






这个就是单纯的最小生成树
计算最小生成树有两种算法
kruska算法
和prim算法
这个题目我就是用的prim算法
因为这个算法和之前遇到的最短路中的dijkstra算法很像
dijkstra算法求的是从一个点到其他点的所有距离
最小生成树求的是一条能够连接所有节点的最短路
dijkstra和prim的区别就是
dijkstra会累加原来走过的路来计算
而prim不需要考虑从起点出发,他的每一步都是走最短的那一条路
最终走过所有的节点。而且每一个节点都只走一遍
代码如下
#include<bits/stdc++.h>
using namespace std;
#define N 5003
#define M 200005
#define inf 123456789
struct Node
{
int v,w,next;
}e[M*2];
int head[N]={0};
int dis[N];//存放最终结果
int vis[N];
int top=0;
int n,m;
int add(int a,int b,int c)
{
top++;
e[top].v=b;
e[top].w=c;
e[top].next=head[a];
head[a]=top;
}
int finding()
{
int result=0;
for(int i=1;i<=n;i++)
{
dis[i]=inf;
}
dis[1]=0;
int count=0;
int present=1;
while(count++<n)
{
int ming=inf;
for(int i=1;i<=n;i++)
{
if(vis[i]==0&&ming>dis[i])
{
ming=dis[i];
present=i;
}
}
if(ming==inf)
return 0;
result+=ming;
for(int i=head[present];i;i=e[i].next)
{
int v=e[i].v;
if(dis[v]>e[i].w&&vis[v]==0)
dis[v]=e[i].w;
}
vis[present]=1;
}
return result;
}
int main()
{
cin>>n>>m;
int a,b,c;
for(int i=1;i<=m;i++)
{
cin>>a>>b>>c;
add(a,b,c);
add(b,a,c);
}
int result=finding();
if(result)
cout<<result;
else
cout<<"orz";
}对比一下昨天写的dijkstra
#include<iostream>
using namespace std;
long long Max=2147483647;
int point,side,start;
long long result[1000000];
long long book[1000000];
struct Data
{
int to;
int length;
int next;
}data[1000000];
int head[1000000];
int top=0;
int add(int a,int b,int c)
{
top++;
data[top].to=b;
data[top].length=c;
data[top].next=head[a];
head[a]=top;
return 0;
}
int finding(int start)
{
for(int i=1;i<=point ;i++)
{
result[i]=Max;
book[i]=0;
}
result[start]=0;
int present=start;
while(book[present]==0)
{
book[present]=1;
long long mining=Max;
for(int i=head[present];i;i=data[i].next)
{
if(book[data[i].to]==0)
if(result[data[i].to]>result[present]+data[i].length)
