









参考资料:
《【领域驱动设计】DDD五板斧》(视频教程)
前言
由于最近接触的新项目采用了DDD领取驱动设计的方式,网上对DDD的讲解文章很多都是偏理论的且很多都倾向于和微服务的结合,对一些朋友不太友好,因此本文计划直接以代码示例的方式来进行讲解,将抽象的概念具体化,让初学者也能快速入门。
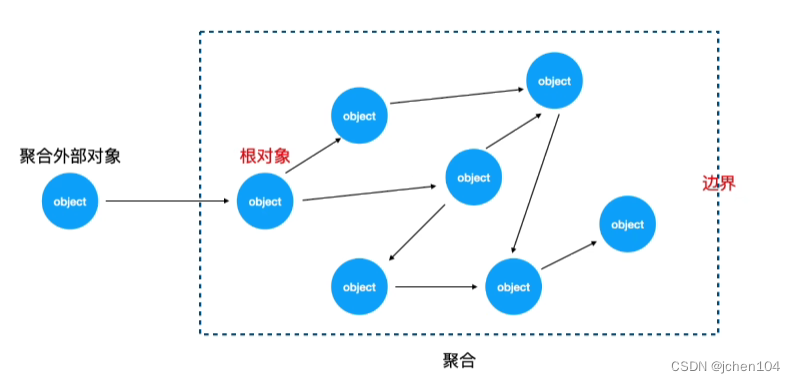
首先需要明确的是DDD是一种设计思想,用来指导整个系统的设计实现高内聚低耦合的目标,简单来说就是将不同的功能模块划分为一个个的领域,每个领域内都有一些领域对象(可以暂且理解为实体类),这些领域对象通过聚合封装在一起,外界看起来就像是一个大的对象,聚合内只有一个领域对象能与外界交互且能将聚合内的对象串联起来,这个对象被叫做聚合根。
DDD与我们常用的设计模式并不相同,可以将DDD理解为战略布局,而设计模式则是具体的战术打法,两者从不同的角度来优化我们系统的设计与开发。
目录
一、从贫血模型到充血模型
比如现在开发一个新客注册的功能:
(1)输入新客的姓名与手机号,查询出手机号的归属地与运营商
(2)根据归属地与运营商将客户分组
(3)按组别将客户分配给对应的销售人员
public class User {
Long userId;
String name;
String phone;
Long repId;
// set/get方法等
}
public class RegistrationServiceImpl implements RegistrationService {
// 销售对象DAO
private SalesRepRepository salesRepRepo;
// 用户对象DAO
private UserRepository userRepo;
public User register(String name, String phone)
throws ValidationException {
// 参数校验
if (name == null || name.length() == 0) {
throw new ValidationException("name");
}
if (phone == null || !isValidPhoneNumber(phone)) {
throw new ValidationException("phone");
}
// 获取手机号归属地编号和运营商编号 然后通过编号找到区域内的销售组
String areaCode = getAreaCode(phone);
String operatorCode = getOperatorCode(phone);
SalesRep rep = salesRepRepo.findRep(areaCode, operatorCode);
// 创建用户并入库
User user = new User();
user.name = name;
user.phone = phone;
if (rep != null) {
user.repId = rep.repId;
}
return userRepo.save(user);
}
private boolean isValidPhoneNumber(String phone) {
String pattern = "^0[1-9]{2,3}-?\\d{8}$";
return phone.matches(pattern);
}
private String getAreaCode(String phone) {
//...
}
private String getOperatorCode(String phone) {
//...
