








相对于开源的Apache HAWQ,OushuDB的增强主要体现在以下方面:
- 采用全新执行引擎,充分利用硬件的所有特性,比Apache HAWQ性能高出5-10倍。
- 替换JAVA PXF,性能高数倍,无需安装部署PXF额外组件,极大简化了用户安装部署和运维。
- 原生支持CSV/TEXT外部存储。
- 可以实现可插拔文件系统:比如S3, Ceph等。
- 可以实现可插拔文件格式:比如ORC,Parquet等。
- 支持ORC/TEXT/CSV作为内部表格式,支持ORC作为外部表格式(通过C++可插拔外部存储)。
- CSV和TEXT文件格式中对非ASCII字符串或长度大于1的字符串作为分隔符的支持。
- 关键Bug fixes。
一、安装规划
1. 选择安装方式
目前OushuDB的最新版本是3.1.1,支持的操作系统为Redhat/Centos 7.0及以上版本,注意这是对操作系统的强制性要求。OushuDB官方文档提供了两种安装方式,手工安装和使用Ambari部署集群。本次安装选择使用Ambari进行安装部署最新的OushuDB 3.1.1。手工安装的步骤较多,具体可以参考 http://www.oushu.io/docs/ch/installation.html。2. 确认Ambari与HDP的版本兼容性
与HAWQ类似,OushuDB官方验证支持的Hadoop平台是Hortonworks Data Platform(HDP),其3.1.1版本支持的Ambari与HDP版本分别是Ambari 2.4.2和HDP 2.5.3。3. 确认最小系统需求
这里可以参考HAWQ的安装文档确认对软硬件的最小系统需求。- 操作系统:CentOS 7.0+
- 浏览器:Google Chrome 26及以上
- 依赖软件包:yum、rpm、scp、curl、unzip、tar、wget、OpenSSL (v1.01, build 16 or later)、Python 2.6.x、OpenJDK 7/8 64-bit
- 系统内存与磁盘:Ambari主机至少应该有1G内存和500M剩余磁盘空间。如果要使用Ambari Metrics,所需内存和磁盘依据集群规模,如表1所示。
节点数 | 可用内存(MB) | 磁盘空间(GB) |
1 | 1024 | 10 |
10 | 1024 | 20 |
50 | 2048 | 50 |
100 | 4096 | 100 |
300 | 4096 | 100 |
500 | 8096 | 200 |
1000 | 12288 | 200 |
- 最大打开文件描述符:推荐值大于10000。
4. 确认安装环境
主机信息如表2所示,所有主机都能连接互联网。主机名 | IP |
hdp1 | 172.16.1.124 |
hdp2 | 172.16.1.125 |
hdp3 | 172.16.1.126 |
hdp4 | 172.16.1.127 |
硬件配置:每台主机CPU4核、内存8G、硬盘100G;软件版本如表3所示。
名称 | 版本 |
操作系统 | CentOS Linux release 7.2.1511 (Core) |
JDK | openjdk version "1.8.0_65" |
数据库 | MySQL 5.6.14 |
JDBC | MySQL Connector Java 5.1.38 |
HDP | 2.5.3 |
Ambari | 2.4.2 |
二、安装前准备
整个OushuDB的安装部署过程包括安装Ambari、HDP、OushuDB三个依次进行的步骤,在实施这些步骤前需要做一些准备工作。如没做特殊说明,配置或命令都用root用户在全部四台主机上执行。(安装CentOS 7.2操作系统过程从略)1. 安装JDK
# 查看JDK软件包列表
yum search java | grep -i --color JDK
# 安装JDK,如果没有java-1.8.0-openjdk-devel.x86_64就没有javac命令
yum install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64 -y 2. 配置环境
(1)设置最大打开文件描述符# 查看当前值
ulimit -Sn
ulimit -Hn
# 如果小于10000,使用下面的命令设置成10000
ulimit -n 10000在安装期间Ambari需要与部署集群主机通信,因此特定的端口必须打开。最简单的实现方式是执行下面的命令禁用防火墙:
systemctl stop firewalld.service
systemctl disable firewalld.serviceAmbari安装需要禁用SELinux:
setenforce 0
# 编辑/etc/selinux/config文件,设置
SELINUX=disabled 编辑/etc/hosts文件,添加如下四行:
172.16.1.124 hdp1
172.16.1.125 hdp2
172.16.1.126 hdp3
172.16.1.127 hdp4 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6hostname hdp1
# 编辑/etc/sysconfig/network文件,设置如下两行:
NETWORKING=yes
HOSTNAME=hdp1(5)安装配置NTP
yum install ntp -y
systemctl enable ntpd.service
systemctl start ntpd.service 为了使得Ambari Server在集群所有主机上自动安装Ambari Agents,必须配置Ambari Server主机到集群其它主机的SSH免密码连接。以下配置用于在hdp1上运行Ambari Server,在所有四台主机上运行Ambari Agents的情况。
在hdp1上执行以下命令:
ssh-keygen
... 一路回车 ...
