







目录
(3)HS2 的 Web 用户界面(Hive 2.0.0 引入)
本篇重点是针对销售订单示例创建并测试数据装载的 Kettle 作业和转换。在此之前,先简要介绍数据清洗的概念,并说明如何使用 Kettle 完成常见的数据清洗工作。由于本示例中 Kettle 在 Hadoop 上的 ETL 实现依赖于 Hive,所以之后对 Hive 做一个概括的介绍,包括它的体系结构、工作流程和优化。最后用完整的 Kettle 作业演示如何实现销售订单数据仓库的数据转换与装载。
一、数据清洗
对大多数用户来说,ETL 的核心价值在“T”所代表的转换部分。这个阶段要做很多工作,数据清洗就是其中一项重点任务。数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
1. 处理“脏数据”
数据仓库中的数据是面向某一主题数据的集合,这些数据从多个业务系统中抽取而来,并且包含历史变化,因此就不可避免地出现某些数据是错误的,或者数据相互之间存在冲突的情况。这些错误的或有冲突的数据显然不是我们想要的,被称为“脏数据”。要按照一定的规则处理脏数据,这个过程就是数据清洗。数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务部门,确认是直接删除掉,还是修正之后再进行抽取。不符合要求的数据主要包括不完整的数据、错误的数据、重复的数据、不一致的数据四大类。
- 残缺数据。这一类数据主要是一些应该有的信息缺失了,如产品名称、客户名称、客户的区域信息,还有业务系统中由于缺少外键约束所导致的主表与明细表不能匹配等。
- 错误数据。这一类错误产生的原因多是业务系统不够健全,在接收输入后没有进行合法性检查或检查不够严格,将有问题的数据直接写入后台数据库造成的,比如用字符串存储数字、超出合法的取值范围、日期格式不正确、日期越界等。
- 重复数据。源系统中相同的数据存在多份。
- 差异数据。本来具有同一业务含义的数据,因为来自不同的操作型数据源,造成数据不一致。这时需要将非标准的数据转化为在一定程度上的标准化数据。
来自操作型数据源的数据如果含有不洁成分或不规范的格式,将对数据仓库的建立和维护,特别是对联机分析处理的使用,造成很多问题和麻烦。这时必须在 ETL 过程中加以处理,不同类型的数据,处理的方式也不尽相同。对于残缺数据,ETL 将这类数据过滤出来,按缺失的内容向业务数据的所有者提交,要求在规定的时间内补全,之后才写入数据仓库。对于错误数据,一般的处理方式是通过数据库查询的方式找出来,并将脏数据反馈给业务系统用户,由业务用户确定是抛弃这些数据,还是修改后再次进行抽取,修改的工作可以是业务系统相关人员配合 ETL 开发者来完成。对于重复数据的处理,ETL 系统本身应该具有自动查重去重的功能。而差异数据,则需要协调 ETL 开发者与来自多个不同业务系统的人员共同确认参照标准,然后在 ETL 系统中建立一系列必要的方法和手段实现数据一致性和标准化。
2. 数据清洗原则
保障数据清洗处理顺利进行的原则是优先对数据清洗处理流程进行分析和系统化的设计,针对数据的主要问题和特征,设计一系列数据对照表和数据清洗程序库的有效组合,以便面对不断变化的、形形色色的数据清洗问题。数据清洗流程通常包括如下内容:
- 预处理。对于大的数据加载文件,特别是新的文件和数据集合,要进行预先诊断和检测,不能冒然加载。有时需要临时编写程序进行数据清洁检查。
- 标准化处理。应用建于数据仓库内部的标准字典,对于地区名、人名、公司名、产品名、分类名以及各种编码信息进行标准化处理。
- 查重。应用各种数据库查询技术和手段,避免引入重复数据。
- 出错处理和修正。将出错的记录和数据写入到日志文件,留待进一步处理。
3. 数据清洗实例
(1)身份证号码格式检查
身份证号码格式校验是很多系统在数据集成时的一个常见需求,这里以 18 位身份证为例,使用一个 Kettle 转换实现身份证号码的合法性验证。该转换执行的结果是将所有合规与不合规的身份证号码写入相应的输出文件。按以下身份证号码的定义规则建立转换。
身份证 18 位分别代表的含义,从左到右方分别表示:
- 1-2 省级行政区代码。
- 3-4 地级行政区划分代码。
- 5-6 县区行政区分代码。
- 7-10 11-12 13-14 出生年、月、日。
- 15-17 顺序码,同一地区同年、同月、同日出生人的编号,奇数是男性,偶数是女性。
- 18 校验码,如果是 0-9 则用 0-9 表示,如果是 10 则用 X(罗马数字 10)表示。
身份证校验码的计算方法为:
- 将身份证号码前 17 位数分别乘以不同的系数。从第一位到第十七位的系数分别为:7-9-10-5-8-4-2-1-6-3-7-9-10-5-8-4-2。
- 将这 17 位数字和系数相乘的结果相加。
- 用相加和除以 11,看余数是多少。
- 余数只可能有 0-1-2-3-4-5-6-7-8-9-10 这 11 个数字,其分别对应的最后一位身份证的号码为 1-0-X -9-8-7-6-5-4-3-2。
总的 Kettle 转换如图6-1 所示。
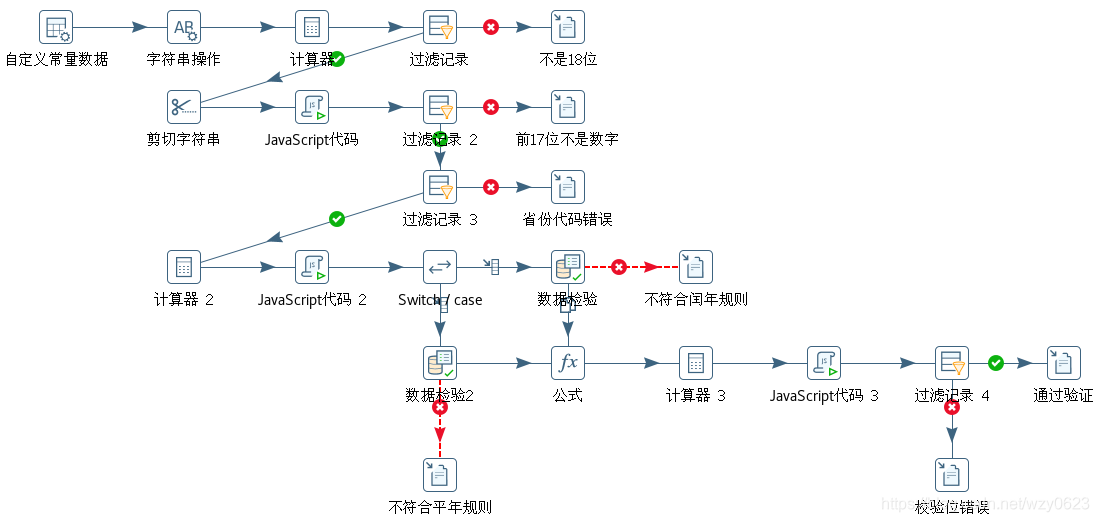
这是本专题到目前为止步骤最多的一个转换。虽然有些复杂,但条理还比较清楚。下面具体说明每个步骤的定义和作用。
“自定义常量数据”定义 8 条身份证号码模拟数据作为输入,其中包括各种不合规的情况及一条完全合规的号码:
cardid
110102197203270816
1101021972032708161
11010219720327081
a00102197203270816
000102197203270816
110102197302290816
110102197202290816
110102197202300816第一层的四个步骤校验号码位数,18 位的数据流向第二层,其它数据输出到一个错误文件。“字符串操作”步骤作用是去除字符串两边空格(Trim type 选择 both),并将字符串转为大写(Lower/Upper 选择 upper)。“计算器”步骤返回一个表示字符串长度的新字段 length(“计算”选择“Return the length of a string A”,“字段A”选择“cardid”,“值类型”选择“String”)。“过滤记录”步骤中的“条件”为“length = 18”,为真时流向下面的步骤,为假时输出错误文件。
第二层的四个步骤校验号码的前 17 位均为数字,合规的数据流向第三层,其它数据输出到一个错误文件。“剪切字符串”步骤将 18 位字符串分隔成 21 个字段,字符串下标从 0 开始,如图6-2 所示。province 取前两位,用于后面验证省份代码。year 取第 7 到第 10 位,用于后面计算是否闰年。p17 取前 17 位,用于判断是否纯数字。s1-s18 表示每一位,用于后面计算检验位。

“JavaScript代码”步骤中只有一行脚本,用 isNaN 函数判断前 17 位的字符串是否纯数字,并返回 Boolean 类型的字段“notnumber”:
notnumber=isNaN(p17)“过滤记录 2”步骤中的“条件”为“notnumber = N”,为真时流向下面的步骤,为假时输出错误文件。
第三层的两个步骤校验两位省份代码,合规的数据流向第四层,其它数据输出到一个错误文件。“过滤记录 3”步骤中的“条件”为:
province IN LIST 11;12;13;14;15;21;22;23;31;32;33;34;35;36;37;41;42;43;44;45;46;50;51;52;53;54;61;62;63;64;65;71;81;82;91“计算器 2”步骤定义如图6-3 所示,先定义三个常数 400、100、4,然后计算 year 除以这三个常数的余数,用于后面判断是否闰年。
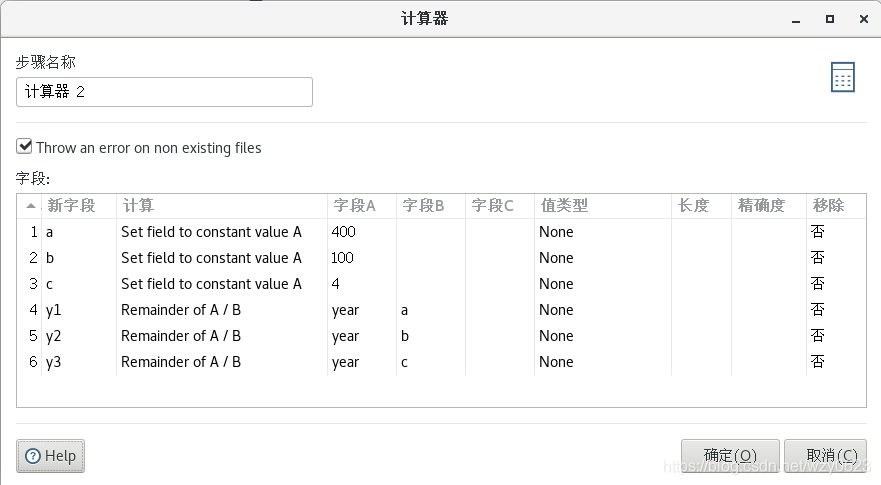
“JavaScript代码 2”步骤中的脚本如下,按闰年定义进行判断,返回 Boolean 类型的字段 isleapyear 表示 year 是否为闰年。
var isleapyear;
if( y1==0 || y2>0 && y3==0 )
{
isleapyear = true;
}
else
{
isleapyear = false;
}“Switch / case”定义如图6-4 所示,根据 isleapyear 的值,闰年与平年走不同数据校验分支。
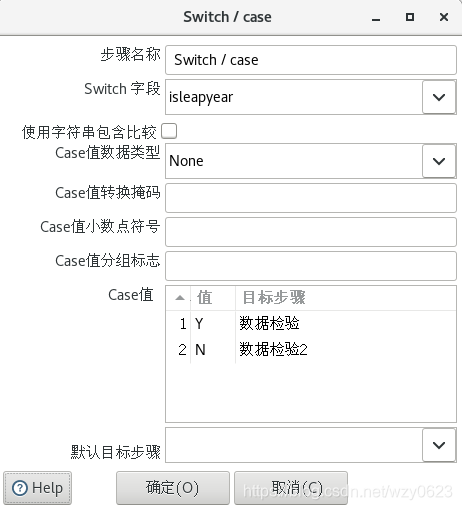
“数据校验”步骤验证闰年的日期规则,“要检验的字段名”选择 cardid,在“合法数据的正则表达式”中填写:
^[1-9][0-9]{5}19[0-9]{2}((01|03|05|07|08|10|12)(0[1-9]|[1-2][0-9]|3[0-1])|(04|06|09|11)(0[1-9]|[1-2][0-9]|30)|02(0[1-9]|[1-2][0-9]))[0-9]{3}[0-9X]$“数据校验2”步骤验证平年的日期规则,“要检验的字段名”选择 cardid,在“合法数据的正则表达式”中填写:
^[1-9][0-9]{5}19[0-9]{2}((01|03|05|07|08|10|12)(0[1-9]|[1-2][0-9]|3[0-1])|(04|06|09|11)(0[1-9]|[1-2][0-9]|30)|02(0[1-9]|1[0-9]|2[0-8]))[0-9]{3}[0-9X]$没有通过两个校验步骤的数据分别输出到一个错误文件,通过的数据流向“公式”步骤。该步骤输出一个新字段 s,公式如下,即将前 17 位数字和系数相乘的结果相加。
([s1]*7+[s2]*9+[s3]*10+[s4]*5+[s5]*8+[s6]*4+[s7]*2+[s8]*1+[s9]*6+[s10]*3+[s11]*7+[s12]*9+[s13]*10+[s14]*5+[s15]*8+[s16]*4+[s17]*2)“计算器 3”步骤定义如图6-5 所示,计算 s 除以 11 的余数。
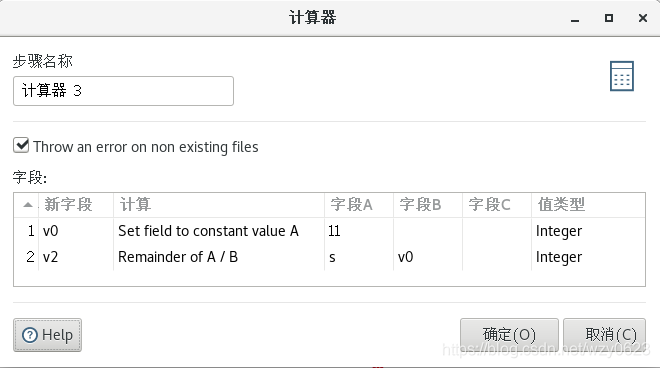
“JavaScript代码 3”步骤中的脚本如下,计算校验位,返回 Boolean 类型的字段 valid 表示校验位是否正确。
var v_str='10X98765432'.substring(v2,v2+1);
if(s18==v_str)
{valid=true}
else
{valid=false}“过滤记录 4”步骤中的“条件”为“valid = Y”,为真时将通过验证的数据输出到文件,为假时输出错误文件。
执行转换后,各错误文件和正确输出文件内容如下:
[root@localhost 6]# cat err1.txt
cardid;length
1101021972032708161;19
11010219720327081;17
[root@localhost 6]# cat err2.txt
cardid;p17
A00102197203270816;A0010219720327081
[root@localhost 6]# cat err3.txt
cardid;province
000102197203270816;00
[root@localhost 6]# cat err4.txt
cardid
110102197202300816
[root@localhost 6]# cat err5.txt
cardid
110102197302290816
[root@localhost 6]# cat err6.txt
cardid
110102197202290816
[root@localhost 6]# cat valid.txt
cardid
110102197203270816
[root@localhost 6]# (2)去除重复数据
有两种意义上的重复记录,一是完全重复的记录,即所有字段均都重复,二是部分字段重复的记录。发生第一种重复的原因主要是表设计不周,通过给表增加主键或唯一索引列即可避免。对于第二类重复问题,通常要求查询出重复记录中的任一条记录。Kettle 转换中有“去除重复记录”和“唯一行(哈希值)”两个步骤用于实现去重操作。“去除重复记录”步骤前,应该按照去除重列进行排序,否则可能返回错误的结果。“唯一行(哈希值)”步骤则不需要事先对数据进行排序。图6-6 所示为一个 Kettle 去重的例子。
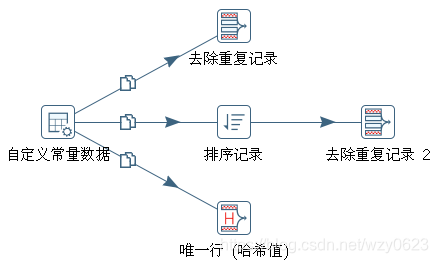
“自定义常量数据”步骤定义 5 条记录:
id name
1 a
2 b
1 b
3 a
3 b“去除重复记录”步骤中“用于比较的字段”选择 id,即按 id 字段去重。因为没有排序,该步骤输出为 4 条记录,id=1 仍然有两条记录:
id name
1 a
