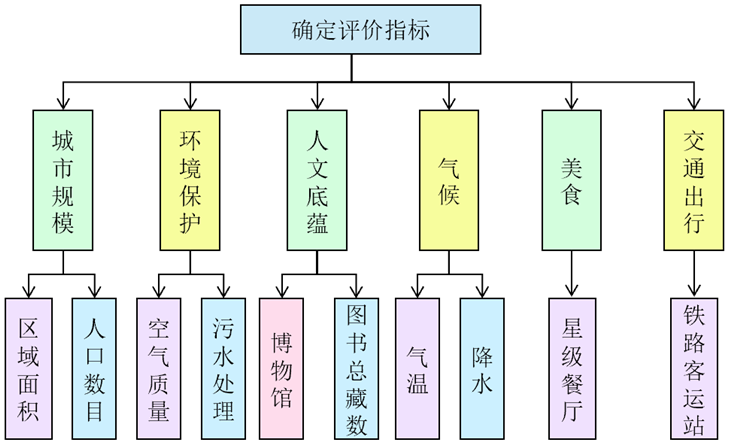
为了评选“最令外国游客向往的城市”,我们首先需要确定以下评价指标:城市规模用以了解其旅游设施和服务能力;环保指标用以评估城市的环保水平;人文底蕴用以展示城市的文化丰富性;交通便利性以确保游客的出行便利;气候条件以判断游客的舒适度;美食方面则用以吸引游客的味蕾。评价指标如图5-2所示。
*

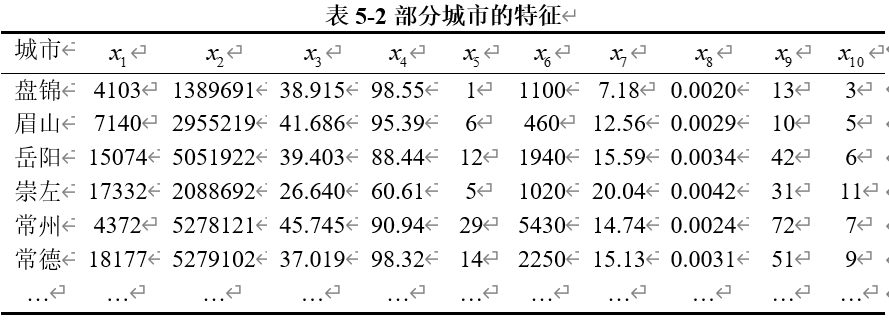
我们在进行数据收集和分析的过程中,整理了部分关键数据,如表5-2所示。这个表格详细列出了各城市在5分景点数量上的分布情况,为我们深入了解旅游景点的质量和分布提供了基础信息。通过这些数据,我们能够清晰地看到每个城市在高评分景点方面的表现,从而揭示出它们在旅游资源上的优势和不足。
三、数据预处理
我们的数据集是通过整合来自多个公开数据源的资料而形成的。由于数据来源的多样性和复杂性,数据预处理成为关键步骤。这包括对数据进行清洗、检测并处理缺失值、识别和修正异常值,以及统一数据格式和标准化数据类型。这一过程确保了数据的一致性和可靠性,从而为后续的分析和建模打下坚实的基础。此外,我还会考虑数据的时间跨度和潜在的偏差,以提高模型的准确性和稳健性。
3.1 正态性检验
正态性检验的基本原理是通过比较样本数据的特征(如均值、方差、偏度、峰度)与正态分布的特征是否一致,来判断数据是否符合正态分布。如果检验统计量的值超过某个临界值,表明样本偏离正态分布的程度显著,则可以拒绝数据符合正态分布的假设。
以下是一些常用的正态性检验方法及其原理:
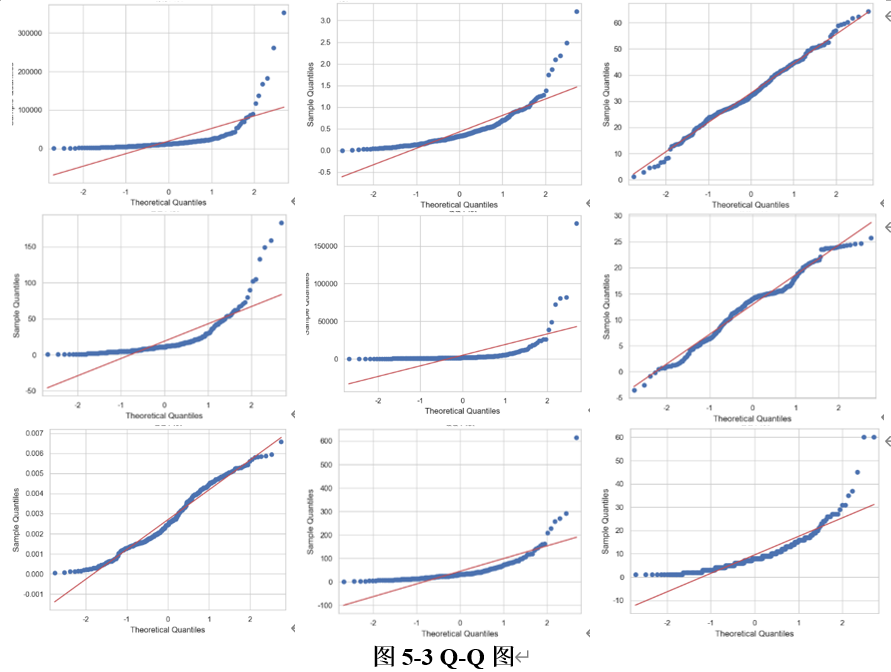
- Q-Q图
Q-Q图是一种用于比较两个分布的图形工具,特别常用于检验一个数据集是否来自某个特定分布(如正态分布)。它通过比较样本数据的分位数与理论分布的分位数来可视化地检查两者的相似性。
首先,将样本数据进行排序,计算出样本数据的分位数。分位数表示的是数据在分布中的位置,例如,第25个百分位数表示比25%的数据小的数值。假设数据来自某个特定的分布(如正态分布),根据该分布计算对应的分位数。对于正态分布,这些分位数可以通过该分布的累积分布函数得到。最后将样本数据的分位数作为纵轴,理论分布的分位数作为横轴,绘制散点图。如果样本数据的分布与理论分布一致,那么这些点应该接近一条45度的直线,即对角线。