ssh-copy-id hdp1
ssh-copy-id hdp2
ssh-copy-id hdp3
ssh-copy-id hdp4 chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys tar -zxvf mysql-connector-java-5.1.38.tar.gz
cp ./mysql-connector-java-5.1.38/mysql-connector-java-5.1.38-bin.jar /usr/share/java/mysql-connector-java.jar 在hdp1、hdp2上安装MySQL,hdp1上的MySQL用于Ambari,hdp2上的MySQL用于Hive、Oozie等Hadoop组件。在hdp1、hdp2上执行以下命令。
rpm -ivh MySQL-5.6.14-1.el6.x86_64.rpm
systemctl start mysql# /home/mysql/mysql-5.6.14/bin/mysql -u root -p
delete from mysql.user where user='';
create database hive;
create database oozie;
create user 'hive'@'%' identified by 'hive';
grant all privileges on hive.* to 'hive'@'%';
create user 'oozie'@'%' identified by 'oozie';
grant all privileges on oozie.* to 'oozie'@'%';
flush privileges;
exit;3. 建立本地Repository
联机安装过程中需要从远程的Repository中yum下载所需要的包,为了防止由于网络不稳定或远程Repository不可用等原因导致的安装失败,最好配置本地Repository。安装HDP时使用本地Repository,能大大加快安装速度。(1)下载 Ambari HDP HDP-UTILS 源包到hdp1
wget -P ~ http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.4.2.0/ambari-2.4.2.0-centos7.tar.gz
wget -P ~ http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.5.3.0/HDP-2.5.3.0-centos7-rpm.tar.gz
wget -P ~ http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos7/HDP-UTILS-1.1.0.21-centos7.tar.gz yum install httpd -y
mkdir -p /var/www/html/HDP-UTILS
tar -zxvf ~/ambari-2.4.2.0-centos7.tar.gz -C /var/www/html
tar -zxvf ~/HDP-2.5.3.0-centos7-rpm.tar.gz -C /var/www/html
tar -zxvf ~/HDP-UTILS-1.1.0.21-centos7.tar.gz -C /var/www/html/HDP-UTILS
systemctl enable httpd && systemctl start httpd links 172.16.1.124/AMBARI-2.4.2.0
links 172.16.1.124/HDP
links 172.16.1.124/HDP-UTILSyum install yum-utils createrepo -y新建/etc/yum.repos.d/ambari.repo文件,添加如下行:
#VERSION_NUMBER=2.4.2.0-136
[Updates-ambari-2.4.2.0]
name=ambari-2.4.2.0 - Updates
baseurl=http://172.16.1.124/AMBARI-2.4.2.0/centos7/2.4.2.0-136
gpgcheck=1
gpgkey=http://172.16.1.124/AMBARI-2.4.2.0/centos7/2.4.2.0-136/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1#VERSION_NUMBER=2.5.3.0
[HDP-2.5]
name=HDP Version - HDP-2.5.3.0
baseurl=http://172.16.1.124/HDP/centos7
gpgcheck=1
gpgkey=http://172.16.1.124/HDP/centos7/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
[HDP-UTILS-1.1.0.21]
name=HDP Utils Version - HDP-UTILS-1.1.0.21
baseurl=http://172.16.1.124/HDP-UTILS
gpgcheck=1
gpgkey=http://172.16.1.124/HDP-UTILS/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1scp -r /etc/yum.repos.d/* root@hdp2:/etc/yum.repos.d/
scp -r /etc/yum.repos.d/* root@hdp3:/etc/yum.repos.d/
scp -r /etc/yum.repos.d/* root@hdp4:/etc/yum.repos.d/ yum clean all
yum makecache
yum repolist三、安装Ambari
Ambari是Apache Software Foundation中的一个顶级项目,目前最新的发布版本是 2.6.1。就Ambari的作用来说,就是创建、管理、监视Hadoop的集群。这里的Hadoop是广义的,指的是Hadoop整个生态圈(例如 Hive、Hbase、Sqoop、Zookeeper等等),而并不仅是特指Hadoop。用一句话来说,Ambari就是让Hadoop 以及相关的大数据软件更容易使用的一个工具。Ambari主要具有以下功能特性:
- 通过一步一步的安装向导简化了集群部署。
- 预先配置好关键的运维指标(metrics),可以直接查看Hadoop Core(HDFS和MapReduce)及相关项目(如HBase、Hive和HCatalog)是否健康。
- 支持作业与任务执行的可视化与分析,能够更好地查看依赖和性能。
- 通过一个完整的RESTful API把监控信息暴露出来,可集成现有的运维工具。
- 用户界面非常直观,用户可以轻松有效地查看信息并控制集群。
Ambari自身也是一个分布式架构的软件,主要由两部分组成:Ambari Server和Ambari Agent。简单来说,用户通过Ambari Server通知Ambari Agent安装对应的软件,Agent会定时地发送各个机器每个软件模块的状态给Ambari Server,最终这些状态信息会呈现在Ambari的 GUI,方便用户了解到集群的各种状态,并进行相应的维护。下面说明Ambari的安装步骤。
1. 安装ambari-server
在hdp1上执行以下命令:yum install ambari-server -y2. 为Ambari配置MySQL数据库