}
}这是一个很简单的功能,几乎和我们平时写的代码如出一辙,定义一个user类,然后在service层实现我们的业务逻辑、与DAO的交互等,逻辑简洁明了,即使是第一次接触这段代码的人也能迅速的理解其中的业务行为。
但是,这段示例是存在一些隐患的。首先来看实体类User,该类只有属性以及属性对应的set/get方法,在使用的时候也只是充当数据库的表结构映射。这看起来没什么问题,可我们回顾一下面向对象的定义会发现,对象应该是具备属性与行为的,简单来说就是这个类不单单要有属性,还要有与其相关行为的方法。
示例中的这种情况被称为失/贫血模型,即只有属性而失去了与其属性相关行为的方法。
然后再来看我们register方法的入参,这里传入的是2个String,我们在传入后还对这两个入参做了参数校验。这可能引发一些问题,首先是当我们调用方法时可能出现参数设置反了的情况,就像下面这样,虽然很低级但确实存在发生的可能(至少我本人和身边同事都遇到过,毕竟编译器只能帮我们校验参数类型)
// register(name,phone)
RegistrationServiceImpl.register("187xxx","CJ");假如后面业务拓展了,又需要实现按姓名和身份证或者其他方式等,这两个参数还是String类型,重载无法帮我们区分这两个方法,我们就只能通过修改方法名(专业术语叫方法签名)来实现区分。
public User registerByPhone(String name, String phone)
public User registerByIdCard(String name, String IdCard)
public User registerByPhoneAndIdCard(String phone, String IdCard)
在一个稳定运行的系统里修改已使用多时的方法名无疑给自己找麻烦,首先本系统中使用register方法的调用处全部需要修改,如果别的工程以jar包或者接口的形式引用了这个方法,将会产生蝴蝶效应,波及甚广。
再就是参数校验,如果出现上文中的情况,出现了多种不同的注册模式,那么每个方法中都需要类似下面这样的校验逻辑,这必然会产生大量的重复代码,如果出现校验逻辑变动,又会导致多个方法的修改。
// 参数校验
if (name == null || name.length() == 0) {
throw new ValidationException("name");
}
if (phone == null || !isValidPhoneNumber(phone)) {
throw new ValidationException("phone");
}一种解决方案是将校验逻辑工具化,例如下文这样
class ValidationUtil{
boolean isValidPhone(String phone){
// ...
}
boolean isValidIdCard(String idCard){
// ...
}
}
public User registerByPhoneAndIdCard(String phone,String idCard){
ValidationUtil.isValidPhone(phone);
ValidationUtil.isValidIdCard(idCard);
}看起来似乎是个不错的选择,但却不是最佳实践,首先随着参数类型的增加,工具类中的校验逻辑也会不断膨胀,我们的业务方法中也需要显性的调用这些校验逻辑,又会造成register方法的膨胀。另外,业务方法中调用校验逻辑如果失败则需要抛出异常,这容易导致参数校验异常与业务异常混合起来,不太合理。
整理一下我们目前为止可以预见到的一些问题,对我们的方法设计提出了以下要求:
(1)明确方法中的参数类型,能区分每个参数,并且最好能自带校验逻辑
(2)参数校验逻辑内聚,方便复用且能与业务异常解耦
为了解决这个问题,我们可以将手机号定义为一个自定义的类PhoneNumber,这样方法中的2个参数就可以区分开来了,然后我们再将参数校验逻辑给封装到这个自定义的类中,在构建对象时便进行参数校验,这样我们的业务方法接收到的参数必然是已经参数校验过了的对象,自然而然地将参数校验异常与业务逻辑异常实现了区分。
经过改在后的代码如下,这样通过自定义类型既区分了每个方法中的参数,也使得该方法可以通过参数类型实现重载。另外不同的参数校验分别内聚到了对应自定义的类中,将修改范围最小化,且每个参数的校验逻辑在自定义对象创建时就完成了,业务方法完全不用担心参数校验的问题,内部可以专注于业务逻辑的实现。
public class PhoneNumber {
private final String number;
private final String pattern = "^0?[1-9]{2,3}-?\\d{8}$";
public String getNumber() {
return number;
}
// 仅存在有参构造器,创建对象时即进行参数校验
public PhoneNumber(String number) {
if (number == null) {
throw new ValidationException("number不能为空");
} else if (isValid(number)) {
throw new ValidationException("number格式错误");
}
this.number = number;
}
private boolean isValid(String number) {
return number.matches(pattern);
}
}
public class User {
Long userId;
String name;
PhoneNumber phone; // 号码由String类型变为了自定义类型
Long repId;
}
public class RegistrationServiceImpl implements RegistrationService {
// 销售对象DAO
private SalesRepRepository salesRepRepo;
// 用户对象DAO
private UserRepository userRepo;
public User register(String name, PhoneNumber phone) {
// 获取手机号归属地编号和运营商编号,然后通过编号找到区域内的SalesRep
String areaCode = getAreaCode(phone);
String operatorCode = getOperatorCode(phone);
SalesRep rep = salesRepRepo.findRep(areaCode, operatorCode);
// 创建用户并入库
User user = new User();
user.name = name;
user.phone = phone;
if (rep != null) {
user.repId = rep.repId;
}
return userRepo.save(user);
}
private String getAreaCode(PhoneNumber phone) {
//...