如果Q-Q图中的点大致落在一条直线上,说明样本数据与理论分布(如正态分布)非常接近。
如图5-3所示,我们展示了数据集中各个特征的Q-Q图分布,以直观地分析这些特征是否符合正态分布。
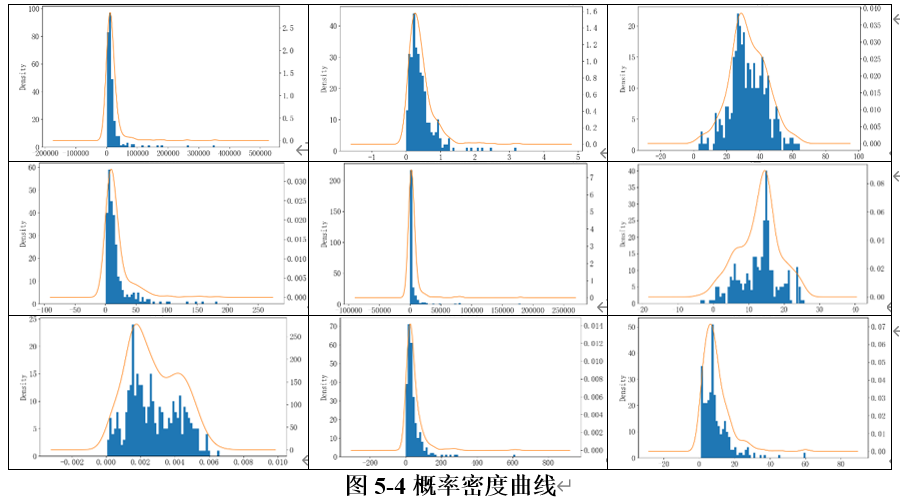
2. 直方图
通过绘制数据的直方图来观察数据的分布形态。如果直方图呈钟形对称分布,则数据可能符合正态分布。如图5-4所示。
3. 统计检验方法
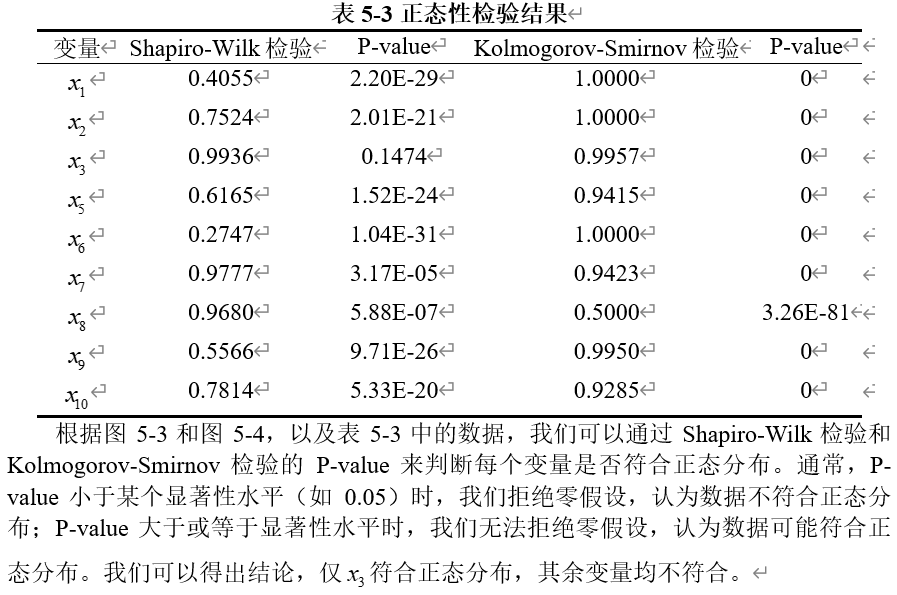
(1)Shapiro-Wilk 检验
Shapiro-Wilk检验是一个用于评估样本数据是否来自正态分布的统计检验。它通过计算样本数据的次序统计量(即排序后的数据)与正态分布下对应的期望次序统计量之间的差异来判断正态性。具体而言,该检验通过一个统计量 来衡量这种差异。如果 值接近1,则表示样本数据接近正态分布;如果 值显著偏离1,则说明样本数据偏离正态分布。当 值对应的p值小于某个显著性水平(如0.05)时,我们拒绝数据符合正态分布的假设。
(2)Kolmogorov-Smirnov (K-S) 检验
Kolmogorov-Smirnov (K-S) 检验用于比较样本的经验累积分布函数 (ECDF) 与假设的理论累积分布函数 (CDF) 之间的差异,以评估样本数据是否符合某个特定的分布(如正态分布)。K-S检验的核心在于计算样本ECDF与理论CDF之间的最大差异。如果这个差异显著,则表明样本数据不符合假设的分布。与Shapiro-Wilk检验相比,K-S检验不仅能用于正态性检验,还能用于其他分布的检验。
其检验结果如表5-3所示。
3.2 异常值检验

2. 箱型图
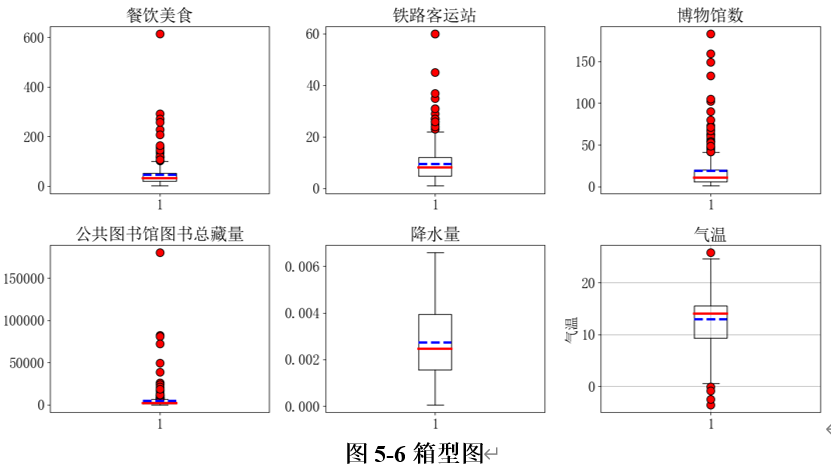
箱型图是一种直观的统计图表,用于显示数据的分布特性,并识别异常值。它通过五个数值总结数据集:最小值、第一四分位数 (Q1)、中位数 (Q2)、第三四分位数 (Q3)、和最大值。“胡须”从箱体延伸,通常表示从Q1减去1.5倍的IQR(Q3 - Q1)到Q3加上1.5倍的IQR范围内的数据点。任何超出“胡须”范围之外的数据点通常被视为异常值。这些点在箱型图上通常以单独的点标示,称为“离群点”或异常值。对不符合正态分布的变量绘制箱型图,如图5-6所示。