(1)在hdp1上的MySQL中建立Ambari数据库用户并授权# /home/mysql/mysql-5.6.14/bin/mysql -u root -p
delete from mysql.user where user='';
create user 'ambari'@'%' identified by 'ambari';
grant all privileges on *.* to 'ambari'@'%';
flush privileges;
exit;# /home/mysql/mysql-5.6.14/bin/mysql -u ambari -p
create database ambari;
use ambari;
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql;
exit;3. 配置Ambari Server
启动Ambari Server前必须进行配置,指定Ambari使用的数据库、安装JDK、定制运行Ambari Server守护进程的用户等。在hdp1上执行下面的命令管理配置过程。ambari-server setup - Customize user account for ambari-server daemon 提示时输入n,使用root用户运行Ambari Server。
- Checking JDK... 提示时选择3。
- Path to JAVA_HOME 提示时输入 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
- Enter advanced database configuration 提示时输入y。
- Choose one of the following options 提示时选择Option [3] MySQL/MariaDB,然后根据提示输入连接MySQL的用户名、密码和数据库名,这里均为ambari。
4. 启动Ambari Server
在hdp1上执行下面的命令启动Ambari Server:ambari-server start
# 查看Ambari Server进程状态
ambari-server status Using python /usr/bin/python
Ambari-server status
Ambari Server running
Found Ambari Server PID: 31100 at: /var/run/ambari-server/ambari-server.pid四、安装、配置、部署HDP集群
Hortonworks Data Platform是Hortonworks公司开发的Hadoop数据平台。Hortonworks由Yahoo的工程师创建,它为Hadoop提供了一种“service only”的分发模型。有别于其它商业化的Hadoop版本,Hortonworks是一个可以自由使用的开放式企业级数据平台。其Hadoop发行版本即HDP,可以被自由下载并整合到各种应用当中。Hortonworks是第一个提供基于Hadoop 2.0版产品的厂商,也是目前唯一支持Window平台的Hadoop分发版本。用户可以通过HDInsight服务,在Windows Azure上部署Hadoop集群。HDP的特性如下:
- HDP通过其新的Stinger项目,使Hive的执行速度更快。
- HDP承诺是一个Apache Hadoop的分支版本,对专有代码的依赖极低,避免了厂商锁定。
- 专注于提升Hadoop平台的可用性。
1. 在浏览器中登录Ambari
http://172.16.1.124:8080,初始的用户名/密码为admin/admin。在欢迎页面点击“Launching Install Wizard”,如图1所示。
2. 给集群命名
集群名称中不要有空格和特殊字符,然后点击“Next”。3. 选择HDP版本
