







5.0 概述
本章介绍的工具使你能诊断应用程序与内存子系统之间的交互,该子系统由Linux内核和CPU管理。由于内存子系统的不同层次在性能上有数量级的差异,因此,修复应用程序使其有效地使用内存子系统会对程序性能产生巨大的影响。
阅读本章后,你将能够:
- 确定一个应用程序使用了多少内存(ps,/proc)。
- 确定应用程序的哪些函数分配内存(memprof)。
- 用软件模拟(kcachegrind,cachegrind)和硬件性能计数器(oprofile)分析应用程序
的内存使用情况。 - 确定哪些进程创建和使用了共享内存(ipcs)。
5.1Linux内存子系统
在诊断内存性能问题的时候,也许有必要观察应用程序在内存子系统的不同层次上是怎样执行的。在顶层,操作系统决定如何利用交换内存和物理内存。它决定应用程序的哪一块地址空间将被放到物理内存中,即所谓的驻留集。不属于驻留集却又被应用程序使用的其他内存将被交换到磁盘。由应用程序决定要向操作系统请求多少内存,即所谓的虚拟集。应用程序可以通过调用malloc进行显式分配,也可以通过使用大量的堆栈或库进行隐式分配。应用程序还可以分配被其自身或其他应用程序使用的共享内存。性能工具ps用于跟踪虚拟集和驻留集的大小。性能工具memprof用于跟踪应用程序的哪段代码是分配内存的。工具ipcs用于跟踪共享内存的使用情况。
当应用程序使用物理内存时,它首先与CPU的高速缓存子系统交互。现代CPU有多级高速缓存。最快的高速缓存离CPU最近(也称为L1或一级高速缓存),其容量也最小。举个例子,假设CPU只有两级高速缓存:L1和L2。当CPU请求一块内存时,处理器会检查看该块内存是否已经存在于L1高速缓存中。如果处于,CPU就可以使用。如果不在L1 高速缓存中,处理器产生一个L1高速缓存不命中。然后它会检查L2高速缓存,如果数据在L2高速缓存中,那么它可以使用。如果数据不在L2高速缓存,将产生一个L2高速缓存不命中,处理器就必须到物理内存去取回信息。最终,如果处理器从不访问物理内存(因为它会在L1或者甚至L2高速缓存中发现数据)将是最佳情况。明智地使用高速缓存,例如重新排列应用程序的数据结构以及减少代码量等方法,有可能减少高速缓存不命中的次数并提高性能。cachegrind和oprofile是很好的工具,用于发现应用程序对高速缓存的使用情况的信息,以及哪些函数和数据结构导致了高速缓存不命中。
5.2内存性能工具
本节讨论各种内存性能工具,它们使你能检查一个给定的应用程序是如何使用内存子系统的,包括进程使用的内存总量和不同的内存类型,内存是在哪里分配的,以及进程是如何有效使用处理器的高速缓存的。
5.2.1 ps(Ⅱ)
对跟踪进程的动态内存使用情况而言,ps是一个极好的命令。除了已经介绍过的CPU 统计数据,ps还能提供关于应用程序使用内存的总量以及内存使用情况对系统影响的详细信息。
5.2.1.1内存性能相关的选项
ps有许多不同的选项,可以获取一个正在运行的应用程序各种各样的状态统计信息。如同你在前面章节里看到的,ps能够检索到一个进程消耗CPU的情况,但它同时也可以检索到进程使用内存的容量和类型信息。ps可以用如下命令行调用:
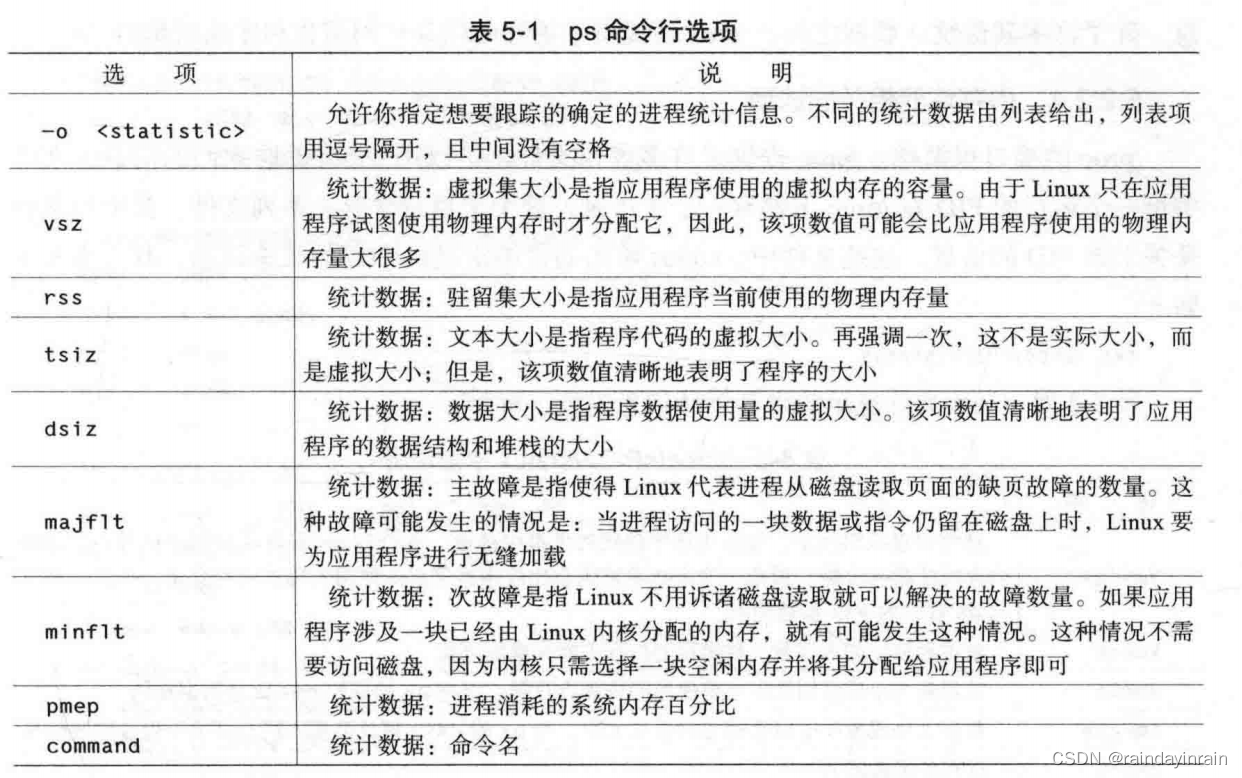
ps [-o vsz, rss, tsiz, dsiz, majflt, minflt, pmem, command]
表5-1解释了给定PID情况下,ps显示的不同类型的内存统计信息。如前所述,在如何选择统计数据要显示哪些PID时,ps是很灵活的。ps-help提供了信息以说明如何指定不同的PID组。
5.2.1.2 用法示例
清单5.1展示了在系统上运行的测试应用程序burn。我们要求ps给出进程的内存统计信息。

如清单5.1所示,应用程序burn的文本大小很小(1KB),但是其数据大小却很大(11122KB)。相对总的虚拟大小(11124KB)来说,进程的驻留集略小一点(10004KB),驻留集表示的是进程实际使用的物理内存总量。此外,burn产生的大多数故障都是次故障,所以,多数内存故障是由内存分配导致的,而不是由从磁盘的程序映像加载大量的文本或数据导致的。