}
private String getOperatorCode(PhoneNumber phone) {
//...
}
}PhoneNumber类不仅具备了属性,还拥有了与其属性相关联的行为,这被称为是充血模型,通过这个例子我们可以发现充血模型可以有效的将对象的行为内聚起来,当涉及到该对象的行为变动时我们也可以将修改范围控制在该类中。
像PhoneNumber这种类型的自定义对象在DDD中被称为是值对象。值对象在代码中有这样两种形态。如果值对象是单一属性,则直接定义为实体类的属性;如果值对象是属性集合,则把它设计为 Class 类,Class 将具有整体概念的多个属性归集到属性集合,这样的值对象没有 ID,会被实体整体引用。

参数类型的问题说完了,我们再来看看业务方法的内部逻辑,这里有一块内容是获取归属地和运营商,其目的是为了查找出对应的销售组,用来构建User对象。但是我们思考一下如果将注册这个行为视为一个领域,那么对他最简单的描述就应该是“拿到用户信息并存储起来”,这里的获取归属地和运营商只是为了获取用于注册用户信息的销售的数据,重点是销售而不是获取归属地和运营商,换句话说只要能获取到销售那么这两个行为是可以被剔除出注册这个领域的。
那么如何改造这个逻辑呢?
第一种思路是调整方法入参,因为这两个参数都是根据手机号的附加信息查询的,这里可以绕过中间的介质简化为直接传入手机号来查询销售组。当然这是建立在我们可以修改findRep方法的基础上的,如果该方法是例如外部接口这样的无法修改的情况,我们可以在看第二种方案。
// 改造前
SalesRep rep = salesRepRepo.findRep(areaCode, operatorCode);
// 改造后
SalesRep rep = salesRepRepo.findRep(PhoneNumber);第二种思路是将查询销售组内聚到PhoneNumber中,之所以这样涉及是因为归属地和运营商都是手机号的相关属性,将该方法内聚到该类中在抽象上是合理的。
public class PhoneNumber {
private final String number;
private final String pattern = "^0?[1-9]{2,3}-?\\d{8}$";
public String getNumber() {
return number;
}
public PhoneNumber(String number) {
if (number == null) {
throw new ValidationException("number不能为空");
} else if (isValid(number)) {
throw new ValidationException("number格式错误");
}
this.number = number;
}
private boolean isValid(String number) {
return number.matches(pattern);
}
public String getAreaCode() {
//...
}
public String getOperatorCode(PhoneNumber phone) {
//...
}
}
public User register(String name, PhoneNumber phone) {
// 获取用户信息
SalesRep rep = salesRepRepo.findRep(phone.getAreaCode(), phone.getOperatorCode());
// 存储用户信息
User user = new User();
user.name = name;
user.phone = phone;
if (rep != null) {
user.repId = rep.repId;
}
return userRepo.save(user);
}这样一来,我们的注册逻辑就变得非常清晰了,只留下了“获取用户信息并注册”这两个最基本的操作,其余的操作都被内聚到了PhoneNumber中,这就是充血模型带来的好处。
当然本例中即使将获取归属地和运营商的逻辑保留在register方法中也是可以的,但是当我们遇到复杂的业务逻辑时可能获取归属地和运营商又要调用三四层其他的接口或者行为,将导致业务方法不再纯粹,如此多的行为耦合在一起必然对这段代码的可维护性造成极大的破坏,随着需求的迭代最后变成了谁都无法准确理清其中逻辑的“屎山”。
二、防腐层与资源库
现在我们将上文中的需求升级一下
1、对手机号进行实名校验,实名信息通过调用外部接口获得
2、根据外部服务返回的实名信息,按照一定逻辑计算出用户标签,记录在用户账号中。
3、根据用户标签为该用户开通相应等级的新客福利。
public class RegistrationServiceImpl implements RegistrationService {
// DAO为数据库操作具体实现
private SalesRepMapper salesRepDAO;
private UserMapper userDAO;
private RewardMapper rewardDAO;
private TelecomRealnameService telecomService;
private RiskControlService riskControlService;
public UserDO register(String name, PhoneNumber phone) {
// 参数合法性校验已在PhoneNumber中处理
// 调用外部接口的具体实现类进行参数一致性校验
TelecomInfoDTO rnInfoDTO = telecomService.getRealnameInfo(phone.getNumber());