选择2.5.3.0,如图2所示。
4. 选择Repositories
选择Use Local Repository,并输入对应的Base URL,如图3所示。然后点击“Next”。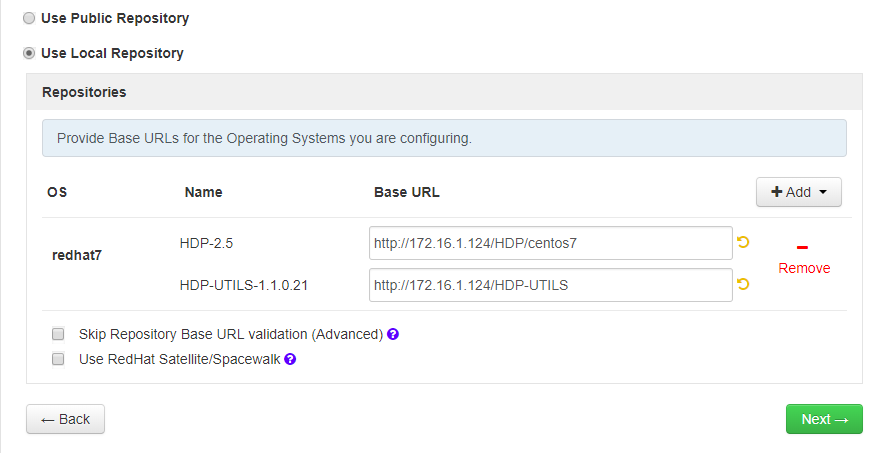
5. 安装选项
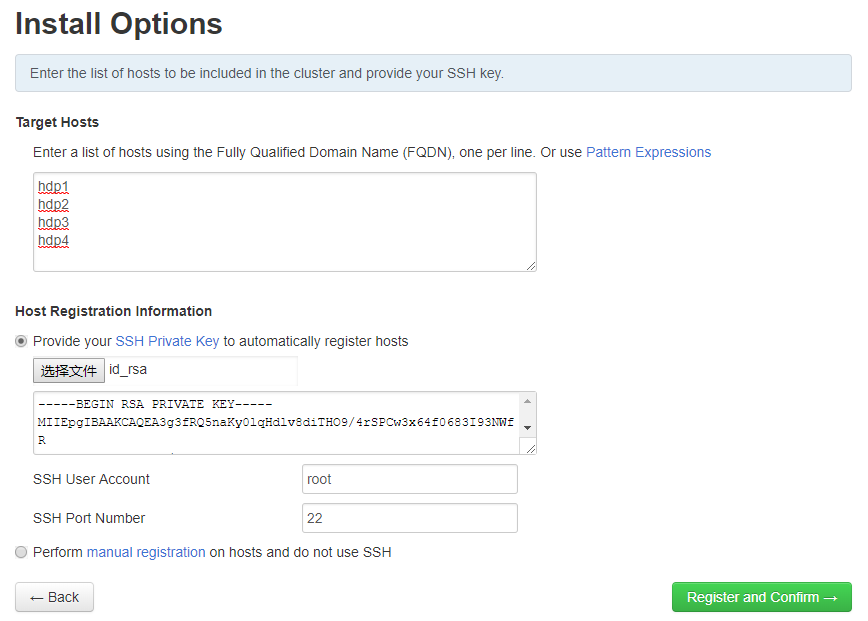
- Target Hosts编辑框中输入四个主机名,每个一行。
hdp1
hdp2
hdp3
hdp4 - 点击“Choose File”按钮,选择“安装前准备 -> 配置环境”第(6)步中hdp1上生成的私钥文件id_rsa。
- 用户名root,端口22
6. 确认主机
如图5所示。点击“Next”。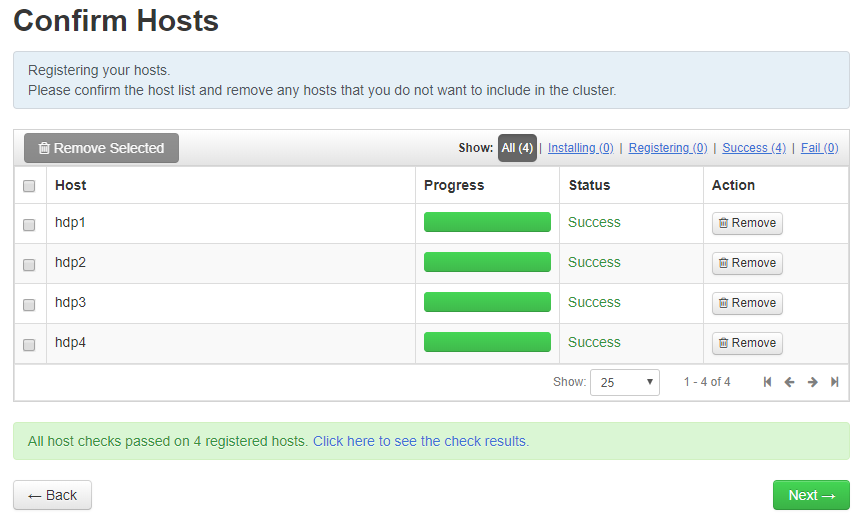
7. 选择服务
根据需要选择服务,这里使用缺省,然后点击“Next”。注意至少需要安装启动HDFS和Zookeeper这两个服务,它们是OushuDB所需要的。8. 标识Masters
根据需要选择Masters,这里使用缺省,然后点击“Next”。9. 标识Slaves和Clients
根据需要选择Slaves和Clients,这里使用缺省,然后点击“Next”。10. 定制服务
- 为hive和oozie配置MySQL数据库连接。
- 设置所需的密码。
- 其它保持缺省。
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar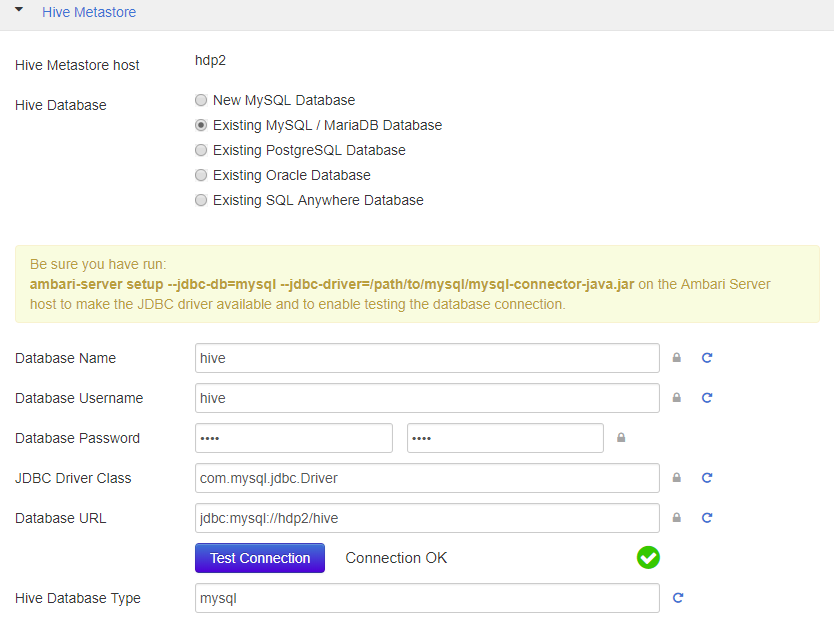
11. 复查确认
检查配置,然后点击“Deploy”。12. 安装、启动与测试
此时显示安装进度页面。Ambari对HDP的每个组件执行安装、启动和简单的测试。不要刷新浏览器,等待部署过程完全执行成功。当出现“Successfully installed and started the services”时,点击“Next”。13. 完成
汇总页面显示完成的任务列表。点击“Complete”,显示Ambari Web GUI主页面。至此,HDP安装完成。
HDP 2.5.3版本部署后,falcon的web ui警告无法访问,错误信息如下:
Falcon HTTP ERROR: 503 Problem accessing /index.html. - wget –O je-5.0.73.jar http://search.maven.org/remotecontent?filepath=com/sleepycat/je/5.0.73/je-5.0.73.jar
- mv remotecontent?filepath=com%2Fsleepycat%2Fje%2F5.0.73%2Fje-5.0.73.jar /usr/share/je-5.0.73.jar
- chmod 644 /usr/share/je-5.0.73.jar
- ambari-server setup --jdbc-db=bdb --jdbc-driver=/usr/share/je-5.0.73.jar
- ambari-server restart
- 重启falcon服务
五、使用Ambari安装部署OushuDB
1. 配置HDFS
登录Ambari,选择HDFS->Configs,做以下修改:- 选择Settings标签,修改DataNode max data transfer threads为40960。
- 选择Advanced标签,点开DataNode,设置DataNode directories permission为750。
- 点开General,设置Access time precision为0。
- 点开Advanced hdfs-site,设置表4所示属性的值,如果属性不存在,则选择Custom hdfs-site,点击Add property… 添加属性并设置表中所示的值。