2 b
1 b
3 a“去除重复记录 2”步骤的定义与“去除重复记录”步骤相同,但前置了一个“排序记录”步骤,在其中定义按 id 和 name 字段排序,因此去重输出为:
id name
1 a
2 b
3 a“唯一行(哈希值)”步骤的输出同上,该步骤不需先排序即可按预期去重。
(3)建立标准数据对照表
这是一个真实数据仓库项目中的案例。某公司要建立一个员工数据仓库,需要从多个业务系统集成员工相关的信息。由于历史的原因,该公司现存的四个业务系统中都包含员工数据,这四个业务系统是 HR、OA、考勤和绩效考核系统。这些系统是彼此独立的,有些是采购的商业软件,有些是公司自己开发的。每个系统中都有员工和组织机构表,存储员工编号、姓名、所在部门等属性。各个系统的员工数据并不一致。例如,员工入职或离职时,HR 系统会更新员工数据,但 OA 系统的更新可能会滞后很长时间。项目的目标是建立一个全公司唯一的、一致的人员信息库。
我们的思路是利用一系列经过仔细定义的参照表或转换表取代那些所谓硬编码的转换程序。其优点是很明显的:转换功能动态化,并能适应多变的环境。对于建立在许多不同数据源之上的数据仓库来说,这是一项非常重要的基础工作。具体方案如下:
- 建立标准码表用以辅助数据转换处理
- 建立与标准值转化有关的函数或子程序
- 建立非标准值与标准值对照的映像表,或者别名与标准名的对照表。
下面的问题是确定标准值的来源。从业务的角度看,HR 系统的数据相对来说是最准确的,因为员工或组织机构的变化,最先反应到该系统的数据更新中。以 HR 系统中的员工表数据为标准是比较合适的选择。有了标准值后,还要建立一个映像表,把其它系统的员工数据和标准值对应起来。比方说有一个员工的编号在 HR 系统中为 101,在其它三个系统中的编号分别是 102、103、104,我们建立的映像表应该与表6-1 类似。
| DW 条目名称 | DW 标准值 | 业务系统 | 数据来源 | 源值 |
| 员工编号 | 101 | HR | HR库.表名.列名 | 101 |
| 员工编号 | 101 | OA | OA库.表名.列名 | 102 |
| 员工编号 | 101 | 考勤 | 考勤库.表名.列名 | 103 |
| 员工编号 | 101 | 绩效 | 绩效库.表名.列名 | 104 |
表6-1 标准值映像表
这张表建立在数据仓库模式中,人员数据从各个系统抽取来以后,与标准值映像表关联,从而形成统一的标准数据。映像表被其它源数据引用,是数据一致性的关键,其维护应该与 HR 系统同步。因此在 ETL 过程中应该首先处理 HR 表和映像表。
数据清洗在实际 ETL 开发中是不可缺少的重要一步。即使为了降低复杂度,在我们的销售订单示例中没有涉及数据清洗,读者还是应该了解相关内容,这会对实际工作有所启发。
二、Hive 简介
让我们回到实践中来。在“(四):建立 ETL 示例模型”中,我们建立了 Hive 库表以存储销售订单示例的过渡区和数据仓库数据,并介绍了 Hive 支持的文件格式、表类型以及如何支持事务处理。Kettle 处理 Hadoop ETL 依赖于 Hive,因此有必要系统了解一下 Hive 的基本概念及其体系结构。
Hive 是 Hadoop 生态圈的数据仓库软件,使用类似于 SQL 的语言读、写、管理分布式存储上的大数据集。它建立在 Hadoop 之上,具有以下功能和特点:
- 通过 HiveQL 方便地访问数据,适合执行 ETL、报表查询、数据分析等数据仓库任务。
- 提供一种机制,给各种各样的数据格式添加结构。
- 直接访问 HDFS 的文件,或者访问如 HBase 的其它数据存储。
- 可以通过 MapReduce、Spark 或 Tez 等多种计算框架执行查询。
Hive 提供标准的 SQL 功能,包括 2003 以后的标准和 2011 标准中的分析特性。Hive 中的 SQL 还可以通过用户定义的函数(UDFs)、用户定义的聚合函数(UDAFs)、用户定义的表函数(UDTFs)进行扩展。Hive 内建连接器支持 CSV 文本文件、Parquet、ORC 等多种数据格式,用户也可以扩展支持其它格式的连接器。Hive 被设计成一个可扩展的、高性能的、容错的、与输入数据格式松耦合的系统,适合于数据仓库中的汇总、分析、批处理查询等任务,而不适合联机事务处理的工作场景。Hive 包括 HCatalog 和 WebHCat 两个组件。HCatalog 是 Hadoop 的表和存储管理层,允许使用 Pig 和 MapReduce 等数据处理工具的用户更容易读写集群中的数据。WebHCat 提供了一个服务,可以使用 HTTP 接口执行 MapReduce(或 YARN)、Pig、Hive 作业或元数据操作。
1. Hive 的体系结构
Hive 的体系结构如图6-7 所示。
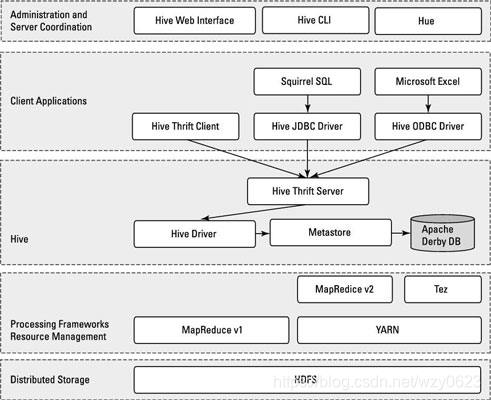
Hive 建立在 Hadoop 的分布式文件系统(HDFS)和 MapReduce 之上。上图中显示了 Hadoop 1 和 Hadoop 2 中的两种 MapReduce 组件。在 Hadoop 1 中,Hive 查询被转化成 MapReduce 代码,并且使用第一版的 MapReduce 框架执行,如 JobTracker 和 TaskTracker。在 Hadoop 2 中,YARN 将资源管理和调度从 MapReduce 框架中解耦。Hive 查询仍然被转化为 MapReduce 代码并执行,但使用的是 YARN 框架和第二版的 MapReduce。
为了更好地理解 Hive 如何与 Hadoop 的基本组件一起协同工作,可以把 Hadoop 看做一个操作系统,HDFS 和 MapReduce 是这个操作系统的组成部分,而象 Hive、HBase 这些组件,则是操作系统的上层应用或功能。Hadoop 生态圈的通用底层架构是,HDFS 提供分布式存储,MapReduce 为上层功能提供并行处理能力。
在 HDFS 和 MapReduce 之上,图中显示了 Hive 驱动程序和元数据存储。Hive 驱动程序及其编译器负责编译、优化和执行 HiveQL。依赖于具体情况,Hive 驱动程序可能选择在本地执行 Hive 语句或命令,也可能是产生一个 MapReduce 作业。Hive 驱动程序把元数据存储在数据库中。
缺省配置下,Hive 在内建的 Derby 关系数据库系统中存储元数据,这种方式被称为嵌入模式。在这种模式下,Hive 驱动程序、元数据存储和 Derby 全部运行在同一个 Java 虚拟机中(JVM)。这种配置适合于学习目的,它只支持单一 Hive 会话,所以不能用于多用户的生产环境。Hive 还允许将元数据存储于本地或远程的外部数据库中,这种设置可以更好地支持 Hive 的多会话生产环境。并且,可以配置任何与 JDBC API 兼容的关系数据库系统存储元数据,如 MySQL、Oracle 等。
对应用支持的关键组件是 Hive Thrift 服务,它允许一个富客户端集访问 Hive,开源的 SQuirreL SQL 客户端被作为示例包含其中。任何与 JDBC 兼容的应用,都可以通过绑定的 JDBC 驱动访问 Hive。与 ODBC 兼容的客户端,如 Linux 下典型的 unixODBC 和 isql 应用程序,可以从远程 Linux 客户端访问 Hive。如果在客户端安装了相应的 ODBC 驱动,甚至可以从微软的 Excel 访问 Hive。通过 Thrift 还可以用 Java 以外的程序语言,如 PHP 或 Python 访问 Hive。就像 JDBC、ODBC 一样,Thrift 客户端通过 Thrift 服务器访问 Hive。
架构图的最上面包括一个命令行接口(CLI),可以在 Linux 终端窗口向 Hive 驱动程序直接发出查询或管理命令。还有一个简单的 Web 界面,通过它可以从浏览器访问 Hive 管理表及其数据。
2. Hive 的工作流程
从接收到发自命令行或是应用程序的查询命令,到把结果返回给用户,期间 Hive 的工作流程(第一版的 MapReduce)如图6-8 所示。
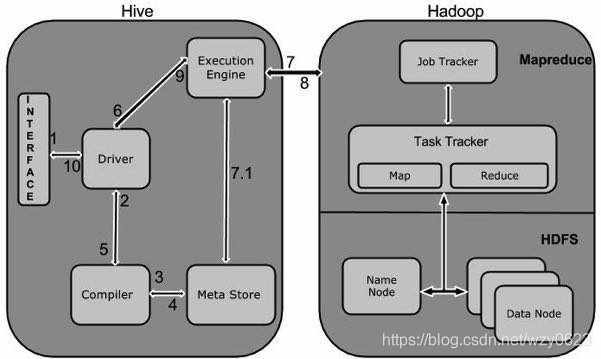
表6-2 说明 Hive 如何与 Hadoop 的基本组件进行交互。从中不难看出,Hive 的执行过程与关系数据库的非常相似,只不过是使用分布式计算框架来实现。
| 步骤 | 操作 |
| 1 | 执行查询 从 Hive 的 CLI 或 Web UI 发查询命令给驱动程序(任何 JDBC、ODBC 数据库驱动)执行。 |
| 2 | 获得计划 驱动程序请求查询编译器解析查询、检查语法、生成查询计划或者查询所需要的资源。 |
| 3 | 获取元数据 编译器向元数据存储数据库发送元数据请求。 |
| 4 | 发送元数据 作为响应,元数据存储发向编译器发送元数据。 |
| 5 | 发送计划 编译器检查需要的资源,并把查询计划发送给驱动程序。至此,查询解析完成。 |
| 6 | 执行计划 驱动程序向执行引擎发送执行计划。 |
| 7 | 执行作业 执行计划的处理是一个 MapReduce 作业。执行引擎向 Name node 上的 JobTracker 进程发送作业,JobTracker 把作业分配给 Data node 上的 TaskTracker 进程。此时,查询执行 MapReduce 作业。 |
| 7.1 | 操作元数据 执行作业的同时,执行引擎可能会执行元数据操作,如 DDL 语句等。 |
| 8 | 取回结果 执行引擎从 Data node 接收结果。 |
| 9 | 发送结果 执行引擎向驱动程序发送合成的结果值。 |
| 10 | 发送结果 驱动程序向 Hive 接口(CLI 或 Web UI)发送结果。 |
表6-2 Hive 执行流程
3. Hive 服务器
我们在“(三):Kettle 对 Hadoop 的支持”中已经提到过 Hive 有 HiveServer 和 HiveServer2 两版服务器,并指出了两个版本的主要区别,这里再对 HiveServer2 做一些深入的补充说明。
HiveServer2(后面简称 HS2)是从 Hive 0.11 版本开始引入的,它提供了一个服务器接口,允许客户端在 Hive 中执行查询并取回查询结果。当前的实现是一个 HiveServer 的改进版本,它基于 Thrift RPC,支持多客户端身份认证和并发操作,其设计对 JDBC、ODBC 这样的开放 API 客户端提供了更好的支持。
HS2 使用单一进程提供两种服务,分别是基于 Thrift 的 Hive 服务和一个 Jetty Web 服务器。基于 Thrift 的 Hive 服务是 HS2 的核心,它对 Hive 查询,例如从 Beeline 里发出的查询语句做出响应。Hive 通过 Thrift 提供 Hive 元数据存储的服务。通常来说,用户不能够调用元数据存储方法来直接对元数据进行修改,而应该通过 HiveQL 语言让 Hive 来执行这样的操作。用户应该只能通过只读方式来获取表的元数据信息。
(1)配置 HS2
不同版本的 HS2,配置属性可能会有所不同。最基本的配置是在 hive-site.xml 文件中设置如下属性:
- hive.server2.thrift.min.worker.threads:缺省值是 5,最小工作线程数。
- hive.server2.thrift.max.worker.threads:缺省值是 500,最大工作线程数。
- hive.server2.thrift.port:缺省值是 10000,监听的 TCP 端口号。
- hive.server2.thrift.bind.host:TCP 接口绑定的主机。
除了在 hive-site.xml 配置文件中设置属性,还可以使用环境变量设置相关信息。环境变量的优先级别要高于配置文件,相同的属性如果在环境变量和配置文件中都有设置,则会使用环境变量的设置,就是说环境变量或覆盖掉配置文件里的设置。可以配置如下环境变量:
- HIVE_SERVER2_THRIFT_BIND_HOST:指定 TCP 接口绑定的主机。
- HIVE_SERVER2_THRIFT_PORT:指定监听的 TCP 端口号,缺省值是 10000。
HS2 支持通过 HTTP 协议传输 Thrift RPC 消息(Hive 0.13 以后的版本),这种方式特别用于支持客户端和服务器之间存在代理层的情况。当前 HS2 可以运行在 TCP 模式或 HTTP 模式下,但是不能同时使用两种模式。使用下面的属性设置启用 HTTP 模式:
- hive.server2.transport.mode:缺省值是 binary,设置为 http 启用 HTTP 传输模式。
- hive.server2.thrift.http.port:缺省值是 10001,监听的 HTTP 端口号。
