








一、广义线性模型简介
在一些实际问题中,变量间的关系并不都是线性的,这种情况就应该用曲线去进行拟合。用曲线拟合数据首先要解决的问题是回归方程中的参数如何估计。下面以一元非线性回归为例,讨论解决这一问题的基本思路。
对于曲线回归建模的非线性目标函数

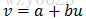


比如,对于指数函数
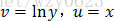
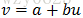
广义线性模型是一般线性模型的直接扩展,它使因变量的总体均值通过一个非线性连接函数(link function,如上例中的ln),而依赖于线性预测值,同时还允许响应概率分布为指数分布族中的任何一员。
广义线性模型在两个方面对普通线性模型进行了扩展:
- 一般线性模型中要求因变量是连续的且服从正态分布。在广义线性模型中,因变量的分布可扩展到非连续的,如二项分布、泊松分布、负二项分布等。
- 一般线性模型中,自变量的线性预测值就是因变量的估计值,而广义线性模型中,自变量的线性预测值是因变量的连接函数估计值。
一个广义线性模型包括以下三个组成部分:
- 线性成分(linear component):
- 随机成分(random component):
- 连接函数(link function):
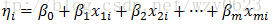


MADlib1.10.0实现的分布族及其相应的连接函数如表1所示。
分布族 | 连接函数 |
二项分布(Binomial) | logit, probit |
伽马分布(Gamma) | inverse, identity, log |
高斯分布(Gaussian) | identity, inverse, log |
逆高斯分布(Inverse Gaussian) | inverse of square, inverse, identity, log |
泊松分布(Poisson) | log, identity, square-root |
表1 MADlib 1.10.0支持的连接函数
二、MADlib广义线性模型相关函数
1. 培训函数
(1) 语法
glm(source_table,
model_table,
dependent_varname,
independent_varname,
family_params,
grouping_col,
optim_params,
verbose
)(2) 参数
参数名称 | 数据类型 | 描述 |
source_table | VARCHAR | 包含训练数据的源表名。 |
model_table | VARCHAR | 包含模型的输出表名。主输出表列和概要输出表列如表3、4所示。 |
dependent_varname | VARCHAR | 训练数据中因变量列的名称。 |
independent_varname | VARCHAR | 评估使用的自变量的表达式列表,一般显式地由包括一个常数1项的自变量列表提供。 |
family_params(可选) | VARCHAR | 当前支持如下分布族参数: family=poisson并且link=[log|identity|sqrt]。 family=gaussian并且link=[identity|log|inverse]。当family=gaussian并且link=identity时,GLM模型等同于线性回归。 family=gamma并且link=[inverse|identity|log]。 family=inverse_gaussian并且link=[sqr_inverse|log|identity|inverse]。 family=binomial并且link=[probit|logit]。 |
grouping_col(可选) | VARCHAR | 缺省值为NULL。和SQL中的“GROUP BY”类似,是一个将输入数据集分成离散组的表达式,每个组运行一个回归。此值为NULL时,将不使用分组,并产生一个单一的结果模型。 |
optim_params(可选) | VARCHAR | 优化相关参数,缺省值为‘max_iter=100,optimizer=irls,tolerance=1e-6’。 |
verbose(可选) | BOOLEAN | 缺省值为FALSE,指定是否输出训练结果的详细信息。 |
表2 glm函数参数说明
列名 | 数据类型 | 描述 |
<...> | TEXT | 分组列,取决于grouping_col输入,可能是多个列。 |
coef | FLOAT8[] | 线性预测的回归系数向量。 |
log_likelihood | FLOAT8 | 对数似然值l(β)。训练函数使用离散度参数的极大似然估算值计算对数似然值。 |
std_err | FLOAT8[] | 系数的标准方差向量。 |
z_stat或t_stats | FLOAT8[] | 系数的z-统计量向量(泊松分布或二项分布)或t-统计量向量(其它分布)。 |
p_values | FLOAT8[] | 系数的P值向量。 |
dispersion | FLOAT8 | Pearson估计的离散度。当family=poisson或family=binomial时,离散度总是1。 |
num_rows_processed | BIGINT | 处理的数据行数。 |
num_missing_rows_skipped | BIGINT | 训练时由于缺少值或失败跳过的行数。 |
num_iterations | INTEGER | 实际完成的迭代次数。 |
表3 glm函数主输出表列说明
训练函数在产生输出表的同时,还会创建一个名为<out_table>_summary的概要表,具有以下列:
列名 | 数据类型 | 描述 |
Method | VARCHAR | 'glm' |
source_table | VARCHAR | 源数据表名称。 |
model_table | VARCHAR | 模型表名。 |
dependent_varname | VARCHAR | 因变量名。 |
independent_varname | VARCHAR | 自变量名。 |
family_params | TEXT | 分布族相关参数,形式为'family=..., link=...' |