5.2.2 /proc/
Linux内核提供了一个虚拟文件系统,使你能提取在系统上运行的进程的信息。由/proc文件系统提供的信息通常仅被如ps之类的性能工具用于从内核提取性能数据。尽管一般不需要深入挖掘/proc中的文件,但是它确实能提供其他性能工具所无法检索到的一些信息。除了许多其他统计数据之外,/proc还提供了进程的内存使用信息和库映射信息。
5.2.2.1 内存性能相关的选项
/proc的接口很简单。/proc提供了许多虚拟文件,可以用cat来提取它们的信息。系统中每一个运行的PID在/proc下都有一个子目录,这个子目录含有一系列文件,其中包含的是关于该PID的信息。这些文件中,status给出的是给定进程PID的状态信息,其检索命令如下:
cat /proc//status
表5-2对status文件显示的内存统计信息进行了解释。

目录下的另一个文件是maps,它提供了关于如何使用进程虚拟地址空间的信息。其检索命令如下所示:
cat /proc//maps
表5-3解释了maps文件中的字段。

/proc提供的信息可以帮助你了解应用程序是如何分配内存的,以及它使用了哪些库。
5.2.2.2 用法示例
清单5.2显示的是运行于系统上的burn测试程序。首先,我们用ps找到burn的PID (4540)。然后,用/proc的status文件抽取进程的内存统计信息。

如清单5.2所示,我们再一次看到应用程序burn的文本大小(4KB)和堆栈大小(8KB)很小,而数据大小(9776KB)很大,库大小(1312KB)较合理。小的文本大小意味着进程没有太多的可执行代码,而适中的库大小表示它使用库来支持其执行。小的堆栈大小意味着该进程没有调用深度嵌套的函数,或者没有调用使用了大型或多个临时变量的函数。VmLck的大小为0KB说明进程没有锁定内存中的任何页面,使得它们无法交换。VmRSS大小为10004KB意味着应用程序当前使用了10004KB的物理内存,不过它分配或映射的大小为VmSize或11124KB。如果应用程序开始使用之前已分配但并非正在使用的内存,那么VmRSS会增加,而VmSize会保持不变。
如前所述,应用程序的VmLib的大小为非零值,因此程序使用了库。在清单5.3中,我们查看进程的maps来了解它使用的那些库。
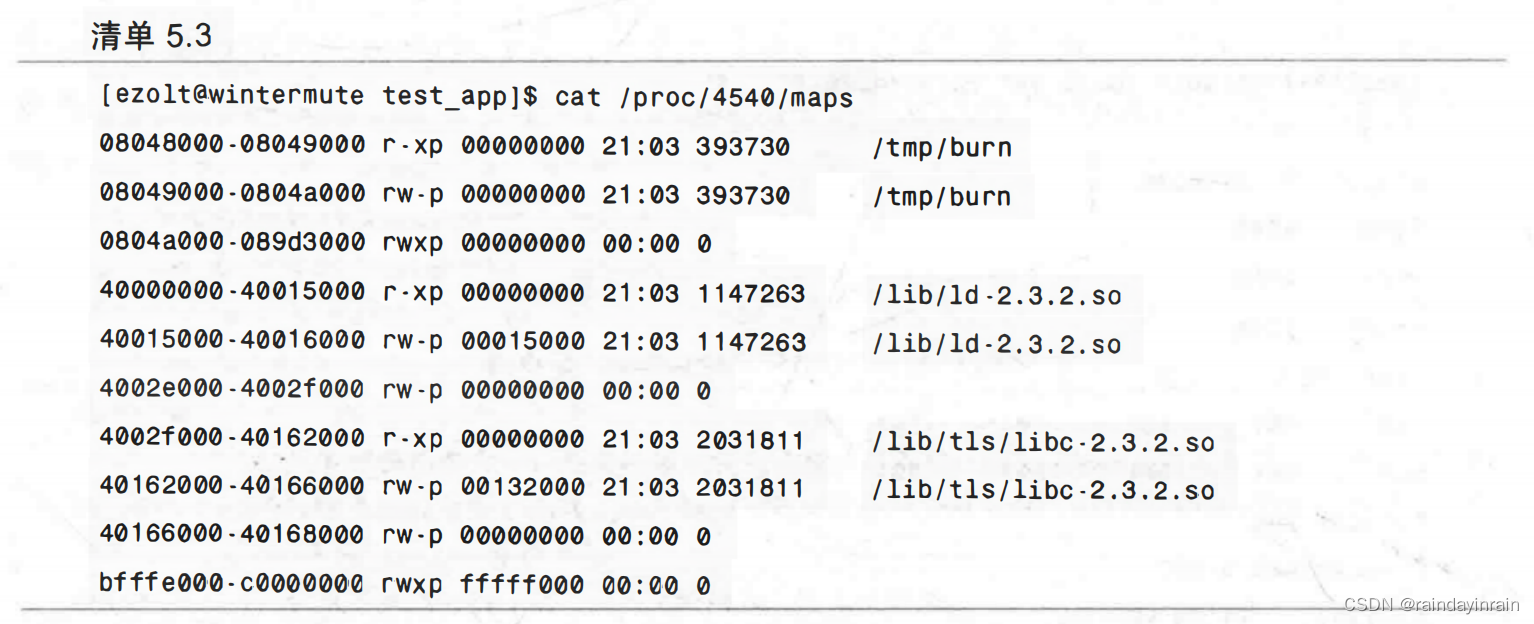
就像你在清单5.3看到的,应用程序burn使用了两个库:ld和libc。libc文本部分(由权限r-xp表示)的范围从0x4002f0000到0x40162000,即大小为0x133000或1257472字节。
libc数据部分(由权限rw-p表示)的范围从40162000到40166000,即大小为0x4000 或16384字节。libc的文本部分大于ld的文本部分,后者的大小为0x15000或86016字节。libc的数据部分也大于ld的数据部分,后者的大小为0x1000或4096字节。libc是burn链接的大库。
/proc被证明是从内核直接提取性能统计信息的有效途径。由于统计信息是基于文本的,因此可以使用标准的Linux工具来访问它们。
5.2.3memprof
memprof是一种图形化的内存使用情况剖析工具。它展示了程序在运行时是如何分配内存的。memprof显示了应用程序消耗的内存总量,以及哪些函数应对这些内存使用量负责。此外,memprof还可以显示哪些代码路径要对内存使用量负责。比如,如果函数foo()不分配内存,但是调用函数bar()要分配大量的内存,那么memprof就会向你显示foo()自身使用的内存量以及foo()调用的全部函数。应用程序运行时,memprof会动态更新这些信息。
5.2.3.1内存性能相关的选项
memprof是一个图形化的应用程序,但是也有一些命令行选项来调整其执行。memprof 用如下命令调用:
memprof [–follow -fork] [-follow -exec] application
memprof剖析给定的“application”,并为其内存使用情况创建一个图形化输出。虽然memprof可以在任何应用程序上运行,但是如果它依赖的应用程序和库使用调试符号编译,那么它就能提供更多的信息。
表5-4说明了控制memprof行为的选项,条件是memprof监控的应用程序调用了fork 或exec。这通常发生在应用程序启动一个新进程或执行一条新命令的时候。

一旦被调用,memprof会创建一个带有一系列菜单和选项的窗口,使你能选择要剖析的应用程序。
5.2.3.2 用法示例
假设我有如清单5.4所示的示例代码,并且我想要剖析这段代码。在这个称为memory eater的应用程序中,函数foo()不分配内存,但是它调用的函数bar()却要分配内存。
用-g3标志编译该应用程序后(这样应用程序就包含了符号),我们使用memprof来剖析该应用程序:
[ezoltelocalhost example]s memprof ./memory_eater memintercept(3965):
_MEMPROF_SOCKET =/tmp/memprof.Bm1AKu memintercept(3965):New process,operation = NEW,old_pid = 0
memprof创建如图5-1所示的应用程序窗口。如同你看到的,它不仅给出了应用程序memory_eater的内存使用情况,还显示了一系列的按钮和菜单使你能对分析进行控制。
如果你点击Profile按钮,memprof会显示对应用程序的内存分析。图5-2中的第一个信息框显示的是每个函数消耗的内存量(用“Self”表示),以及该函数及其子函数消耗的内存总量(用“Total”表示)。和预期的一样,函数foo()不分配任何内存,因此它的Self 值为0,但它的Total值为100000,这是因为它调用的函数要分配内存。
当你点击上面信息框中不同的函数时,Children和Callers信息框会发生变化。这样你就可以看到应用程序的哪些函数在使用内存。
memprof提供了一种以图形方式遍历大量的关于内存分配数据的途径。它给出了一种简单的方法来确定给定函数及其调用的函数的内存分配情况。

5.2.4 valgrind(cachegrind)
valgrind是一个强大的工具,使你能调试棘手的内存管理错误。虽然valgrind主要是一个开发者工具,但它也有一个“界面”能显示处理器的高速缓存使用情况。valgrind模拟当前的处理器,并在这个虚拟处理器上运行应用程序,同时跟踪内存使用情况。它还能模拟处理器高速缓存,并确定程序在哪里有指令和数据高速缓存的命中或缺失。
虽然valgrind很有用,但是它的高速缓存统计信息却是不准确的(因为valgrind只是处理器的模拟,而不是一个真实的硬件)。valgrind不计算通常由对Linux内核的系统调用导致的高速缓存缺失,也不计算由于上下文切换而发生的高速缓存缺失。此外,valgrind运行应用程序的速度比本机执行程序的速度慢得多。但是,valgrind提供了与应用程序高速缓存使用情况最接近的数据。valgrind可以运行于任何可执行文件。如果程序已经用符号编译过了(在编译时把-g3传递给gcc),它还是能够准确地找出要对高速缓存的使用情况负责的代码行。
5.2.4.1内存性能相关的选项
当使用valgrind分析一个特定应用程序的高速缓存使用情况时,要经历两个阶段:收集和注释。收集阶段从如下命令行开始:
valgrind -skin=cachegrind application
valgrind是一个灵活的工具,它有几种不同的“界面”使其可以执行不同类型的分析。在收集阶段,valgrind用cachegrind界面来收集关于高速缓存使用情况的信息。上述命令行中的application表示的是要剖析的应用程序。收集阶段在屏幕上显示的是概要信息,但它同时也在名为cachegrind.out.pid的文件中保存了更加详细的统计数据,文件名中的pid是其运行时被剖析应用程序的PID。当收集阶段完成后,使用命令cg_annotate把高速缓存使用情况映射回应用程序源代码。cg_annotate调用方式如下:
cg_annotate -pid [–auto=yeslno]
cg_annotate获取valgrind生成的信息,并用它来注释被剖析的应用程序。选项–pid是必须的,因为pid是你有兴趣进行剖析的对象的PID。默认情况下,cg_annotate只显示函数级的高速缓存使用情况。如果你的设置为–auto=yes,那么就会在源代码级显示高速缓存的使用情况。
5.2.4.2用法示例
本例展示了在一个简单应用程序上运行的valgrind(v2.0)。该应用程序清除一大块内存区域,然后调用两个函数:a()和b(),这两个函数都要访问这个内存区域。函数a()访问内存的次数是函数b()访问次数的10倍。首先,如清单5.5所示,我们用cachegrind界面在应用程序上运行valgrind。
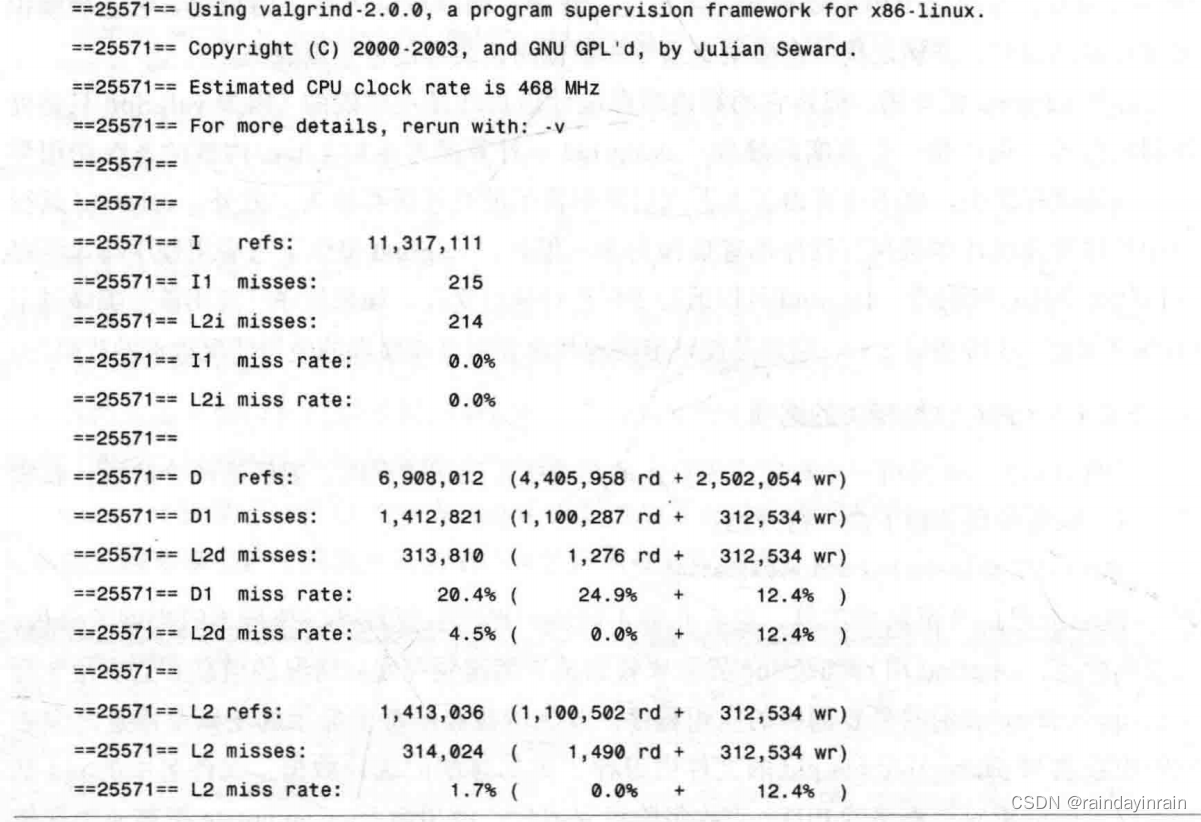
在清单5.5的运行中,应用程序执行了11317111条指令;该项显示在Irefs统计数据中。进程在L1(215)和L2(214)指令高速缓存中的缺失次数低得令人吃惊,由I1和L2i miss rate的0.0%表示。进程的数据引用总次数为6908012,其中,4405958次为读,2502054次为写。24.9%的读和12.4%的写无法由L1高速缓存满足。幸运的是,我们几乎总是可以在L2数据高速缓存中满足读操作,因此,它们显示的缺失率为0%。写操作仍然是个问题,其缺失率为12.4%。在这个应用程序中,数据的内存访问是需要调查的问题。
理想的应用程序应该有非常低的指令高速缓存和数据高速缓存缺失率。要消除指令高速缓存缺失,可能需要用不同的编译器选项重新编译应用程序,或者裁剪代码,这样热代码就不需要与不常用的代码一起共享icache空间了。要消除数据高速缓存缺失,使用数组而非链表作为数据结构,如果可能的话,降低数据结构中元素的大小,并用高速缓存友好的方式来访问内存。在任何情况下,valgrind有助于指出哪个访问/数据结构需要进行优化。该应用程序运行的汇总信息表明数据访问是主要问题。
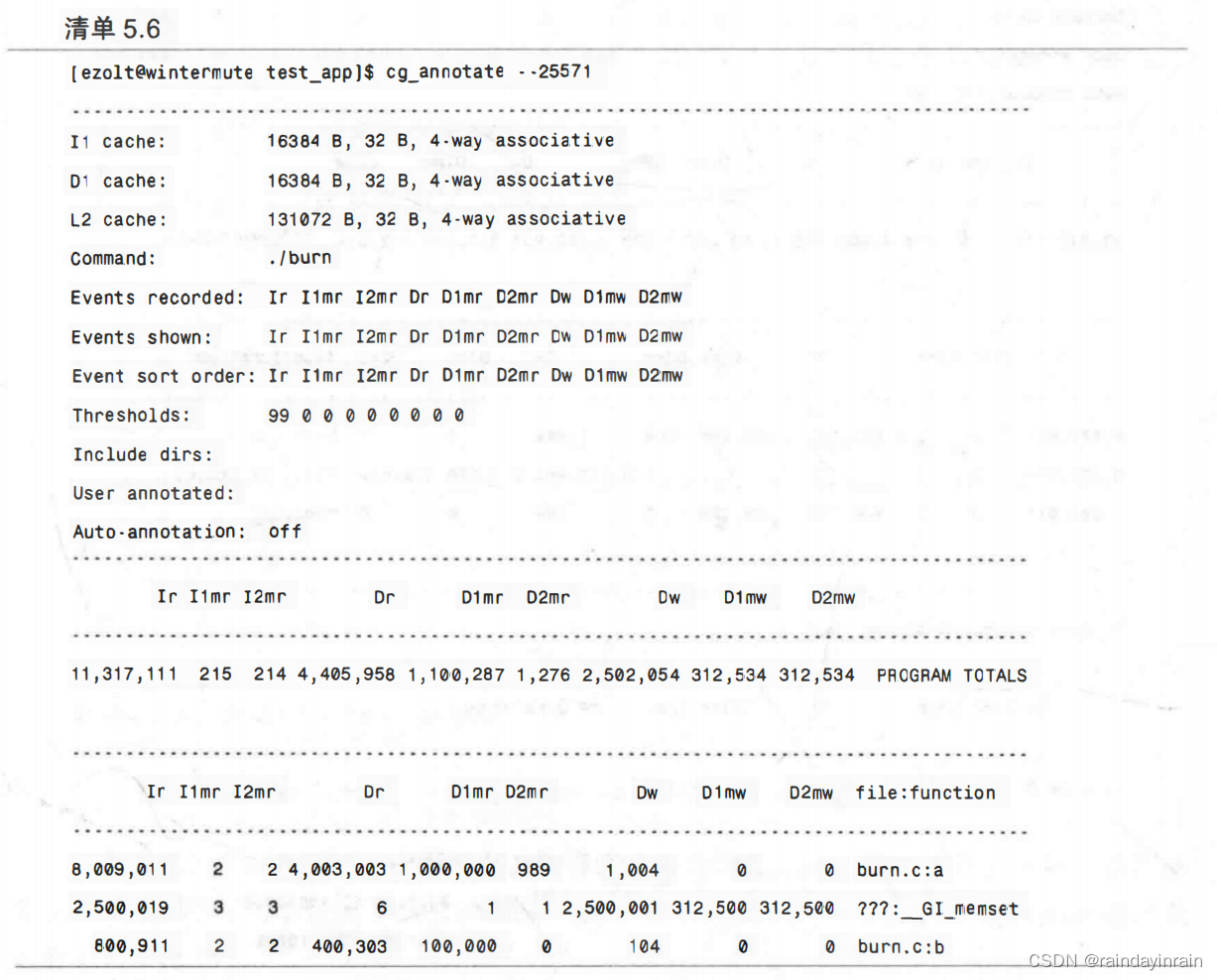
如清单5.5所示,这条命令显示了整体运行的高速缓存的使用情况统计信息。但是,对开发应用程序,或调查性能问题而言,更为有趣的是查看高速缓存缺失发生的位置,而不是仅仅了解在应用程序运行期间出现的缺失总数。要确定由哪个函数为高速缓存缺失负责,我们运行cg_annoate,如清单5.6所示。它向我们展示了哪个函数要为哪个高速缓存缺失负责。和我们预想的一样,函数a()的缺失次数(1000000)是函数b()(100000)的10倍。
虽然按单个函数来分解高速缓存缺失是有用的,但是查看应用程序的哪些行导致了高速缓存缺失也是很有趣的。如果我们如清单5.7那样使用–auto选项,cg_annotate就会准确地告诉我们每个缺失都要由哪一行负责。


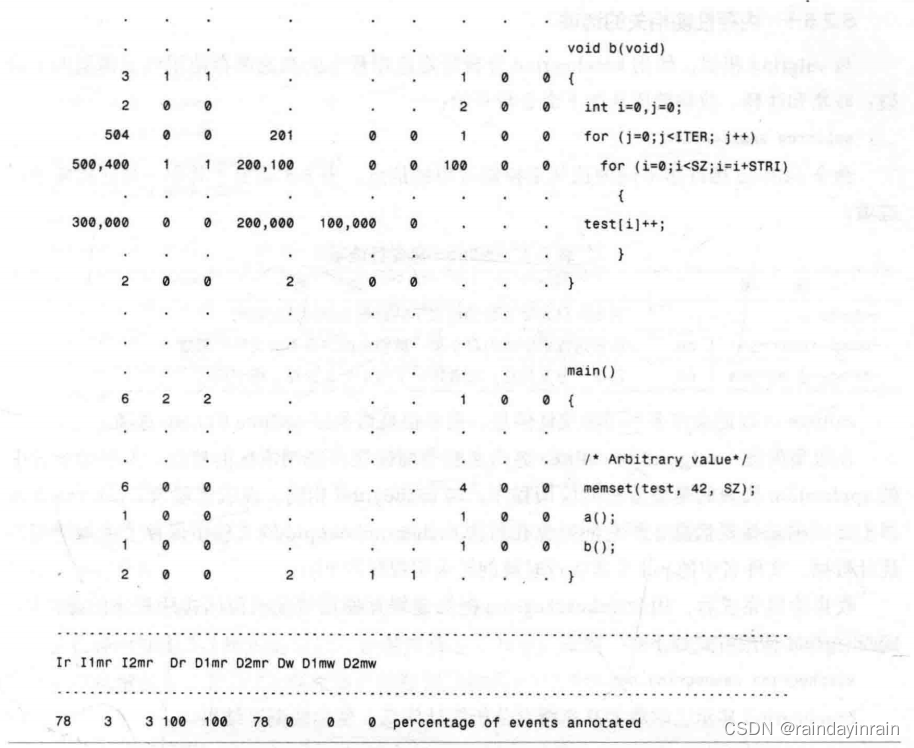
如清单5.7所示,我们在不同的高速缓存缺失和命中发生时,进行了逐行分解。我们能看到内层for循环几乎包揽了所有的数据引用。和我们预期的一样,函数a()的for循环是函数b()的10倍。
valgrind/cachegrind提供的不同级别(程序级、函数级和代码行级)的详细信息为你提供了一个很好的途径来了解应用程序的哪些部分正在访问内存,以及在有效地使用处理器的高速缓存。
5.2.5 kcachegrind
kcachegrind与valgrind密切合作,提供关于被剖析应用程序的高速缓存使用情况的详细信息。它在标准valgrind的基础上增加了两个新的功能。首先,它为valgrind提供了一个界面,称为calltree,以捕捉特定应用程序的高速缓存和调用树的统计数据。其次,它还提供了对高速缓存性能信息的图形化展示,以及新颖的数据视图。