if (!name.equals(rnInfoDTO.getName())) {
throw new InvalidRealnameException();
}
// 计算用户标签
String label = getLabel(rnInfoDTO);
// 计算销售组
String salesRepId = getSalesRepId(phone);
// 构造User对象和Reward对象
String idCard = rnInfoDTO.getIdCard();
// DO为数据表映射类
UserDO userDO = new UserDO(idCard, name, phone.getNumber(), label, salesRepId);
RewardDO rewardDO = RewardDO(idCard, label);
// 检查风控
if(!riskControlService.check(idCard, label)) {
userDO.setNew(true);
rewardDO.setAvailable(false);
}else {
userDO.setNew(false);
rewardDO.setAvailable(true);
}
// 通过DAO直接与数据库交互
rewardDAO.insert(rewardDO);
return userDAO.insert(userDO);
}
private String getLabel(TelecomInfoDTO dto) {
// 本地逻辑处理
}
private String getSalesRepId(PhoneNumber phone) {
// 数据库直接查询销售信息
SalesRepDO repDO = salesRepDAO.select(phone.getAreaCode(), phone.getOperatorCode());
if (repDO != null) {
return repDO.getRepId();
}
return null;
}
}首先是对外部依赖的耦合,比如telecomService.getRealnameInfo这个具体实现调用外部接口,如果外部接口产生了变化,又或者我们需要替换接口对接方,那么这块就需要进行调整。为了缩小调整范围,我们可以使用接口来进行抽象。
public interface RealnameService {
RealnameInfo get(PhoneNumber phone);
}
public class TelecomRealnameService implements RealnameService {
@Override
public RealnameInfo get(PhoneNumber phone){
// 调用的具体的接口实现,可以对接不同的第三方
// 返回结果封装为RealnameInfo
}
}
// 改造前
TelecomInfoDTO rnInfoDTO = telecomService.getRealnameInfo(phone.getNumber());
if (!name.equals(rnInfoDTO.getName())) {
throw new InvalidRealnameException();
}
// 改造后
RealnameInfo realnameInfo = realnameService.get(phone);
realnameInfo.check(name);通过调整,具体实现的方式我们可以通过配置来进行注入,完成了抽象与具体实现的分离,无论是参数调整还是替换实现都只需要调整具体实现或者配置文件即可。并且实名信息可以通过自定义类型RealnameInfo配合充血模型进一步的内聚。
这里的RealnameService及其具体实现达到了将业务逻辑与外部隔离开来的效果,在DDD中的专业术语叫做防腐层,防止外部依赖(所有不属于当前领域的服务,包括数据库、外部接口等)的变化影响到我们的当前领域。
再来看代码中显性的使用了DO(数据表映射类)与DAO(数据库操作的具体实现),但我们的业务逻辑应该只面向领域对象(领域对象不代表救赎数据库中表的映射,他可能是多张表的联合映射构建的对象),不用关心是否使用数据库和使用了哪种数据库,更不用关心表中的字段等。
总结起来一句话,上层的业务实现不需要关注下层的具体实现。
为了达到这个效果,我们首先定义实体User类,这个类用于描述系统中客户的信息与行为,并使用充血模型将行为内聚起来。其中我们还定义了一个数据访问的抽象层salesRepRepository,这是因为我们的实体同样不应该关心数据操作的具体实现,是从redis获取还是从mysql获取都不重要,我们关心的只有操作的结果。
// User Entity
public class User {
// 用户id,DP
private UserId userId;
// 用户手机号,DP
private PhoneNumber phone;
// 用户标签,DP
private Label label;
// 绑定销售组ID,DP
private SalesRepId salesRepId;
private Boolean fresh = false;
// 数据访问的抽象层
private SalesRepRepository salesRepRepository;
// 构造方法
public User(RealnameInfo info, name, PhoneNumber phone) {
// 参数一致性校验,若校验失败,则check内抛出异常(DP的优点)
info.check(name);
initId(info);
labelledAs(info);
// 查询
SalesRep salesRep = salesRepRepository.find(phone);