grouping_col | TEXT | 分组列名称。 |
optimizer_params | TEXT | 包含优化参数的字符串,形式为'optimizer=..., max_iter=..., tolerance=...'。 |
num_all_groups | INTEGER | 分组数。 |
num_failed_groups | INTEGER | 失败的分组数。 |
total_rows_processed | BIGINT | 所有分组处理的总行数。 |
total_rows_skipped | BIGINT | 由于缺失值或失败跳过的总行数。 |
表4 glm函数概要输出表列说明
2. 预测函数
(1) 语法
glm_predict(coef,
col_ind_var
link)(2) 参数
- coef:FLOAT8[]类型,训练模型获得的回归系数向量。
- col_ind_var:FLOAT8[]类型,包含自变量列名索引的数组,应该与训练函数中‘independent_varname’参数得到的数组具有相同的数组长度。
- link:TEXT类型,连接函数字符串,应该与训练函数使用相同的连接函数。
三、示例
1. 问题提出
为了了解百货商店销售额x与流通率(这是反映商业活动的一个质量指标,指每元商品流转额所分摊的流通费用)y之间的关系,收集了九个商店的有关数据(见表5)。假设数据服从伽马分布,请建立销售额与流通率之间的回归模型。
样本点 | x-销售额(万元) | y-流通费率(%) |
1 | 1.5 | 7.0 |
2 | 4.5 | 4.8 |
3 | 7.5 | 3.6 |
4 | 10.5 | 3.1 |
5 | 13.5 | 2.7 |
6 | 16.5 | 2.5 |
7 | 19.5 | 2.4 |
8 | 22.5 | 2.3 |
9 | 25.5 | 2.2 |
表5 销售额与流通费率数据
2. 建立表并添加数据
drop table if exists t1;
create table t1 (x float, y float);
insert into t1 values
(1.5,7.0), (4.5,4.8), (7.5,3.6), (10.5,3.1), (13.5,2.7),
(16.5,2.5), (19.5,2.4), (22.5,2.3), (25.5,2.2);
3. 使用identity连接函数
(1) 训练生成模型
drop table if exists t1_glm, t1_glm_summary;
select madlib.glm( 't1',
't1_glm',
'y',
'array[1, x]',
'family=gamma, link=identity'
); (2) 查询结果
\x on
select * from t1_glm; 结果:
-[ RECORD 1 ]------+-------------------------------------------
coef | {5.032482978893,-0.124291210170803}
log_likelihood | -8.09384975775831
std_err | {0.594336150129185,0.0304615709894519}
t_stats | {8.46740178567152,-4.08026264350718}
p_values | {6.33195030885822e-05,0.00468813243359916}
dispersion | 0.0500321476619188
num_rows_processed | 9
num_rows_skipped | 0
num_iterations | 11(3) 利用预测函数估计残差
\x off
select x,y,predict,y-predict residual
from (select t1.*,
madlib.glm_predict(coef,array[1, x]::float8[],'identity') as predict
from t1, t1_glm m) t; x | y | predict | residual
------+-----+------------------+--------------------
1.5 | 7 | 4.84604616363679 | 2.15395383636321
4.5 | 4.8 | 4.47317253312439 | 0.326827466875614
7.5 | 3.6 | 4.10029890261198 | -0.500298902611978
10.5 | 3.1 | 3.72742527209957 | -0.62742527209957
13.5 | 2.7 | 3.35455164158716 | -0.654551641587162
16.5 | 2.5 | 2.98167801107475 | -0.481678011074754
19.5 | 2.4 | 2.60880438056235 | -0.208804380562346
22.5 | 2.3 | 2.23593075004994 | 0.0640692499500619
25.5 | 2.2 | 1.86305711953753 | 0.33694288046247
(9 rows)
4. 使用inverse连接函数
(1) 训练生成模型
drop table if exists t1_glm, t1_glm_summary;
select madlib.glm( 't1',
't1_glm',
'y',
'array[1, x]',
'family=gamma, link=inverse'
); (2) 查询结果
\x on
select * from t1_glm;结果:
-[ RECORD 1 ]------+--------------------------------------------
coef | {0.137708424903124,0.0147719820924827}
log_likelihood | -1.12823356728084
std_err | {0.0137829792192191,0.0013221473412605}
