







 本文探讨了强化学习与其他学习模式的区别,强调其在环境探索和数据生成中的作用,如围棋AI。接着介绍了智能体的两种学习策略:基于价值的价值型学习和基于策略的策略型学习。此外,还讨论了强化学习的不同类别,包括模型基础与模型自由、价值基础与策略基础、在线策略与离线策略。最后,提到了编程实践环节,如GYM环境的应用。
本文探讨了强化学习与其他学习模式的区别,强调其在环境探索和数据生成中的作用,如围棋AI。接着介绍了智能体的两种学习策略:基于价值的价值型学习和基于策略的策略型学习。此外,还讨论了强化学习的不同类别,包括模型基础与模型自由、价值基础与策略基础、在线策略与离线策略。最后,提到了编程实践环节,如GYM环境的应用。
Ⅰ:强化学习与别的学习的区别、关系:
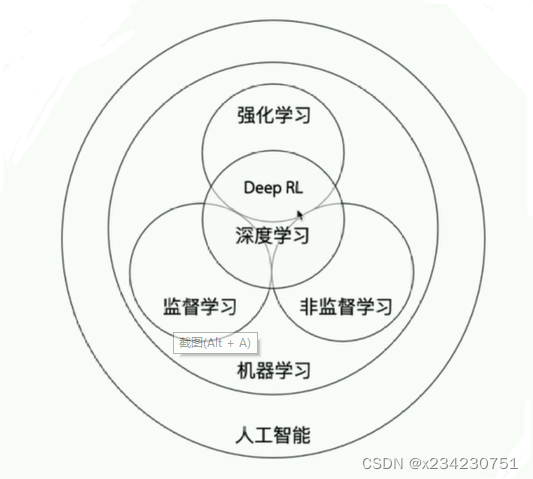
机器学习:通过优化方法挖掘数据中规律(从数据中总结模型)的学科
强化学习:不规定训练的目标,所训练的数据仅对模型打分,通过不断优化算法获得更高的模型评分。不仅能利用现有数据,还可以通过对环境的探索获得新数据,并利用新数据循环往复地更新迭代现有模型的机器学习算法。学习是为了更好地对环境进行探索,而探索是为了获取数据进行更好的学习。例:围棋AI
监督学习:通过对已有数据的学习预测未来事件。分为回归/分类两类:回归模型用于输出变量为实际值的问题,例如预测未来的美元膨降趋势;分类模型用于可以对输出变量进行分类,例如判别一个人的表情体现开心或难过。
非监督学习:无监督学习是训练机器使用既未分类也未标记的数据的方法,机器只能自行学习。机器必须能够对数据进行分类,而无需事先提供任何有关数据的信息。分为聚类/查异两类:聚类即将有相似性的数据归为一类;查异即找到与大多数数据有显著不同的特殊项。
深度学习:运用了神经网络作为参数结构进行优化的强化学习算法,拥有更强的算法拟合性,理论上可以模拟一切函数。但训练过程解释性较差,训练模型要求较高。
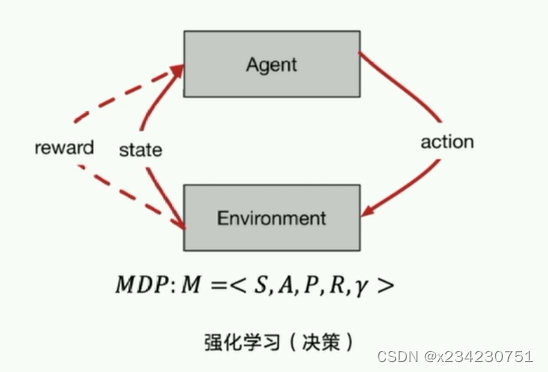
强化学习体现智能体通过与环境的交互
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