result[data[i].to]=result[present]+data[i].length;
}
for(int i=1;i<=point;i++)
{
if(book[i]==0)
if(result[i]<mining)
{
mining=result[i];
present=i;
}
}
}
return 0;
}
int main()
{
cin>>point>>side>>start;
for(int i=1;i<=side;i++)
{
int a,b,c;
cin>>a>>b>>c;
add(a,b,c);
}
finding(start);
for(int i=1;i<=point ;i++)
cout<<result[i]<<' ';
}就会发现其中的基本架构都差不多
这个题目也是直接建立最小生成树,输出第s+1大的那个数据就可以
题目中任意的两个点都是可以直接连接的,使用prim算法每一次都走最短的那一条路
代码如下
#include<iostream>
#include<math.h>
using namespace std;
#define Max 502
#define inf 123456789
int n,m;
struct Data
{
int x;
int y;
double range;
bool select;
}data[Max];
double length(int a,int b)
{
double result;
int x=data[a].x-data[b].x;
int y=data[a].y-data[b].y;
result=sqrt(x*x+y*y);
return result;
}
//寻找每个点对应的最短距离
int finding()
{
int count=0;
int present=1;
while(count++<m)
{
int ming=inf;
data[present].select=1;
for(int i=1;i<=m;i++)
{
if(data[i].select)
continue;
double len=length(present,i);
if(data[i].range>len)
{
data[i].range=len;
}
}
for(int i=1;i<=m;i++)
{
if(data[i].select)
continue;
if(data[i].range<ming)
{
ming=data[i].range;
present=i;
}
}
}
// for(int i=1;i<=m;i++)
// {
// for(int j=i+1;j<=m;j++)
// {
// int len=length(i,j);
// if(data[j].range>len)
// data[j].range=len;
// }
// }
}
//根据距离排序
int ranked()
{
for(int i=1;i<=m;i++)
{
int ming=i;
for(int j=i+1;j<=m;j++)
if(data[ming].range<data[j].range)
ming=j;
Data change;
{
change=data[i];
data[i]=data[ming];
data[ming]=change;
}
}
}
int main()
{
cin>>n>>m;
for(int i=1;i<=m;i++)
{
data[i].range=inf;//距离初值为无限大
data[i].select=0;
cin>>data[i].x>>data[i].y;
}
finding();
ranked();
// for(int i=1;i<=m;i++)
// cout<<data[i].range<<endl;
printf("%.2lf",data[n+1].range);
}
这个题目使用prim是比较难算出来的,所以只能用另一种算法
cruska算法
首先我们把题目给出的数据根据美丽度从大到小来进行排序