- hive.server2.thrift.http.max.worker.threads:缺省值是 500,服务器池中的最大工作线程数。
- hive.server2.thrift.http.min.worker.threads:缺省值是 5,服务器池中的最小工作线程数。
可以配置 hive.server2.global.init.file.location 属性指定一个全局初始化文件的位置(Hive 0.14 以后版本),它或者是初始化文件本身的路径,或者是一个名为“.hiverc”的文件所在的目录。在这个初始化文件中可以包含的一系列命令,这些命令会在 HS2 实例中运行,例如注册标准的 JAR 包或函数等。
如下参数配置 HS2 的操作日志:
- hive.server2.logging.operation.enabled:缺省值是 true,当设置为 true 时,HS2 会保存对客户端的操作日志。
- hive.server2.logging.operation.log.location:缺省值是 ${java.io.tmpdir}/${user.name}/operation_logs,指定存储操作日志的顶级目录。
- hive.server2.logging.operation.verbose:缺省值是 false,如果设置为 true,HS2 客户端将会打印详细信息。
- hive.server2.logging.operation.level:缺省值是 EXECUTION,该值允许在客户端的会话级进行设置。有四种日志级别,NONE 忽略任何日志;EXECUTION 记录完整的任务日志;PERFORMANCE 在 EXECUTION 加上性能日志;VERBOSE 记录全部日志。
缺省情况下,HS2 以连接服务器的用户的身份处理查询,但是如果将下面的属性设置为 false,那么查询将以运行 HS2 进程的用户身份执行。当遇到无法创建临时表一类的错误时,可以尝试设置此属性。
- hive.server2.enable.doAs:作为连接用户的身份,缺省值为 true。
为了避免不安全的内存溢出,可以通过将以下参数设置为 true,禁用文件系统缓存。
- fs.hdfs.impl.disable.cache:禁用 HDFS 缓存,缺省值为 false。
- fs.file.impl.disable.cache:禁用本地文件系统缓存,缺省值为 false。
(2)临时目录管理
HS2 允许配置临时目录,这些目录被 Hive 用于存储中间临时输出。临时目录相关的配置属性如下。
- hive.scratchdir.lock:缺省值是 false。如果设置为 true,临时目录中会持有一个锁文件。如果一个 Hive 进程异常挂掉,可能会遗留下挂起的临时目录。使用 cleardanglingscratchdir 工具能够删除挂起的临时目录。如果此参数为 false,则不会建立锁文件,cleardanglingscratchdir 工具也不能删除任何挂起的临时目录。
- hive.exec.scratchdir:指定 Hive 作业使用的临时空间目录。该目录用于存储为查询产生的不同 map/reduce 阶段计划,也存储这些阶段的中间输出。
- hive.scratch.dir.permission:缺省值是 700。指定特定用户对根临时目录的权限。
- hive.start.cleanup.scratchdir:缺省值是 false。指定是否在启动 HS2 时清除临时目录。在多用户环境下不使用该属性,因为可能会删除正在使用的临时目录。
(3)HS2 的 Web 用户界面(Hive 2.0.0 引入)
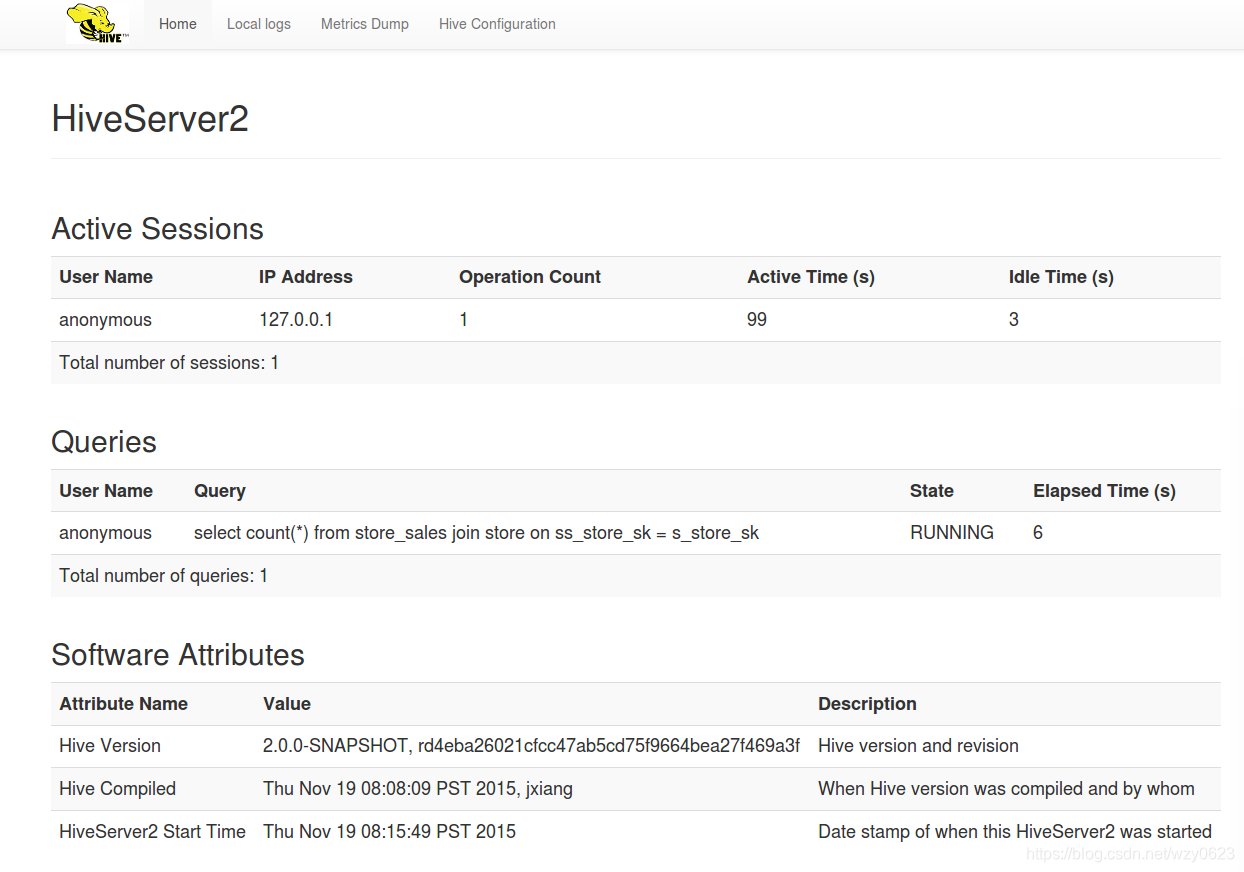
HS2 的 Web 界面提供配置、日志、度量和活跃会话等信息,其使用的缺省端口是 10002。可以设置 hive-site.xml 文件中的 hive.server2.webui.host、hive.server2.webui.port、hive.server2.webui.max.threads 等属性配置 Web 接口。Web 界面如图6-9 所示。
(4)查看 Hive 版本
可以使用两种方法查看 Hive 版本。
- 使用 version() 函数
hive> select version(); OK 2.1.1-cdh6.3.1 re8d55f408b4f9aa2648bc9e34a8f802d53d6aab3 - 查询元数据存储数据库的 version 表
mysql> select * from hive.VERSION; +--------+----------------+----------------------------+ | VER_ID | SCHEMA_VERSION | VERSION_COMMENT | +--------+----------------+----------------------------+ | 1 | 2.1.1 | Hive release version 2.1.1 | +--------+----------------+----------------------------+ 1 row in set (0.00 sec)
4. Hive 优化
Hive 的执行依赖于底层的 MapReduce 作业,因此对 Hadoop 作业的优化或者对 MapReduce 作业的调整是提高 Hive 性能的基础。大多数情况下,用户不需要了解 Hive 内部是如何工作的。但是当对 Hive 具有越来越多的经验后,学习一些 Hive 的底层实现细节和优化知识,会让用户更加高效地使用 Hive。如果没有适当的调整,那么即使查询 Hive 中的一个小表,有时也会耗时数分钟才得到结果。也正是因为这个原因,Hive 对于 OLAP 类型的应用有很大的局限性,它不适合需要立即返回查询结果的场景。然而,通过实施下面一系列的调优方法,Hive 查询的性能会有大幅提高。
(1)启用压缩
压缩可以使磁盘上存储的数据量变小。例如,文本文件格式能够压缩 40% 甚至更高比例,这样可以通过降低 I/O 来提高查询速度。除非产生的数据用于外部系统,或者存在格式兼容性问题,建议总是启用压缩。压缩与解压缩会消耗 CPU 资源,但 Hive 产生的 MadReduce 作业往往是 I/O 密集型的,因此 CPU 开销通常不是问题。
为了启用压缩,需要查出所使用的 Hive 版本支持的压缩编码方式,下面的 set 命令列出可用的编解码器(CDH 5.7.0 中的 Hive)。
hive> set io.compression.codecs;
io.compression.codecs=org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.DeflateCodec,org.apache.hadoop.io.compress.SnappyCodec,org.apache.hadoop.io.compress.Lz4Codec
hive>一个复杂的 Hive 查询在提交后,通常被转换为一系列中间阶段的 MapReduce 作业,Hive 引擎将这些作业串联起来完成整个查询。可以将这些中间数据进行压缩。这里所说的中间数据指的是上一个 MapReduce 作业的输出,这些输出将被下一个 MapReduce 作业作为输入数据使用。我们可以在 hive-site.xml 文件中设置 hive.exec.compress.intermediate 属性以启用中间数据压缩。
<property>
<name>hive.exec.compress.intermediate</name>
<value>true</value>
<description/>
</property>
<property>
<name>hive.intermediate.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description/>
</property>
<property>
<name>hive.intermediate.compression.type</name>
<value>BLOCK</value>
<description/>
</property>也可以在 Hive 客户端中使用 set 命令设置这些属性:
hive> set hive.exec.compress.intermediate=true;
hive> set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
hive> set hive.intermediate.compression.type=BLOCK;当 Hive 将输出写入到表中时,输出内容同样可以进行压缩。我们可以设置 hive.exec.compress.output 属性启用最终输出压缩。
<property>
<name>hive.exec.compress.output</name>
<value>true</value>
<description/>
</property>或者:
hive> set hive.exec.compress.output=true;
hive> set mapreduce.output.fileoutputformat.compress=true;
hive> set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
hive> set mapreduce.output.fileoutputformat.compress.type=BLOCK;(2)优化连接
可以通过配置 Map 连接和倾斜连接的相关属性提升连接查询的性能。
- 自动 Map 连接
当连接一个大表和一个小表时,自动 Map 连接是一个非常有用的特性。如果启用了该特性,小表将保存在每个节点的本地缓存中,并在 Map 阶段与大表进行连接。开启自动 Map 连接提供了两个好处。首先,将小表装进缓存将节省每个数据节点上读取时间。其次,它避免了 Hive 查询中的倾斜连接,因为每个数据块的连接操作已经在 Map 阶段完成了。设置下面的属性启用自动 Map 连接属性。
<property>
<name>hive.auto.convert.join</name>
<value>true</value>
</property>
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
</property>
<property>
<name>hive.auto.convert.join.noconditionaltask.size</name>
<value>10000000</value>
</property>
<property>
<name>hive.auto.convert.join.use.nonstaged</name>
<value>true</value>
</property>属性说明:
hive.auto.convert.join:是否启用基于输入文件的大小,将普通连接转化为 Map 连接的优化机制。
hive.auto.convert.join.noconditionaltask:是否启用基于输入文件的大小,将普通连接转化为 Map 连接的优化机制。假设参与连接的表(或分区)有 N 个,如果打开这个参数,并且有 N-1 个表(或分区)的大小总和小于 hive.auto.convert.join.noconditionaltask.size 参数指定的值,那么会直接将连接转为 Map 连接。
hive.auto.convert.join.noconditionaltask.size:如果 hive.auto.convert.join.noconditionaltask 是关闭的,则本参数不起作用。否则,如果参与连接的 N 个表(或分区)中的 N-1 个的总大小小于这个参数的值,则直接将连接转为 Map 连接。缺省值为 10MB。
hive.auto.convert.join.use.nonstaged:对于条件连接,如果从一个小的输入流可以直接应用于 join 操作而不需要过滤或者投影,那么不需要通过 MapReduce 的本地任务在分布式缓存中预存。当前该参数在 vectorization 或 Tez 执行引擎中不工作。
- 倾斜连接
两个大表连接时,会先基于连接键分别对两个表进行排序,然后连接它们。Mapper 将特定键值的所有行发送给同一个 Reducer。例如,表 A 的 id 列有 1、2、3、4 四个值,表 B 的 id 列有 1、2、3 三个值。查询语句如下:
select A.id from A join B on A.id = B.id一系列 Mapper 读取表中的数据并基于键值发送给 Reducer。如 id=1 的行进入 Reducer R1,id=2 的行进入 Reducer R2 等等。这些 Reducer 产生 A、B 的交集并输出。Reducer R4 只从 A 获取行,不会产生查询结果。
现在假设 id=1 的数据行是高度倾斜的,则 R2 和 R3 会很快完成,而 R1 需要很长时间,将成为整个查询的瓶颈。配置倾斜连接的相关属性可以有效优化倾斜连接。
<property>
<name>hive.optimize.skewjoin</name>
<value>true</value>
</property>
<property>
<name>hive.skewjoin.key</name>
<value>100000</value>
</property>
<property>
<name>hive.skewjoin.mapjoin.map.tasks</name>
<value>10000</value>
</property>
<property>
<name>hive.skewjoin.mapjoin.min.split</name>
<value>33554432</value>
</property>属性说明:
hive.optimize.skewjoin:是否为连接表中的倾斜键创建单独的执行计划。它基于存储在元数据中的倾斜键。在编译时,Hive 为倾斜键和其它键值生成各自的查询计划。
hive.skewjoin.key:决定如何确定连接中的倾斜键。在连接操作中,如果同一键值所对应的数据行数超过该参数值,则认为该键是一个倾斜连接键。
hive.skewjoin.mapjoin.map.tasks:指定倾斜连接中,用于 Map 连接作业的任务数。该参数应该与 hive.skewjoin.mapjoin.min.split 一起使用,执行细粒度的控制。
hive.skewjoin.mapjoin.min.split:通过指定最小 split 的大小,确定 Map 连接作业的任务数。该参数应该与 hive.skewjoin.mapjoin.map.tasks 一起使用,执行细粒度的控制。
- 桶 Map 连接
如果连接中使用的表是按特定列分桶的,可以开启桶 Map 连接提升性能。
<property>
<name>hive.optimize.bucketmapjoin</name>
<value>true</value>
</property>
<property>
<name>hive.optimize.bucketmapjoin.sortedmerge</name>
<value>true</value>
</property>属性说明:
hive.optimize.bucketmapjoin:是否尝试桶 Map 连接。
hive.optimize.bucketmapjoin.sortedmerge:是否尝试在 Map 连接中使用归并排序。
(3)避免使用 order by 全局排序
Hive 中使用 order by 子句实现全局排序。order by 只用一个 reducer 产生结果,对于大数据集,这种做法效率很低。如果不需要全局有序,则可以使用 sort by 子句,该子句为每个 reducer 生成一个排好序的文件。如果需要控制一个特定数据行流向哪个 reducer,可以使用 distribute by 子句,例如:
select id, name, salary, dept from employee
distribute by dept sort by id asc, name desc;属于一个 dept 的数据会分配到同一个 reducer 进行处理,同一个 dept 的所有记录按照 id、name 列排序。最终的结果集是全局有序的。
(4)启用 Tez 执行引擎
使用 Tez 执行引擎代替传统的 MapReduce 引擎会大幅提升 Hive 查询的性能。在安装好 Tez 后,配置 hive.execution.engine 属性指定执行引擎。
<property>
<name>hive.execution.engine</name>
<value>tez</value>
<description/>
</property>(5)优化 limit 操作
缺省时 limit 操作仍然会执行整个查询,然后返回限定的行数。在有些情况下这种处理方式很浪费,因此可以通过设置下面的属性避免此行为。
<property>
<name>hive.limit.optimize.enable</name>
<value>true</value>
</property>
<property>
<name>hive.limit.row.max.size</name>
<value>100000</value>
</property>
<property>
<name>hive.limit.optimize.limit.file</name>
<value>10</value>
</property>
<property>
<name>hive.limit.optimize.fetch.max</name>
<value>50000</value>
</property>属性说明:
hive.limit.optimize.enable:是否启用 limit 优化。当使用 limit 语句时,对源数据进行抽样。
hive.limit.row.max.size:在使用 limit 做数据的子集查询时保证的最小行数据量。
hive.limit.optimize.limit.file:在使用 limit 做数据子集查询时,采样的最大文件数。
hive.limit.optimize.fetch.max:使用简单 limit 数据抽样时,允许的最大行数。
(6)启用并行执行
每条 HiveQL 语句都被转化成一个或多个执行阶段,可能是一个 MapReduce 阶段、采样阶段、归并阶段、限制阶段等。缺省时,Hive 在任意时刻只能执行其中一个阶段。如果组成一个特定作业的多个执行阶段是彼此独立的,那么它们可以并行执行,从而整个作业得以更快完成。通过设置下面的属性启用并行执行。
<property>
<name>hive.exec.parallel</name>
<value>true</value>
</property>
<property>
<name>hive.exec.parallel.thread.number</name>
<value>8</value>
</property>属性说明:
hive.exec.parallel:是否并行执行作业。
hive.exec.parallel.thread.number:最多可以并行执行的作业数。
(7)启用 MapReduce 严格模式
Hive 提供了一个严格模式,可以防止用户执行那些可能产生负面影响的查询。通过设置下面的属性启用 MapReduce 严格模式。
<property>
<name>hive.mapred.mode</name>
<value>strict</value>
</property>严格模式禁止下面三种类型的查询:
- 对于分区表,where 子句中不包含分区字段过滤条件的查询语句不允许执行。
- 对于使用了 order by 子句的查询,要求必须使用 limit 子句,否则不允许执行。
- 限制笛卡尔积查询。
(8)使用单一 Reduce 执行多个 Group By
通过为 group by 操作开启单一 reduce 任务属性,可以将一个查询中的多个 group by 操作联合在一起发送给单一 MapReduce 作业。
<property>
<name>hive.multigroupby.singlereducer</name>
<value>true</value>
<description/>
</property>(9)控制并行 Reduce 任务
Hive 通过将查询划分成一个或多个 MapReduce 任务达到并行的目的。确定最佳的 mapper 个数和 reducer 个数取决于多个变量,例如输入的数据量以及对这些数据执行的操作类型等。如果有太多的 mapper 或 reducer 任务,会导致启动、调度和运行作业过程中产生过多的开销,而如果设置的数量太少,那么就可能没有充分利用好集群内在的并行性。对于一个 Hive 查询,可以设置下面的属性来控制并行 reduce 任务的个数。
<property>
<name>hive.exec.reducers.bytes.per.reducer</name>
<value>256000000</value>
</property>
<property>
<name>hive.exec.reducers.max</name>
<value>1009</value>
</property>属性说明:
hive.exec.reducers.bytes.per.reducer:每个 reducer 的字节数,缺省值为 256MB。Hive 是按照输入的数据量大小来确定 reducer 个数的。例如,如果输入的数据是 1GB,将使用 4 个 reducer。
hive.exec.reducers.max:将会使用的最大 reducer 个数。
(10)启用向量化
向量化特性在 Hive 0.13.1 版本中被首次引入。通过查询执行向量化,使 Hive 从单行处理数据改为批量处理方式,具体来说是一次处理 1024 行而不是原来的每次只处理一行,这大大提升了指令流水线和缓存的利用率,从而提高了表扫描、聚合、过滤和连接等操作的性能。可以设置下面的属性启用查询执行向量化。
<property>
<name>hive.vectorized.execution.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.vectorized.execution.reduce.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.vectorized.execution.reduce.groupby.enabled</name>
<value>true</value>
</property>属性说明:
hive.vectorized.execution.enabled:如果该标志设置为 true,则开启查询执行的向量模式,缺省值为 false。
hive.vectorized.execution.reduce.enabled:如果该标志设置为 true,则开启查询执行 reduce 端的向量模式,缺省值为 true。
hive.vectorized.execution.reduce.groupby.enabled:如果该标志设置为 true,则开启查询执行 reduce 端 group by 操作的向量模式,缺省值为 true。
(11)启用基于成本的优化器
Hive 0.14 版本开始提供基于成本优化器(CBO)特性。使用过 Oracle 数据库的读者对 CBO 一定不会陌生。与 Oracle 类似,Hive 的 CBO 也可以根据查询成本制定执行计划,例如,确定表连接的顺序,以何种方式执行连接,使用的并行度等等。设置下面的属性启用基于成本优化器。
<property>
<name>hive.cbo.enable</name>
<value>true</value>
</property>
<property>
<name>hive.compute.query.using.stats</name>
<value>true</value>
</property>
<property>
<name>hive.stats.fetch.partition.stats</name>
<value>true</value>
</property>
<property>
<name>hive.stats.fetch.column.stats</name>
<value>true</value>
</property>属性说明:
hive.cbo.enable:控制是否启用基于成本的优化器,缺省值是 true。Hive 的 CBO 使用 Apache Calcite 框架实现。
hive.compute.query.using.stats:该属性的缺省值为 false。如果设置为 true,Hive 在执行某些查询时,例如 select count(1),只利用元数据存储中保存的状态信息返回结果。为了收集基本状态信息,需要将 hive.stats.autogather 属性配置为 true。为了收集更多的状态信息,需要运行 analyze table 查询命令。