接下来我们将提取每个变量的具体异常值。通过识别和处理异常值,可以纠正错误数据、提高模型的准确性和鲁棒性,发现潜在的业务问题或机会,并更好地理解数据的整体分布和趋势。这一过程有助于减少数据噪声,改进分析和决策的效果,确保数据分析和建模的可靠性。
- 异常值分析
(1)区域面积
我们得到具体的异常值如表5-4所示。
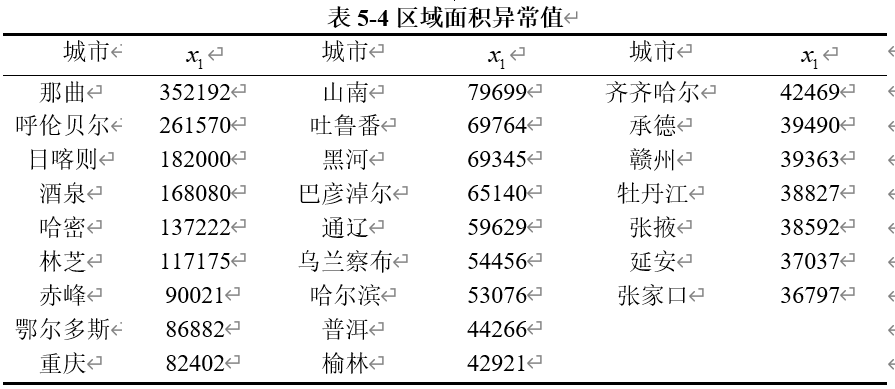
根据表格提供的数据,我们可以看到这些城市主要集中在中国的大西北和东北地区。这些地区的行政区域通常比较大,因此城市的面积也相对较大。那曲地区面积极大,是西藏自治区的一个地级地区,拥有广阔的无人区和草原。山南地区位于西藏的南部,地势较高,包含多个重要的河流源头。日喀则地区也是西藏的一个重要地区,面积较大,地形复杂,包括雪山和高原。哈密地区位于新疆的东部,拥有广阔的沙漠和戈壁地带。酒泉地区包括部分沙漠和戈壁,是一个面积较大的地区。巴彦淖尔地区地形以草原为主,属于大面积的草原地区。乌兰察布地区包括大量的草原和山区,面积较大。张掖地区以戈壁和沙漠为主,面积相对较大。通辽地区主要为草原,面积较广。鄂尔多斯地区包括沙漠和草原,面积较大。呼伦贝尔地区以广阔的草原和森林著称,是中国面积最大的地级市之一。
东北地区中,黑河地区包括大量的森林和湿地,地形广阔。牡丹江地区以森林和湖泊为主,面积适中。哈尔滨是黑龙江省的省会,周边有较大的森林和湿地,面积也较大。
其他地区中,承德地区包含多山地和森林,面积相对较大。赣州地区以丘陵和山地为主,面积适中。张家口地区以山地和草原为主,面积较大。赤峰地区以草原和丘陵为主,面积较大。普洱地区以森林和山地为主,面积适中。榆林地区以山地和沙漠为主,面积较大。
这些城市主要集中在大西北和东北地区,这些地区通常具有较大的行政区划面积。大西北和东北地区包括了广阔的草原、沙漠、山地和森林,这些地理特征导致了城市的面积较大。在这些区域中,城市的面积从几万到几十万平方公里不等,符合实际的地理和行政区域划分。因此,这些城市及其面积数据符合实际情况,不存在异常值。
(2)城市人口
我们得到具体的异常值如表5-5所示。
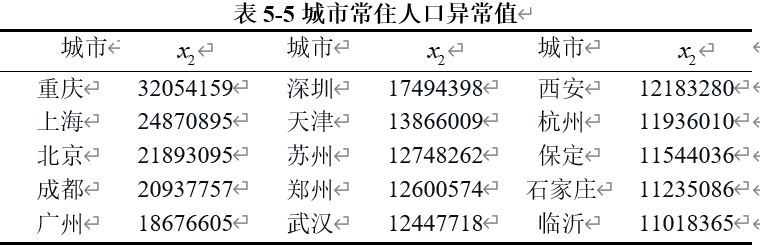
重庆、上海和北京等大城市的人口数非常高,分别为32,054,159、24,870,895和21,893,095。这些城市是中国的直辖市和经济中心,人口规模大是正常现象。大城市由于经济机会、教育资源和医疗设施的集中,通常吸引大量的人口流入,导致人口数据高于其他城市。