this.salesRepId = salesRep.getRepId();
}
// 对this.userId赋值
private void initId(RealnameInfo info) {
}
// 对this.label赋值
private void labelledAs(RealnameInfo info) {
// 本地处理逻辑
}
public void fresh() {
this.fresh = true;
}
}通过UserRepository抽象出对User实体的数据操作,然后通过其实现类来完成具体的操作,这里就可以依赖与数据库相关操作的各种具体实现了,无论是与redis还是别的什么数据库操作的实现都可以在这里完成。
public interface UserRepository {
User find(UserId id);
User find(PhoneNumber phone);
User save(User user);
}
public class UserRepositoryImpl implements UserRepository {
private UserMapper userDAO;
private UserBuilder userBuilder;
@Override
public User find(UserId id) {
UserDO userDO = userDAO.selectById(id.value());
return userBuilder.parseUser(userDO);
}
@Override
public User find(PhoneNumber phone) {
UserDO userDO = userDAO.selectByPhone(phone.getNumber());
return userBuilder.parseUser(userDO);
}
@Override
public User save(User user) {
UserDO userDO = userBuilder.fromUser(user);
if (userDO.getId() == null) {
userDAO.insert(userDO);
} else {
userDAO.update(userDO);
}
return userBuilder.parseUser(userDO);
}
}经过上面的调整,我们的注册方法被简化成了如下模样,此时已经与外部依赖完全解耦,当外部依赖产生变化我们只需要去修改具体实现类即可,从而保证了业务逻辑的文档。
public class RegistrationServiceImpl implements RegistrationService {
private UserRepository userRepository;
private RewardRepository rewardRepository;
private RealnameService realnameService;
private RiskControlService riskControlService;
public UserDO register(String name, PhoneNumber phone) {
// 查询实名信息
RealnameInfo realnameInfo = realnameService.get(phone);
// 构造对象
User user = new User(realnameInfo, phone);
Reward reward = Reward(user);
// 检查风控
if(!riskControlService.check(user)) {
user.fresh();
reward.inavailable();
}
// 存储信息
rewardRepository.save(reward);
return UserRepository.save(user);
}
}上文中Repository在DDD中被称为是资源库,资源库可以理解成 DAO,但它比 DAO 更宽泛,存储的手段可以是多样化的,常见的无非是数据库、分布式缓存、本地缓存等。资源库(Repository)的作用,就是对领域的存储和访问进行统一管理的对象。
另外一个概念就是User类在DDD中被称为实体,注意和上文中介绍的值对象的区别,实体是有状态的,而值对象是无状态的,我个人的理解是值对象更多的是将我们原本的属性丰富为了类,而实体则是由多个值对象组成的属性和行为更丰富的类。
最后我们再回到业务逻辑中,在检查完风控后存在这样一段逻辑,涉及到给新用户发奖的逻辑,回顾一下我们上文中的内容,业务逻辑应该越简洁越好,这两个操作实际上属于判断用户是否为新用户的衍生行为,放在这里有些不太合适。
// 检查风控
if(!riskControlService.check(user)) {
user.fresh();
reward.inavailable();
}我们梳理下注册逻辑,可以简化为获取用户信息、检查并更新用户信息、存储用户信息这三个步骤,类似发奖这样的操作就可以被包含在检查并更新用户信息的衍生行为中。
public interface CheckUserService(User user) {
void check(user);
}
public class CheckAndUpdateUserServiceImpl(User user) {
private RiskControlService riskControlService;
private RewardRepository rewardRepository;
@Override
public void check(User user) {
rewardCheck(user);
// ...
