







Ⅰ:概念:一种Policy-based的方法,策略梯度不计算奖励(reward),而是输出选择所有动作的概率分布,然后基于概率选择动作。 其训练的基本原理是通过反馈调整策略,具体来说就是在得到正向奖励时,增加相应的动作的概率;得到负向的奖励时,降低相应动作的概率。
Ⅱ:改变:Policy Gradient直接输出动作的最大好处就是,他能在一个连续区间内挑选动作,而基于值的,比如Q-Learning,它如果在无穷多得动作种计算价值,计算量过于庞大,无法很好完成(pg可以更好完成分幕式与连续性的案例,主要是连续性),但pg在一整轮实验完成后才会根据回馈更改策略(蒙特卡洛方法:蒙特卡罗方法又称统计模拟法、随机抽样技术,是一种随机模拟方法,以概率和统计理论方法为基础的一种计算方法,是使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。. 将所求解的问题同一定的概率模型相联系,用电子计算机实现统计模拟或抽样,以获得问题的近似解。. 为象征性地表明这一方法的概率统计特征)
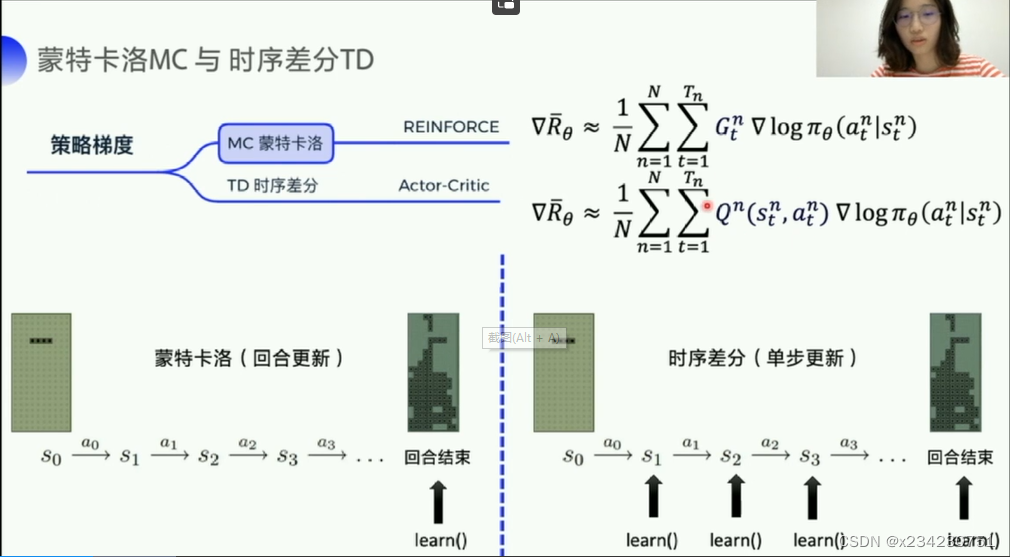
Ⅲ:基本组成:对象系统:策略梯度的学习对象;Policy策略:![]() 表示在状态s和参数θ条件下发生动作a的概率;Episode轮次:表示从起始状态开始使用某种策略产生动作与对象系统交互,直到某个终结状态结束;
表示在状态s和参数θ条件下发生动作a的概率;Episode轮次:表示从起始状态开始使用某种策略产生动作与对象系统交互,直到某个终结状态结束;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1595
1595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