深圳、广州和杭州等东部沿海城市的人口数也相对较高。这些城市经济发达,生活水平高,吸引了大量的内地人口迁移。东部沿海地区作为中国经济最发达的区域,吸引了大量的移民和外来务工人员,因此这些城市的人口相对较多。
城市如西安、苏州、郑州和石家庄的人口数在一千多万到两千多万之间。这些城市虽然没有达到顶尖大城市的规模,但作为省会城市或重要经济城市,人口数据在合理范围内。
其他城市如保定和临沂的人口数据虽然不如一线城市高,但在其区域内仍然是人口集中的城市。
根据上述分析,提供的城市人口数据是合理的,没有发现异常值。这些数据反映了中国城市人口的真实分布情况,显示出大城市和东部沿海城市由于经济发展和生活条件的优势,吸引了大量人口。中小城市的人口数据也在预期范围内。因此,这些数据符合实际情况,不需要进一步处理。
(3)博物馆数的异常值
我们得到具体的异常值如表5-6所示。
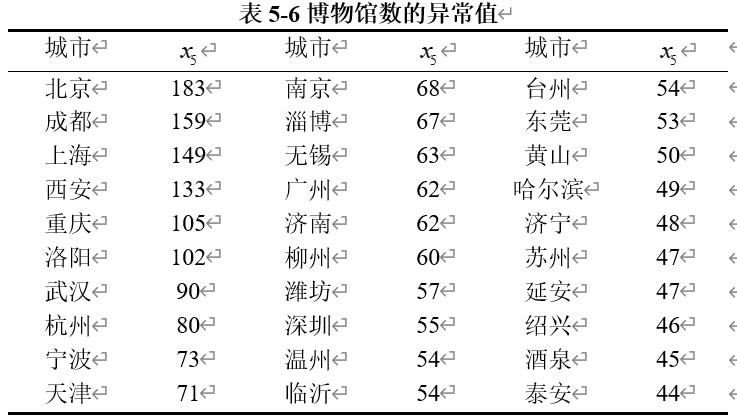
北京、上海、广州等城市是中国的主要经济和文化中心。作为国家的政治、经济和文化重心,这些城市拥有丰富的历史遗产和文化资源,博物馆的数量较多反映了这些城市对文化和历史保护的重视。
城市如西安和洛阳拥有丰富的历史遗产和文化资源。作为历史悠久的城市,这些地方的博物馆数量多,展示了其深厚的历史文化背景。
南京、成都等城市有众多的教育和科研机构。这些机构往往推动地方博物馆的建设,以促进学术研究和公众教育,提高市民的文化素养。
大城市如重庆、武汉和杭州通常人口众多,对公共文化设施的需求也相对较高。博物馆作为文化设施的重要组成部分,这些城市建设了较多的博物馆来满足市民的文化需求。
在一些城市,政府对公共文化设施的支持和投入也促进了博物馆的建设。例如,东莞、无锡等城市的政府政策可能鼓励了博物馆的建设和运营,以提升城市的文化形象和市民的文化福利。
城市如黄山、温州和酒泉以其独特的旅游资源吸引了大量游客。博物馆作为展示城市文化和历史的重要场所,常常得到地方政府和企业的支持,以促进旅游业和城市发展。
在一些城市,如淄博、潍坊和柳州,对公共文化设施的重视体现在博物馆的数量上。这些城市可能通过文化项目和公共建设提升市民的文化生活质量。
