






一、环境配置
总结笔者安装环境版本为:
Visual Studio2019
Opencv 4.6.0
Cuda 11.5
Cudann 8.3.0
TensorRT 8.4.1
Python环境3.8
Pytorch 1.12.0
1.Opencv C++安装
VS配置永久OpenCV(小萌轻松操作):超细致_visual studio永久配置opencv-CSDN博客
按照这个链接进行安装(将Visual studio和OPENCV的版本进行更换),
Visual Studio版本为2019
OPENCV版本为4.6.0
问题日志:
当遇到这个错误时

是由于你的电脑Visual Studio编译采用win32位架构,而OPENCV是使用64位
因此需要对以下几个配置进行更改:
右键点击项目属性会出现以下图像

进入1处配置管理器更改平台为x64
2处更改为Machinex64
2.Cuda、Cudann、TensorRT安装指南
VS2022配置CUDA、CuDNN和TensorRT的环境_vs2022 cuda-CSDN博客
Cuda安装11.5
CUDA Toolkit 11.5 Downloads | NVIDIA Developer
Cudann 8.3.0 for 11.5版本
cuDNN Archive | NVIDIA Developer
TensorRT版本选择 TensorRT 8.4 GA for Windows 10 and CUDA 11.5 ZIP Package
https://developer.nvidia.com/nvidia-tensorrt-8x-download
Visual Studio2019 配置OPENCV Cuda Cudann TensorRT环境
OPENCV的配置方法:
VS配置永久OpenCV(小萌轻松操作):超细致_visual studio永久配置opencv-CSDN博客
CUDA 和Cudann以及TensorRT配置方法从2.0开始看
VS2019+CUDA10.2+tensorRT7.0+opencv4.12环境配置yolo-tensorrt | AI技术聚合
注意事项:高于8.2的版本的TensorRT,依赖库中不要添加myelin64_1.lib
问题错误:1: [runtime.cpp::nvinfer1::Runtime::parsePlan::314] Error Code 1: Serialization (Serialization assertion plan->header.magicTag == rt::kPLAN_MAGIC_TAG failed.)
出现这个错误是由于原Github上下载的engine文件与本地版本不对,需要自己将模型pt文件转换为Onnxtime文件,最后生成engine文件。
二、模型转换
在上面的工作均已完成后,再进行下一步:
模型转换指南,RTM模型包括两个模块:RTMdet用于检测人体框;RTMpose用于检测人体关键点。
1.RTMdet转换步骤:
(1)首先去rtmpose_tensorrt网站上下载源码,
GitHub - Dominic23331/rtmpose_tensorrt (里面有部署好的rtmdet.engine和rtmpose_s.engine,但是和我们下载的tensorRT版本不同,因此需要自己转换版本)
(2)根据自己的需求,在网站下载合适的RTMdet.pth模型和配置文件(注意是两个文件)
https://github.com/open-mmlab/mmdetection/tree/3.x/configs/rtmdet
此处选择的是标红框
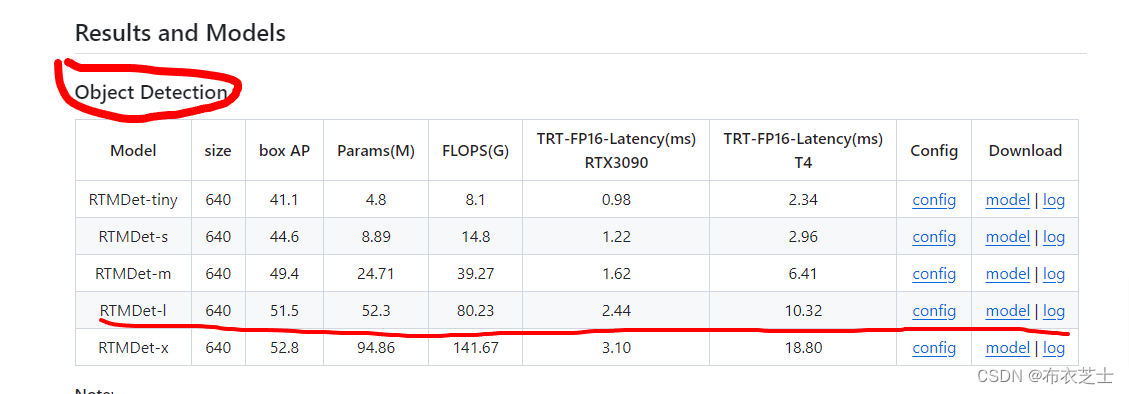
文件下载完毕后,将两个文件移入(1)中下载的文件夹中的python/convert_rtmdet.py同一路径下,然后运行