t_stats | {9.9911944081801,11.1727200376923}
p_values | {2.15188055884168e-05,1.02542310032808e-05}
dispersion | 0.00982968278042609
num_rows_processed | 9
num_rows_skipped | 0
num_iterations | 6(3) 利用预测函数估计残差
\x off
select x,y,predict,y-predict residual
from (select t1.*,
madlib.glm_predict(coef,array[1, x]::float8[],'inverse') as predict
from t1, t1_glm m) t; 结果:
x | y | predict | residual
------+-----+------------------+---------------------
1.5 | 7 | 6.25522318791614 | 0.744776812083859
4.5 | 4.8 | 4.89758310560006 | -0.0975831056000596
7.5 | 3.6 | 4.02417255104088 | -0.424172551040882
10.5 | 3.1 | 3.41513449166629 | -0.315134491666294
13.5 | 2.7 | 2.9662132018307 | -0.266213201830703
16.5 | 2.5 | 2.62160216829753 | -0.121602168297529
19.5 | 2.4 | 2.34872962402895 | 0.0512703759710513
22.5 | 2.3 | 2.12730643262039 | 0.172693567379613
25.5 | 2.2 | 1.94403523699905 | 0.255964763000946
(9 rows)5. 使用log连接函数
(1) 训练生成模型
drop table if exists t1_glm, t1_glm_summary;
select madlib.glm( 't1',
't1_glm',
'y',
'array[1, x]',
'family=gamma, link=log'
);(2) 查询结果
\x on
select * from t1_glm; 结果:
-[ RECORD 1 ]------+--------------------------------------------
coef | {1.75614873826444,-0.0442718284575659}
log_likelihood | -5.67230519309458
std_err | {0.111953106344754,0.00719290385898647}
t_stats | {15.6864672683264,-6.15493121074527}
p_values | {1.03559068682089e-06,0.000465286458020498}
dispersion | 0.0279384475992961
num_rows_processed | 9
num_rows_skipped | 0
num_iterations | 7(3) 利用预测函数估计残差
\x off
select x,y,predict,y-predict residual
from (select t1.*,
madlib.glm_predict(coef,array[1, x]::float8[],'log') as predict
from t1, t1_glm m) t; 结果:
x | y | predict | residual
------+-----+------------------+---------------------
1.5 | 7 | 5.41807721742676 | 1.58192278257324
4.5 | 4.8 | 4.7442127661024 | 0.0557872338976022
7.5 | 3.6 | 4.15415909866612 | -0.55415909866612
10.5 | 3.1 | 3.63749238658367 | -0.537492386583666
13.5 | 2.7 | 3.18508524786705 | -0.485085247867048
16.5 | 2.5 | 2.78894550366558 | -0.288945503665581
19.5 | 2.4 | 2.44207498924096 | -0.0420749892409602
22.5 | 2.3 | 2.13834592509533 | 0.161654074904671
25.5 | 2.2 | 1.87239266423715 | 0.327607335762848
(9 rows)从自变量x的标准差、t统计值和P值来看,在符合伽马分布的假设下,inverse连接函数的拟合程度最高,其次是log连接函数,而误差最大的是identity连接函数。与madlib.linregr_train线性回归训练函数不同,madlib.glm不返回R2决定系数,而是用对数似然值评估模型的拟合程度。统计学中,似然函数是一种关于统计模型参数的函数。给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率:L(θ|x)=P(X=x|θ)。涉及到似然函数的许多应用中,更方便的是使用似然函数的自然对数形式,即“对数似然函数”。求解一个函数的极大化往往需要求解该函数的关于未知参数的偏导数。由于对数函数是单调递增的,而且对数似然函数在极大化求解时较为方便,所以对数似然函数常用在最大似然估计及相关领域中。
在该例子中,伽马分布的三种连接函数identity、inverse和log对应的似然函数值分别为-8.0938、-1.1282和-5.6723。对数似然函数绝对值越小,表示拟合程度越好。因此从结果来看,可以认为inverse连接函数形式更符合因变量与自变量之间的关系。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