这些因素共同作用,使得这些城市在博物馆建设上有较高的投入和发展,反映了其对文化传承和公众教育的重视。因此,这些数据符合实际情况,不需要进一步处理。
(4)公共图书馆图书总藏量的异常值
我们得到具体的异常值如表5-7所示。
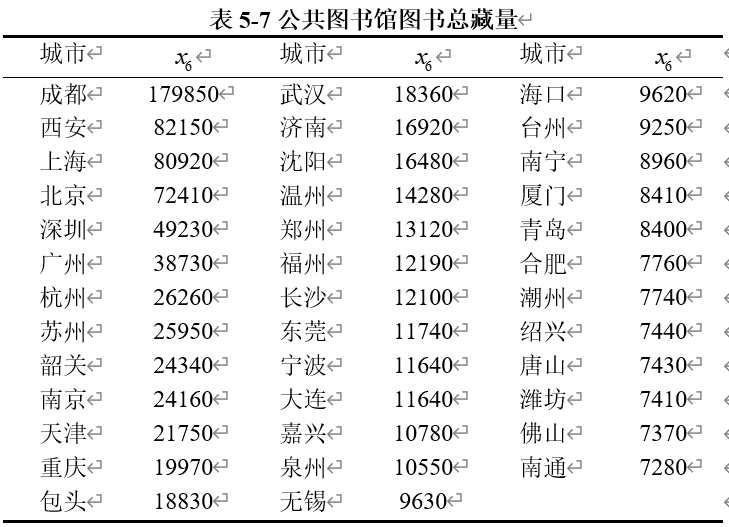
成都、武汉、上海等城市是中国的主要经济和文化中心。这些城市由于经济实力强、文化氛围浓厚,公共图书馆的图书总藏量通常较高,以满足市民的阅读和研究需求。
深圳、广州、北京等大城市拥有较大的人口规模。大规模的人口需求推动了公共图书馆的建设和资源积累,从而提高了图书馆的图书总藏量。
城市如西安、南京和苏州拥有众多的高等教育和科研机构。这些城市的图书馆往往需要提供大量的书籍和资源以支持学术研究和教育工作,因此图书总藏量较高。
郑州、合肥等城市的公共图书馆可能得到政府的政策支持和资金投入,促进了图书馆资源的丰富。政府对公共文化设施的投入和重视有助于提升图书馆的图书藏量。
城市如杭州、东莞和宁波在城市发展过程中注重文化设施建设。这些城市可能因对文化需求的重视而建设了大量图书馆,并积累了丰富的图书资源。
台州、温州和福州等城市的图书馆图书总藏量较高,可能与其本地文化资源的丰富性、经济发展水平以及对公共文化服务的投入有关。
这些城市的高图书总藏量可以归因于多种因素,包括经济和文化中心的地位、丰富的教育资源、大规模的人口、政府政策支持以及对公共文化设施的重视。这些因素共同作用,使得这些城市在公共图书馆的建设上投入较多,从而提高了图书总藏量的数量。因此,这些数据符合实际情况,不需要进一步处理。
(5)星级餐厅的异常值
我们得到具体的异常值如表5-8所示。
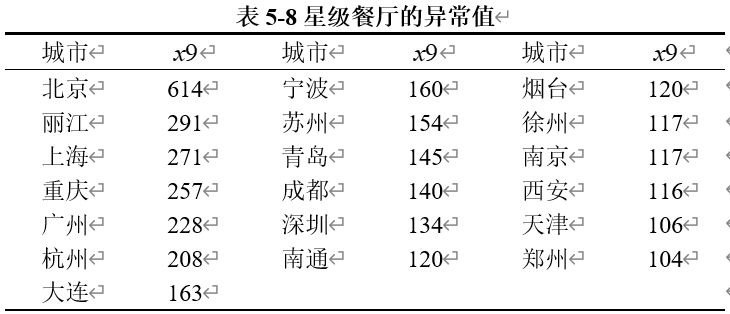
这些城市中星级餐厅数量较高,反映了其在经济发展、旅游业、文化多样性、以及美食文化等方面的特点。
北京、上海、广州等城市是中国的主要经济中心。这些城市不仅经济繁荣,而且居民的消费能力较高,因此对高端餐饮的需求也更大。星级餐厅数量的多寡往往与城市的经济水平成正比。
丽江、杭州和大连等城市是著名的旅游胜地。这些地方因旅游业发达,吸引了大量国内外游客,推动了高档餐饮业的发展。星级餐厅不仅为游客提供高质量的餐饮体验,也成为城市吸引游客的亮点之一。
成都、重庆和西安等城市以其丰富的美食文化闻名。作为中国重要的美食城市,这些地方的餐饮文化多样性极高,星级餐厅也反映了这些城市的饮食文化和美食传统的延续与创新。