hive.stats.fetch.partition.stats:该属性的缺省值为 true。操作树中所标识的统计信息,需要分区级别的基本统计,如每个分区的行数、数据量大小和文件大小等。分区统计信息从元数据存储中获取。如果存在很多分区,要为每个分区收集统计信息可能会消耗大量的资源。这个标志可被用于禁止从元数据存储中获取分区统计。当该标志设置为 false 时,Hive 从文件系统获取文件大小,并根据表结构估算行数。
hive.stats.fetch.column.stats:该属性的缺省值为 false。操作树中所标识的统计信息,需要列统计。列统计信息从元数据存储中获取。如果存在很多列,要为每个列收集统计信息可能会消耗大量的资源。这个标志可被用于禁止从元数据存储中获取列统计。
可以使用 HiveQL 的 analyze table 语句收集一个表中所有列相关的基本统计信息,例如下面的语句收集 sales_order_fact 表的统计信息。
analyze table sales_order_fact compute statistics for columns;
analyze table sales_order_fact compute statistics for columns order_number, customer_sk;(12)使用 ORC 文件格式
ORC 文件格式可以有效提升 Hive 查询的性能。图6-10 由 Hortonworks 公司提供,显示了 Hive 不同文件格式的大小对比。

三、初始装载
对 Hive 的服务器结构一定了解后,我们开始使用 Kettle 创建销售订单示例数据仓库数据装载的作业和转换。在数据仓库可以使用前,需要装载历史数据。这些历史数据是导入进数据仓库的第一个数据集合。首次装载被称为初始装载,一般是一次性工作。由最终用户来决定有多少历史数据进入数据仓库。例如,数据仓库使用的开始时间是 2020 年 3 月 1 日,而用户希望装载两年的历史数据,那么应该初始装载 2018 年 3 月 1 日到 2020 年 2 月 29 日之间的源数据。在 2020 年 3 月 2 日装载 2020 年 3 月 1 日的数据(假设执行频率是每天一次),之后周期性地每天装载前一天的数据。在装载事实表前,必须先装载所有的维度表。因为事实表需要引用维度的代理键。这不仅针对初始装载,也针对定期装载。本节说明执行初始装载的步骤,包括标识源数据、维度历史的处理、创建相关 Kettle 作业和转换,以及验证初始装载过程。
设计开发初始装载步骤前需要识别数据仓库的每个事实表和每个维度表用到的并且是可用的源数据,还要了解数据源的特性,例如文件类型、记录结构和可访问性等。表8-3 显示的是销售订单示例数据仓库需要的源数据的关键信息,包括源数据表、对应的数据仓库目标表等属性。这类表格通常称作数据源对应图,因为它反应了每个从源数据到目标数据的对应关系。在本示例中,客户和产品的源数据直接与其数据仓库里的目标表,customer_dim 和 product_dim 表相对应,而销售订单事务表是多个数据仓库表的数据源。
| 源数据 | 源数据类型 | 文件名/表名 | 数据仓库中的目标表 |
| 客户 | MySQL表 | customer | customer_dim |
| 产品 | MySQL表 | product | product_dim |
| 销售订单 | MySQL表 | sales_order | order_dim、sales_order_fact |
表8-3 销售订单数据源映射
标识出了数据源,现在要考虑维度历史的处理。大多数维度值是随着时间改变的,如客户改变了姓名,产品的名称或分类变化等。当一个维度改变,比如当一个产品有了新的分类时,有必要记录维度的历史变化信息。在这种情况下,product_dim 表里必须既存储产品老的分类,也存储产品当前的分类。并且,老的销售订单里的产品引用老的分类。渐变维(SCD)即是一种在多维数据仓库中实现维度历史的技术。有三种不同的 SCD 技术:SCD 类型1(SCD1),SCD 类型2(SCD2),SCD 类型3(SCD3):
- SCD1:通过更新维度记录直接覆盖已存在的值,它不维护记录的历史。SCD1 一般用于修改错误的数据。
- SCD2:在源数据发生变化时,给维度记录建立一个新的“版本”记录,从而维护维度历史。SCD2 不删除、修改已存在的数据。
- SCD3:通常用作保持维度记录的几个版本。它通过给某个数据单元增加多个列来维护历史。例如,为了记录客户地址的变化,customer_dim 维度表有一个 customer_address 列和一个 previous_customer_address 列,分别记录当前和上一个版本的地址。SCD3 可以有效维护有限的历史,而不像 SCD2 那样保存全部历史。SCD3 很少使用,它只适用于数据的存储空间不足并且用户接受有限维度历史的情况。
同一个维度表中的不同字段可以有不同的变化处理方式。在本示例中,客户维度历史的客户名称使用 SCD1,客户地址使用 SCD2,产品维度的两个属性,产品名称和产品类型都使用 SCD2 保存历史变化数据。
多维数据仓库中的维度表和事实表一般都需要有一个代理键,作为这些表的主键,代理键一般由单列的自增数字序列构成。Hive 没有关系数据库中的自增列,但它也有一些对自增序列的支持,通常有两种方法生成代理键:使用 row_number() 窗口函数或者使用一个名为 UDFRowSequence 的用户自定义函数(UDF)。
假设有维度表 tbl_dim 和过渡表 tbl_stg,现在要将 tbl_stg 的数据装载到 tbl_dim,装载的同时生成维度表的代理键。
- 用 row_number() 函数生成代理键
insert into tbl_dim
select row_number() over (order by tbl_stg.id) + t2.sk_max, tbl_stg.*
from tbl_stg
cross join (select coalesce(max(sk),0) sk_max from tbl_dim) t2; 上面语句中,先查询维度表中已有记录最大的代理键值,如果维度表中还没有记录,利用 coalesce 函数返回 0。然后使用 cross join 连接生成过渡表和最大代理键值的笛卡尔集,最后使用 row_number() 函数生成行号,并将行号与最大代理键值相加的值,作为新装载记录的代理键。
- 用 UDFRowSequence 生成代理键
add jar hdfs:///user/hive-contrib-2.0.0.jar;
create temporary function row_sequence as 'org.apache.hadoop.hive.contrib.udf.udfrowsequence';
insert into tbl_dim
select row_sequence() + t2.sk_max, tbl_stg.*
from tbl_stg
cross join (select coalesce(max(sk),0) sk_max from tbl_dim) t2;hive-contrib-2.0.0.jar 中包含一个生成记录序号的自定义函数 udfrowsequence。上面的语句先加载 JAR 包,然后创建一个名为 row_sequence() 的临时函数作为调用 UDF 的接口,这样可以为查询的结果集生成一个自增伪列。之后就和 row_number() 写法类似了,只不过将窗口函数 row_number() 替换为 row_sequence() 函数。
因为窗口函数的方法比较通用,而且无需引入额外的 JAR 包,所以我们在示例中使用 row_number() 函数生成代理键。初始装载 Kettle 作业如图6-11 所示。
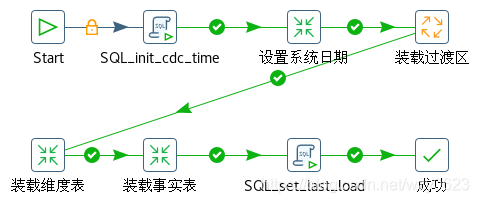
初始装载作业流程描述如下:
- 系统初始化,包括更新时间戳表的当前装载日期,设置变量并赋值。
- 装载过渡区。
- 装载数据仓库维度表。
- 装载数据仓库事实表。
- 设置时间戳表的最后装载日期。
1. 系统初始化
系统初始化部分包括“SQL_init_cdc_time”和“设置系统日期”两个作业项。“SQL_init_cdc_time”作业项中执行的 SQL 语句如下,用于数据初始化,以便测试或排错后重复执行,实现幂等操作。
truncate table dw.customer_dim;
truncate table dw.product_dim;
update rds.cdc_time set last_load='1970-01-01', current_load='1970-01-01';“设置系统日期”作业项调用一个如图6-12 所示的转换,用于获取当前系统日期,更新时间戳表 rds.cdc_time,并设置相关变量。
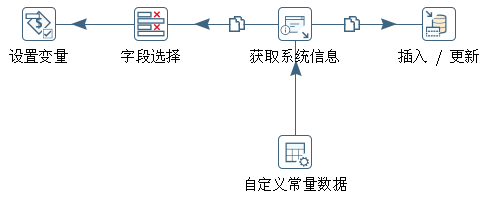
“自定义常量步骤”设置一个 Date 类型的常量 max_date,格式为yyyy-MM-dd,数据为 2200-01-01。该值用于设置渐变维的初始过期日期。“获取系统信息”步骤中用两个字段 cur_date 和 pre_date 表示当前日期和前一天的日期。当前日期用于获得需要处理的数据,前一天日期用于设置变量,在后续步骤中构成文件名。该步骤定义如下,两个字段将被以复制方式发送到“字段选择”和“插入/更新”步骤。
名称 类型
cur_date 今天 00:00:00
pre_date 昨天 00:00:00“字段选择”步骤用于将 pre_date 字段格式化为“yyyy-MM-dd”形式。在该步骤的“元数据”标签中进行如下定义:
字段名称 类型 格式
pre_date Date yyyy-MM-dd“设置变量”步骤设置两个变量 PRE_DATE、MAX_DATE,变量值从 pre_date 和 max_date 数据流字段获得。“变量活动类型”选择“Valid in the root job”,使得作业中涉及的所有子作业或转换都可以使用这两个变量。
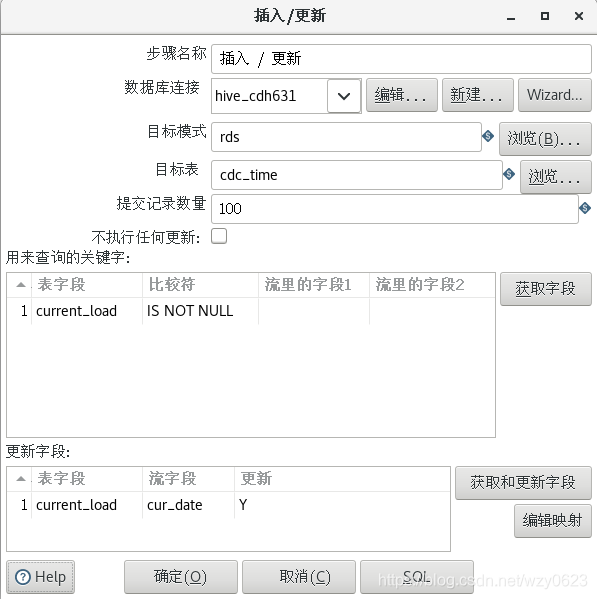
“插入/更新”步骤定义如图6-13 所示。该步骤的功能类似于 SQL 中 replace into 或 merge into。当 rds.cdc_time 表字段 current_load 为 NULL 时执行插入操作,否则更新该字段的值,插入或更新的值为数据流字段 cur_date 的值。
2. 装载过渡区
“装载过渡区”作业项调用的是一个子作业,如图6-14 所示。

该作业包括“Sqoop import customer”、“Sqoop import product”、“load_sales_order”三个作业项。前两个 Sqoop 作业的命令行定义如下,其含义与功能在前一篇中已经详细讲解,这里不再赘述。
--connect jdbc:mysql://node3:3306/source --delete-target-dir --password 123456 --table customer --target-dir /user/hive/warehouse/rds.db/customer --username root
--connect jdbc:mysql://node3:3306/source --delete-target-dir --password 123456 --table product --target-dir /user/hive/warehouse/rds.db/product --username root“load_sales_order”作业项调用的是一个装载事实表的转换,如图6-15 所示。

“表输入”步骤执行下面的 SQL,查询出当前日期与最后装载日期,本例中分别为“2020-10-07”和“1971-01-01”。
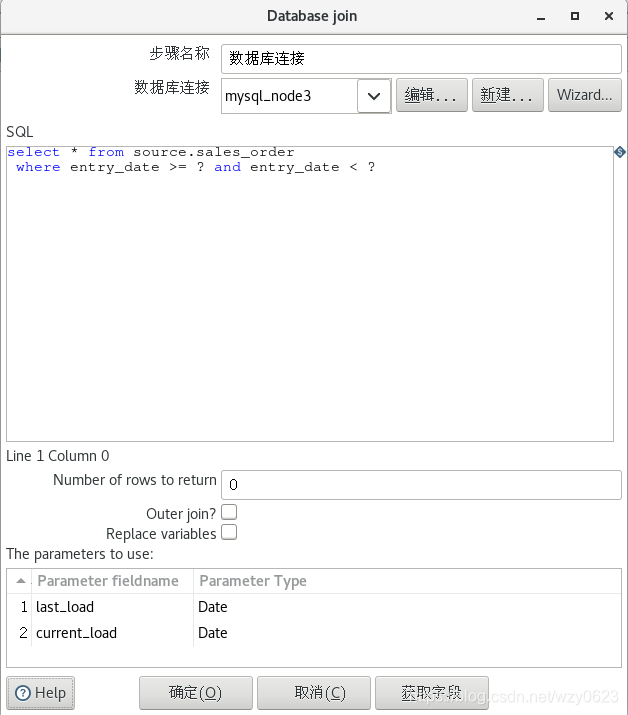
select id, last_load, current_load from rds.cdc_time;“数据库连接”步骤的定义如图6-16 所示。该步骤将前一步骤输出的 last_load 和 current_load 字段作为参数,查询出源数据中 sales_order 表的全部数据。
最后的“Hadoop file output”步骤将 sales_order 源数据以文本文件的形式,存储到 rds.sales_order 表对应的 HDFS 目录下。在该步骤的“文件”标签页中,“Folder/File”属性输入“/user/hive/warehouse/rds.db/sales_order/sales_order”,“扩展名”属性输入“txt”。“内容”标签页中,“分隔符”为“,”,“编码”选择“UTF-8”。字段标签页的定义表6-4 所示。注意由于性能原因,对于 Hive 表不能使用普通的“表输出”步骤为其装载数据。
| 名称 | 类型 | 格式 | 长度 | 精度 |