Property | Setting |
dfs.allow.truncate | true |
dfs.block.access.token.enable | false for an unsecured HDFS cluster, or true for a secure cluster |
dfs.block.local-path-access.user | gpadmin |
HDFS Short-circuit read | true |
dfs.client.socket-timeout | 300000000 |
dfs.client.use.legacy.blockreader.local | false |
dfs.datanode.handler.count | 60 |
dfs.datanode.socket.write.timeout | 7200000 |
dfs.namenode.handler.count | 600 |
dfs.support.append | true |
dfs.datanode.max.transfer.threads | 40960 |
- 点开Advanced core-site,设置表5所示属性的值,如果属性不存在,则选择Custom core-site,点击Add property… 添加属性并设置表中所示的值。
Property | Setting |
ipc.client.connection.maxidletime | 3600000 |
ipc.client.connect.timeout | 300000 |
ipc.server.listen.queue.size | 3300 |
- 点击Save保存配置,然后重启相关服务。
2. 安装OushuDB插件
(1)在每台机器上下载hawq repo文件#Redhat/CentOS 7.0, 7.1, 7.2系统并且包含avx指令请配置以下YUM源:
wget -P /etc/yum.repos.d/ http://yum.oushu.io/oushurepo/oushudatabaserepo/centos7/3.1.1.0/oushu-database.repo
#Redhat/CentOS 7.0, 7.1, 7.2系统但不包含avx指令请配置以下YUM源:
wget -P /etc/yum.repos.d/ http://yum.oushu.io/oushurepo/oushudatabaserepo/centos7/3.1.1.0/oushu-database-noavx.repo
#Redhat/CentOS 7.3系统并且包含avx指令请配置以下YUM源:
wget -P /etc/yum.repos.d/ http://yum.oushu.io/oushurepo/oushudatabaserepo/centos7/3.1.1.0/oushu-database-cent73.repo
#Redhat/CentOS 7.3系统但不包含avx指令请配置以下YUM源:
wget -P /etc/yum.repos.d/ http://yum.oushu.io/oushurepo/oushudatabaserepo/centos7/3.1.1.0/oushu-database-cent73-noavx.reposudo yum install oushu-database-ambari-plugin -y
cd /var/lib/hawq/
sudo ./add-hawq.py --stack HDP-2.5 --hawqrepo http://yum.oushu.io/oushurepo/yumrepo/release/oushu-database/centos7/3.1.1.0/release/