深圳、苏州和宁波等城市因其活跃的商业环境和经济活动,吸引了大量的商务人士和高收入群体。这种高收入群体的存在推动了高端餐饮市场的发展,星级餐厅的数量也因此较多。
南京、天津、郑州等城市具有较大的人口基数和密集的城市布局,带来了巨大的餐饮市场需求。这些城市的居民消费水平较高,对高端餐饮的需求也随之增加。
南通、青岛、烟台等城市的星级餐厅数量相对较高,可能与这些城市在区域发展中经济的快速增长以及居民消费升级有关。随着城市经济水平的提升,居民对于高品质生活的追求也带动了高端餐饮行业的发展。
综合这些因素,可以得出结论:这些城市的星级餐厅数量反映了其在经济、文化、旅游、和美食领域的强大实力,属于正常现象,不需要进行异常处理。
3.2 缺失值


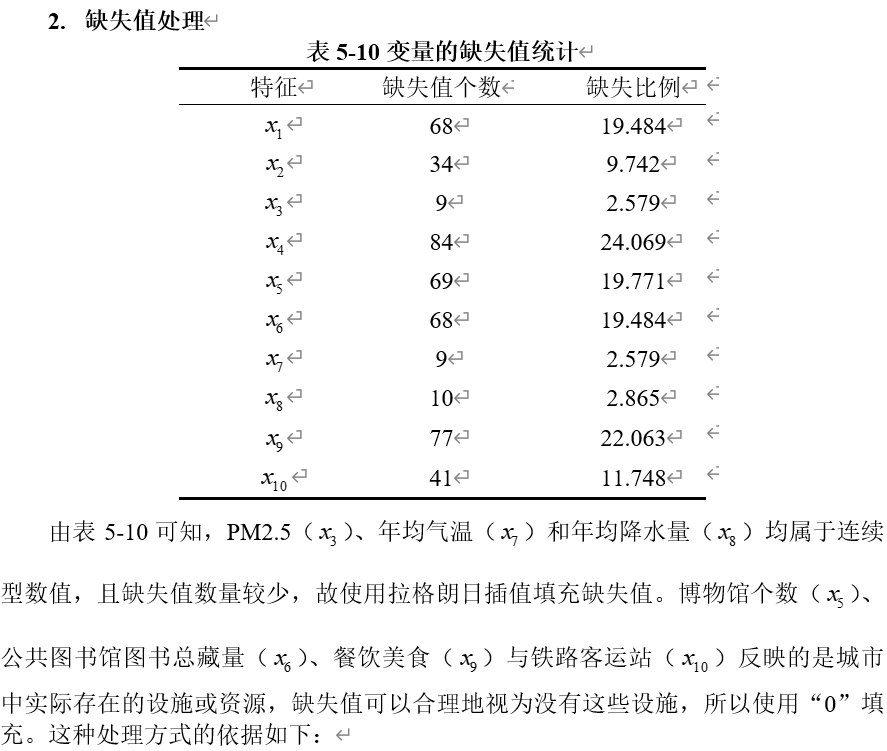
(1)设施的物理存在性:这些特征表示的是某种设施或资源在城市中的实际存在或数量。如果数据中缺少某城市的相关值,可能意味着该城市确实没有这类设施。例如,一个城市没有铁路客运站,那么在此数据特征中用“0”表示是合乎逻辑的。
(2)数据的稀缺性与完整性:在很多情况下,数据缺失可能是因为相关设施在某些城市并不存在,而不是由于数据收集过程中的疏漏。因此,将缺失值填充为“0”能够更准确地反映城市的实际情况,而不至于因为误填充其他值而产生偏差。
(3)避免误导性分析:若将缺失值用其他方式填充(如均值填充),可能会引入偏差,导致误导性的分析结果。因此,直接将缺失值填充为“0”更为合理。
综上所述,针对这几个特征的缺失值填充为“0”是合理且有效的做法,这样可以保持数据的真实性与完整性,确保分析结果的准确性。

由于保留这些样本可能存在以下弊端:
(1)影响结果的准确性和一致性:与城市相关的分析通常需要结合人口、面积等基本特征,而这些样本存在数据缺失或不匹配的情况,无法体现真实的城市特征,容易导致结果偏差。
(2)带来误导性结果:在后续分析中,使用包含旅游景点或城市辖区的数据集可能会误导模型,进而得出不准确的结论。例如,基于区域面积和城市人口的聚类分析或模型预测可能会受到这些无效样本的影响。
因此,本文删除上述无关样本,将分析的重点放在剩下的281个城市上。这有助于聚焦分析目标有助于提高分析的精准度,确保结果更加符合预期和实际情况。
四、模型的建立




五、模型的求解