| order_number | Integer | 9 | 0 | |
| customer_number | Integer | 9 | 0 | |
| product_code | Integer | 9 | 0 | |
| order_date | Date | yyyy-MM-dd HH:mm:ss | 0 | |
| entry_date | Date | yyyy-MM-dd HH:mm:ss | 0 | |
| order_amount | Number | 00000000.00 | 10 | 2 |
表6-4 sales_order.txt 文件字段定义
3. 装载维度表
“装载维度表”作业项调用一个如图6-17 所示的转换。
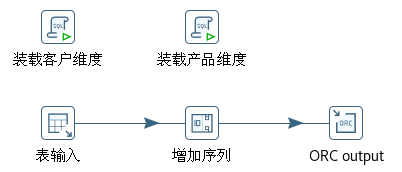
“装载客户维度”执行下面的 SQL 语句:
use dw;
insert into customer_dim
select row_number() over (order by t1.customer_number) + t2.sk_max,
t1.customer_number, t1.customer_name, t1.customer_street_address,
t1.customer_zip_code, t1.customer_city, t1.customer_state, 1,
'2020-03-01', '2200-01-01'
from rds.customer t1
cross join (select coalesce(max(customer_sk),0) sk_max from customer_dim) t2;“装载产品维度”执行下面的 SQL 语句:
use dw;
insert into product_dim
select row_number() over (order by t1.product_code) + t2.sk_max,
t1.product_code, t1.product_name, t1.product_category, 1,
'2020-03-01', '2200-01-01'
from rds.product t1
cross join (select coalesce(max(product_sk),0) sk_max from product_dim) t2;说明:
- 时间粒度为每天,也就是说,一天内的发生的数据变化将被忽略,以一天内最后的数据版本为准。
- 使用了窗口函数 row_number() 实现生成代理键。
- 客户和产品维度的生效日期是 2020 年 3 月 1 日。装载的销售订单不会早于该日期,也就是说,不需要更早的客户和产品维度数据。
订单维度表的装载当然也可以使用类似的“执行SQL语句”步骤,但订单维度与客户维度或产品维度不同。在前一篇中曾提到,它的数据是单向递增的,不涉及数据更新,因此这里使用“表输入”、“增加序列”、“ORC output”三个步骤装载订单维度数据。
“表输入”步骤中执行以下查询:
select order_number,
1 version,
date_format(order_date,'yyyy-mm-dd') effective_date,
'2200-01-01' expiry_date
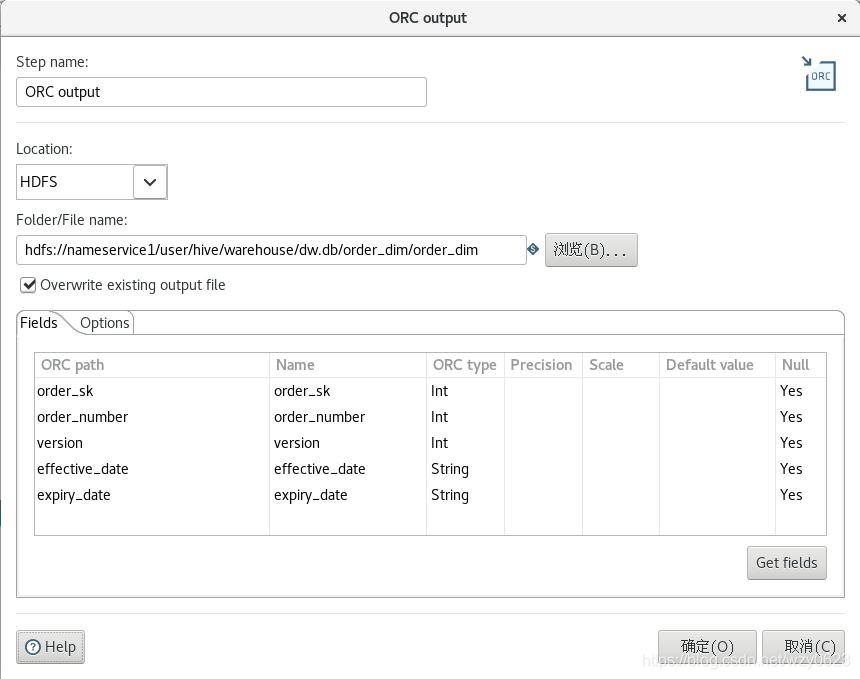
from rds.sales_order order by order_number;因为不会更新,订单维度的版本号恒为1,而其生效日期显然就是订单生成的日期(order_date 字段)。为了使所有维度表具有相同的粒度,使用 date_format 函数将订单维度的生效日期字段只保留到日期,忽略时间部分。“增加序列”步骤生成代理键,将“值的名称”定义为 order_sk。“ORC output”步骤的定义如图6-18 所示。与装载过渡区的 rds.sales_order 表类似,这里也是将数据以文件形式上传到 Hive 表所对应的 HDFS 目录。dw 库中的维度表是 ORC 格式,因此将“Hadoop file output”步骤替换为“ORC output”步骤。
4. 装载事实表
“装载事实表”作业项调用一个如图6-19 所示的转换。
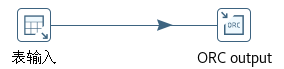
该转换比较简单,只有“表输入”和“ORC output”两个步骤。“表输入”步骤执行下面的查询,销售订单事实表的外键列引用维度表的代理键。date_dim 维度表的数据已经预生成,日期从 2018 年 1 月 1 日到 2022 年 12 月 31 日,参见“(四):建立 ETL 示例模型”。这里说的外键只是逻辑上的外键,Hive 并不支持创建表的物理主键或外键。
select order_sk, customer_sk, product_sk, date_sk, order_amount
from rds.sales_order a, dw.order_dim b, dw.customer_dim c, dw.product_dim d, dw.date_dim e
where a.order_number = b.order_number
and a.customer_number = c.customer_number
and a.product_code = d.product_code
and to_date(a.order_date) = e.dt;“ORC output”与上一步装载 dw.order_dim 表的步骤相同,只是将“Folder/File name”属性值改为:
hdfs://nameservice1/user/hive/warehouse/dw.db/sales_order_fact/sales_order_fact5. 设置时间戳表的最后装载日期
初始装载的最后一个作业项是“SQL”,执行下面的语句,将最后装载日期更新为当前装载日期。对于时间戳表的详细使用说明参见“(五):数据抽取”。
update rds.cdc_time set last_load=current_load;成功执行初始装载作业后,可以在 Hive 中执行下面的查询验证数据正确性。
use dw;
select order_number,customer_name,product_name,dt,order_amount amount
from sales_order_fact a, customer_dim b, product_dim c, order_dim d, date_dim e
where a.customer_sk = b.customer_sk
and a.product_sk = c.product_sk
and a.order_sk = d.order_sk
and a.order_date_sk = e.date_sk
order by order_number;四、定期装载
初始装载只在开始数据仓库使用前执行一次,然而,必须要按时调度定期执行装载源数据的过程。与初始装载不同,定期装载一般都是增量的,并且需要捕获和记录数据的变化历史。本节说明执行定期装载的步骤,包括识别源数据与装载类型、创建 Kettle 作业和转换实现定期增量装载过程并执行验证。
定期装载首先要识别数据仓库的每个事实表和每个维度表用到的并且是可用的源数据。然后要决定适合装载的抽取模式和维度历史装载类型。表6-5 汇总了本示例的这些信息。
| 数据源 | 源数据存储 | 数据仓库 | 抽取模式 | 维度历史装载类型 |
| customer | customer | customer_dim | 整体、拉取 | address 列上 SCD2,name 列上 SCD1 |
| product | product | product_dim | 整体、拉取 | 所有属性均为 SCD2 |
| sales_order | sales_order | order_dim | CDC(每天)、拉取 | 唯一订单号 |
| sales_order_fact | CDC(每天)、拉取 | N/A | ||
| N/A | N/A | date_dim | N/A | 预装载 |
表6-5 销售订单定期装载
order_dim 维度表和 sales_order_fact 事实表使用基于时间戳的 CDC 装载模式。时间戳表 rds.cdc_time 用于关联查询增量数据。定期装载 Kettle 作业如图6-20 所示。
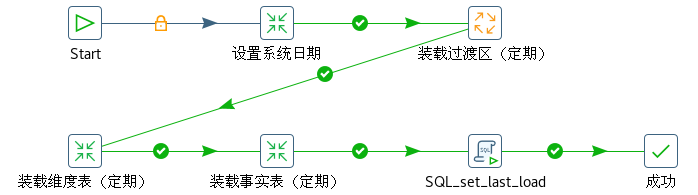
定期装载作业流程描述如下:
- 更新时间戳表的当前装载日期,设置变量并赋值。
- 装载过渡区。
- 装载数据仓库维度表。
- 装载数据仓库事实表。
- 设置时间戳表的最后装载日期。
1. 设置系统日期
“设置系统日期”作业项调用一个如图6-12 所示的转换,用于获取当前系统日期,更新时间戳表 rds.cdc_time,并设置相关变量。每个步骤的定义已经在前面“初始转载”部分说明。该作业项的输出中,last_load 为最后装载日期,current_load 为当前日期。用如下 SQL 即可查询出增量数据:
select * from source.sales_order
where entry_date >= last_load
and entry_date < current_load; 2. 装载过渡区
“装载过渡区”作业项调用的子作业与图6-14 所示的初始装载过渡区只有一点不同:“load_sales_order”作业项调用的转换中,“Hadoop file output”步骤生成的文件,其文件名中带有装载日期,这通过在“Folder/File”属性输入 /user/hive/warehouse/rds.db/sales_order/sales_order_${PRE_DATE} 实现。${PRE_DATE} 引用的是前一作业项“设置系统日期”中所设置的变量,值为当前日期前一天。过渡区的 rds.sales_order 表存储全部销售订单数据,因此需要向表所对应的 HDFS 目录中新增文件,而不能覆盖已有文件。
3. 装载维度表
“装载维度表”作业项调用一个如图6-21 所示的转换。

这个转换貌似很简单,只有三个执行 SQL 脚本的步骤。正如你所想到的,实现渐变维使用的就是 Hive 提供的行级更新功能。与单纯用 shell 执行 SQL 相比,Kettle 转换一个明显的好处是这三个步骤可以并行以提高性能。
“装载客户维度表”步骤中的 SQL 脚本如下:
use dw;
update customer_dim
set expiry_date = '${PRE_DATE}'
where customer_dim.customer_sk in
(select a.customer_sk
from (select customer_sk,customer_number,customer_street_address
from customer_dim where expiry_date = '${MAX_DATE}') a left join
rds.customer b on a.customer_number = b.customer_number
where b.customer_number is null or a.customer_street_address <> b.customer_street_address);
insert into customer_dim
select
row_number() over (order by t1.customer_number) + t2.sk_max,
t1.customer_number,
t1.customer_name,
t1.customer_street_address,
t1.customer_zip_code,
t1.customer_city,
t1.customer_state,
t1.version,
t1.effective_date,
t1.expiry_date
from
(
select
t2.customer_number customer_number,
t2.customer_name customer_name,
t2.customer_street_address customer_street_address,
t2.customer_zip_code,
t2.customer_city,
t2.customer_state,
t1.version + 1 version,
'${PRE_DATE}' effective_date,
'${MAX_DATE}' expiry_date
from customer_dim t1
inner join rds.customer t2