5.2.5.1内存性能相关的选项
与valgrind相似,使用kcachegrind分析特定应用程序的高速缓存使用情况需要两个阶段:收集和注释。收集阶段从如下命令行开始:
calltree application
命令calltree用许多不同的选项来控制收集的信息。表5-5给出了其中一些比较重要的选项。

calltree可以记录许多不同的统计信息。更多信息请参阅calltree的help选项。
在收集阶段,valgrind用calltree界面来收集高速缓存使用情况的信息。上述命令行中的application代表的是要分析的应用程序。与cachegrind相同,在收集阶段,calltree在屏幕上显示的是概要信息,而它同时也在名为cachegrind.out.pid的文件中保存了更加详细的统计数据,文件名中的pid是其运行时被剖析应用程序的PID。
收集阶段完成后,用命令kcachegrind把高速缓存使用情况映射回应用程序的源代码。kcachegrind调用方式如下:
kcachegrind cachegrind.out.pid
kcachegrind显示已收集的高速缓存分析统计信息,使你能浏览结果。
5.2.5.2 用法示例
使用kcachegrind的第一步是用符号编译应用程序,以允许样本到源代码行的映射。下面的命令能完成这一步:
[ezoltewintermute test_app]$ gcc -o burn burn.c -g3
第二步,对应用程序运行calltree,如清单5.8所示。这提供了与cachegrind类似的输出,但是更重要的是,它生成了cachegrind.out文件,kcachegrind将使用这个文件。
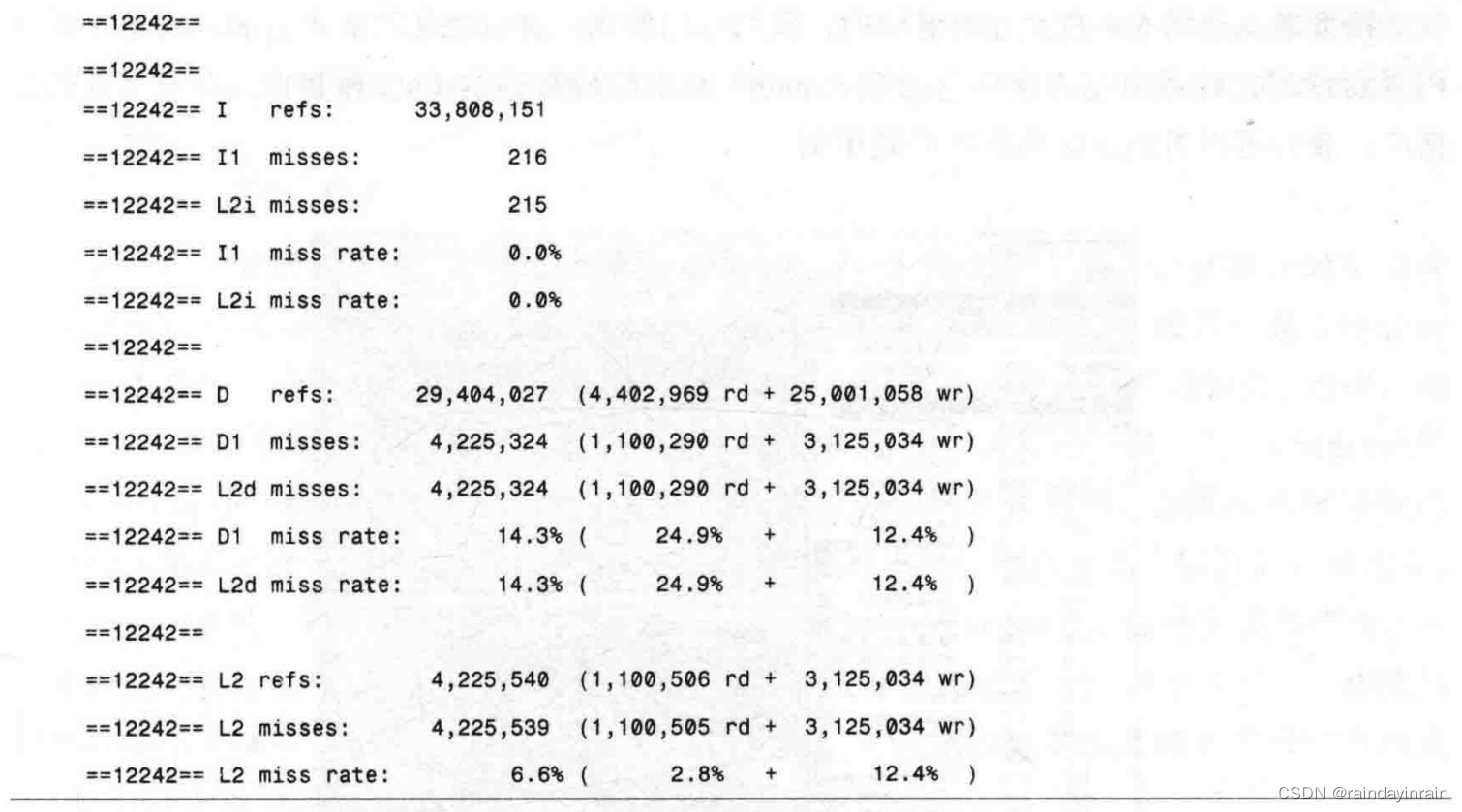
当我们得到cachegrind.out文件后,我们可以用下面的命令来启动kcachegrind(v.0.54)对数据进行分析:
[ezoltewintermute test_app]s kcachegrind cachegrind.out.12242
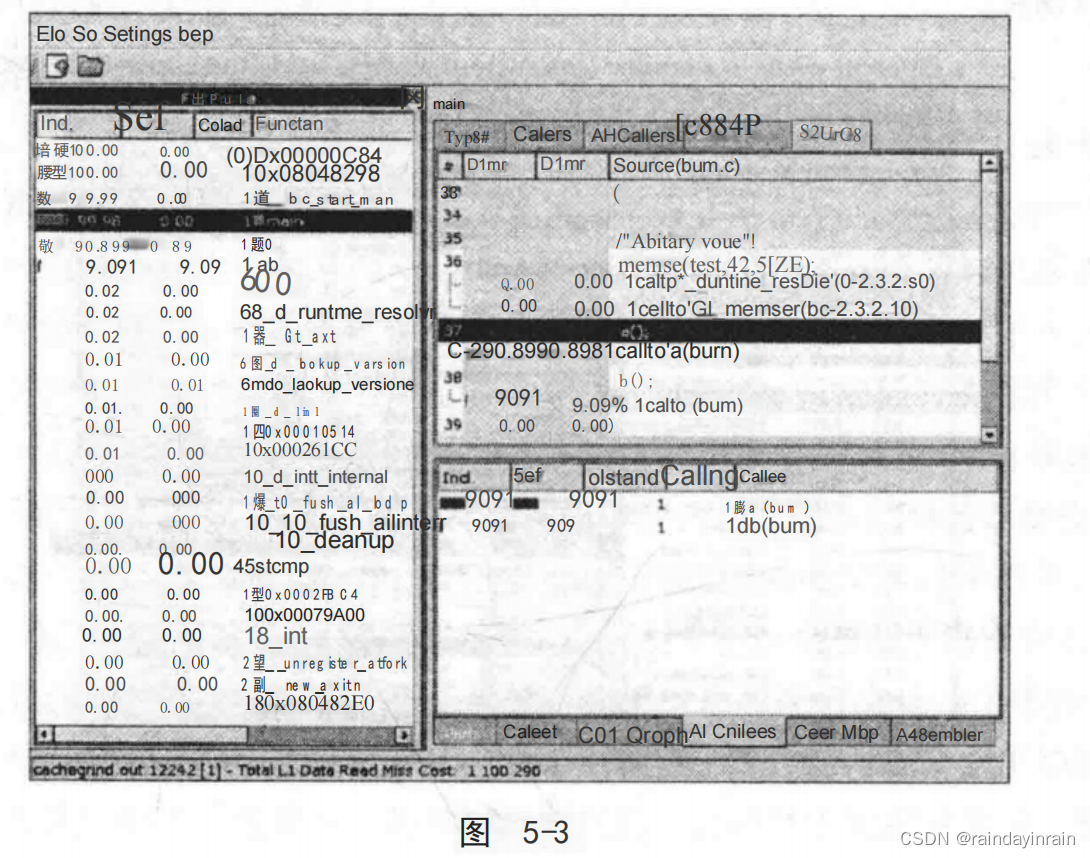
这将弹出如图5-3所示的窗口。该窗口给出了对左边窗格中所有的高速缓存缺失的平面描述。默认情况下,显示L1高速缓存的数据读缺失。
接下来,在图5-4右上方的窗格中,我们可以看到一种可视化的表示,表示对象为被调用者示意图,或者由左边窗格内函数(main)调用的所有函数(a()和b())。在右下方的窗格中,我们可以看到该应用程序的调用图。
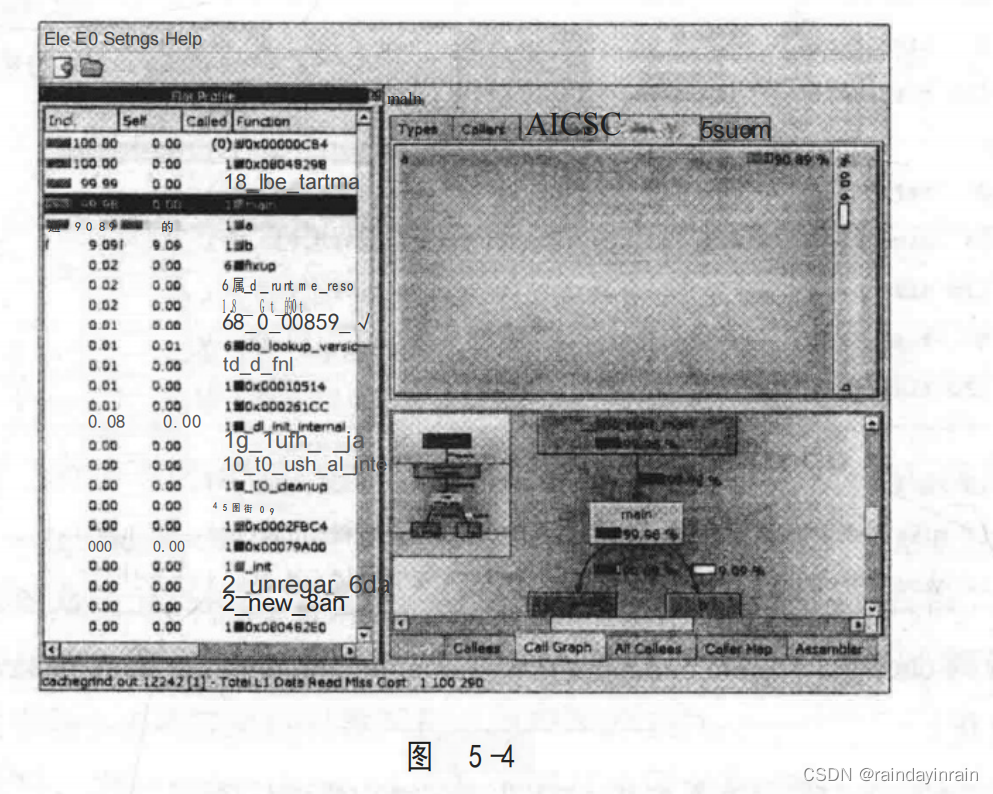
最后,在图5-5中,我们选择查看左边窗格内一个不同的函数,并用右上方窗格选择了一个不同的事件(Instruction Fetch)。最终,我们可以用右下方的窗格将用汇编代码表示的循环进行可视化。
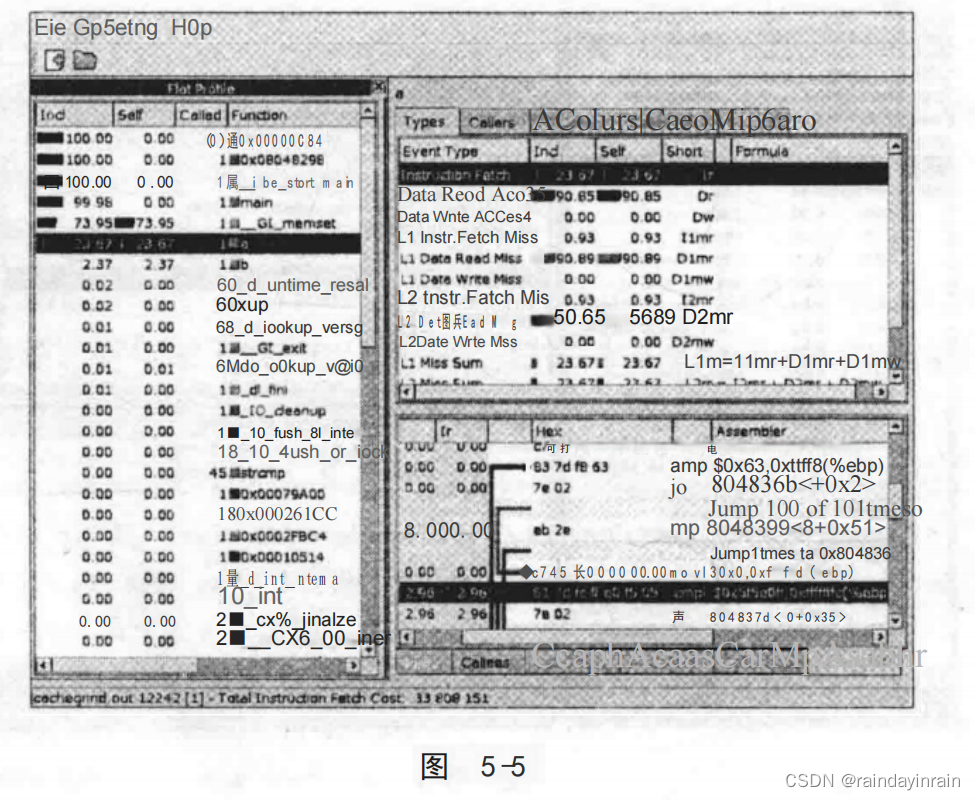
上述示例仅仅涉及了kcachegrind功能的表面,学习这个工具最好的方法就是尝试使用它。对那些喜欢将性能问题调查可视化的人来说,kcachegrind是一个非常有用的工具。
5.2.6 oprofile(III)
如同你在前面章节里了解过的一样,oprofile是一个强大的工具,它有助于确定应用程序的时间都花在哪些地方。不过,oprofile还可以和处理器的性能计数器一起工作,以提供关于其执行情况的精确描述。cachegrind模拟CPU来找到高速缓存的缺失/命中,而oprofile则利用实际的CPU性能计数器来精确查找高速缓存缺失的位置。与cachegrind不同,oprofile不用模拟处理器,因此它记录的高速缓存结果是真实的,由操作系统导致的结果则将是可见的。此外,在oprofile下分析的应用程序执行起来基本上接近其原始速度,而cachegirnd则要花更多时间。但是,与oprofile相比,cachegrind更容易安装和使用,并且不论它运行于那个版本的x86处理器,它都可以跟踪同样的事件。当你需要一个快捷且相当准确的答案时,cachegrind是一个很好的工具。而当你需要更加准确的统计信息或者cachegrind无法提供的统计信息时,oprofile就很有用了。