在选择旅游目的地时,游客会综合考虑多种因素,其中空气质量、气温、美食和交通便利性等因素对游客的吸引力最大,这些指标直接影响游客的舒适度、便利性和整体旅游体验。而区域面积、城市人口、气候条件、博物馆数量等因素则在一定程度上影响着旅游吸引力。公共图书馆的藏书量对大多数游客来说影响较小。
如表5-13所示,我们总结了建立的特征对于游客的重要程度。这些分析帮助我们更好地理解游客的偏好和决策过程,也为城市旅游发展和规划提供了重要参考。


基于上述对十个指标的详细分析,我们可以构建一个判断矩阵。这个矩阵将各指标的重要性进行量化和对比,通过对这些因素的相对重要性进行分析,我们能够更系统、更科学地评估各个城市的旅游吸引力。矩阵不仅帮助我们明确哪些因素对旅游决策起到关键作用,也为进一步的多因素分析和综合评估奠定了基础,从而为城市规划和旅游资源优化提供了更有力的数据支持和决策依据。

这个判断矩阵展示了十个特征之间的相对重要性,每个元素表示在两个特征之间,哪一个更重要以及重要程度的比值。矩阵中的元素是以特征的对比为基础的,数值越大表示行特征比列特征更重要,反之亦然。
餐饮美食和铁路客运站在矩阵中占据了最高的重要性,表明饮食和交通便利性对游客的吸引力最大。PM2.5均值、气温和降水量等环境和气候条件也被认为是较为重要的因素,尤其是在与区域面积和公共图书馆图书总藏量相比时,显示空气质量和气候对旅游体验的显著影响。城市人口的重要性居中,反映出它在整体旅游吸引力中的影响力较为适中,但不如餐饮和交通关键。相对而言,区域面积和公共图书馆图书总藏量对游客的吸引力较小,显示出这些特征对旅游吸引力的影响较为有限。污水处理率的重要性位于中间位置,尽管它对环保有直接影响,但对游客的感知可能不如交通、饮食或气候条件直接重要。博物馆数显示出了一定的人文旅游吸引力,但总体来说,其重要性低于前述主要因素。
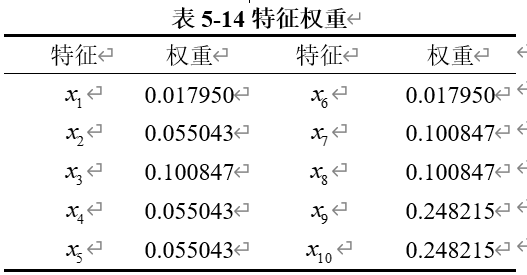
根据判断矩阵,我们利用AHP对各个特征进行了权重计算,结果如表5-14所示。通过这种方法,我们能够客观地量化各特征的重要性,从而明确每个因素在整体评价中的相对影响力。这些权重不仅反映了不同特征在决策过程中的优先级,还为我们提供了更科学的依据,用于优化旅游资源配置、提升城市吸引力和制定相关政策。这一分析结果有助于深入理解游客的偏好,指导实际的旅游发展战略。
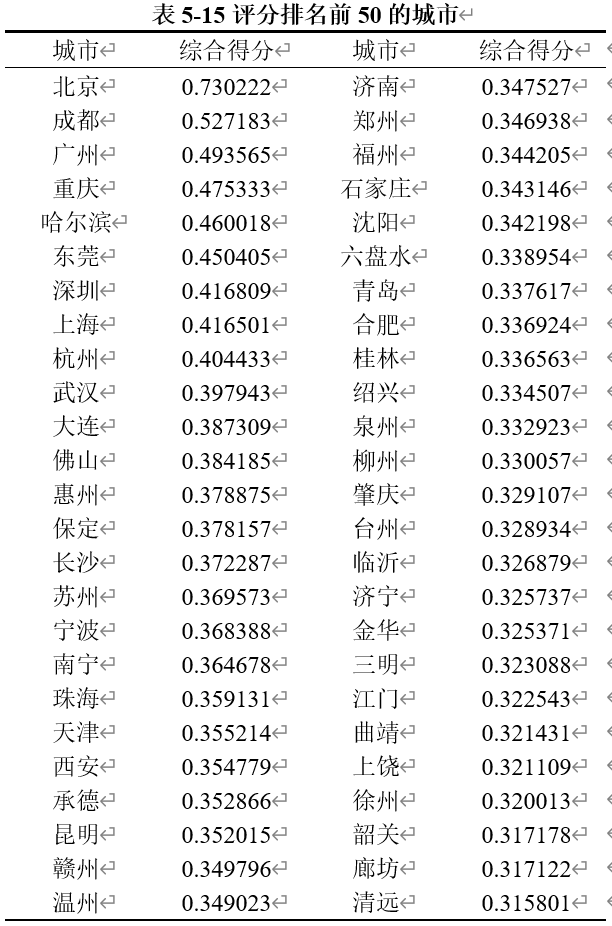