// 可能存在的其他逻辑
}
private void rewardCheck(User user) {
Reward reward = Reward(user);
// 检查风控
if(!riskControlService.check(user)) {
user.fresh();
reward.inavailable();
}
rewardRepository.save(reward);
}
}
public class RegistrationServiceImpl implements RegistrationService {
private UserRepository userRepository;
private RealnameService realnameService;
private CheckUserService checkUserService;
public UserDO register(String name, PhoneNumber phone) {
// 查询信息
RealnameInfo realnameInfo = realnameService.get(phone);
// 构造对象
User user = new User(realnameInfo, phone);
// 检查并更新对象
checkUserService.check(user);
// 存储信息
return userRepository.save(user);
}
}
通过如上调整,我们的业务方法就只剩下了三个非常简明易懂的步骤,后续即使需求发生变化也可以把改动范围尽量虽小,最小化对业务方法的影响。
像 rewardCheck可能修改user或reward这些实体的状态,这样的操作在DDD中被称为领域服务。
到目前为止我们介绍了DDD中的值对象、实体、资源库与防腐层,下面我们换个例子来介绍下聚合与聚合根。
三、聚合与聚合根
以通过手机号注销微信账号为例,这就涉及到是否要删除微信钱包,如果不删除,假如该号码被用户弃用,之后被运营商发给另一个用户,新用户再用这个手机号注册微信就会发现已经绑定了他人的微信钱包。如果需要解绑,又会涉及到是否要解绑银行卡,如果这张卡还作为亲属卡绑定了他人的钱包,此时解绑又是否会影响他人的使用?
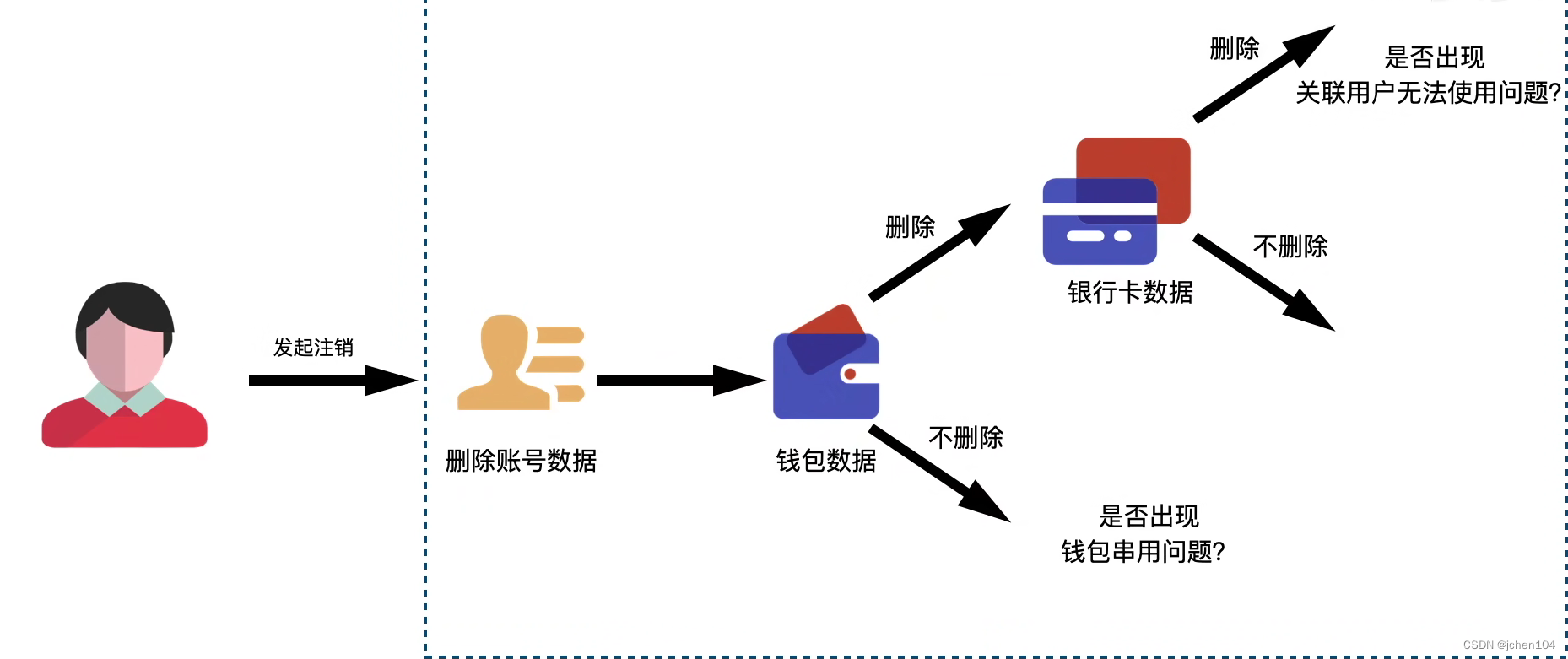
这个例子我们可以发现对一个对象的修改可能会涉及到大量其他关联对象的状态,如何保持这些对象的状态保持一致是个很复杂的问题。
在DDD中使用聚合来描述这种存在引用关系的对象的集合,其目的便是屏蔽掉内部对象间复杂的关联关系,只对外暴露一个统一的接口。对于聚合我们只要关注根对象(聚合根)和边界这两个属性,根对象是聚合中唯一能被外部引用的对象,换句话说,聚合对外暴露的接口只允许操作根对象,边界则是用来判断哪个对象能放入当前聚合的条件。
现在我们来看看上面注销账号的例子,账号关联了钱包,钱包关联了银行卡,因此这三个对象自然是可以聚合在注销账号这个业务领域中。此时的根对象很自然便是账号,而边界的定义则是当前对象在注销时是否被引用,例如聊天消息自然是不包括在内的,于是这样一个聚合便设计好了。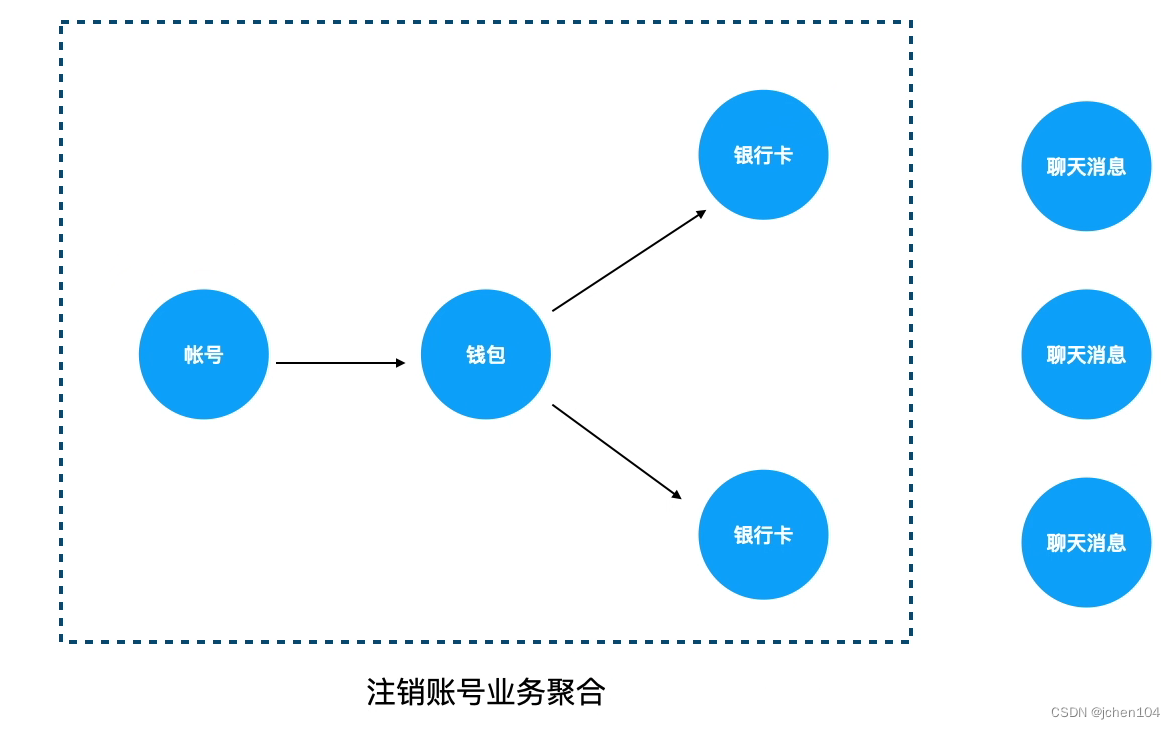
到这里我们DDD种的聚合、聚合根与边界便有了初步的理解,篇幅原因这段的代码实现我们暂时留到下篇文章再做介绍。















 1323
1323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