# 用户名密码请输入ambari登录用户名密码,默认都为admin::
sudo ambari-server restart3. 安装部署OushuDB
- 在Ambari主页选择Actions > Add Service。
- 从服务列表选择HAWQ,点击Next,显示Assign Masters页。
- 选择HAWQ Master和HAWQ Standby Master的主机,或接受缺省值,点击Next显示Assign Slaves and Clients页。
- 选择运行HAWQ segments和PXF的主机,或接受缺省值,点击Next。Add Service助手会基于可用的Hadoop服务自动为HAWQ选择主机。注意,HAWQ segment必须安装在每个DataNode节点上。
- 在Customize Services页面点击Advanced标签,输入HAWQ系统用户口令,点击Next。
- 如弹出警告,点击“proceed anyway”按钮继续。
- 在Review页面点击Deploy进行部署,等待部署成功。
- 最后点击Complete。如果Ambari提示集群上的组件需要重启,选择Restart > Restart All Affected重启所有受影响的服务。
- 验证HAWQ安装。
# 设置HAWQ环境变量
source /usr/local/hawq/greenplum_path.sh
psql -d postgres
create database test;
\c test
create table t (i int);
insert into t select generate_series(1,100);
\timing
select count(*) from t; 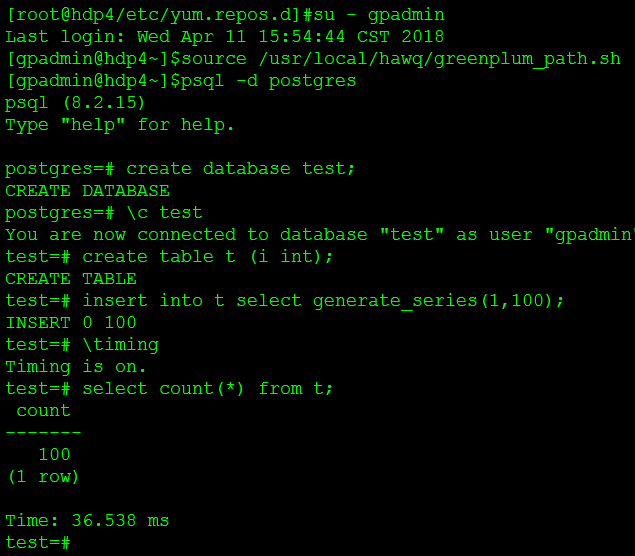
4. 排错
(1)部署成功后,Ambari中的HAWQ服务可能会出现如图8所示的一个警告信息,内容为“This alert is triggered when a HAWQ Segment node fails to register with the HAWQ Master.”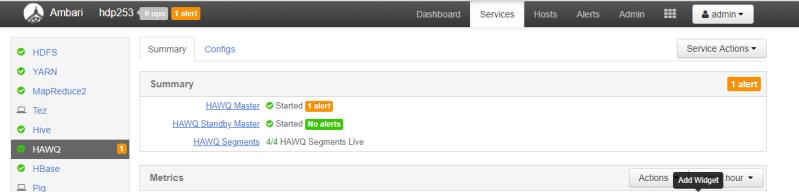
这表示在gp_segment_configuration表中具有up状态的HAWQ段与HAWQ主服务器上/usr/local/hawq/etc/slaves文件中列出的HAWQ段不匹配。解决的办法是将HAWQ主服务器上/usr/local/hawq/etc/slaves文件中的主机名改成IP地址即可,不需要重启等其它任何操作。
(2)在hawq state命令的输出或gp_segment_configuration表中显示没有standby,但ambari里显示standby正常。ambari中的显示如图9所示,hawq state命令的输出如图10所示,查询gp_segment_configuration表的结果如图11所示。

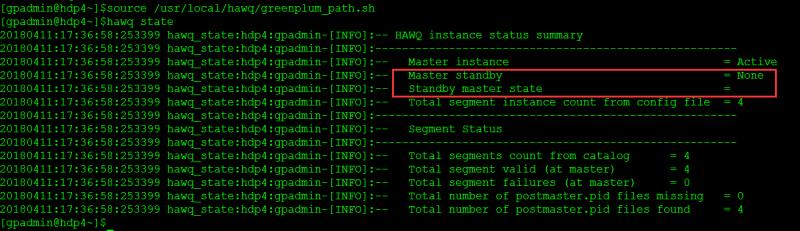
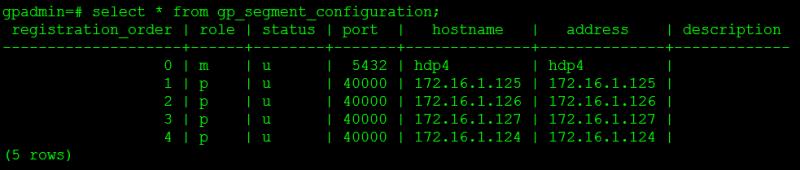
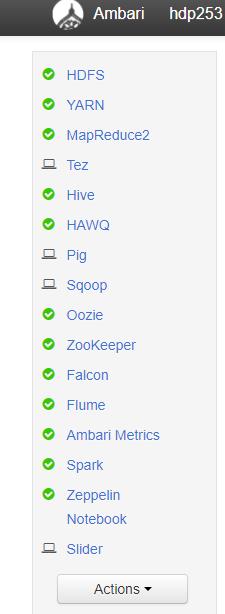
初步判断出现该问题的原因是OushuDB 3.1.1和某些HDP 2.5.3的服务存在冲突或兼容性问题,保留了如图12的部分服务后,重新部署OushuDB,问题解决,全部正常输出!
参考:
https://blog.csdn.net/wzy0623/article/details/55212318http://www.oushu.io/docs/ch/deployment.html















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