python convert_rtmdet.py --config rtmdet_tiny_8xb32-300e_coco.py --checkpoint rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --output RTMdet-l.onnx具体可以参考(1)中README,最后就得到RTMdet-l.onnx文件。
问题:注意可能配置文件中包含其他文件的依赖,导致程序无法正常运行;
因此需要下载github上的rtmdet源代码
GitHub - open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark
然后去configs/rtmdet文件夹中找与上面模型对应的配置文件名
最后运行代码为:
python convert_rtmdet.py --config E:/工厂机器视觉-行为动作识别/mmdetection-main/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py --checkpoint rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth --output RTMdet-l.onnx(3)onnx转换tensorRT文件
进入自己下载的tensorRT文件中bin中可以看到有一个trtexec.exe程序,复制上面创建的RTMdet-l.onnx文件
在CMD程序当前目录中运行
--onnx是自己生成的文件 --saveEngine是将会生成的engine文件
trtexec --onnx=RTMdet-l.onnx --saveEngine=RTMdet-l.engine
最后得到适应自己版本的tensorRT文件。
2.RTMpose转换
(1)
- 去官网上下载合适的模型pth和相应的配置文件,以及下载mmpose的源代码(配置文件可能存在依赖,因此需要下载整个文件夹)
https://github.com/open-mmlab/mmpose/blob/main/projects/rtmpose/README_CN.md
这里我选择的是检测人体全身133个关键点的模型,标红线的模型
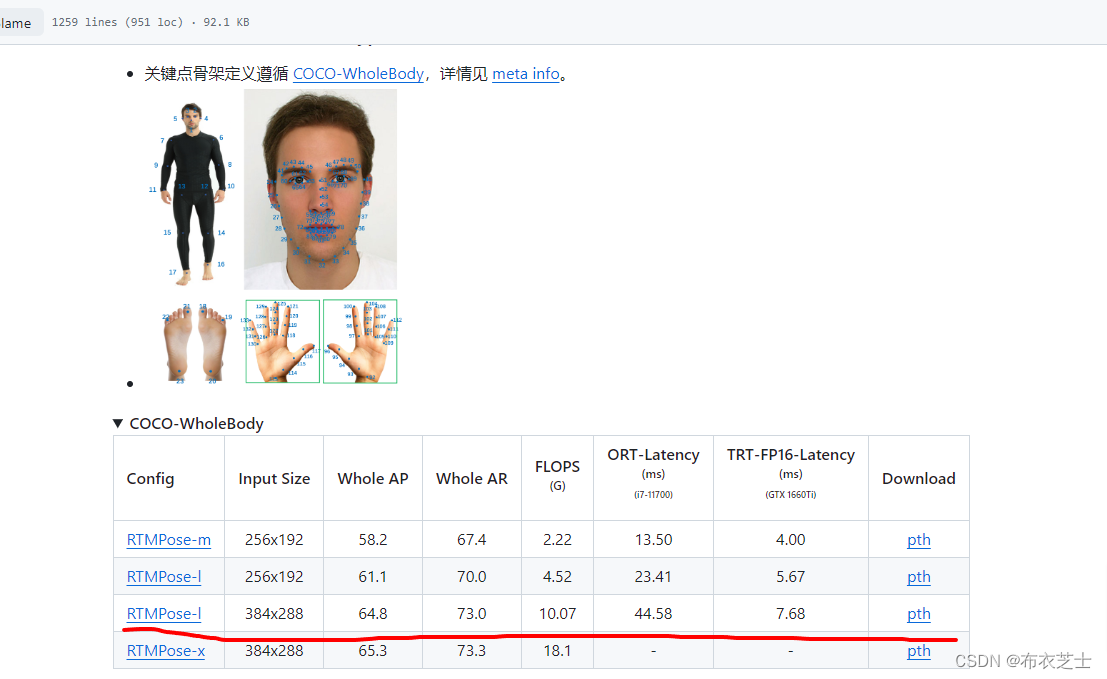
记录配置文件为rtmpose-l_8xb32-270e_coco-wholebody-384x288.py,后面需要到mmpose项目中去找到相应的位置。
(2)从pytorch一步转到tensorRT
下载mmdeploy项目(将RTMpose模型转换成tensorRT类型)
https://github.com/open-mmlab/mmdetection/
进入mmdeploy文件夹中,根据
python tools/deploy.py <deploy cfg> /
<model cfg> /
<checkpoint> /
<image path>/
<work-dir>
模版进行匹配
python tools/deploy.py \
configs/mmpose/pose-detection_simcc_tensorrt_dynamic-256x192.py \
E:/工厂机器视觉-行为动作识别/mmpose-main/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmw-x_8xb704-270e_cocktail14-256x192.py \
download_model/rtmw-x_simcc-cocktail14_pt-ucoco_270e-256x192-13a2546d_20231208.pth \
human-pose.jpg \
--workdir RTMpose最后生成三张测试图片(一张pytorch,一张onnx,一张tensorRT
)和一个onnx文件和eigne文件。
最后将两个engine文件导入C++部署环境中进行测试。














 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