on t1.customer_number = t2.customer_number
and t1.expiry_date = '${PRE_DATE}'
left join customer_dim t3
on t1.customer_number = t3.customer_number
and t3.expiry_date = '${MAX_DATE}'
where t1.customer_street_address <> t2.customer_street_address and t3.customer_sk is null) t1
cross join
(select coalesce(max(customer_sk),0) sk_max from customer_dim) t2;
drop table if exists tmp;
create table tmp as
select
a.customer_sk,
a.customer_number,
b.customer_name,
a.customer_street_address,
a.customer_zip_code,
a.customer_city,
a.customer_state,
a.version,
a.effective_date,
a.expiry_date
from customer_dim a, rds.customer b
where a.customer_number = b.customer_number and (a.customer_name <> b.customer_name);
delete from customer_dim where customer_dim.customer_sk in (select customer_sk from tmp);
insert into customer_dim select * from tmp;
insert into customer_dim
select
row_number() over (order by t1.customer_number) + t2.sk_max,
t1.customer_number,
t1.customer_name,
t1.customer_street_address,
t1.customer_zip_code,
t1.customer_city,
t1.customer_state,
1,
'${PRE_DATE}',
'${MAX_DATE}'
from
(
select t1.* from rds.customer t1 left join customer_dim t2 on t1.customer_number = t2.customer_number
where t2.customer_sk is null) t1
cross join
(select coalesce(max(customer_sk),0) sk_max from customer_dim) t2; 客户维度表的 customer_street_addresses 字段值变化时采用 SCD2,需要新增版本,customer_name 字段值变化时采用 SCD1,直接覆盖更新。如果一个表的不同字段有的采用 SCD2,有的采用 SCD1,就像客户维度表这样,那么是先处理 SCD2,还是先处理 SCD1 呢?为了回答这个问题,我们看一个简单的例子。假设有一个维度表包含 c1,c2、c3、c4 四个字段,c1 是代理键,c2 是业务主键,c3 使用 SCD1,c4 使用 SCD2。源数据从 1、2、3 变为 1、3、4。如果先处理 SCD1,后处理 SCD2,则维度表的数据变化过程是先从 1、1、2、3 变为 1、1、3、3,再新增一条记录 2、1、3、4。此时表中的两条记录是 1、1、3、3 和 2、1、3、4。如果先处理 SCD2,后处理 SCD1,则数据的变化过程是先新增一条记录 2、1、2、4,再把 1、1、2、3 和 2、1、2、4 两条记录变为 1、1、3、3 和 2、1、3、4。可以看出,无论谁先谁后,最终的结果是一样的,而且结果中都会出现一条实际上从未存在过的记录:1、1、3、3。因为 SCD1 本来就不保存历史变化,所以单从 c2 字段的角度看,任何版本的记录值都是正确的,没有差别。而对于 c3 字段,每个版本的值是不同的,需要跟踪所有版本的记录。我们从这个简单的例子可以得出以下结论:SCD1 和 SCD2 的处理顺序不同,但最终结果是相同的,并且都会产生实际不存在的临时记录。因此从功能上说,SCD1 和 SCD2 的处理顺序并不关键,只需要记住对 SCD1 的字段,任意版本的值都正确,而 SCD2 的字段需要跟踪所有版本。但在性能上看,先处理 SCD1 应该更好些,因为更新的数据行更少。本示例我们先处理 SCD2。
第一句的 update 语句设置已删除记录和 customer_street_addresses 列上 SCD2 的过期。该语句将老本的过期时间列从‘2200-01-01’更新为执行装载的前一天。内层的查询获取所有当前版本的数据。外层查询使用一个左外连接查询出地址列发生变化的记录的代理键,然后在 update 语句的 where 子句中用 in 操作符,更新这些记录的过期时间列。left join 的逻辑查询处理顺序是:
- 执行 a 和 b 两个表的笛卡尔积。
- 应用 on 过滤器:on a.customer_number = b.customer_number。
- 添加外部行:a 为保留表,将不满足 on 条件的 a 表记录添加到结果集中。
- 应用 where 过滤器:where b.customer_number is null or a.customer_street_address <> b.customer_street_address,其中 b.customer_number is null 过滤出源数据中已经删除但维度表还存在的记录,a.customer_street_address <> b.customer_street_address 过滤出源数据修改了地址信息的记录。
第二句的 insert 语句处理 customer_street_addresses 列上 SCD2 的新增行。这条语句插入 SCD2 的新增版本行。子查询中用 inner join 获取当期版本号和源数据信息。left join 连接是必要的,否则如果多次执行该语句,会生成多条重复的记录。最后用 row_number() 方法生成新纪录的代理键。新记录的版本号加 1,开始日期为执行时的前一天,过期日期为‘2200-01-01’。
后面的四条 SQL 语句处理 customer_name 列上的 SCD1,因为 SCD1 本身就不保存历史数据,所以这里更新维度表里的所有 customer_name 改变的记录,而不是仅仅更新当前版本的记录。在关系数据库中,SCD1 非常好处理,如在 MySQL 中使用类似如下的语句即可:
update customer_dim a, customer_stg b set a.customer_name = b.customer_name
where a.customer_number = b.customer_number and a.customer_name <> b.customer_name ;但是 Hive 里不能在 update 后跟多个表,也不支持在 set 子句中使用子查询,它只支持 set column = value 的形式,其中 value 只能是一个具体的值或者是一个标量表达式。所以这里使用了一个临时表存储需要更新的记录,然后将维度表和这个临时表关联,用先 delete 再 insert 代替 update。为简单起见也不考虑并发问题(典型数据仓库应用的并发操作基本都是只读的,很少并发写,而且 ETL 通常是一个单独在后台运行的程序,如果用 SQL 实现,并不存在并发执行的情况,所以并发导致的问题并不像 OLTP 那样严重)。
最后的 insert 语句处理新增的 customer 记录。内层子查询使用 rds.customer 和 dw.customer_dim 的左外链接获取新增的数据。新数据的版本号为 1,开始日期为执行时的前一天,过期日期为‘2200-01-01’。同样使用 row_number() 方法生成代理键。到这里,客户维度表的装载处理代码已完成。
“装载产品维度表”步骤中的 SQL 脚本如下:
use dw;
update product_dim
set expiry_date = '${PRE_DATE}'
where product_dim.product_sk in
(select a.product_sk
from (select product_sk,product_code,product_name,product_category
from product_dim where expiry_date = '${MAX_DATE}') a left join
rds.product b on a.product_code = b.product_code
where b.product_code is null or (a.product_name <> b.product_name or a.product_category <> b.product_category));
insert into product_dim
select
row_number() over (order by t1.product_code) + t2.sk_max,
t1.product_code,
t1.product_name,
t1.product_category,
t1.version,
t1.effective_date,
t1.expiry_date
from
(
select
t2.product_code product_code,
t2.product_name product_name,
t2.product_category product_category,
t1.version + 1 version,
'${PRE_DATE}' effective_date,
'${MAX_DATE}' expiry_date
from product_dim t1
inner join rds.product t2
on t1.product_code = t2.product_code
and t1.expiry_date = '${PRE_DATE}'
left join product_dim t3
on t1.product_code = t3.product_code
and t3.expiry_date = '${MAX_DATE}'
where (t1.product_name <> t2.product_name or t1.product_category <> t2.product_category) and t3.product_sk is null) t1
cross join
(select coalesce(max(product_sk),0) sk_max from product_dim) t2;
insert into product_dim
select
row_number() over (order by t1.product_code) + t2.sk_max,
t1.product_code,
t1.product_name,
t1.product_category,
1,
'${PRE_DATE}',
'${MAX_DATE}'
from
(
select t1.* from rds.product t1 left join product_dim t2 on t1.product_code = t2.product_code
where t2.product_sk is null) t1
cross join
(select coalesce(max(product_sk),0) sk_max from product_dim) t2;产品维度表的所有属性都使用 SCD2,处理方法和客户表类似。
“装载订单维度表”步骤中的 SQL 脚本如下:
use dw;
insert into order_dim
select
row_number() over (order by t1.order_number) + t2.sk_max,
t1.order_number,
t1.version,
t1.effective_date,
t1.expiry_date
from
(
select
order_number order_number,
1 version,
order_date effective_date,
'2200-01-01' expiry_date