基于特征权重的计算结果,我们进一步计算了每个城市的综合得分,从而得出各城市在旅游吸引力方面的整体排名。根据这些综合得分,我们筛选出了得分最高的前五十个城市,如表5-15所示。
六、本章小结
在本章中,我们系统地评估了352个城市的多项关键因素,旨在选出最令外国游客向往的50个城市。首先,我们明确了评估指标的定义,综合考虑了城市规模、环境保护、人文底蕴、交通便利、气候条件以及地方美食等因素,这些指标直接影响了城市对外国游客的吸引力。接着,我们详细阐述了数据收集与准备的过程,确保所收集的数据涵盖了各个评估指标,能够准确反映城市的综合实力和吸引力。
我们通过标准化处理这些数据,并采用层次分析法(AHP)构建综合评分模型,以量化每个城市在各项指标上的表现。通过这种方法,我们能够合理地分配权重,精确计算出每个城市的综合得分。最终,我们根据综合得分对所有城市进行了排序,从中选出了得分最高的50个城市,作为最令外国游客向往的城市名单。
然而,单一的模型方法可能会带来一定的偏差或局限性,因此为了进一步验证我们的选择的合理性,接下来的研究中将引入其他综合评价方法,如熵权法。
熵权法是一种基于信息熵理论的客观赋权方法,能够根据数据的差异性和不确定性来动态调整各指标的权重。通过使用熵权法,我们可以避免在层次分析法中可能存在的主观因素影响,从而进一步客观、公正地评价每个城市的吸引力。
在下一步的分析中,我们将把熵权法的结果与层次分析法的结果进行比较,分析两者的异同。通过这种方法,我们不仅可以验证最初选择的合理性,还可以通过对比分析,找到更为客观的综合评价方法,从而确保评选结果的科学性和公正性。
这种多模型的评估方法将为我们的研究提供更为全面的视角,帮助我们更准确地理解城市吸引力的各个维度,也为未来的综合评价研究提供了参考路径。最终,我们将综合多个模型的结果,对城市吸引力进行更加深入的分析,为提升城市的国际旅游形象和吸引力提供科学的依据和建议。
这一系列分析不仅为城市的旅游吸引力提供了一个科学的评价体系,也为各城市在国际旅游市场中的定位和发展提供了有价值的参考。通过这次评选,我们不仅深入了解了哪些城市在不同指标上表现突出,也为未来的城市规划和旅游推广提供了重要的数据支持。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











