







最近学习python 顺便写下爬虫练手
爬的是豆瓣电影排行榜 http://movie.douban.com/chart
python版本2.7.6
// 安装 Beautiful Soup
sudo apt-get install Python-bs4
// 安装 requests
sudo apt-get install Python-requests下面是py代码
__author__ = 'wzz'
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
r = requests.get('http://movie.douban.com/chart')
page_code = BeautifulSoup(r.text)
# 查找clss为indent里面的table标签
items = page_code.select('.indent table')
line = '-----------------------------------'
# 根据评分显示星星数量
def getStar(num):
str = ''
for i in range(0, 5):
# 等价于 num/2>i?'★':'☆'
str += '★'if int(float(num))/2>i else'☆'
return str
for item in items:
# 查找clss为pl2的div里面的a标签
name = item.select('div.pl2 a')[0]
# 删除span标签
name.span.unwrap()
# 去掉空格和换行
name = name.text.replace(' ', '').replace('\n', '')
actor = item.select('div.pl2 p.pl')[0]
actor = actor.text
score = item.select('span.rating_nums')[0]
score = score.text
num = item.select('span.pl')[0]
num = num.text
print '\n%s\n%s\n%s\n%s' %(name, line, actor, line)
# ★特殊字符不能用 %s 来输出 有没有知道的跟我说一下
print getStar(score), score, num
用面向对象改了下 加入时间
__author__ = 'wzz'
# -*- coding: utf-8 -*-
import requests
import time
from bs4 import BeautifulSoup
# 豆瓣电影爬虫
class doubanMove:
def __init__(self):
self.url = 'http://movie.douban.com/chart'
self.line = '-----------------------------------'
# 根据url获得页面并提取数组
def getPageItem(self):
r = requests.get(self.url)
page_code = BeautifulSoup(r.text)
items = page_code.select('.indent table')
return items
# 根据评分显示星星数量
def getStar(self, num):
str = ''
for i in range(0, 5):
# 等价于 num/2>i?'★':'☆'
str += '★'if int(float(num))/2>i else'☆'
return str
def start(self):
print '加载中...'
startTime = time.time()
items = self.getPageItem()
print '用时:', time.time()-startTime, '秒'
for item in items:
# 查找clss为pl2的div里面的a标签
name = item.select('div.pl2 a')[0]
# 删除span标签
name.span.unwrap()
# 去掉空格和换行
name = name.text.replace(' ', '').replace('\n', '')
actor = item.select('div.pl2 p.pl')[0]
actor = actor.text
score = item.select('span.rating_nums')[0]
score = score.text
num = item.select('span.pl')[0]
num = num.text
print '\n%s\n%s\n%s\n%s' %(name, self.line, actor, self.line)
# ★特殊字符不能用 %s 来输出 有没有知道的跟我说一下
print self.getStar(score), score, num
dbMove = doubanMove()
dbMove.start()效果图:
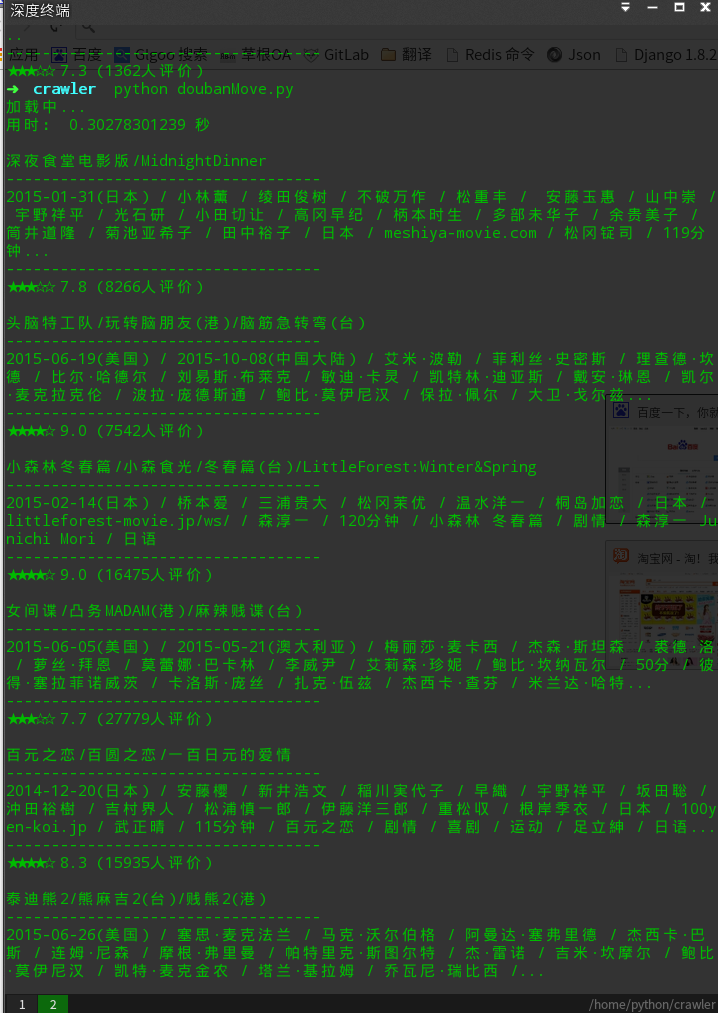
参考网站:
http://beautifulsoup.readthedocs.org/zh_CN/latest/
http://cuiqingcai.com/1319.html















 75万+
75万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