from rds.sales_order, rds.cdc_time
where entry_date >= last_load and entry_date < current_load ) t1
cross join
(select coalesce(max(order_sk),0) sk_max from order_dim) t2;订单维度表的装载比较简单,因为不涉及维度历史变化,只要将新增的订单号插入 rds.order_dim 表就可以了。上面语句的子查询中,将过渡区库的订单表和时间戳表关联,用时间戳表中的两个字段值作为时间窗口区间的两个端点,用 entry_date >= last_load and entry_date < current_load 条件过滤出上次执行定期装载的日期到当前日期之间的所有销售订单,装载到 order_dim 维度表。
4. 装载事实表
“装载事实表”作业项调用一个如图6-22 所示的转换。

为了装载 dw.sales_order_fact 事实表,需要关联 rds.sales_order 与 dw 库中的四个维度表,获取维度表的代理键和源数据的度量值。这里只有销售金额字段 order_amount 一个度量。和订单维度一样,也要关联时间戳表,获取时间窗口作为确定新增数据的过滤条件。
“表输入”步骤中的 SQL 查询语句如下,输出时间区间的两端日期:
select last_load, current_load from rds.cdc_time;“销售订单事务数据”是一个数据库连接步骤,定义如图6-23 所示,输出度量和维度代理键。虽然“维度查询/更新”步骤也能实现同样的功能,但性能极差。它会对数据流中输入的每一行进行一次维度表查询,相当于在游标中循环执行 select,速度与集合操作的 SQL 相去甚远。
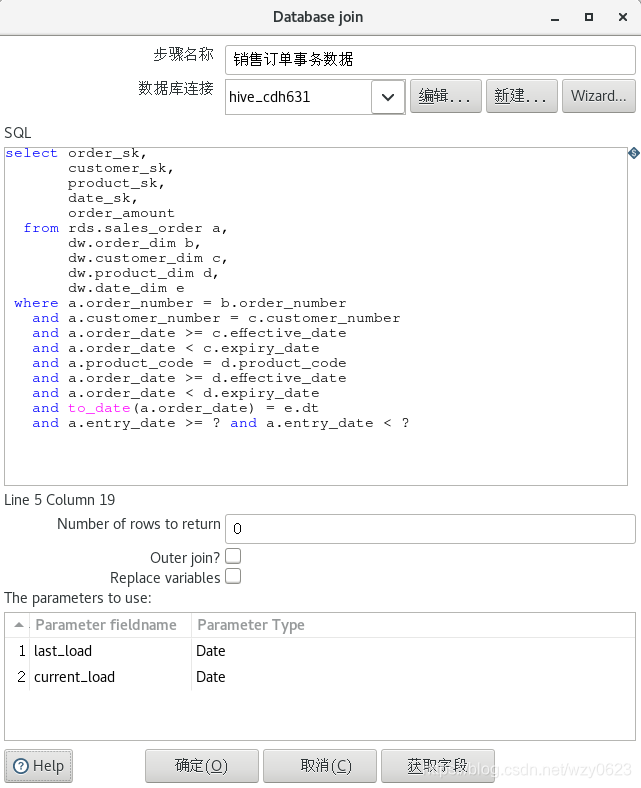
“ORC output”步骤定义如图6-24 所示,将事实表数据以文件形式存储到相应的 HDFS 目录中,文件名中带有日期。
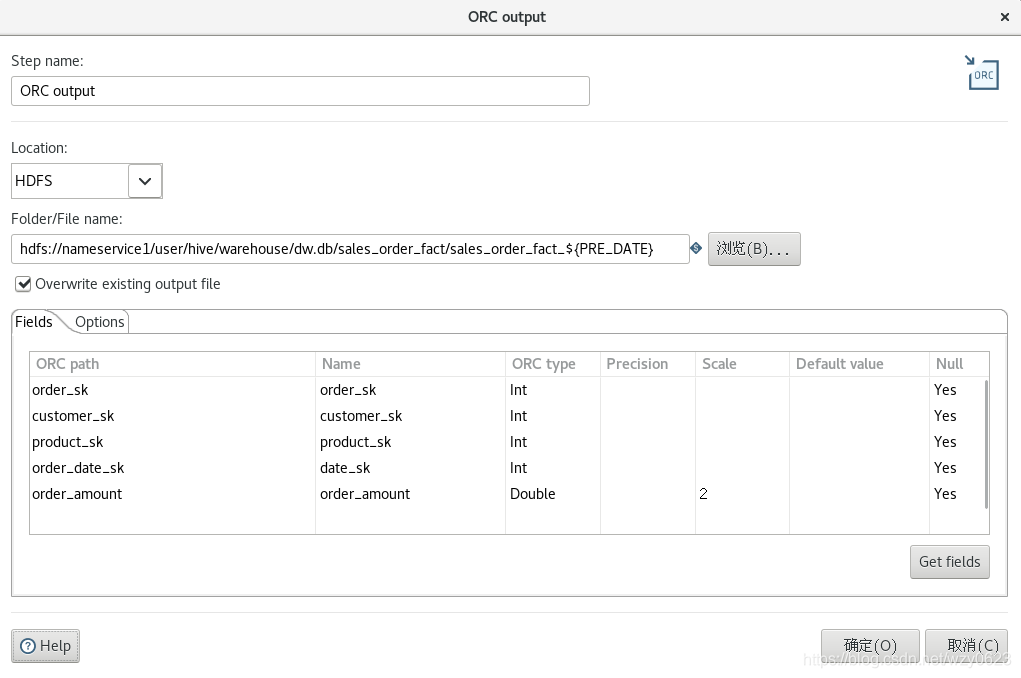
5. 设置时间戳表的最后装载日期
与初始装载一样,最后一个“SQL”作业项执行下面的语句,将最后装载日期更新为当前装载日期。
update rds.cdc_time set last_load=current_load;下面进行一些测试,验证数据装载的正确性。测试步骤:
(1)在 MySQL 的 source 源数据库中准备客户、产品和销售订单测试数据。
use source;
/*** 客户数据的改变如下:
客户 6 的街道号改为 7777 ritter rd。(原来是 7070 ritter rd)
客户 7 的姓名改为 distinguished agencies。(原来是 distinguished partners)
新增第八个客户。
***/
update customer set customer_street_address = '7777 ritter rd.' where customer_number = 6 ;
update customer set customer_name = 'distinguished agencies' where customer_number = 7 ;
insert into customer (customer_name, customer_street_address, customer_zip_code, customer_city, customer_state)
values ('subsidiaries', '10000 wetline blvd.', 17055, 'pittsburgh', 'pa') ;
/*** 产品数据的改变如下:
产品 3 的名称改为 flat panel。(原来是 lcd panel)
新增第四个产品。
***/
update product set product_name = 'flat panel' where product_code = 3 ;
insert into product (product_name, product_category)
values ('keyboard', 'peripheral') ;
/*** 新增订单日期为 2020 年 10 月 7 日的 16 条订单。 ***/
drop table if exists temp_sales_order_data;
create table temp_sales_order_data as select * from sales_order where 1=0;
set @start_date := unix_timestamp('2020-10-07');
set @end_date := unix_timestamp('2020-10-08');
set @customer_number := floor(1 + rand() * 8);
set @product_code := floor(1 + rand() * 4);
set @order_date := from_unixtime(@start_date + rand() * (@end_date - @start_date));
set @amount := floor(1000 + rand() * 9000);
insert into temp_sales_order_data values (1,@customer_number,@product_code,@order_date,@order_date,@amount);
... 插入 16 条数据 ...
insert into sales_order
select @a:=@a+1, customer_number, product_code, order_date, entry_date, order_amount
from temp_sales_order_data t1,(select @a:=102) t2 order by order_date;
commit ; (2)执行定期装载 Kettle 作业。
(3)验证结果。
use dw;
select * from customer_dim; 查询的部分结果如下:
...
6 6 loyal clients 7070 ritter rd. 17055 pittsburgh pa 1 2020-03-01 2020-10-07
8 6 loyal clients 7777 ritter rd. 17055 pittsburgh pa 2 2020-10-07 2200-01-01
7 7 distinguished agencies 9999 scott st. 17050 mechanicsburg pa 1 2020-03-01 2200-01-01
9 8 subsidiaries 10000 wetline blvd. 17055 pittsburgh pa 1 2020-10-07 2200-01-01可以看到,客户 6 因为地址变更新增了一个版本,而客户 7 的姓名变更直接覆盖了原来的值,新增了客户 8。注意客户 6 第一个版本的到期日期和第二个版本的生效日期同为‘2020-10-07’,这是因为任何一个 SCD 的有效期是一个“左闭右开”的区间,以客户 6 为例,其第一个版本的有效期大于等于‘2020-03-01’,小于‘2020-10-07’,即为‘2020-03-01’到‘2020-10-06’。
select * from product_dim;查询的部分结果如下:
...
3 3 lcd panel monitor 1 2020-03-01 2020-10-07
4 3 flat panel monitor 2 2020-10-07 2200-01-01
5 4 keyboard peripheral 1 2020-10-07 2200-01-01可以看到,产品 3 的名称变更使用 SCD2 增加了一个版本,新增了产品 4 的记录。
select * from order_dim;查询的部分结果如下:
...
111 111 1 2020-10-07 2200-01-01
112 112 1 2020-10-07 2200-01-01
113 113 1 2020-10-07 2200-01-01
114 114 1 2020-10-07 2200-01-01
115 115 1 2020-10-07 2200-01-01
116 116 1 2020-10-07 2200-01-01
117 117 1 2020-10-07 2200-01-01
118 118 1 2020-10-07 2200-01-01
Time taken: 0.146 seconds, Fetched: 118 row(s)现在有 118 个订单,102 个是“初始导入”装载的,16 个是本次定期装载的。
select * from sales_order_fact;查询的部分结果如下:
...
110 8 5 1011 7791.00
111 3 1 1011 6711.00
112 7 1 1011 5570.00
113 1 2 1011 4722.00
114 1 5 1011 7330.00
115 3 1 1011 7214.00
116 9 4 1011 9160.00
117 9 5 1011 8382.00
118 3 1 1011 4956.00
Time taken: 0.135 seconds, Fetched: 118 row(s)可以看到,2020 年 10 月 7 日的 16 个销售订单被添加,产品3的代理键是 4 而不是 3,客户 6 的代理键是 8 而不是 6。
select * from rds.cdc_time;查询结果如下:
1 2020-10-08 2020-10-08
Time taken: 0.117 seconds, Fetched: 1 row(s)可以看到,两个字段值都已更新为当前日期。
查看销售订单过渡区表和事实表所对应的的 HDFS 文件如下,不带日期的文件是初始装载作业所生成,带日期的文件为定期装载作业所生成。
[hdfs@manager~]$hdfs dfs -ls /user/hive/warehouse/rds.db/sales_order/*
-rw-r--r-- 3 root hive 6012 2020-10-08 20:28 /user/hive/warehouse/rds.db/sales_order/sales_order.txt
-rw-r--r-- 3 root hive 960 2020-10-08 20:39 /user/hive/warehouse/rds.db/sales_order/sales_order_2020-10-07.txt
[hdfs@manager~]$hdfs dfs -ls /user/hive/warehouse/dw.db/sales_order_fact/*
-rw-r--r-- 3 root hive 1625 2020-10-08 20:31 /user/hive/warehouse/dw.db/sales_order_fact/sales_order_fact
-rw-r--r-- 3 root hive 770 2020-10-08 21:06 /user/hive/warehouse/dw.db/sales_order_fact/sales_order_fact_2020-10-07
[hdfs@manager~]$以上示例说明了如何用 Kettle 实现 Hadoop 数据仓库的初始装载和定期装载。需要指出的一点是,就本示例的环境和数据量而言装载执行速度很慢,一次定期装载就需要二十多分钟,比关系数据库慢多了。但考虑到 Hadoop 本身就只适合大数据量的批处理任务,再加上 Hive 的性能问题一直就被诟病,也就不必再吐槽了。至此,ETL 过程已经实现,下一篇将介绍如何定期自动执行这个过程。
五、小结
数据清洗是转换过程的一个重要步骤,是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。Hive 是 Hadoop 生态圈的数据仓库软件,使用类似于 SQL 的语言读、写、管理分布式存储上的大数据集。使用 row_number() 窗口函数或者使用一个名为 UDFRowSequence 的用户自定义函数可以生成代理键。Kettle 作业和转换能够实现 Hadoop 数据仓库的初始装载和定期装载。

















 3748
3748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