5.2.6.1内存性能相关的选项
本节在讨论oprofile时不再添加任何新的命令行选项,因为在关于CPU性能的章节中已经描述过它们了。但是当你开始采样与oprofile默认设置不同的事件时,有一个命令会变得更加重要。不同的处理器和架构可以采样不同的事件集,oprofile的op_help命令会显示当前你的处理器所支持的事件列表。
5.2.6.2用法示例
如前所述,oprofile能够监控的事件都是与特定处理器相关的,因此,这些示例都是运行在当前的机器上的,即Pentium ⅢI。在Pentium ⅢI上,我们可以利用oprofile提供的性能计数器来收集信息,这些信息与valgrind在cachegrind界面下给出的信息类似。这使用的就是性能计数器硬件,而不是软件模拟。使用性能硬件有两个缺陷。第一,我们必须应对性能计数器的底层硬件限制。在Pentium Ⅲ上,oprofile只能同时测量两个事件,而cachegrind则可以同时测量多种类型的内存事件。这就意味着,对oprofile来说要测量与cachegrind相同的事件,我们必须多次运行应用程序,并且每次运行期间都要改变oprofile 的监控事件。第二个缺陷就是oprofile不会像cachegrind那样提供精确的事件计数,它只对计数器采样,因此我们能够看到事件最有可能在哪里发生,但是却无法看到确切的数量。实际上,我们只能接收到(1/采样率)个采样。如果应用程序只会让一个事件发生几次,那么这个事件可能根本就不会被记录下来。尽管在调试一个性能问题时,不知道事件确切的数目会让人沮丧,但通常最重要的却是弄清楚代码行之间样本的相对数量。即使无法直接确定特定源代码行发生事件的总数,但是可以找到事件最多的那一行,一般说来,这足以启动性能问题调试。这种无法获取准确事件计数的情况出现在每一种形式的CPU采样中,也将出现在所有实现它的处理器性能硬件中。而实际上,正是这一限制,使得性能硬件从根本上得以存在,如果没有它,那么性能监控将会导致过多的消耗。
oprofile可以监控许多不同类型的事件,这些事件在不同的处理器上会发生变化。作为示例,本小节将介绍一些Pentium ⅢI的重要事件。通过利用下述事件(事件及说明由op_help提供),Pentium ⅢI可以监控L1数据高速缓存(在Pentium ⅢI中被称为DCU):
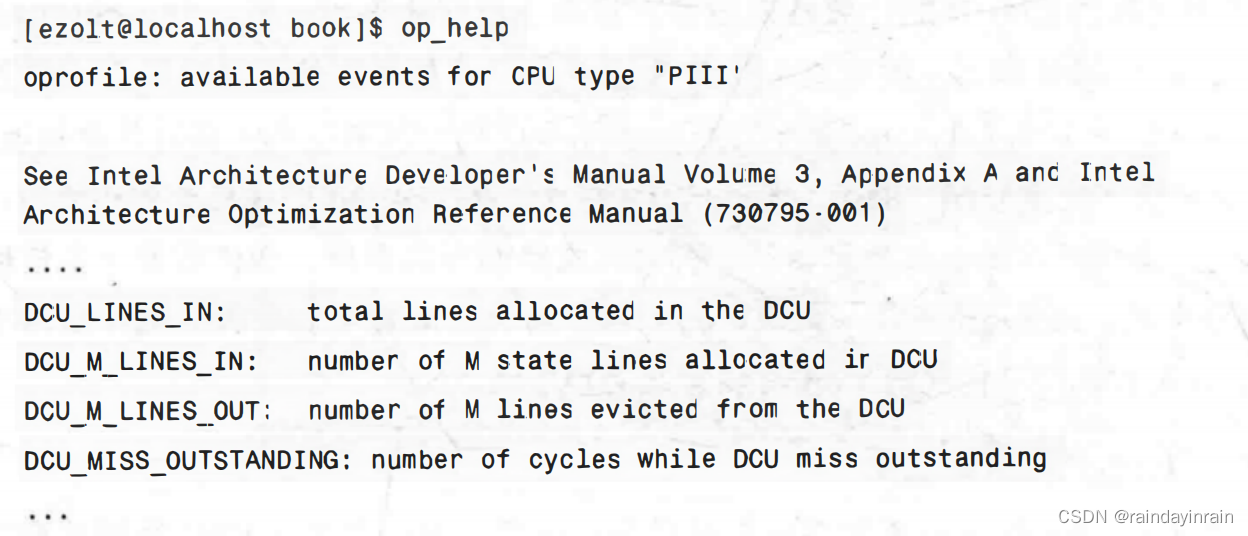
注意,我们没有与cachegrind提供信息的确切对应,即L1数据高速缓存的“读和写”数量。但是,通过使用DCU_LINES_IN事件,我们可以发现每个函数有多少周期的L1数据缺失。尽管这个事件不会告诉我们每个函数准确的缺失数量,但是它却会告诉我们每个函数相对于彼此在高速缓存中有多少缺失。监控L2数据高速缓存的事件有点接近,但它仍然没有与cachegrind提供信息的精确对应。下面是Pentium Ⅲ的与L2数据高速缓存相关的事件:
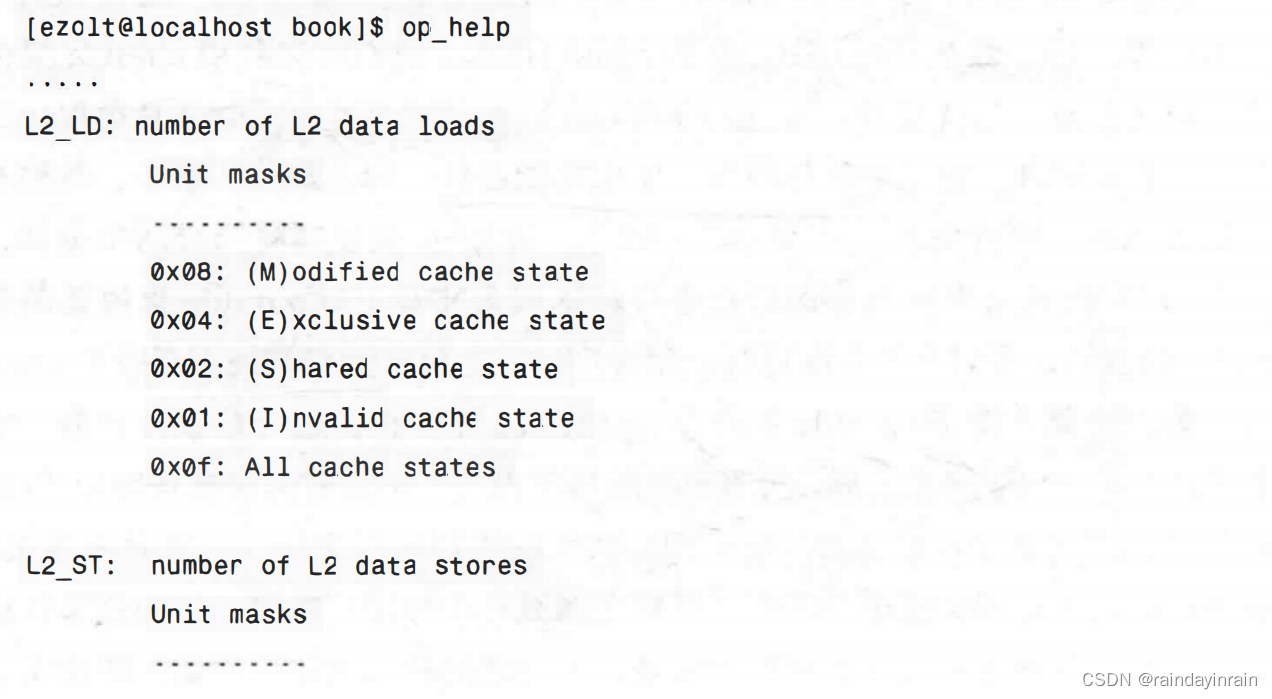

Pentium Ⅲ实际支持的要比这些更多,但是上述这些是基本的加载和存储事件。(cachegrind将加载称为“读”,将存储称为“写”。)我们可以用这些事件来计算每一行源代码上发生的加载和存储的数量。我们还可以用L2_LINES_IN来显示哪一块代码有更多的L2高速缓存缺失。如前所述,我们不会得到精确的数值。此外,在Pentium ⅢI上,指令和数据共享L2高速缓存。任何L2缺失都有可能是指令或数据缺失的结果。oprofile展现给我们的L2中的高速缓存缺失是指令和数据缺失的结果,而cachegrind则帮助我们将它们区分开来。
在Pentium Ⅲ上,有一系列相似的事件来监控指令高速缓存。对L1指令高速缓存(Pentium ⅢI称其为“IFU”)而言,我们可以通过使用如下事件来直接测量读(或取)和缺失的数量:
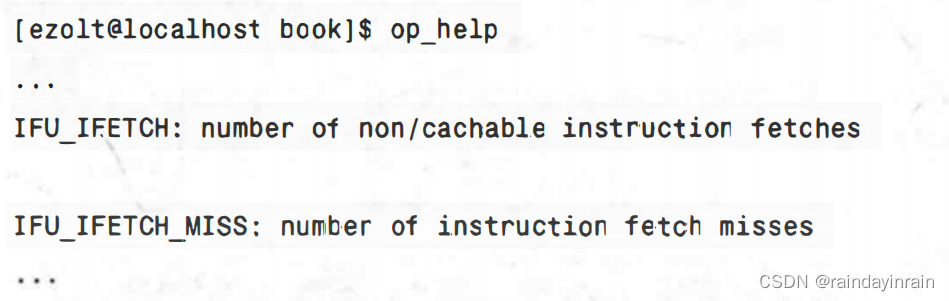
我们还可以利用下述事件来测量从L2高速缓存中取到的指令数:
可惜的是,如前面提到的一样,处理器的L2高速缓存是由指令和数据共享的,因此,没有办法区分数据使用中的高速缓存缺失和指令使用中的高速缓存缺失。我们可以利用这些事件来获得与cachegrind所提供信息的近似值。
如果提取相同信息是如此困难,为什么还要使用oprofile?首先,oprofile的开销非常低(<10%)并且可以运行于产品化的应用程序。其次,oprofile可以精确抽取正在发生的事件。这比可能不准确的模拟器要好得多,更不要说这个模拟器还不考虑操作系统或其他应用程序的高速缓存使用情况。
尽管这些事件在Pentium Ⅲ上是可用的,但它们在其他处理器上不一定可用。每个Intel和AMD的处理器家族都有各种的事件集可用来提供关于内存子系统性能的不同数量的信息。op_help显示可被监控的事件,但是要理解这些事件的含义可能还需要阅读详细的Intel或AMD处理器信息。
要了解怎样用oprofile来获取高速缓存信息,可用对比同一个应用程序在使用cachegrind的虚拟CPU以及使用oprofile的实际CPU这两种情况下的高速缓存使用情况信息。让我们运行一下之前的示例程序burn。再说一次,这个应用程序在函数a()中运行的指令是函数b()中的十倍。它在函数a()中访问的数据量也是b()中的十倍。下面是这个示例程序在cachegrind中的输出:
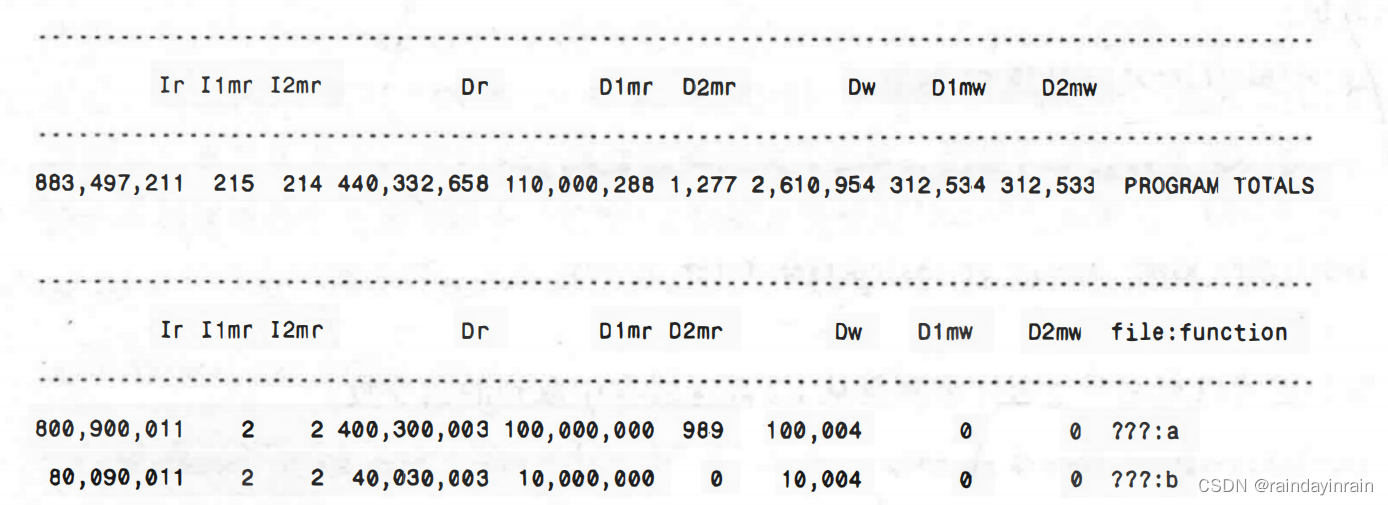
在接下来的几个例子中,多次运行了oprofile的数据收集阶段。我使用oprof_start为特定的运行设置事件,然后再运行演示程序。因为我的CPU只有两个计数器,因此需要多次重复这个步骤。这就意味着程序不同的执行过程将可以监控到不同的事件集。由于我的应用程序在每次运行时不会改变其运行方式,因此,每次运行都应产生相同的结果。不过这一点对于更加复杂的应用程序来说不一定是正确的,比如Web服务器或数据库,它们会根据提出的请求动态改变其执行情况。然而,对于简单的测试程序来说这一点则是适用的。
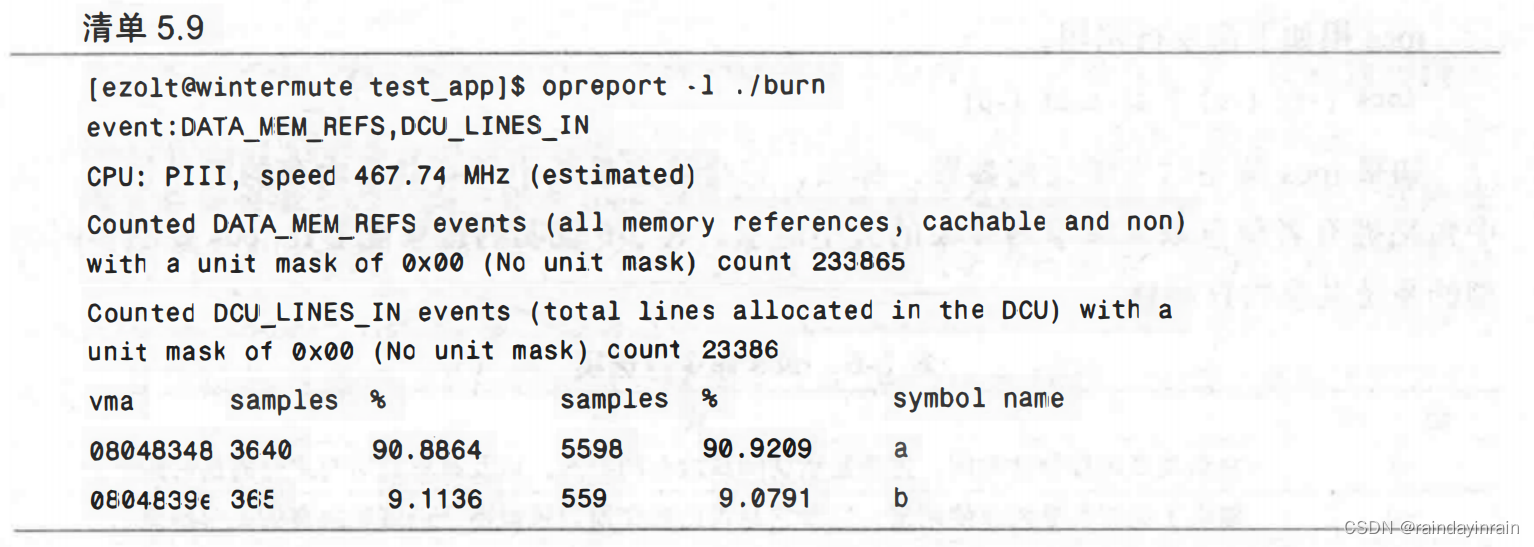
收集了采样信息之后,我们用opreport提取被收集的信息。如清单5.9所示,我们向oprofile查询已生成的对数据内存引用的数量,以及在L1数据高速缓存(DCU)中有多少次缺失。和cachegrind告诉我们的一样,函数a()对内存引用的次数和发生的L1数据缺失数是函数b()的10倍。
现在查看清单5.10,它显示opreport对指令高速缓存进行了同样的信息检测。请注意,和我们预期的一样,函数a()执行的指令数是函数b()的10倍。不过,L1指令缺失的数量却和cachegrind预期的不同。最可能的原因是其他应用程序和内核正在使用高速缓存,从而导致burn在icache中出现缺失。(请记住cachegrind不会将内核或其他应用程序的高速缓存使用情况考虑在内。)同样的情况也可能发生在数据高速缓存里,但由于应用程序导致的数据高速缓存缺失数量太大,以致其他的事件就被淹没在噪声里。
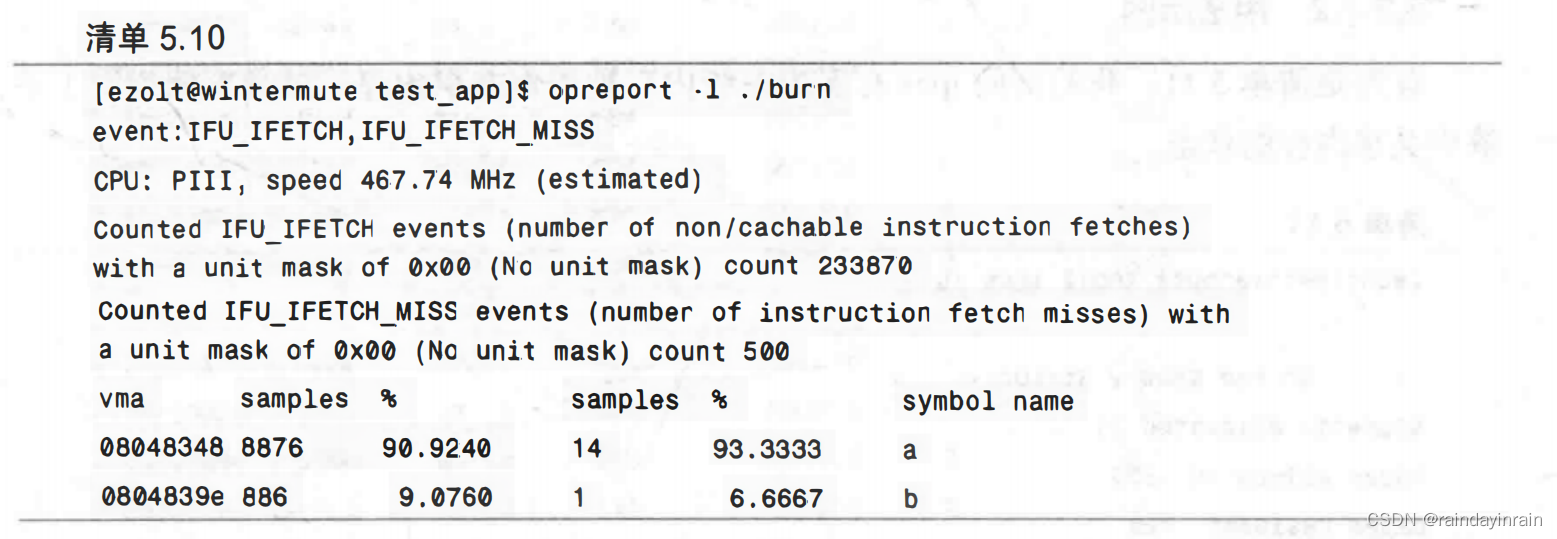
比较cachegrind和oprofile的输出可知,用oprofile来收集与内存相关的信息是很有效的,因为oprofile开销低且能直接利用处理器硬件,但是它却难以找到与你感兴趣的内容相匹配的事件。
5.2.7 ipcs
ipcs是一种系统级工具,可以展示进程之间通信内存的信息。进程可以分配整个系统共享的内存、信号量,以及由系统上运行的多个进程所共享的内存队列。ipcs最好被用于跟踪哪些应用程序分配并使用了大量的共享内存。
5.2.7.1内存性能相关的选项
ipcs用如下命令行调用:
ipcs [-t] [-C] [-l] [-u] [-P]