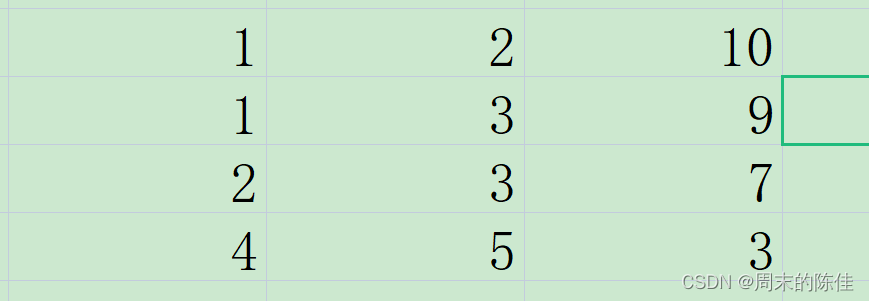
我们从最大的开始选择
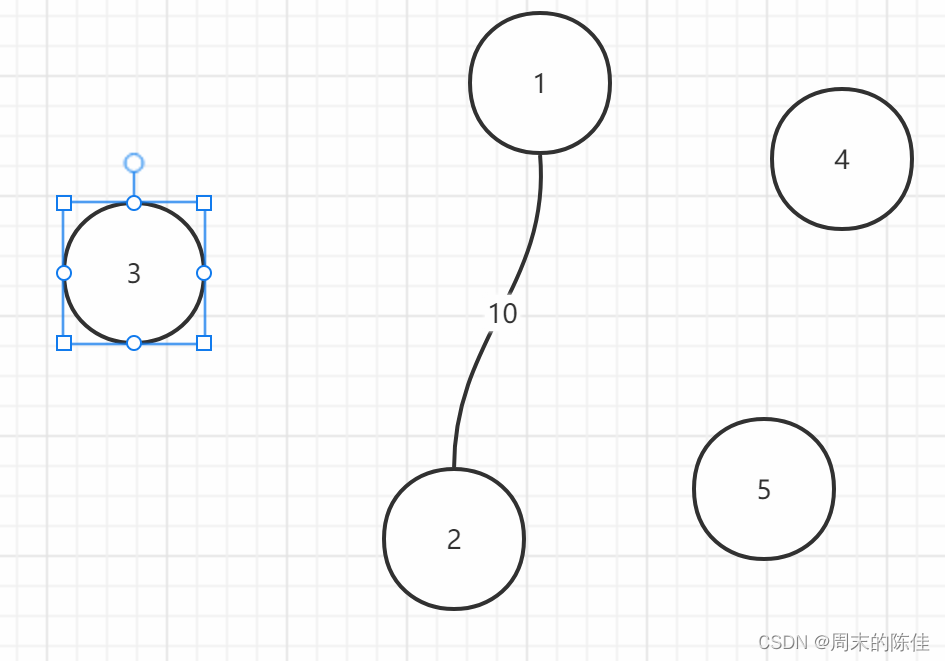
接着选择第二个
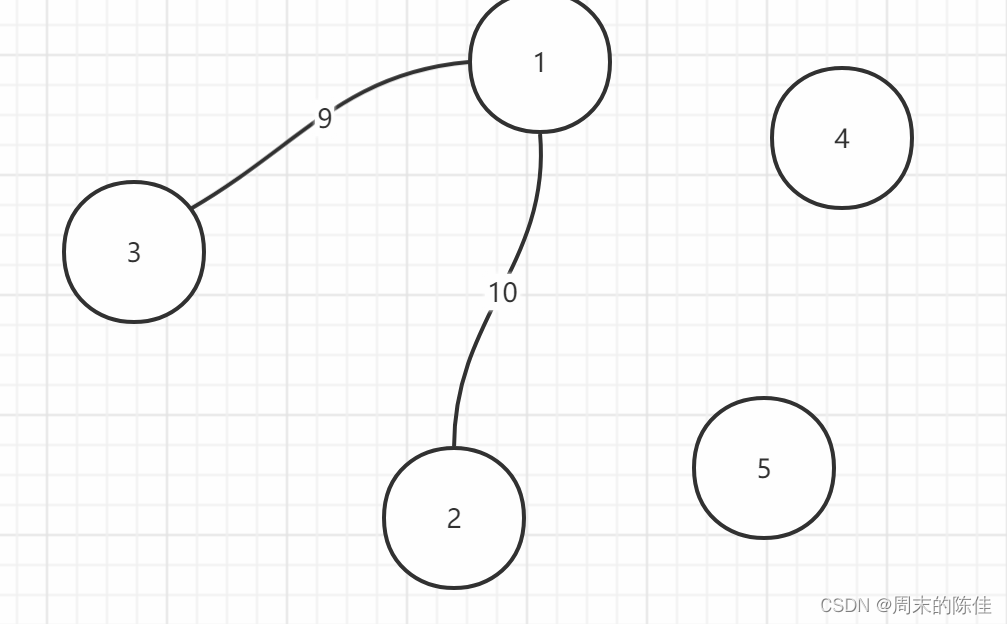
接着来选择第三个
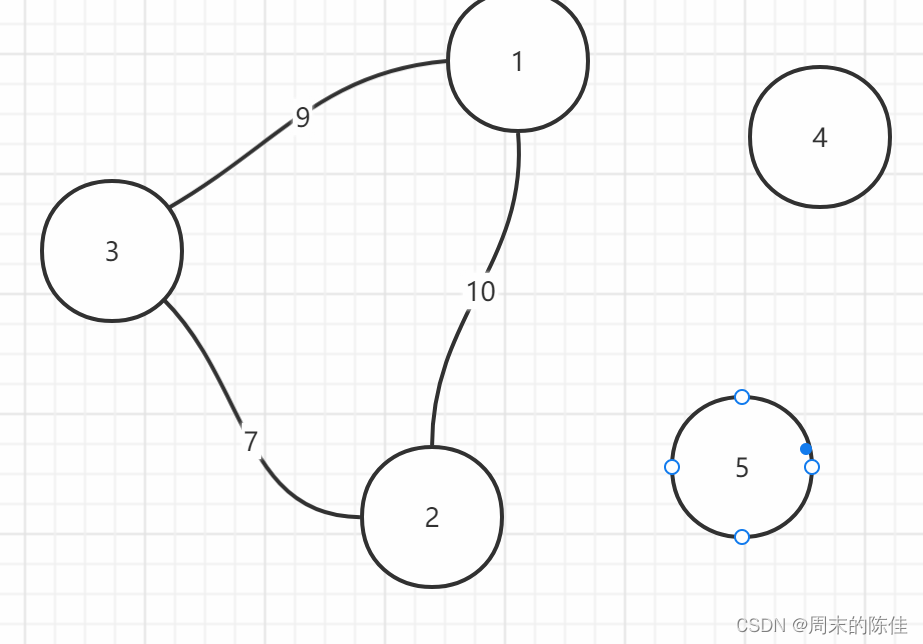
这个时候我们发现形成了一个环
首先题目中不允许出现环,其次最小生成树也是不允许出现环的,如果有环的话,说明一点到另一点不止有一条路可以走,最小生成树就是一条路贯穿到底
所以为了避免出现环。我们使用并查集
通过判断需要连接的两个节点是否是同一类的,如果是同一类,说明连接会成环
否则不会,并把它们归于一类
这个就是cruska算法需要注意的地方
理解了原理,实现代码也是比较简单的
#include<iostream>
using namespace std;
#define N 100005
int point ,rug ,needs;//区域数,地毯数,保留数
int result=0;//存放最终结果
int parent[N];//并查表
// 并查集
int check(int start)
{
if(parent[start]==start)
return start;
parent[start]=check(parent[start]);
return parent[start];
}
struct Data
{
int a;
int b;
int beaut;
}data[N];
int comp(int start ,int end)
{
int mid=(start+end)/2;
int a=start;
int b=mid+1;
Data shadow[N];
int len=0;
while(a<=mid&&b<=end)
{
if(data[a].beaut>data[b].beaut)
shadow[len++]=data[a++];
else
shadow[len++]=data[b++];
}
while(a<=mid)
shadow[len++]=data[a++];
while(b<=end)
shadow[len++]=data[b++];
for(int i=0;i<len;i++)
data[start+i]=shadow[i];
return 0;
}
int ranked(int start,int end)
{
if(start>=end)
return 0;
int mid=(start+end)/2;
ranked(start,mid);
ranked(mid+1,end);
comp(start,end);
return 0;
}
int finding()
{
//初始化并查表
for(int i=0;i<=point ;i++)
parent[i]=i;
int present=1;
for(int i=1;i<=needs;i++)
{
//定位到不能够形成环的毯子
while(check(data[present].a)==check(data[present].b))
present++;
result+=data[present].beaut;
parent[check(data[present].a)]=check(data[present].b);
present++;
}
return 0;
}
int main()
{
cin >>point>>rug>>needs;
for(int i=1;i<=rug;i++)
cin >>data[i].a>>data[i].b>>data[i].beaut;
ranked(1,rug);
finding();
cout<<result;
}因为要排序,而且数据量比较大,所以还要专门写一个比较快的排序方法来进行排序















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