如果ipcs调用时不带任何参数,那么,它会给出系统中所有共享内存的汇总信息。其中包括拥有者信息以及共享内存段的大小信息。表5-6说明的选项能够让ipcs显示不同类型的系统共享内存信息。
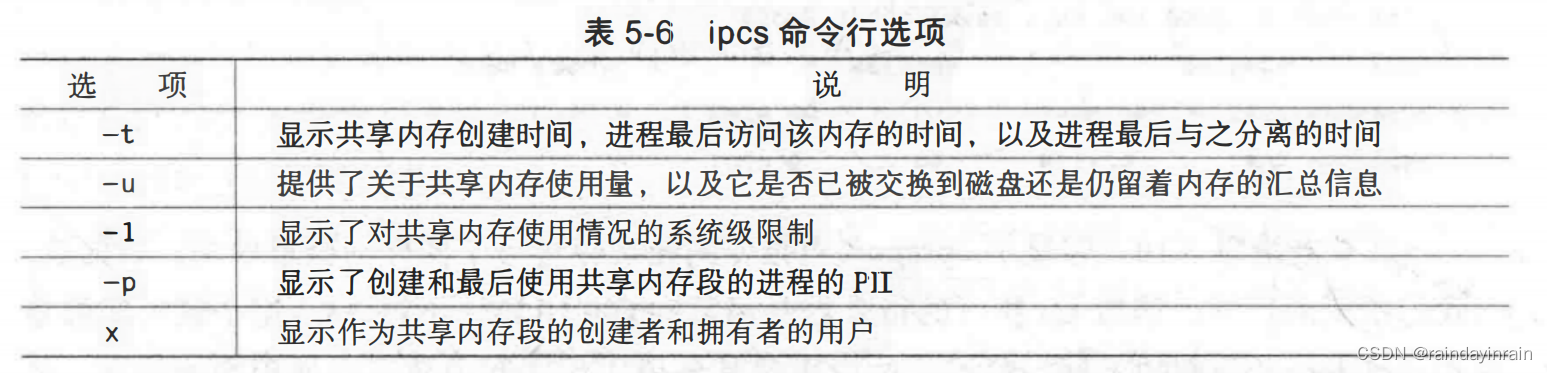
由于共享内存被多个进程使用,它不能归属于任何一个特定的进程。ipcs提供了足够的系统级共享内存的状态信息,可以用于确定哪些进程分配了共享内存,哪些进程使用了它们,以及使用的频率。在试图降低共享内存使用量时,这些信息是很有用的。
5.2.7.2 用法示例
首先是清单5.11,我们询问ipcs有多少系统内存被用作共享内存。这清晰地指明了系统中共享内存的状态。
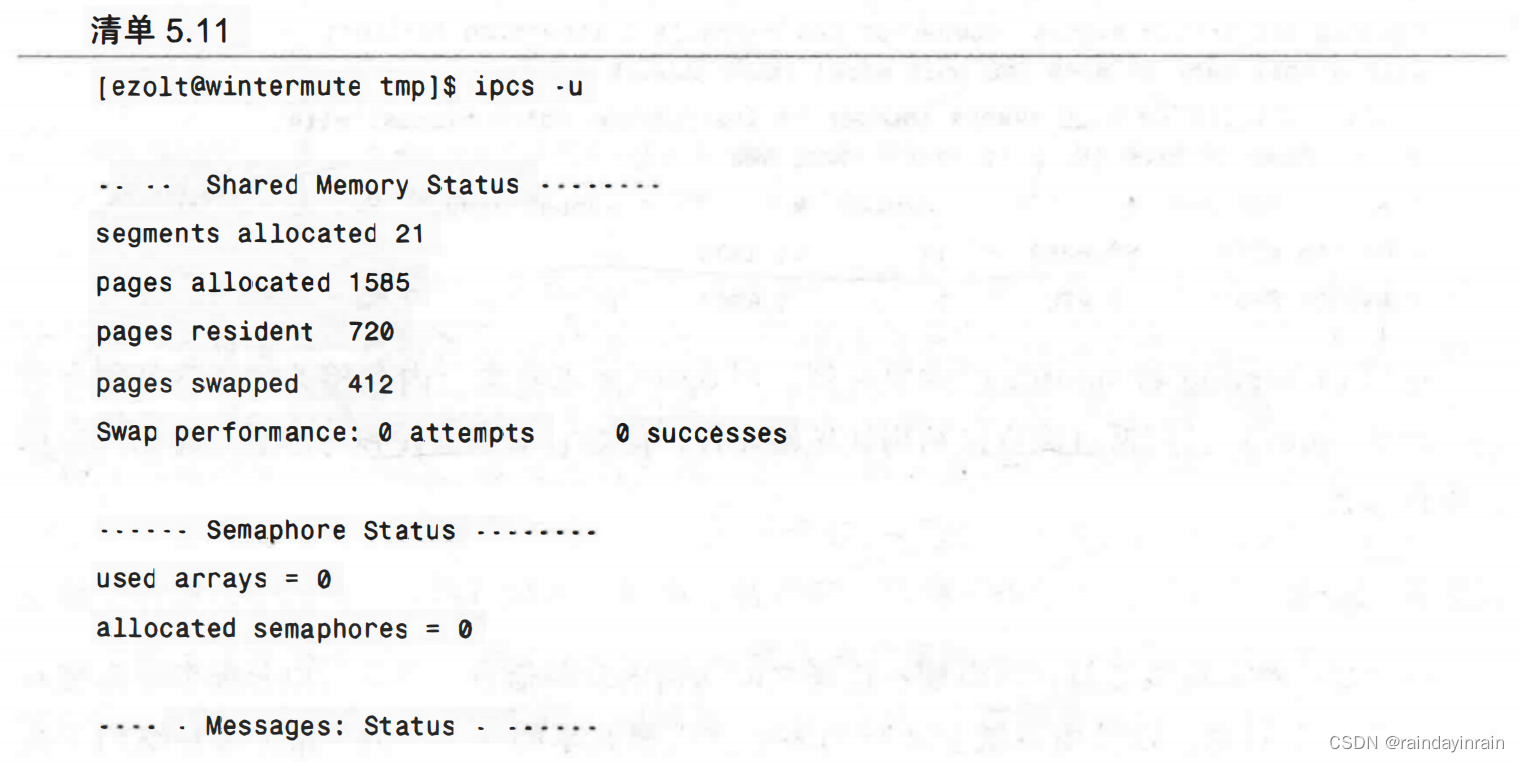

在这个例子中,我们看到有21个不同的内存段或内存片已经被分配了。所有这些段一共占用了1585个内存页。其中,720页留驻在物理内存中,412页已经交换到磁盘。
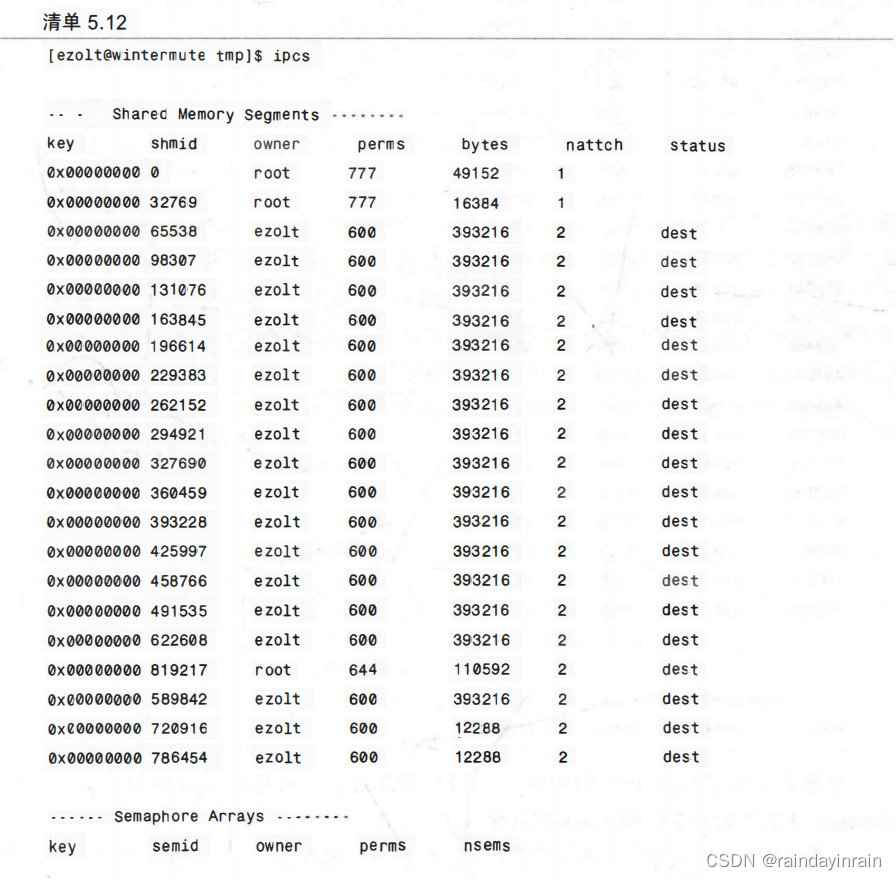
接下来是清单5.12,我们要求ipcs为系统中所有的共享内存段提供一个概览。这会指明谁使用了哪个内存段。本例中,我们看到了包含所有共享段的清单。特别是共享内存ID 为65538的,其用户(ezolt)就是拥有者。它的权限为600(典型的UNIX权限),在本例中,这意味着只有ezolt能够对其进行读写。该共享段有393216个字节,有两个进程访问了它。

最后,我们还可以确切地指出哪些进程创建了共享内存段,哪些进程使用了这些段,如清单5.13所示。对shmid为32769的段来说,我们可以看到PID1224的进程创建了它,最后使用它的是PID为11954的进程。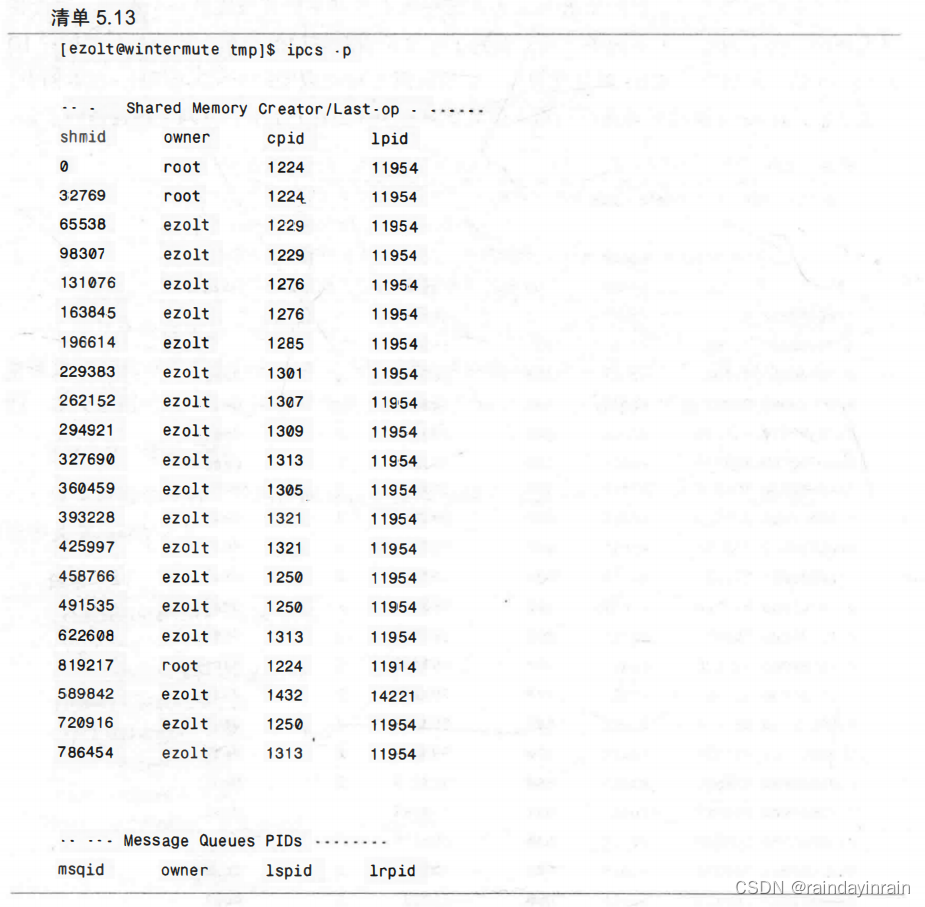
当我们知道了负责分配和使用这些段的PID之后,我们就可以使用诸如“ps-o command PID”的命令从PID回溯到进程名。如果共享内存使用量占了系统总量的很大一部分,那么ipcs是一个很好的方法来准确地跟踪那些创建和使用共享内存的程序。
5.2.8动态语言(Java和Mono)
与CPU性能工具一样,本章讨论的大多数工具都支持对诸如C和C++的静态语言的分析。在我们调查的工具中,只有ps、/proc和ipcs是支持动态语言,如Java、Mono、Python和Perl等。高速缓存和内存剖析工具,如oprofile以及memprof则不支持动态语言。像CPU分析一样,每种语言都提供了自定义的工具来提取内存使用情况信息。
对Java应用程序而言,如果Java命令运行时带上了-Xrunhprof命令行选项,它就会分析应用程序的内存使用情况。更多详细信息参见http://antprof.sourceforge.net/hprof.html,或者运行带-Xrunhprof:help选项的java命令。对Mono应用程序来说,如果向mono可执行代码传递了–profile标志,它也会分析应用程序的内存使用情况。更多详细信息参见http://www.go-mono.com/performance.html。Perl和Python没有出现类似的功能。
5.3 本章小结
本章介绍了各种可以用于诊断内存性能问题的Linux工具,展示了可以显示应用程序内存消耗量的工具(ps、/proc),以及显示应用程序中的哪些函数分配了内存的工具(memprof)。本章还包括了可以监控处理器、系统高速缓存和内存子系统有效性的工具(cachegrind、kcachegrind和oprofile)。本章最后描述了一种可以监控共享内存使用情况的工具(ipcs)。这些工具一起使用就可以跟踪内存的每个分配、这些分配的大小、应用程序中这些分配的函数位置,以及在访问这些分配时,应用程序使用内存子系统的有效性。
下一章将调查磁盘I/O瓶颈。















 1124
1124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











